Can You Understand Documents Without OCR?
– A New Approach to AI Document Analysis

Samsung SDS Research has developed an AI technology capable of directly interpreting document images without the need for OCR. The core of this innovation is 'HVFA (Hierarchical Visual Feature Aggregation),' a cutting-edge technology that facilitates fast and accurate analysis of documents with various resolutions and styles. By bypassing the need for OCR engines, HVFA significantly enhances processing speed, accuracy, and adaptability, revolutionizing document analysis.
Hierarchical Visual Feature Aggregation for OCR-Free Document Understanding
👉 See the Publication
Why is OCR-Free Document Understanding Essential? What Are the Challenges of This Research?
Are you familiar with a novel OCR-free document understanding framework? Let’s delve into this topic further.
In early research on OCR-free document understanding, studies primarily relied on external OCR engines to analyze the texts within images and utilized it for modeling. Subsequent studies shifted toward simultaneously modeling text, visual, and layout information. However, these models were highly dependent on the performance of OCR engines, requiring complex modules for seamless integration and consuming significant time.
* Examples of performance dependency: Varied fonts, handwritten text, and damaged documents can negatively impact OCR engine analysis.
Samsung SDS's Approach: Processing Diverse Fonts and Styles with Minimal Input!
We developed a Multimodal Large Language Model (MLLM) capable of processing visual documents at multiple scales rather than a fixed scale. This approach allowed us to effectively handle diverse font sizes and styles within document images.
* MLLM: A model that understands and analyzes not just text but various types of data and generates text-based responses.
However, extracting visual features at multiple scales leads to a quadratic increase in the complexity of the LLM. To address this, we designed and implemented a Hierarchical Visual Feature Aggregation (HVFA) module, integrating Cross-Attentive Pooling and Feature Pyramid structures. This approach reduced the number of visual feature tokens fed into the LLM, effectively mitigating increased computational costs while enhancing overall model performance.
* Cross-Attentive Pooling: A deep learning technique that combines pooling operations with attention mechanisms, particularly aggregating information by considering relationships between different inputs (e.g., queries and references, images and text).
** Feature Pyramid: A hierarchical structure that stacks feature maps of various resolutions to effectively recognize objects of different sizes.
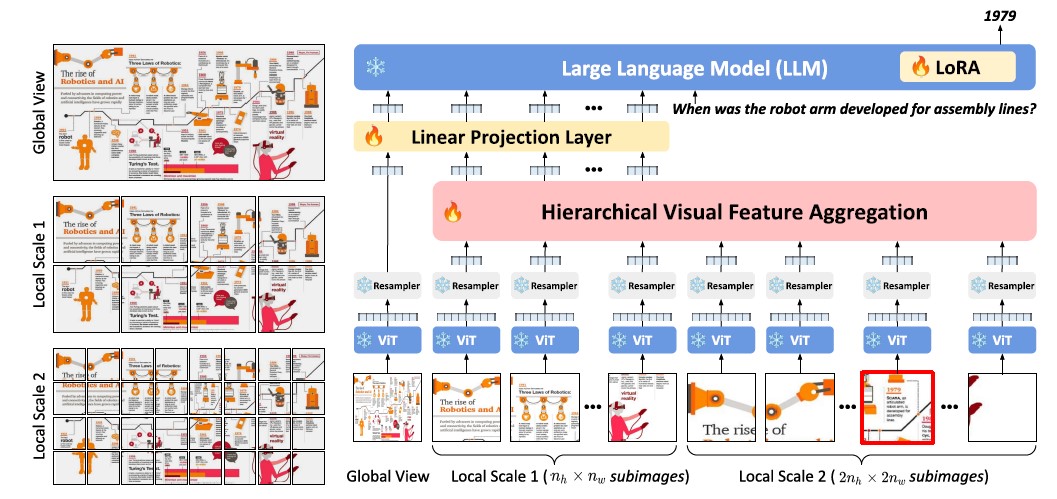 [Figure 1] Overview of the Framework Proposed in the Study
[Figure 1] Overview of the Framework Proposed in the Study
This model extracts visual features at multiple scales and aggregates them through the HVFA module. The resulting aggregated visual features are then fed into the LLM, which generates language responses in an autoregressive manner.
Detailed Explanation of the Research Methodology
We will discuss this research methodology in more details. For the study, we employed a vision encoder and a projector to generate visual inputs of multiple scales from images. We then introduced HVFA to reduce the number of visual feature vectors while preserving local details. As previously mentioned, HVFA leverages cross attentive pooling, which functions within a feature pyramid structure (Local → Global) to fuse visual features of adjacent sub-images. As illustrated in [Figure 2], we first obtained low-dimensional feature vectors by applying max pooling to the finer-grained sub-image visual features. These pooled feature vectors serve as query (Pooled Q) for cross-attention, while the original visual feature vectors act as keys and values (Unpooled K, V). Through its cross-attention mechanisms, the pooled feature vectors reference the information of the original features, enabling the compression and preservation of detailed information. Additionally, the enhanced pooled feature vectors are combined with the feature vectors of lower-resolution images to reconstruct the final aggregated features. This process facilitates the learning of feature relationships and context-aware information aggregation.
