
Video

Learn how you can streamline your AI workflow by labeling only the data that provide valuable information and by using an arbitrarily large hardware infrastructure to execute it – all of this comes in an easy-to-use environment powered by Samsung SDSA’s Brightics AI Accelerator and RedBrickAI.
Driving Innovation
Now, you can fully streamline your AI workflow by labeling only the data that provide valuable information and by using an arbitrarily large hardware infrastructure to execute it – all of this comes in an easy-to-use environment powered by Samsung SDSA’s autoLabel and RedBrickAI.
Recognition


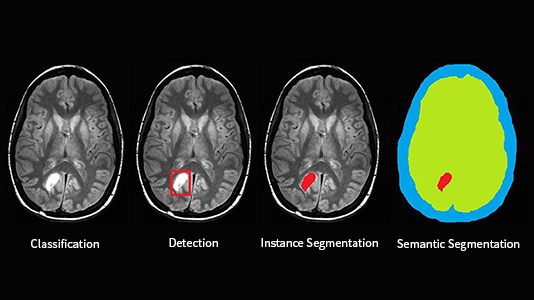
Active Learning Performance in Labeling Radiology Images Is 90% Effective
Major Services
- What can Autolabel do for you and your business?


-
Improve productivity
Automate 80% - 90% of manual data labeling effort
autoLabel is a human-in-the-loop, active learning system which sorts data by uncertainty, and human labelers start by labeling a small, automatically and carefully selected portion of the data. The autoLabel system trains a model on the labeled data and uses it to sort the remaining unlabeled data in order of confidence. Human labelers label the most informative images and autoLabel improves its model in several iterations. After 5% - 16% of the data is labeled manually, the confidence is typically so high that no further manual labeling needs to happen, and the remaining dataset can be labeled automatically. These automatically labeled images can now be checked by human domain experts with over 80% less effort than creating the labels themselves.
-
Improve processes
As the complexity and scale of datasets increase, the processes surrounding labeling datasets also need to evolve. You need a comprehensive toolset to accelerate labeling projects, reduce cost, and maintain high quality output. Structure, automate and qualify your labeling workflows by using the RedBrick AI platform. By building a completely custom labeling workflow, your team can easily carry out autoLabel active learning iterations.
Gain and maintain visibility into the productivity of your workforce, and track how autoLabel automates data labeling over time. Your labeling tasks will get automatically routed in the Active Learning workflow, and assigned to the appropriate stakeholders -- simplify the project management and focus on your science. -
Deliver performance
The rapid pace of AI innovation makes designing and training accurate AI models challenging. With autoLabel, you can eliminate guesswork and get started faster by automating the initial tasks of labeling data. This will get you a fully, accurately labeled dataset in the most efficient way possible. After that, you can train and fine-tune your model using Brightics AI Accelerator and later run it at inference on unlabeled data.
-
Reduce Total-Cost-of-Ownership
Compared to manually labeling all of the dataset, autoLabel reduces the time it takes to start labeling 66% and the Total-Cost-of-Ownership (TCO) up to 54% depending on the use case.
Because Samsung SDS’s autoLabel solution pre-processes the dataset in order of confusion before the first manual labeling iteration, it is able to exploit the most informative data to reduce active learning iterations and cloud infrastructure costs 33% over competing cloud offerings.
Use Cases
-
