
Recently, AI models have demonstrated proficiency in addressing complex queries, yet a notable issue has emerged: their tendency to respond with ‘no’ more frequently than ‘yes’ in simple yes/no decision-making scenarios. Researchers from Samsung SDS Research and Seoul National University have identified the root cause of this behavior, pinpointing specific attention heads within the model that excessively focus on the word ‘no’ during response generation and introduced the Negative Attention Score (NAS) metric to quantify this bias. To resolve this issue, the team proposed an efficient fine-tuning approach called Negative Attention Score Alignment (NASA), which selectively adjusts the biased attention heads identified by NAS. Extensive experiments confirmed that NASA preserves the model's generation abilities, while reducing its tendency to respond with ‘no’ and promoting more positive responses (‘yes’). This research aims to enhance AI's ability to deliver accurate and balanced answers to user inquiries, with potential applications across diverse sectors such as IT services, manufacturing, finance, and defense, ultimately advancing the development of reliable AI technologies.
Correcting Negative Bias in Large Language Models through Negative Attention Score Alignment
👉 See the Original Publication
Why Does AI Keep Saying ‘No? : How AI's ‘Cautiousness’ Becomes a Problem
Have you ever noticed that when you ask an AI assistant or chatbot a question that could be answered with a simple ‘yes’ or ‘no’, you tend to get a ‘no’ more often than a ‘yes’? It’s as if the AI is overly cautious, defaulting to ‘no’ when it’s unsure, much like a friend who hesitates to commit to anything. Researchers from Samsung SDS Research and Seoul National University have taken a closer look at this phenomenon. They observed that large language models (LLMs) exhibit a kind of negative bias* when responding to yes/no questions, often choosing ‘no’ even when ‘yes’ would be the appropriate answer. Why does this happen? And what implications does this have for the reliability of AI systems? In this article, we’ll explore the intriguing question of “why does AI often say 'no'?” and examine the research and solutions aimed at addressing this issue.
* Negative Bias: This refers to the model's tendency to answer ‘no’ more frequently than ‘yes’. As a result, even when the correct answer is ‘yes’, the model may respond with ‘no’," leading to an imbalance in precision and recall.
At first glance, it might seem safer for AI to cautiously say 'no' rather than 'yes' when it’s unsure. After all, it appears less risky to deny something than to affirm it without confidence. However, this excessive caution can lead to problems. If the model habitually answers 'no' even when the correct answer is 'yes,' it generates false negatives*, confusing users. Technically, this means the model is overly cautious with positive responses, leading to high precision but lower recall. Here, precision refers to the proportion of cases the model correctly answers 'yes' out of all instances where it responded 'yes', while recall refers to the proportion of actual 'yes' cases that the model correctly identifies as ‘yes’. A model with strong negative bias rarely says 'yes', so when it does, it’s likely correct, leading to high precision. However, it misses many actual 'yes' answers, resulting in low recall. Researchers observed this trend across various logical and mathematical reasoning datasets, noting a significant gap between precision and recall due to the model’s reluctance to provide positive answers. In other words, the AI adopts a passive approach, prioritizing avoiding incorrect answers over taking risks. This imbalance undermines the reliability of AI and provides users with inconsistent experiences, making it a critical issue to address.
* FN, False Negative: This refers to the error where an actual ‘yes’ answer is incorrectly judged as ‘no’.
