A Preference Mismatch Is the Reason
Why AI Sometimes Gives Strange Answers
– Introducing Self-Curation, a Technology Designed to Enhance the Quality of Language Model Training.

One of the key challenges in making language models respond like humans is the ‘lack of consistency in preference data.’ To tackle this, Samsung SDS Research has been pioneering the ‘Self-Curation’ technique, which allows AI to self-refine its training data. This innovative approach has demonstrated a significant improvement in response quality by more than double. It is being recognized as a foundational technology for significantly enhancing the accuracy and efficiency of AI tuning.
Preference Consistency Matters: Enhancing Preference Learning in Language Models with Automated Self-Curation of Training Corpora
👉 See the Publication
Limitations of Preference Learning Datasets: Why Does AI Sometimes Provide Strange Answers?
Aligning language models to generate responses that reflect human preferences is essential for enhancing the reliability of deployed models. Preference learning methods - such as Reinforcement Learning from Human Feedback (RLHF) and Direct Preference Optimization (DPO) - leverage preference datasets to achieve alignment that surpasses the abilities of instruction fine-tuning (IFT). Unlike instruction fine-tuning, which relies on single-response supervision, preference learning methods enable more explicit learning by comparing chosen and rejected responses to given instructions.
However, preference learning datasets are inherently susceptible to noise, as inconsistent preferences for two responses can stem from the diverse cultural backgrounds of annotators.
Samsung SDS's Approach: What is ‘Self-Curation’?
To address this challenge, this study introduces a Self-Curation method. This approach begins by training a proxy model on the target preference dataset and subsequently using it to select data. By leveraging the Bradley-Terry model [Bradley & Terry, 1952], it assesses preference consistency by identifying discrepancies between the proxy model’s predictions - trained on the preference patterns of the target preference dataset - and the given annotations. This ensures that only data consistent with the proxy model's predicted preference patterns are retained, thereby enhancing the quality of preference learning and enabling language models operate in a safer and more reliable manner.
The goal of data curation is to select a subset of the initial dataset that can optimize a model’s performance [John and Draper, 1975]. In Language Model literature, data curation has primarily been proposed to increase efficiency of instruction tuning (IFT) by providing exemplar responses. In contrast, this study focuses on addressing inconsistent preference within the dataset for more effective preference learning.
While some studies combine individual reward models trained on unit preference objectives - such as usefulness and harmlessness - to create a reward model that reflects diverse preferences, the issue of inconsistent preference labels within each preference dataset remains unresolved. Our study introduces a fully automated approach that learns and extracts preference patterns directly from the preference dataset itself, selecting only data that consistently aligns with these patterns. By doing so, we aim to enhance the quality of individual learning datasets and improve the learning outcomes derived from them.
Preference Consistency: Key Factors for Generating Better Responses
Noisy labels in preference datasets often result from vague annotation criteria and ambivalent data that induce conflicting preferences. This issue is particularly pronounced when the quality of preference and non-preference (rejection) responses is nearly indistinguishable, as demonstrated in the example below. In such cases, language models struggle to identify clear criteria for meaningful preferences, complicating the learning process.
 [Figure 1] A Noisy Annotation: (Left) From Anthropic-HH, (Right) From UltraFeedback
[Figure 1] A Noisy Annotation: (Left) From Anthropic-HH, (Right) From UltraFeedback
Our analysis of preference consistency, leveraging the UltraFeedback dataset annotated by GPT-4, revealed that models trained solely on consistent preference data generate superior responses nearly twice as often as those trained on the equivalent volume of inconsistent data. Notably, even when the preference labels of inconsistent data were flipped, the quality of the generated responses remained largely unchanged. This finding suggests that the majority of the data is unlikely to be mislabeled. In this study, we introduce a new category termed "better-not-to-learn" data, which encompasses information that hinders effective preference learning. This category includes ambivalent data with split preferences and ambiguous data with high preference uncertainty. Such data, which even annotators find challenging to confidently differentiate, constitute a substantial portion of the original preference dataset, ranging from less than 10% to over 30%.
What is Self-Curation Method, and How Effective is It?
The self-curation method proposed in this study for preference learning datasets involves training a proxy model that provides response quality score and using it to identify and remove inconsistent data.