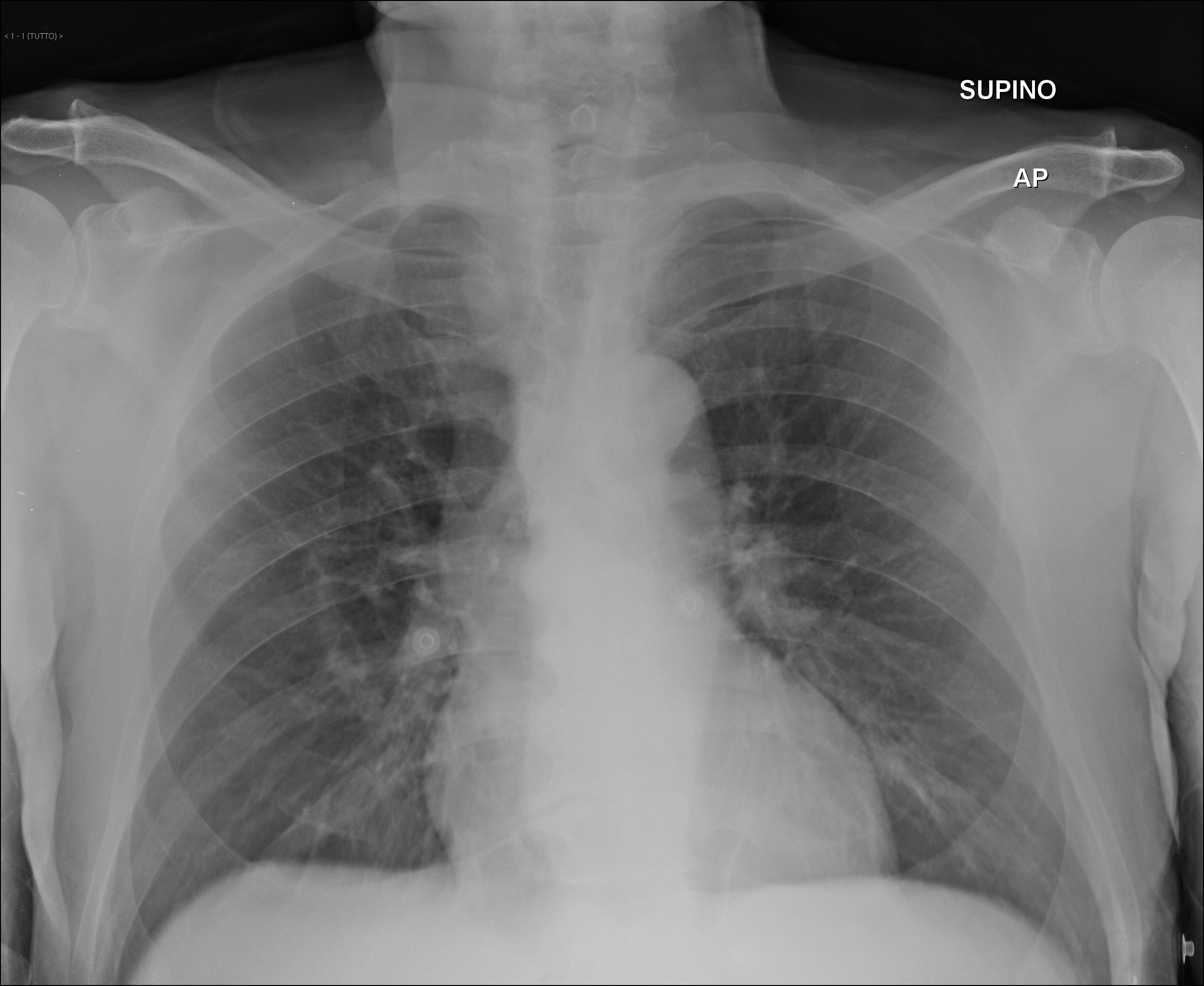 Detecting COVID-19 from X-ray ImagesAI has the potential to revolutionize healthcare by classifying, detecting and segmenting diseases image data so that doctors can focus more on patient care and treatment. Diagnosing COVID-19 usually requires a nasal swab and a laboratory analysis that takes time. By labeling only 6% of COVID-19 X-ray images, Samsung SDSA’s autoLabel converged label accuracy 94% faster than random order data labeling and 50% faster than regular active learning found in other AI platforms. The resulting COVID-19 classification model achieved 95% accuracy which is 4% more accurate than Rapid Test Kit nasal swab, and the Rapid Test Kits are often not available. Samsung SDSA’s COVID-19 X-ray classifier is also 1% more accurate than the PCR test that takes 1 – 2 days for results, and lung X-rays are quick, easy, and cheap.
Detecting COVID-19 from X-ray ImagesAI has the potential to revolutionize healthcare by classifying, detecting and segmenting diseases image data so that doctors can focus more on patient care and treatment. Diagnosing COVID-19 usually requires a nasal swab and a laboratory analysis that takes time. By labeling only 6% of COVID-19 X-ray images, Samsung SDSA’s autoLabel converged label accuracy 94% faster than random order data labeling and 50% faster than regular active learning found in other AI platforms. The resulting COVID-19 classification model achieved 95% accuracy which is 4% more accurate than Rapid Test Kit nasal swab, and the Rapid Test Kits are often not available. Samsung SDSA’s COVID-19 X-ray classifier is also 1% more accurate than the PCR test that takes 1 – 2 days for results, and lung X-rays are quick, easy, and cheap.
Price Plan
Customers pay for the number of 512 x 512 pixel or lower resolution tiles labeled in addition to cloud training and inference instance costs.
autoLabel software License
Tier 1 Price per Tile (<50K tiles): $0.08
Tier 2 Price per Tile (50K < x < 1M): $0.04
Tier 3 Price per Tile (>1M): $0.02
Total autoLabel SaaS
Tier 1 Price per Tile (<50K tiles): $0.135
Tier 2 Price per Tile (50K < x < 1M): $0.095
Tier 3 Price per Tile (>1M): $0.075
Example Pricing: For applying object detection labels to a dataset of 100,000 tiles, we estimate 11 autoLabel iterations, each consisting of 1% of the dataset, which would require manual labeling of 11,000 tiles. The autoLabel system will apply labels to the entire dataset of 100,000 tiles, automatically. The autoLabel SaaS price estimate would be 50,000 * $0.135 + 50,000 * $0.095 = $11,500, and the end customer would also pay 11,000 tiles * 7 labels/tile * $0.036/label * 3 labelers = $8,316 in estimated manual labeling costs. The customer TCO would be $19,816 = $11,500 for autoLabel SaaS + $8,316 for 3rd party manual labeling assuming that each manually labeled tile is separately labeled by 3 human labelers to disambiguate labeling quality. Note: Manual labeling is not part of this offering, and the price for a human-generated label is stated here only for comparative purposes.










Partner
Certificates
Related Offerings
Find out more about our offerings

Save time and deliver value faster with automated machine learning and automated deep learning in only a few lines of code.
Whether you’re looking for a specific business solution or just need some questions answered, we’re here to help.