Introduction of an open-source Kubernetes-based MLOps platform
- 2022-06-30
- 작성자 Park Migyeong



A recent survey by a global research company found that many global companies are starting to use AI for their key activities. This is especially evident in product development, service operations, and marketing, which means many companies are actually bolstering their achievements with AI. Investing in AI and breakthrough achievements are not limited to tech companies, but are spread to the overall industry. Then, what should be considered for a successful AI application?
What should global companies consider when adopting AI?
How many global companies are adopting AI?
According to “The state of AI in 2020” (Nov. 17, 2020), a survey of global companies by McKinsey, more than 50% of respondents said that they were using AI for their key activities. The result showed that AI technology was actively used in the fields of product development, service operation, and marketing. 66% of respondents said that investing in AI has increased their revenue, while 22% said that it contributed more than 5% to their *EBIT. It implies that numerous companies are boosting their achievements with AI. It also shows that investment in AI and achievements are not limited to tech companies, but are spread to the overall industry.
* Earnings Before Interest and Taxes: Operating profits, profits before taxes, and sales revenues minus expenses
What should be considered to successfully adopt AI?
Now, let’s take a look at what should be considered for a successful application of AI. McKinsey mentioned that companies with the highest achievements from the use of AI have active support from their executives and technical leadership, unlike other companies. It also said that they tend to secure professionals and introduce end-to-end (E2E) AI platforms on top of internal development of AI services the company needs, rather than purchasing individual AI applications based on aggressive investment in manpower and platforms. In this context, an AI platform is a platform that integrates various technological elements used to run various AI services, including AI models and offers a combination of them.
Why is it hard to develop commercial services in the field of AI?
Currently, studies on algorithms and the latest technologies of AI models are being carried out rapidly and actively. Only commercial services that effectively keep up at a fast pace can be competitive, however it is not a simple matter. This is because it is harder to commercialize and operate an AI model as a service than to develop one. In fact, research shows that 80% of developed models are abandoned.※ Source: https://www.roboticsbusinessreview.com/ai/almost-80-of-ai-and-mlprojects-have-stalled-survey-says/
The biggest reason for this result lies in the fact that AI models are susceptible to data changes. Algorithm studies on AI models use a fixed range of refined data, whereas data provided for AI service operation has potential changes in patterns from external environments or is possibly of lower quality than the research data. Therefore, actual data should be collected to train and tune AI models on a large scale, prior to applying developed AI models to operating services. In addition, it is desirable to improve the AI models by monitoring their performances and reflecting the accumulated user data. Efficient data management and infrastructure management are essential for large-scale computing (CPU/GPU and memory) and the use of storage resources when dealing with massive data. Meanwhile, it is also recommended to be able to support various machine learning (ML) programming languages and tools for model development.
What should be considered when developing and operating AI services?
There are more things to consider for AI service development and operation other than securing AI models with good performance. Other things to consider include securing fast inference or explainability (the possibility of explaining or interpreting decisions by the model) of a given model. In the process, the link of all processes from data collection → model development and experiment → model training and optimization → deployment and operation are highly important. Therefore, organic communication and collaboration among related departments are essential. However, data scientists who lead model development are not well-versed in infrastructure management or SW development, while ML engineers driving the IT operation of the AI services have a hard time understanding AI models.
In addition, collaboration across multiple departments, including data engineers and business product owners operating services, is required, but in reality, it is difficult to discuss R&R and unfamiliar tasks every time there is a new development, release, or update.
Why do we need MLOps?
MLOps is a technology that was introduced to resolve such issues. MLOps is a production engineering technology needed in the stage of commercializing AI services after the pilot stage. MLOps has gained a lot of attention lately along with the widespread adoption of AI. The technology applies DevOps principles to ML, aiming to integrate ML system development (Dev) and operations (Ops). It is the culture of ML engineering and includes all of the standard procedures and tools. Adopting MLOps helps easily test and develop models. It provides development environments and computing resources, links and performs all stages from model training/optimization, model evaluation/verification, model deployment/operation, to infrastructure management with pipelines, and monitors the process.
