When Should Retrieval Model (Embedding Model) Be Updated? Optimal Timing revealed by GradNormIR

Today, retrieval models have evolved beyond mere information retrieval tools to become the core of large-scale artificial intelligence systems. In particular, in Retrieval-Augmented Generation (RAG) systems based on Large Language Models (LLMs), the quality of the retriever significantly influences the overall performance. However, the challenge lies in the fact that these models gradually lose performance over time. While they initially show excellent results after training, their accuracy declines as new topics, terms, and evolving user interests accumulate. So, how can this issue be resolved?
If the model is retrained every time new data is introduced, it would lead to excessive resource waste. Conversely, if the model is left unchanged for too long, retrieval quality will degrade significantly, leading to a poor user experience. Ultimately, the key is to determine ‘when an update is absolutely necessary.’
The paper we are introducing today presents a novel solution to this question: the GradNormIR (Gradient Norm Information Retrieval) method. This approach detects moments when documents with patterns different from the data used for training appear, solely using Gradient Norm*, and indicates when retraining is required. Let’s continue with the explanation below.
* Gradient Norm: In deep learning, models adjust parameters (weights) by calculating the gradient of the loss function. The gradient is a vector, and its magnitude is represented by the Gradient Norm. In this paper, the extent to which the model finds a new document "foreign" is measured using Gradient Norm.
When Should Dense Retrievers Be Updated in Evolving Corpora? Detecting Out-of-Distribution Corpora Using GradNormIR 👉 See the Publication
The Performance Decline of Retrieval Models Over Time
Dense Retrievers are advanced retrieval models powered by deep learning, designed to semantically understand text and retrieve relevant information with greater accuracy by leveraging semantic similarity within documents. Unlike keyword-based retrievers, which require exact word or phrase matches, dense retrievers can provide retrieval results even when the meaning is semantically identical or similar. This capability has made them increasingly popular across various industries in recent years. However, no model can perfectly understand all data. When new trends emerge or domains expand, the data distribution in the operational environment may differ from the distribution of the data used for training. As this discrepancy accumulates, it leads to a decline in performance.
Traditionally, to prevent performance degradation, models were updated regularly or retrained whenever there was even a slight change in data. However, these approaches require significant time and cost, and there is no guarantee that they will lead to improved performance. In other words, updates were often made unnecessarily while the model was still functioning well. Conversely, critical changes could go unnoticed, resulting in delayed updates. Ultimately, the most rational approach is to accurately identify the point at which changes in data begin to impact the model's performance.
The key concept to focus on here is Out of Domain (OOD). OOD data refers to data (documents or queries) with characteristics different from the data distribution used for training. While models exhibit strong performance with familiar data distributions, their predictions become unstable and error-prone in OOD scenarios. Therefore, if OOD data can be accurately detected, it becomes possible to identify the point at which changes in data begin to affect the model's performance. This insight can serve as a critical benchmark for determining when to update dense retrievers.
The Secrets Unveiled by the Model’s Gradient
Researchers from Samsung SDS and universities have proposed a method called GradNormIR to address the challenge of predicting Out of Domain (OOD) data before indexing. When new data is introduced, GradNormIR measures how different this new data is from the existing data distribution without requiring complex labeling or additional queries. Instead, it treats new documents as temporary queries and automatically constructs positive (Positive) and negative (Negative) samples. It applies dropout* to introduce variability into the learning process, and measures the size of the resulting Gradient Norm.
* Dropout: Typically used in neural network training to randomly deactivate some neurons (set them to zero), dropout prevents the model from becoming overly reliant on specific neurons or pathways. In this paper, when a new document is introduced, the model treats it as a temporary query. During this process, dropout is applied, resulting in the generation of an incomplete embedding vector for the document. The underlying assumption is that if the model is robust to the document, the vector's meaning should remain relatively unchanged even when parts of it are omitted.
By leveraging this approach, GradNormIR effectively identifies OOD data by analyzing the stability of the model's predictions under varying conditions, providing a practical solution for maintaining model performance in dynamic environments.