Furthermore, to address the challenge of managing multiple image scales, we developed a multi-scale visual input integration framework. We enhanced this framework to capture detailed information even from high-resolution images. As a result, it enabled more efficient processing of document images with varying resolutions and aspect ratios.
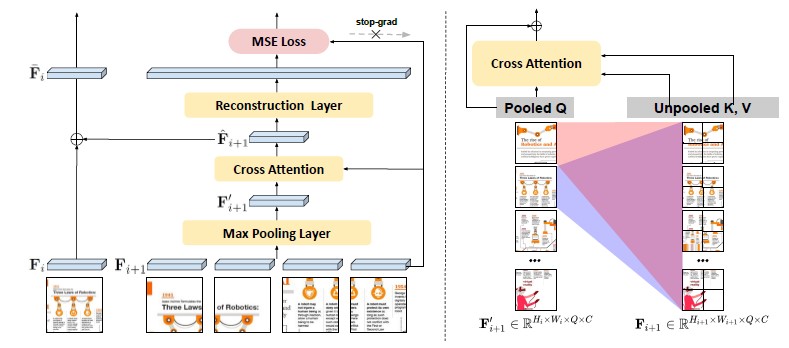 [Figure 2] Example of Hierarchical Visual Feature Aggregator(HVFA) Module
[Figure 2] Example of Hierarchical Visual Feature Aggregator(HVFA) Module
(Left) HVFA aggregates high-resolution features into low-resolution features using feature pyramid layers.
(Right) In cross-attentive pooling, each grid involves detailed visual features, summarizing them to preserve finer details by reflecting the refined features.
Performance Experiment: How Well Does It Work?
To train the document analysis model, we utilized a document instruction dataset corpus that includes various types of document images (tables, charts, natural images, web page screenshots, etc.). The model was trained and evaluated using this dataset.
The dataset contains approximately 650,000 images of diverse document types, and the model’s performance was evaluated using the test split of each dataset. Implementation details include the use of two Resampler-based MLLMs, BLIP-2 and mPLUG-Owl. The vision encoder was kept frozen and the language model was fine-tuned using LoRA*. Additionally, we implemented a multi-scale HVFA module configuration, integrated a Reconstruction Layer Loss, and performed a relative text position prediction task.
* LoRA (Low-Rank Adaptation): A method that significantly reduces the number of learnable parameters by adding low-rank matrices instead of updating all weights during fine-tuning of a large model, enhancing efficiency.
As a result, the proposed algorithm outperformed UReader* on most benchmarks, demonstrating successful knowledge transfer from pre-trained MLLMs to the document analysis model.
* Proposed document analysis Instruction Tuning based on pre-trained MLLMs, achieving lower training costs and an ability to handle a wider variety of document images. (Related papers: UReader: Universal OCR-Free Visually-Situated Language Understanding with Multimodal Large Language Model.)
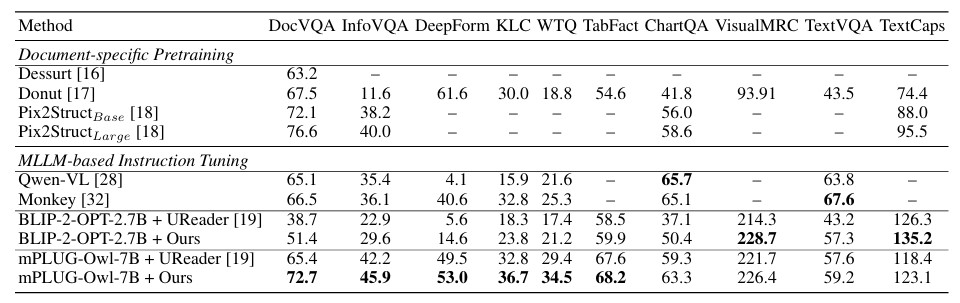 [Table 1] Comparison with Other OCR-Free Document Understanding Baseline Models
[Table 1] Comparison with Other OCR-Free Document Understanding Baseline Models(The bold numbers indicate the best performance in each column)
What Are the Implications of This Research?
Now, let us summarize the conclusions of this study. We presented a novel OCR-free document understanding framework that leverages a pre-trained Multimodal Large Language Model. Our approach integrated multi-scale visual features to accommodate diverse font sizes within document images. We proposed the Hierarchical Visual Feature Aggregation (HVFA) module with cross-attentive pooling, effectively reducing the computational costs associated with detailed visual inputs. This effectively balanced information retention and computational efficiency while adapting to varying document sizes. Furthermore, our framework introduced a novel instruction tuning task to enhance the model’s text-reading capability by incorporating positional information of text within images. Extensive experiments validated the efficacy of our framework, demonstrating strong performance across a range of document understanding tasks.
👉 See the Publication