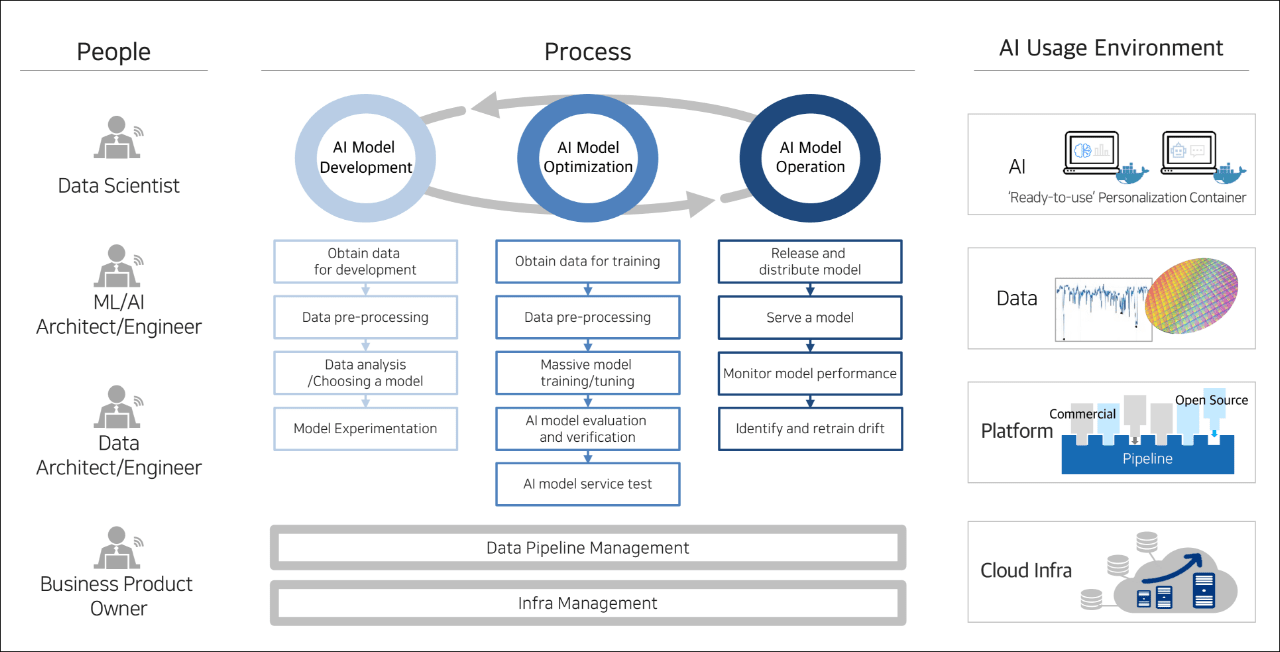
- Data Scientist
- ML/AI Architect/Engineer
- Data Architect/Engineer
- Business Product Owner
A three-step circular diagram: AI model development, AI model optimization, and AI model operation
- Securing data for development
- Data preprocessing
- Data analysis/model selection
- Model experiment
- Securing data for training
- Data preprocessing
- Large-scale model training/tuning
- AI model evaluation and verification
- AI model service test
- Model release and deployment
- Model serving
- Model performance monitoring
- Drift detection and retraining
Data pipeline management
Infrastructure management
- AI 'Ready-to-use' personalization container
- Data
- Platform
- Cloud infrastructure
Why is it urgent to introduce MLOps in the AI field?
Currently, it is urgent to introduce MLOps in the field of AI because of the lack of professionals, which is one of the biggest issues in the field. It provides an environment where data scientists can focus on their main task of model development, by reducing additional work, while ML engineers can be supported in an environment where they can continuously relearn operating models and manage their performance. Therefore, providing a stable infrastructure and automation system is one of the main objectives of MLOps introduction.
