Trung tâm R&D Samsung SDS giành giải nhất nhiệm vụ chung Cuộc thi Xử lý ngôn ngữ tự nhiên tiếng Việt

VLSP là gì?
VLSP là hội thảo thường niên về Xử lý tiếng nói và ngôn ngữ tiếng Việt do Cộng đồng VLSP tổ chức. Hiệp hội VLSP tập hợp tất cả các nhóm nghiên cứu học thuật và công nghiệp liên quan đến xử lý ngôn ngữ và lời nói tiếng Việt.
Từ năm 2012, VLSP Consortium đã tổ chức hàng loạt hội thảo, kết hợp với các hội nghị quốc tế lớn được tổ chức tại Việt Nam. Hội thảo quốc tế lần thứ 9 được tổ chức vào ngày 26/11/2020 đã thu hút sự quan tâm của cộng đồng.
Nhiệm vụ chung về Dịch máy trong chiến dịch Đánh giá VLSP đánh dấu sự trở lại thành công của Dịch máy trong hoạt động VLSP.
Nhiệm vụ chung về cuộc thi dịch máy ở VLSP
NHỮNG NGƯỜI THAM GIA
- Tổng số 25 đội:
- ✓ Học thuật: Đại học Stanford, JAIST, HUST, UIT-VNUHCM, UET-VNU,...
- ✓ Ngành: Samsung SDS, VinBigData, VCCorp, Ftech,...
- 5 đội cuối cùng:
- ✓ Samsung SDS (SDS) , VinBigData (VBD-MT) , JAIST (JNLP) , VCCorp (VC - Datamining) , HUST (S-NLP)
MÔ TẢ CÔNG VIỆC
- → Tiếng Trung → Dịch Máy Tiếng Việt
- → Tiếng Việt → Dịch Máy Tiếng Trung
SỰ ĐÁNH GIÁ
- → Bởi BLEU
- → Bởi con người (đánh giá cuối cùng)
Dữ liệu huấn luyện và kiểm tra

VLSP là hội thảo thường niên về Xử lý tiếng nói và ngôn ngữ tiếng Việt do Cộng đồng VLSP tổ chức. Hiệp hội VLSP tập hợp tất cả các nhóm nghiên cứu học thuật và công nghiệp liên quan đến xử lý ngôn ngữ và lời nói tiếng Việt.
Từ năm 2012, VLSP Consortium đã tổ chức hàng loạt hội thảo, kết hợp với các hội nghị quốc tế lớn được tổ chức tại Việt Nam. Hội thảo Quốc tế lần thứ 9 được tổ chức vào ngày 26/11/2020 đã thu hút sự quan tâm của cộng đồng.
Nhiệm vụ chung về Dịch máy trong chiến dịch Đánh giá VLSP đánh dấu sự trở lại thành công của Dịch máy trong hoạt động VLSP.
Luồng xử lý dữ liệu và đào tạo mô hình
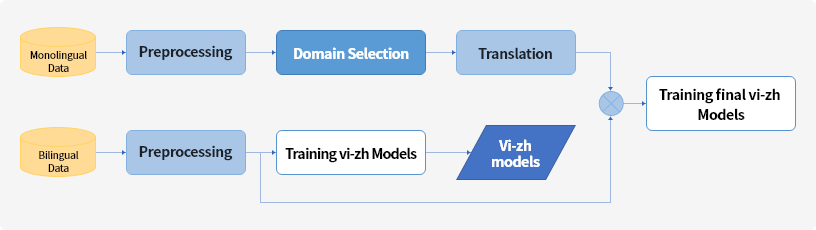
Giải pháp kỹ thuật
Mô hình được đào tạo trước mBART-50 đã qua sử dụng (https://arxiv.org/abs/2001.08210)
Đã đào tạo mô hình của chúng tôi bằng cách sử dụng tập dữ liệu song ngữ => mô hình cơ sở
Đã chọn 200K câu từ tập dữ liệu đơn ngữ có miền tương tự với tập dữ liệu song ngữ huấn luyện, để tạo tập dữ liệu song ngữ bổ sung (200K) bằng mô hình cơ sở của chúng tôi
Đã đào tạo mô hình với bộ dữ liệu song ngữ bổ sung
Đánh giá cuối cùng
→ Tiếng Trung -> Bài Dịch Tiếng Việt
- ✓ Hạng 1 : SDS , BLEU = 34,19 , Con người = 74,73
- ✓ Hạng 2 : VBD-MT , BLEU = 34,21 , Con người = 71,42
- ✓ Hạng 3 : S-NLP , BLEU = 29,91 , Con người = 68,74
→ Tiếng Trung -> Bài Dịch Tiếng Việt
- ✓ Hạng 1 : VBD-MT , BLEU = 17,95 , Con người = 69,19
- ✓ Hạng 2 : vc-datamining , BLEU = 17.1 , Human = 67.80
- ✓ Hạng 3 : SDS , BLEU = 21,87 , Con người = 67,68
→ Xếp hạng chung: (Nhiệm vụ 1 + Nhiệm vụ 2)/2
- ✓ Hạng 1 : SDS , 71,21
- ✓ Hạng 2 : VBD-MT , 70,30
- ✓ Hạng 3 : JNLP , 66,18

SDSRV - SAMSUNG SDS R&D CENTER IN VIETNAM
- Official Blog: https://sdsrv.ai/
- Facebook Channel: https://www.facebook.com/SDSRV.official
- Contact: Karrman Kim, Head of SDSRV (Tae Hyun, Kim, karrman@samsung.com)