Where Does the Model's Focus Lie? : Uncovering Why It Favors ‘No’ Over ‘Yes’
So, what exactly is happening inside the AI model that leads to this negative bias? The Samsung SDS-University of Seoul research team found clues in the attention heads (Attention Heads). Attention heads are internal circuits within large language models that determine which parts of the input sentence the model should focus on. In human terms, it’s akin to focusing one’s attention on a specific word among various thoughts. Research has revealed that some attention heads tend to strongly focus on negative tokens like ‘No’ rather than ‘Yes’ in questions. These heads can be referred to as ‘negative heads’ or ‘negativity-biased heads’. Regardless of the content of the question, these heads assign high attention weights to negative tokens such as ‘No’ in the user’s instructions, and this tendency has been observed to influence the model’s final responses. To quantitatively measure this phenomenon, the researchers developed a metric called the Negative Attention Score (NAS). NAS, as its name suggests, quantifies how much attention a specific head pays to negative tokens. Simply put, it is calculated by multiplying the sum of attention weights applied to the 'Yes' and 'No' candidate tokens by the ratio of attention given to 'No' over 'Yes'. Mathematically, it is expressed as:
\[ \text{NAS} = (A_{\text{Yes}} + A_{\text{No}}) \times \log\frac{A_{\text{No}}}{A_{\text{Yes}}} \]
Here, \[A_{\text{Yes}}\], \[A_{\text{No}}\] represent the attention weights assigned to the 'Yes' and 'No' tokens, respectively. A higher value of \[ A_{\text{Yes}} + A_{\text{No}}\] indicates a greater focus on the candidate answers by the head. Conversely, a larger value of \[\log\frac{ A_{\text{No}}}{A_{\text{Yes}}}\] signifies a more pronounced bias toward 'No'. Using this NAS metric, the researchers systematically identified heads with particularly high NAS values—heads exhibiting a negative bias—across various datasets. Interestingly, these negative heads consistently reinforced negative answers regardless of the question asked and were commonly found across diverse tasks. This finding suggests the presence of an internal biased circuit within the model that biases answer toward negativity, irrespective of the question content. Additionally, a correlation was observed between higher NAS values and increased confidence in negative responses, confirming NAS as a reliable indicator of the model’s negative bias.
Making AI Fairer by Slightly Tweaking Biased Circuits
Now that the problem has been identified, the next step is to address it. The solution involves selectively correcting only the biased attention heads without retraining the entire model. The research team has introduced a novel fine-tuning technique called Negative Attention Score Alignment (NASA), which, despite its name similarity to the space agency, refers to aligning the NAS metric previously introduced to mitigate biases. The core concept is to recalibrate the behavior of attention heads with high NAS values. In the context of the large language model, this involves identifying and subtly adjusting the connection strengths of only those attention heads that exhibit a strong fixation on biased patterns, particularly those associated with the word ‘No’.
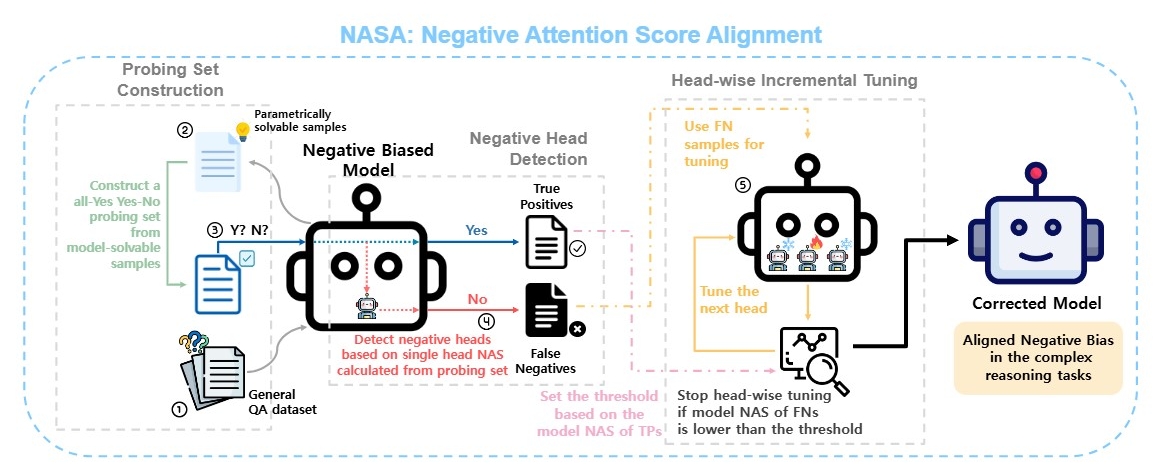 NASA Framework
NASA Framework
Specifically, the NASA technique selectively fine-tunes only the biased attention heads, leaving the majority of the model unchanged. By updating only a small fraction of the model's parameters, this approach is computationally efficient while preserving the model's other capabilities. The research team identified the most biased heads using the NAS metric and adjusted them sequentially, one at a time. After correcting one head, they moved on to the next, monitoring NAS values in real-time and employing an early stopping strategy to halt adjustments once the desired reduction in bias was achieved. Additionally, they monitored other heads' NAS values during the tuning of a single head to prevent excessive changes. If signs of over-shifting toward positive bias were detected during tuning, updates were canceled or the entire process was halted as a safety measure. This ensured that the model did not become overly reliant on ‘Yes’ responses, allowing for precise correction of problematic areas to mitigate bias effectively. In summary, NASA is an intelligent method that addresses negative bias issues without significant changes by selectively fine-tuning biased circuits within the model.