※ Source: https://cloud.google.com/architecture/mlops-continuous-delivery-andautomation-pipelines-in-machine-learning
Gartner predicts the MLOps market will grow to around USD 4 billion by 2025. It also expects 50% of companies to adopt AI platforms by 2025. It predicts 50% of those would use open source along with commercial solutions. At this time, we will discuss building and adopting an AI platform based on MLOps using Kubeflow, the leading open source for MLOps.
What is Kubeflow (Kubernetes + ML flow)?
Kubeflow is a Kubernetes-based MLOps open-source platform introduced by Google that has expertise in AI development. It enables users to deal with the complicated ML workflow of model development, training, deployment, and operation in a simple, portable, and scalable way. Since the initial release of Kubeflow v1.0 in March 2018, the open-source project that started off with three people has grown into a project involving more than 200 developers from top global companies, including Ant Group, AWS, Baidu, Bloomberg, Canonical, Cisco, Google, IBM/RedHat, Microsoft, and Nvidia. The open-source ecosystem is rapidly expanding. In order to use open source at a production level, not only the product readiness level, but the user community activity of the open source have to be considered. Kubeflow fulfills them both. The latest version, v1.3, was released in April 2021, and v1.4 is expected to be released soon.
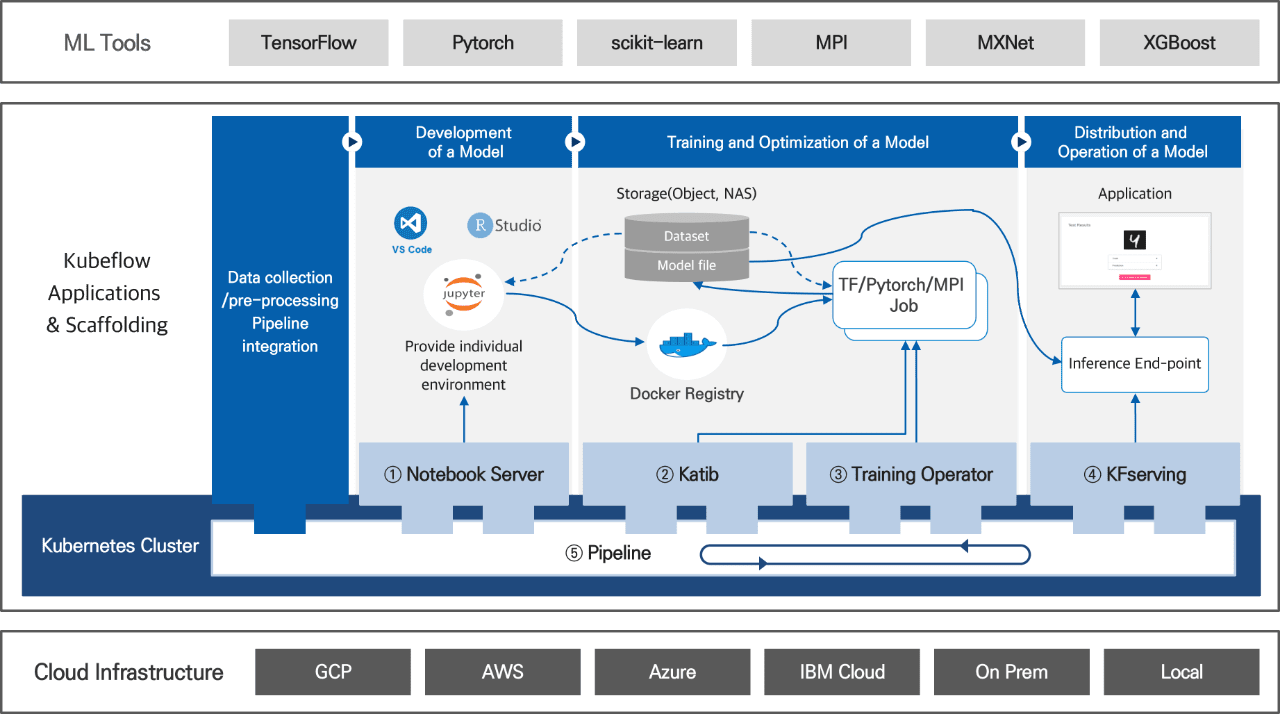
- ML Tools
- TensorFlow
- Pytorch
- scikiy-learn
- MPI
- MXNet
- XGBoost
| Kubeflow Applications and Scaffolding | Pipeline link between data collection and preprocessing | Model development | model training and optimization | and model deployment and operation |
|
Storage (object, NAS)
Docker Registry TF/Pytorch/MPI Job |
Application Inference endpoint |
||
| 1.Notebook Server | 2.Katib, 3Training Operator | 4. KFserving | ||
| Kubernetes Cluster | Pipeline | |||
- Cloud Infrastructure
- GCP
- AWS
- Azure
- IBM Cloud
- On Prem
- Local
Main characteristics of Kubeflow
Kubeflow provides various programming languages and tools of the ML open-source ecosystem, including TensorFlow and PyTorch.
