The Brain of AI, Moving Faster
– The Story of Samsung SDS’s Memory-Computation-Based LLM Inference Optimization Technology, ‘PAISE’

Samsung SDS has developed 'PRAISE,' an innovative AI system designed to significantly enhance the inference speed of large language models (LLMs) by up to 48.3% while cutting power consumption by 11.5%. At its core lies PIM (Processing-In-Memory) technology, which executes calculations directly within memory. This paper explores how PRAISE effectively addresses existing AI bottlenecks and facilitates the development of sustainable AI infrastructure.
PAISE: PIM-Accelerated Inference Scheduling Engine for Transformer-based LLM
👉 See the Publication
Why is AI slow? - The Bottleneck of Attention Mechanisms
At the heart of today's AI services lie large language models (LLMs). Models like ChatGPT and Claude enable natural, human-like conversations, but this capability comes at a cost—massive computational power and memory usage. A key factor in this process is the 'attention' mechanism’, which evaluates the relevance of all previously generated words when creating a new one, significantly influencing overall performance.
Attention mechanisms pose a computational challenge because, when generating a current word, they calculate relevance with all previously generated words. This process generates three vectors—Query, Key, and Value—with the Key and Value vectors needing repeated storage and retrieval. For each word generated, the entire stored data must be read again, and new data added, leading to exponential growth in data volume over time. The primary bottleneck affecting model speed is not the computational process itself but rather the repeated 'reading and writing' of data to memory.
![[Figure 1] PAISE Architecture diagram showing the three main components: Scheduling Algorithm, PIM-DLA (Data Layout Adjustment), and IB-GEMM(V)](https://image.samsungsds.com/kr/research-blog/250617_3_01.jpg?queryString=20260629022022) [Figure 1] PAISE Architecture (Scheduling Algorithm, PIM-DLA, IB-GEMM(V))
[Figure 1] PAISE Architecture (Scheduling Algorithm, PIM-DLA, IB-GEMM(V))
Samsung SDS’s Approach: PAISE, a Novel Method of In-Memory Computation
Samsung SDS's Cloud Research Team has introduced a new system called PAISE (PIM-Accelerated Inference Scheduling Engine, presented at IEEE HPCA 2025) to overcome these limitations. At its core, PAISE leverages PIM (Processing-In-Memory) technology. Unlike conventional systems that rely on CPUs or GPUs for computation, PIM integrates computational units directly into memory chips, enabling data processing on the spot without the need for constant data transfer. This approach is particularly effective for compute-intensive tasks such as attention mechanisms, which require frequent data reading and writing.
![[Figure 2] Diagram of the PIM-DLA technique, comparing a conventional data layout with the PIM-DLA optimized layout that partitions and aligns data across memory banks for parallel in-memory computation](https://image.samsungsds.com/kr/research-blog/250617_3_02.jpg?queryString=20260629022022) [Figure 2] PAISE’s Data Layout Optimization Technique (PIM-DLA)
[Figure 2] PAISE’s Data Layout Optimization Technique (PIM-DLA)
PIM-DLA: Improved Memory Alignment Method
However, simply having PIM does not guarantee faster performance. It requires intelligent decision-making to determine which calculations should be processed on PIM for optimal efficiency, as well as sophisticated techniques to organize data in alignment with PIM’s internal structure. PAISE addresses this challenge effectively. First, it analyzes the characteristics of each computation and the hardware structure to automatically decide which operations should be offloaded to PIM (scheduling algorithm). Second, it applies optimization techniques (PIM-DLA, Data Layout Adjustment) to arrange and partition data within memory to enable faster calculation.