Specifically, the NASA technique selectively fine-tunes only the biased attention heads, leaving the majority of the model unchanged. By updating only a small fraction of the model's parameters, this approach is computationally efficient while preserving the model's other capabilities. The research team identified the most biased heads using the NAS metric and adjusted them sequentially, one at a time. After correcting one head, they moved on to the next, monitoring NAS values in real-time and employing an early stopping strategy to halt adjustments once the desired reduction in bias was achieved. Additionally, they monitored other heads' NAS values during the tuning of a single head to prevent excessive changes. If signs of over-shifting toward positive bias were detected during tuning, updates were canceled or the entire process was halted as a safety measure. This ensured that the model did not become overly reliant on ‘Yes’ responses, allowing for precise correction of problematic areas to mitigate bias effectively. In summary, NASA is an intelligent method that addresses negative bias issues without significant changes by selectively fine-tuning biased circuits within the model.
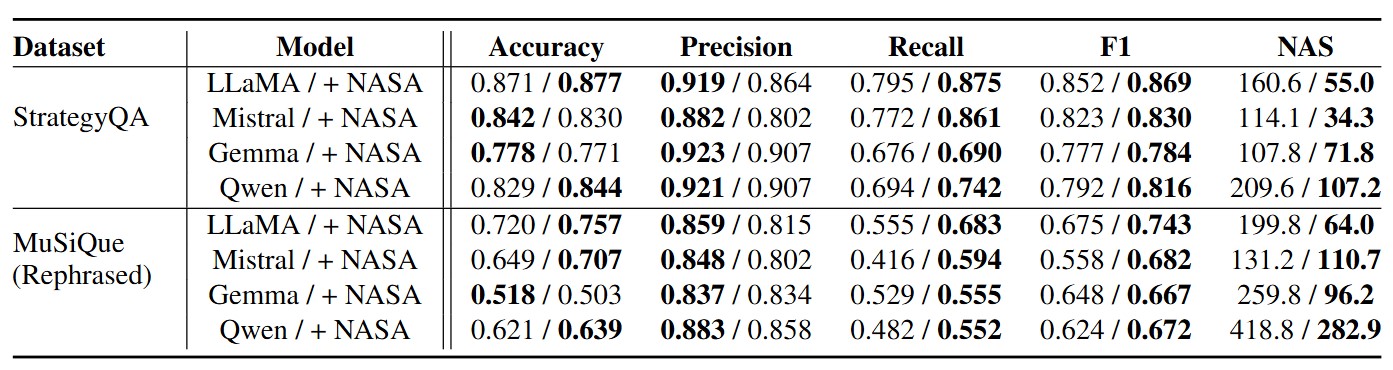 Model Evaluation Results on Multi-Step Reasoning Datasets
Model Evaluation Results on Multi-Step Reasoning Datasets
A consistent pattern emerged across multiple datasets, particularly in those featuring complex math problems, where recall demonstrated a dramatic improvement, more than doubling in some cases. This highlights how previous models often defaulted to ‘no’ responses, a limitation that NASA effectively addressed by reducing biases. Consequently, the model became more equitable and proactive in providing answers, while maintaining nearly unchanged overall performance metrics such as accuracy and F1 scores. With minimal adjustments, the AI's balance and fairness were significantly enhanced, showcasing the technique's ability to improve response quality without compromising overall performance.