Kubeflow offers an optimal combination of open-source technologies for each ML domain to meet various user requirements. It supports various programming languages and tools of the ML open-source ecosystem, including TensorFlow and PyTorch. It also provides major ML workflow tools along with Notebook Server for ML development, Katib, the hyperparameter tuning tool, Training Operator for distributed training, and KFServing, the model serving tool for inference. A powerful pipeline tool that connects, carries out, and monitors the entire ML workflow; helps automate the workflow; increases productivity; and serves to ensure collaboration between related departments. Each element of the pipeline here is based on containers. Lightweight, efficient, and composable containers enable flexible pipeline configuration by reusing each element of pipelines. Using these pipelines enables building an E2E AI platform by connecting big data lakes and company’s data management system and implementing operations including data collection, model development, training, and deployment.
Kubeflow offers a large-scale distributed cluster environment for massive computation.
Moreover, Kubeflow offers a large-scale distributed cluster environment based on Kubernetes for massive data processing and computation of AI models. It dynamically allocates computing (CPU/GPU) and storage resources on demand, and it also ensures scalability and availability based on auto recovery through auto-scaling. In addition, Kubeflow offers Job Operator for easy distribution work and effective resource management and scheduling for this. Kubeflow primarily secures optimal individual development environments and portability. Individual development environments being developed simultaneously on the platform are logically separated from other development environments, allowing AI developers to focus on model development only, without concern for other environments. The development environment is deployable as an operating environment itself, and the same development environment is available without depending on cloud providers. It also offers authentication and permission management for the resources, as well as multitenancy.