![[Figure 3] Diagram of the IB-GEMV technique, contrasting sequential small matrix-vector multiplications with interleaved batched processing that groups operations to enable parallel execution and maximize memory bandwidth](https://image.samsungsds.com/kr/research-blog/250617_3_03.jpg?queryString=20260629022022) [Figure 3] PAISE’s New Matrix Operation Technique (IB-GEMV)
[Figure 3] PAISE’s New Matrix Operation Technique (IB-GEMV)
IB-GEMV: Parallelized Attention Computations
To further optimize the efficiency of attention computations, the research team introduced IB-GEMV (Interleave-Batched General Matrix-Vector Multiplication) method. Typically, models perform repeated small matrix multiplications, but processing these operations individually limits parallelization and reduces execution speed. IB-GEMV addresses this problem by pre-interleaving these small operations within memory, enabling batch processing. By grouping multiple computations into a single batch, it facilitates parallel execution and efficiently distributes the calculation results, thereby maximizing memory bandwidth utilization
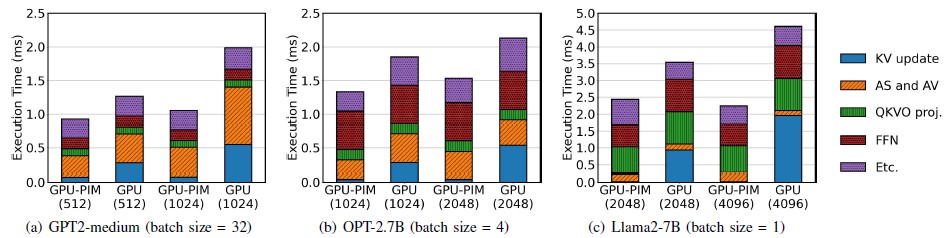 [Figure 4] Stage-wise Execution Time Reduction in LLM Inference After Implementing PAISE (GPU-PIM)
[Figure 4] Stage-wise Execution Time Reduction in LLM Inference After Implementing PAISE (GPU-PIM)
Experimental Results – Speed Increased by Up to 48%, Power Consumption Reduced by 11%
The research team implemented this technology across GPT-2, OPT, and Llama2 models and conducted experiments. As illustrated in Figure 4, the IB-GEMV method demonstrates notable performance gains, particularly with larger batch sizes, while maintaining efficiency for smaller batches. A significant improvement lies in the substantial reduction in the time required for Key-Value (KV) cache updates, which repeatedly occur in attention layers. This visually illustrates that the IB-GEMV method dynamically adapts to different computational structures, effectively accommodating diverse scenarios in LLM inference. PAISE is recognized as an effective system that enhances LLM inference performance by transitioning from a GPU-only architecture to a PIM-based approach, thereby alleviating memory-bound bottlenecks.
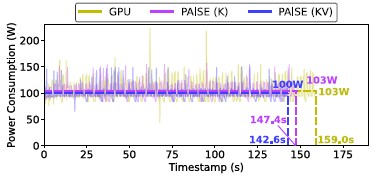 [Figure 5] Reduced Power Consumption after the Use of PAISE
[Figure 5] Reduced Power Consumption after the Use of PAISE
Furthermore, the implementation of PAISE resulted in a maximum inference speed improvement of 48.3% and a power consumption reduction of approximately 11.5%. As depicted in Figure 5, the use of PIM technology led to a decrease in the average power consumption of the entire GPU system, alongside reduced execution times, thereby lowering overall energy usage. This demonstrates that PAISE goes beyond mere speed enhancements, providing tangible benefits for sustainable AI infrastructure operations.
Significance of the Research and Future Directions
Lastly, unlike many existing GPU-based studies that relied solely on simulations for performance analysis, PAISE stands out for its implementation and validation on Samsung’s real PIM hardware, 'Aquabolt-XL'. Beyond merely accelerating AI, PAISE plays a crucial role in reducing power consumption and lowering infrastructure costs. With continued advancements in PAISE, a wide array of artificial intelligence services can be expected to become significantly faster and more cost-efficient. This groundbreaking approach of performing calculations directly within memory is once again advancing the future of AI.
👉 See the Publication