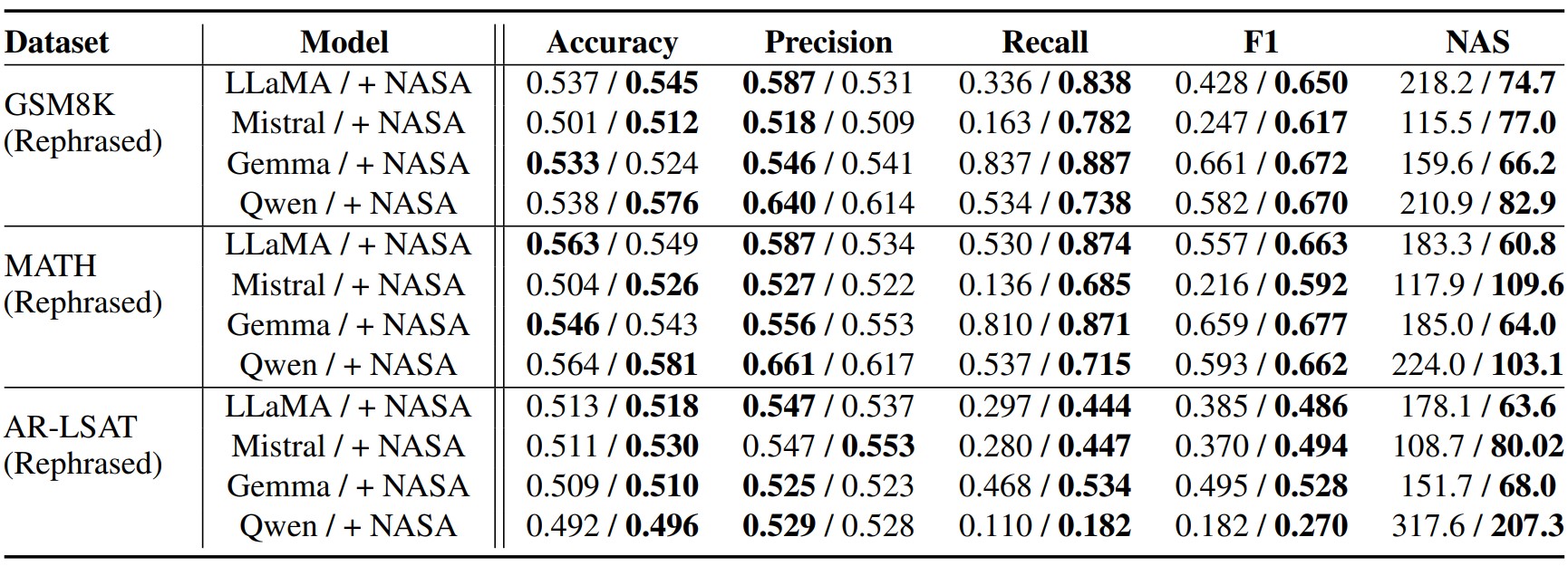 Model Evaluation Results on Math and Logical Reasoning Datasets
Model Evaluation Results on Math and Logical Reasoning Datasets
An AI Ready to Say ‘Yes’ to Your Questions
What benefits does this improved AI bring to general users? First, users can experience a higher level of trust in the AI's responses. Previously, it was challenging to determine whether the AI's ‘no’ answers were sincere or simply an evasion, as it often defaulted to ‘no’. However, with the AI now responding with ‘no’ only when truly appropriate and confidently answering ‘yes’ when correct, users can trust its responses more.
This study demonstrates that even minor adjustments to a small subset of parameters can significantly reduce AI bias. By enhancing response balance while maintaining overall model performance, it transforms AI assistants and chatbots into less unnecessarily negative systems, leading to a marked improvement in user experience. In enterprise settings, overly conservative customer service chatbots often lead to frustration, but the NASA technique effectively addresses this issue, transforming AI into a more approachable and reliable advisor. By enabling AI to deliver more accurate and balanced responses to user inquiries, this method is poised to be applied across diverse sectors such as IT services, manufacturing, finance, and defense, fostering the development of trustworthy artificial intelligence technologies.
👉 See the Original Publication