What are the components of a Kubeflow-based AI platform?
As shown in the below diagram, a Kubeflow-based AI platform consists of three components:
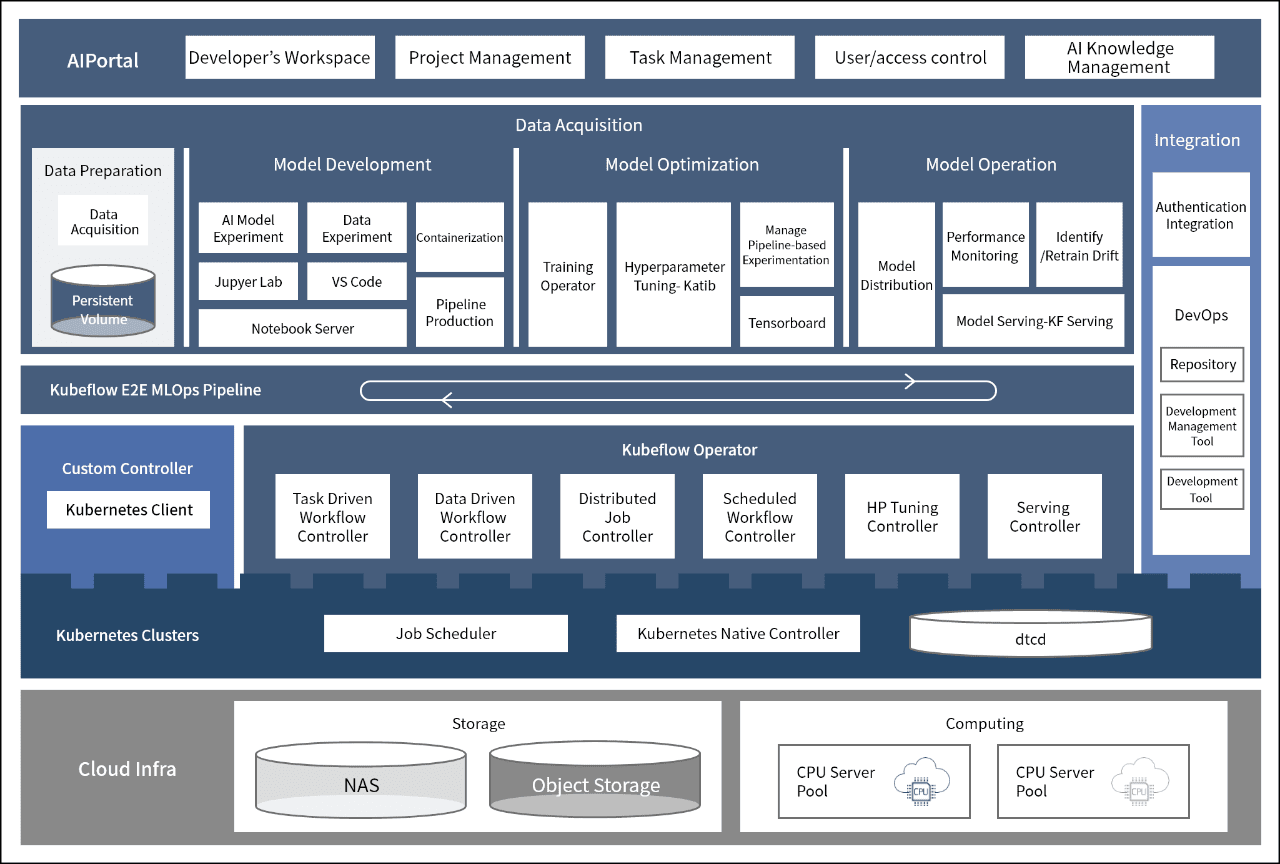
- AIPortal
- Developer workspace
- Project management
- Work management
- User/Permission management
- AI knowledge management
| Kubeflow-based MLOps |
Link
Link authentication
|
|||||||||
|
Data preparation Date acquisition Perststent Volume |
Model development | Model optimization | Model operation | |||||||
| AI Model Experiment | Data Experiment | Containerization | Distributed training-based training experiment management operator | Hyperparameter - Katib | pipeline tuning | Model deployment | performance monitoring | drift detection/retraining, model serving | ||
| Jupyer Lab | VS Code | |||||||||
| Notebook Server | , pipeline production | Tensorboard | model serving - KF Serving | |||||||
| Kubeflow E2E MLOps Pipeline | ||||||||||
| Custom Controller | Kubeflow Operator | |||||||||
| Task Driven WorkFlow Controller | Data Driven Workflow Controller | Distributed Job Controller | Scheduled WorkFlow Controller | HP Tuning Controller | Serving Controller | |||||
| Kubernetes Clusters | Job Scheduler | Kubernetes Native Controller | dtcd | |||||||
- Cloud infra
-
Storage
- NAS
- Object Storage
-
Computing
- CPU server pool
- CPU server pool
ML Tools
This is software designed for ML model development, offering support for both development tools for deep learning (DL) models, such as TensorFlow and PyTorch, as well as conventional ML model tools, like scikit-learn. It is expected to be able to provide more ML tools in the future since it is a plugin.
Kubeflow Applications and Scaffolding
Kubeflow applications and scaffolding are designed to handle a complex ML workflow. In order to ensure smooth ML model development and operation, it is divided so that it caters to general user interactions and provides better performance of major features of Kubeflow, including logging, monitoring, and authentication.