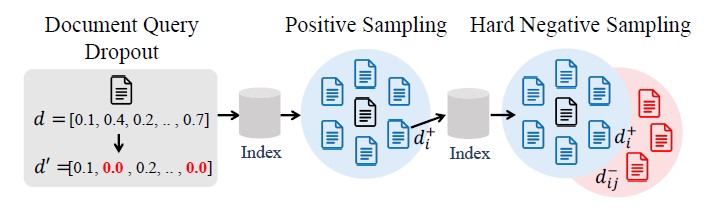 [Figure 1] Dropout and Positive and Hard Negative Sampling for Document Query Representation
[Figure 1] Dropout and Positive and Hard Negative Sampling for Document Query Representation
The key point here is that the size of the Gradient Norm indicates how "poorly generalized" the model is to the given data. If new data is similar to the distribution the model has been trained on, the model responds stably without significant changes, resulting in a small Gradient Norm value. Conversely, if the data is unfamiliar, the model attempts to make large adjustments to its learned parameters, leading to a larger Gradient Norm value. This simple calculation alone allows for the quantitative assessment of how different the entire corpus is from the existing data. In other words, Gradient Norm serves as an indicator to determine whether new data is out of domain or not.
The advantage of this approach is that it does not require additional labeled data or complex feedback collection processes, and it can be easily applied in operational environments. In practice, by calculating the Gradient Norm whenever a new document is added, it is possible to evaluate distributional differences and preemptively detect the timing when updates are necessary. This represents a preventive strategy, distinct from the conventional approach of updating only when performance declines noticeably enough to be perceived by users or operators.
GradNormIR's Proven Power through Experiments
The effectiveness of GradNormIR has been demonstrated through experiments on the BEIR (Benchmarking Information Retrieval) benchmark, which evaluates out of domain detection across various domains, including news, academic papers, and Wikipedia. In this study, experiments were conducted on multiple retrieval models, and the results confirmed that the GradNormIR method can detect out of domain data with significantly higher accuracy compared to existing methods.
As shown in the table below, GradNormIR maintains a low Document Retrieval Rate (DRR)* across datasets, demonstrating its ability to accurately identify retrieval failures. A lower DRR value indicates more effective out of domain detection.
* Document Retrieval Rate (DRR): The Document Retrieval Rate measures the probability of accurately retrieving documents for relevant queries. If a document is frequently retrieved for a query, the model is well-generalized for that document. Conversely, frequent omission of a document suggests a higher likelihood of retrieval failure.
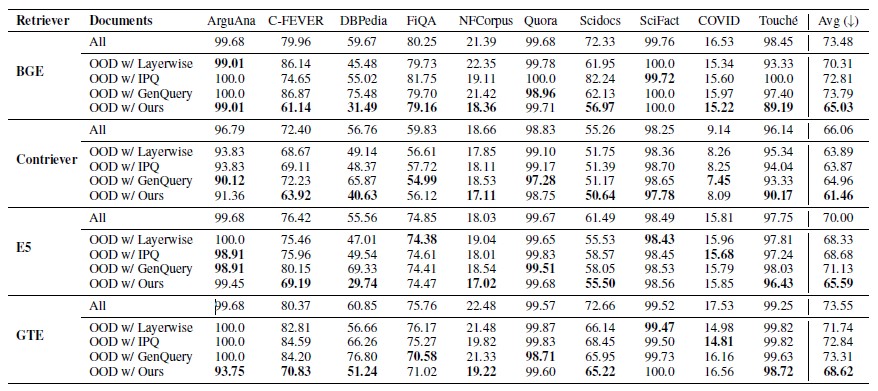 [Table 1] Comparison of Out Of Domain Document Detection among Various Retrievers in the BEIR Benchmark
[Table 1] Comparison of Out Of Domain Document Detection among Various Retrievers in the BEIR Benchmark
What is particularly interesting is that, in addition to predicting retrieval failures with GradNormIR, it can also serve as a criterion for selecting retrievers. In the experiments, retrievers evaluated as having a lower out of domain ratio achieved the highest scores in actual retrieval performance. This indicates that GradNormIR is not merely an alarm tool but can act as a compass to determine which retriever is optimal for operational environments.