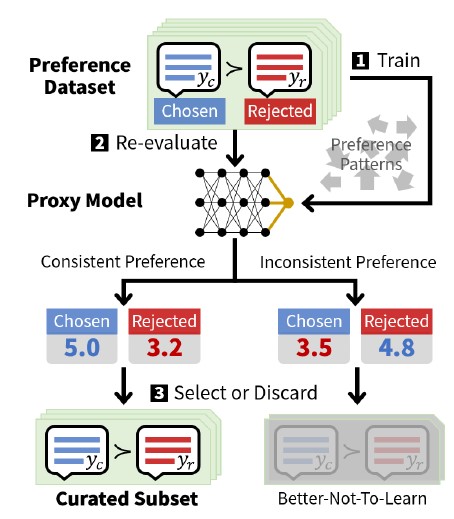 [Figure 2] Self-Curation Process
[Figure 2] Self-Curation Process
The detailed self-curation process is illustrated in Figure 2. As mentioned earlier, inconsistent annotations in preference datasets significantly impede effective preference learning. To address this challenge, the proposed self-curation method employs a proxy model to systematically identify and exclude inconsistent preferences from the training process, as outlined below.
(1) Train a proxy model to predict preferred responses by scoring response quality using the preference learning dataset itself;
(2) Identify discrepancies between the proxy model's predictions and the annotations in the dataset;
(3) Select data that exhibit consistent preferences to enhance preference learning effectiveness.
Figure 3 illustrates that, across a diverse array of preference datasets, the application of self-curation to the representative preference learning method DPO results in higher-quality responses compared to those generated using the original dataset. As evidenced by GPT-4’s response quality assessment, self-curation consistently and significantly enhances the quality of generated responses.
 [Figure 3] Performance Details of Self-Curation vs No Curation
[Figure 3] Performance Details of Self-Curation vs No Curation
Even when employing other preference learning methods such as cDPO (conservative DPO, Mitchell 2023) and rDPO (robust DPO, Chowdhury et al. 2024), as shown in Figure 4, self-curation consistently and markedly surpasses the performance achieved with the original datasets.
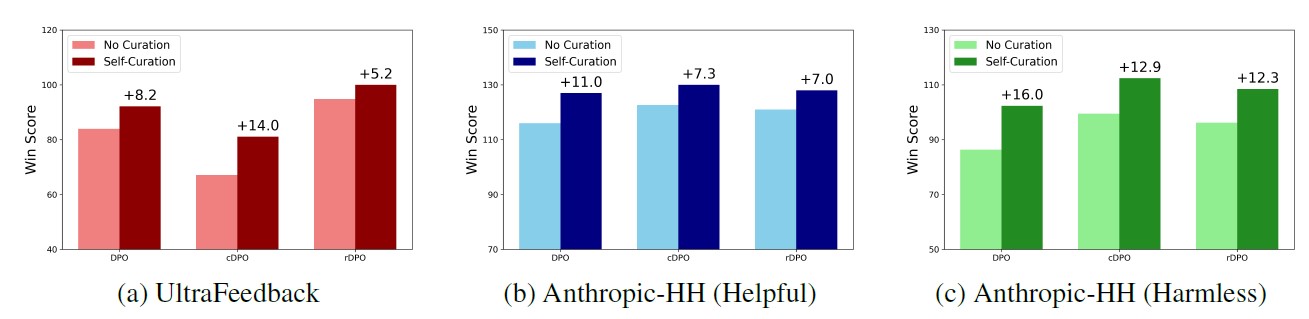 [Figure 4] Comparison of the Effectiveness of Self-Curation in DPO, cDPO, and rDPO
[Figure 4] Comparison of the Effectiveness of Self-Curation in DPO, cDPO, and rDPO
Furthermore, as long as the proxy model possesses the ability to extract consistent preference patterns from the preference dataset—such as a pre-trained model with over 30 billion parameters—our experiments show that self-curation remains effective regardless of the specific proxy model employed. These findings underscore the reliability of self-curation as a robust strategy for preference learning, delivering substantial improvements in model performance.
Furthermore, self-curation facilitates rapid convergence to peak performance even when utilizing smaller preference datasets, reducing the time required for preference learning by an average of 71.7%. It also demonstrates exceptional performance on benchmarks evaluating generalized instruction-following ability, such as Vicuna/MT-Bench. While there is an initial computational cost overhead associated with proxy learning, the consistently high response quality achieved through self-curation-based training fully offsets this initial overhead. Algorithm 1 (refer to below) shows a more detailed and structured representation of the self-curation process. The threshold for the reward score difference (lambda) between preferred and non-preferred responses, which determines the consistency of preference labels, defaults to 0. However, additional experiments demonstrate that fine-tuning it to a slightly larger positive value can further enhance performance.

The Implications of the Research and Key Things to Consider Moving Forward
In this study, we introduced a self-curation method to address label consistency problem in preference data used for language model training. By employing a proxy model to identify and select data with consistent preferences, self-curation significantly improves the performance of preference learning. This approach has consistently and significantly surpassed the use of original data, as evidenced by comparisons of instruction-following abilities across diverse datasets, preference learning methods, and proxy-based model configurations. However, identifying the optimal threshold for this process remains an ongoing research challenge.
👉 See the Publication