Notebook Server
This is a tool that offers the Python-based Jupyter Notebook/Jupyter Lab running on Kubernetes, to help data scientists perform data preprocessing and model development with Notebooks. VSCode and RStudio are additionally supported for v1.3 and above.
Katib
Katib is a Kubernetes-based AutoML tool that consists of hyperparameter tuning and neural architecture search. For hyperparameters, users are required to input variables that control the model training process, and Katib finds the best values for users. Neural architecture search is used to design artificial neural networks.
Training Operator
Training operator helps perform and monitor large-scale distributed training efficiently when training models. Currently, Kubeflow supports TensorFlow, PyTorch, MPI, MXNet, XGBoost, etc.
KFServing
Model serving refers to deploying models for inference using ML models in applications. Kubeflow offers KFServing as a default serving tool, but it also offers various tools, including Seldon Core, TensorFlow Serving, Nvidia Triton Inference Server, and BentoML.
Pipeline
It is one of the key tools of Kubeflow that allows you to create and deploy a pipeline that is a container-based E2E ML workflow. When you execute the pipeline, it dynamically allocates the necessary resources for each step. Spotify has reported that their data scientists’ productivity increased by 700% by adopting pipelines in December 2019.
Source: https://engineering.atspotify.com/2019/12/13/the-winding-road-tobetter-machine-learning-infrastructure-through-tensorflow-extended-andkubeflow
Cloud Infrastructure
As a component that offers computing (CPU/GPU), networking, and storage resources for ML workload, Kubeflow can be installed in any environment where Kubernetes is running (public cloud, on-premise, and local).

Kubeflow implementation cases and lessons-learned
What are the status and advantages of Samsung SDS's AI development platform?
Samsung SDS has built a Kubeflow-based AI development platform, focusing on stages of model development and optimization. The platform has been used to develop AI models that can be used as product features. Based on the assets and research results obtained from this experience, we are currently building and improving the Samsung Cloud Platform's (SCP) AI platform. At the same time, a project to build an on-premise AI platform for customers is also ongoing.
The stages of AI model development and model optimization have different objectives and levels of resource usage.
The model development stage and model optimization stage have different objectives and resource usage. This leads to different considerations when building a platform. Model development is a stage for securing high-performance models with the goal of allocating small exclusive resources to each project while providing an environment that data scientists can easily use. On the other hand, model optimization is a stage that applies the models to a production environment after model development. It performs large-scale training and tuning, which makes efficient management and scheduling over large-scale, shared resources important.
The infrastructure is based on SDS Kubernetes PaaS with the latest GPU of Nvidia, A100, to secure a GPU cluster. NAS and object storage utilize SDS Cloud’s products. If the GPU driver and CUDA version are not compatible, the GPU is not recognized and the AI model is not executable, so we tested and installed the optimal version of the GPU driver and CUDA library for the A100 on all the nodes in GPU clusters. The model development stage is built based on Kubernetes’ Notebook Server, and the difference is that data scientists can easily create a Notebook through Kubeflow's Notebook Server, without having to configure its development environment by themselves. Resources (CPU, GPU, memory, and storage) can be allocated on demand. The container image for the Notebook is selectable when creating a Notebook, so the standard development environment of the company, programming language, etc. can be provided as container images. On top of that, personalized development environments are offered as well.
When building Samsung SDS AI platforms, container images of CPU and GPU for TensorFlow and PyTorch are provided as a standard development environment for the company. For the GPU container images, pre-tests on multi-GPU distributed training, as well as single GPU training, were conducted. AI development environments that have gone through these processes reduce the time for data scientists. Building an AI development environment, which previously took more than a week, now takes only two to three minutes. The Samsung SDS platform offers an environment where data scientists can easily develop models using Notebooks, allowing them to create and manage Custom container images, etc. through the AI Portal. That is, you can enjoy additional conveniences that are not offered by Kubeflow. Moreover, quotas are allocated for each AI model development project so that project members can automatically utilize resources within a quota. In the optimization stage, the resource-sharing tool is secured mainly with Kubeflow Training Operator and Katib to build the platform. Training Operator helps perform large-scale distributed training effectively and monitor the progress when training the developed models.