Moreover, this approach is highly practical due to its low computational cost and lack of need for additional data. In practice, service operators can move away from uncertain questions like “Should I update now?” and make rational decisions based on patterns of data distribution changes. This allows for the reduction of unnecessary waste while maintaining stable retrieval quality.
 [Table 2] Comparison of Retrieval Performance Changes by Update Strategy in a Sequential Growth of Document Sets (S1→S10)
[Table 2] Comparison of Retrieval Performance Changes by Update Strategy in a Sequential Growth of Document Sets (S1→S10)
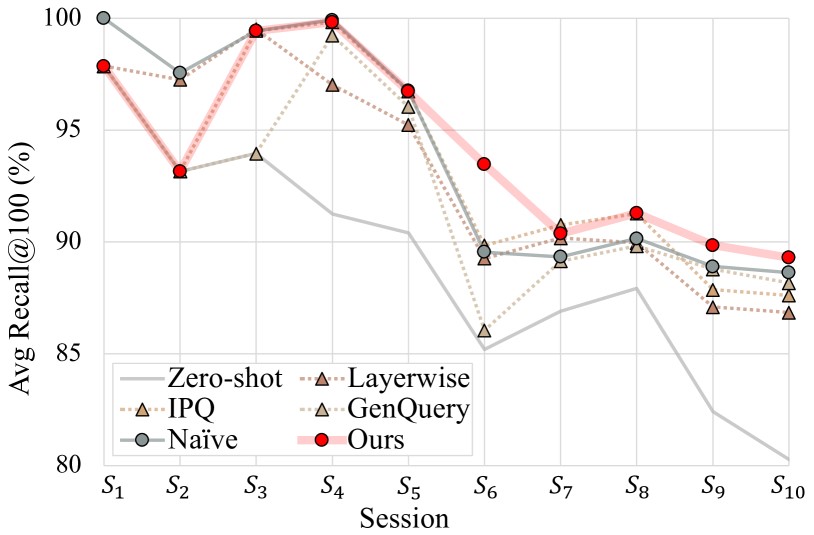
The figure above illustrates how retrieval performance (Avg Recall@100, as a percentage of the upper bound for each dataset) varies across different update strategies in a scenario where the document set grows sequentially (S1→S10). The comparison groups include Zero-shot (no updates), Naïve (retraining at every session), and existing methods (IPQ, Layerwise, GenQuery).
As the document set expands, the overall performance tends to decrease slightly, indicating an increase in retrieval difficulty. Notably, Zero-shot, which does not undergo updates, shows a significant drop to around 80% of its initial performance. In contrast, GradNormIR starts with lower performance in the early stages (S1, S2) due to delayed updates but maintains its performance by selectively updating only when out of domain is detected. After S6, GradNormIR consistently outperforms all other methods, visually demonstrating that updating "only when necessary" is more effective than updating "every time."
Anticipated Expansion in More Diverse Data Environments in the Future
GradNormIR has presented a meaningful solution to the problem of dense retrieval updates, but its potential extends far beyond this. It can be effectively utilized in more complex environments, such as multimodal data, multilingual corpora, and real-time data streams. In particular, in rapidly changing data contexts like social media or news, GradNormIR can quickly detect distribution changes and optimize model update strategies.
The true contribution of this research is not merely about improving performance. More importantly, it provides a new standard for the long-standing operational challenge of determining ‘when to update models’. This breakthrough has the potential to create significant turning points not only in academia but also in real-world industrial applications. Moving forward, methods like GradNormIR are expected to become standard tools for operating retrieval models, contributing to the development of smarter and more efficient artificial intelligence systems.
👉 See the Publication