Meanwhile, distributed training in ML requires detailed resource management. For example, all individual work should be run simultaneously while waiting until the required resources for the entire work are secured for successful distributed training. To that end, Volcano, the open-source Job Scheduler, was adopted in v1.3 and above. With Volcano Scheduler, you can expect the following performance and efficiency:
Determines the order of work according to priorities, such as creation time, priority class, etc. (FIFO, priority)
Minimizes network bottlenecks by allocating individual work from the same distributed training to a single GPU node. (Bin-packing)
How can you effectively use Volcano Scheduler?
There is a special technique for effectively utilizing Volcano Scheduler. That is to find an appropriate combination of resource queues and scheduling policies from the Scheduler, such as gang, bin-packing, etc. The resource queue refers to a bundle of resources to be managed. Each queue can determine its own scheduling policies and the configuration of the resource queue directly affects the use of all resources of the platform and work efficiency. The model training code should be created as a container image to use Training Operator and Katib from Kubeflow. Kubeflow supports this via a tool called Fairing.
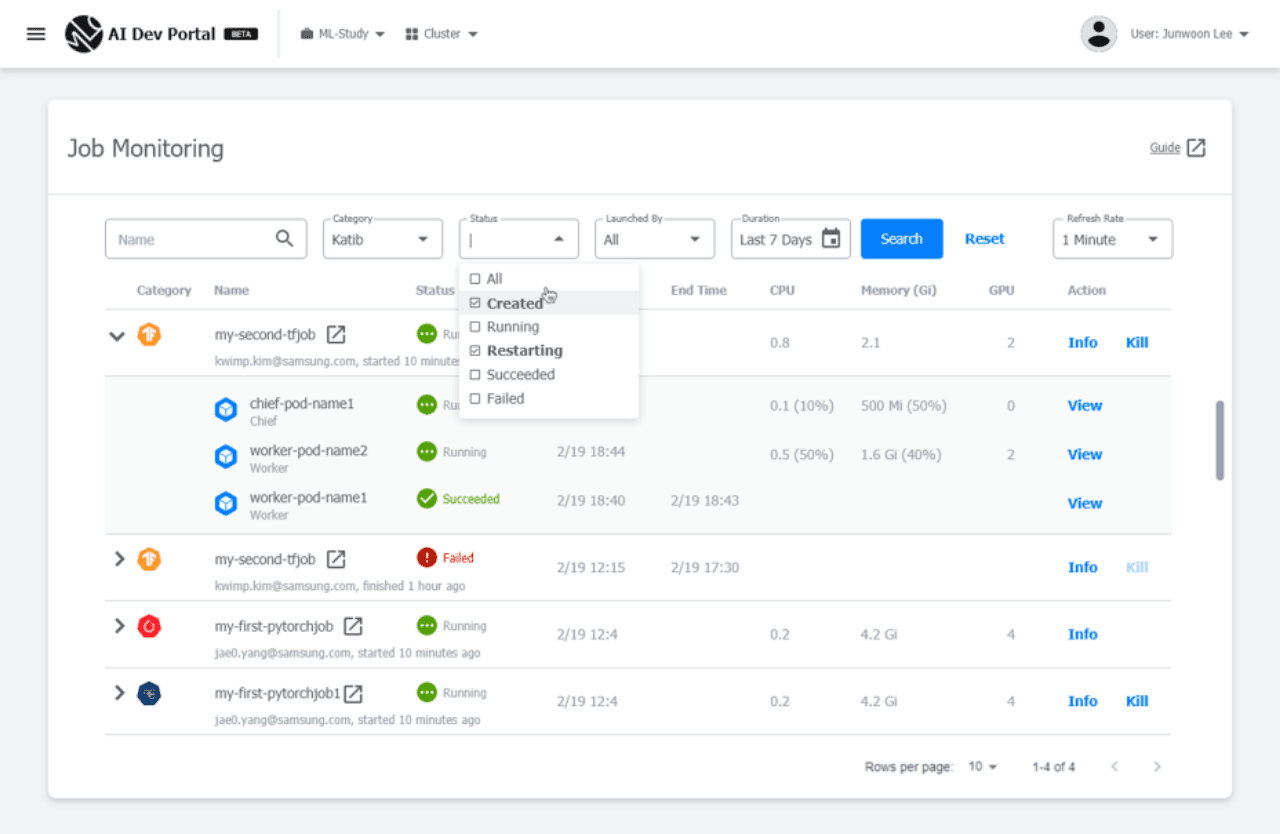
Special features of the Samsung SDS AI platform
The Samsung SDS platform has added a feature that helps data scientists easily carry out training and hyperparameter tuning with the Notebook images themselves. Because it is common for data scientists to install extra libraries and tools for model development with Notebooks. Meanwhile, Training Operator makes it relatively easy to manage distributed training work, but it is still hard for data scientists to do the work themselves. To improve this, we provide a UI for running distributed training work and an integrated monitoring UI that monitors the overall status of Training Operator, Katib, and Notebooks. At this point, administrators can find the work that causes bottlenecks and arbitrarily stop progress.
There is a lot more to talk about, but due to the restrictions of the paper, let me finish the article by pointing out the importance of the pipeline.
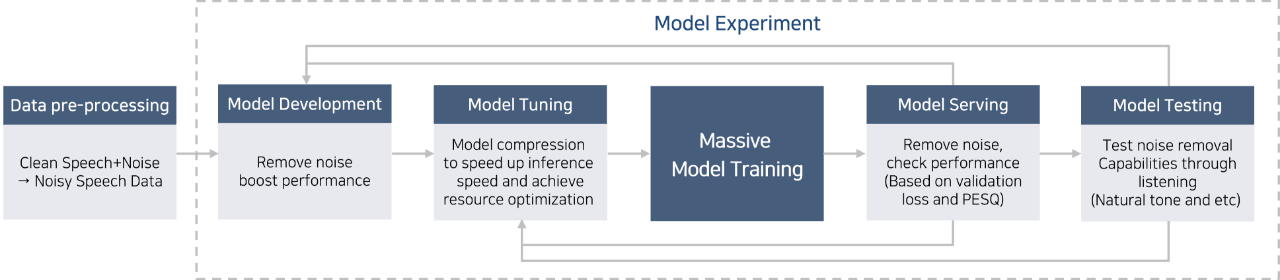
-
Data preprocessing
Clean speech + noise, Noisy speech data
-
Model development
Securing noise-canceling performance
-
Model tuning
Lightening for securing inference speed and resource optimization
- Large-scale model training
-
Model serving
Noise-canceling and performance validation (based on validation loss and PESQ)
-
Model test
Checking noise-canceling performance through actual listening (naturalness of speech, etc.)
The importance of Kubeflow pipelines
I have been involved in the development of AI models for noise-canceling, in addition to the project of building an AI platform based on MLOps, since the second half of last year. Model development for production applications is an infinite, repetitive process. In the model development stage, model experiments with the dataset combination according to multiple noise-canceling algorithm candidates and size, level of sound reverberation, etc. are repeatedly carried out. The one with the best noise-canceling performance among the models becomes a candidate for production. However, noise-canceling models will be used for mobile phones or PCs, which means inference speed for production and usage of the resources for inference are highly important. That is, models whose inference speed is fast with small resource usage are chosen, even if their performance is not as good. A variety of model lightening techniques are used to derive candidate models, and the final model is selected through model performance verification.
As the ones who provide the model, we check its performance with quantitative values, such as *validation loss or *PEsQ. But when actually using the model, it is finalized by listening to it to check performance with quantitative values, such as the side effects of noise-canceling, naturalness of speech, etc.
It is obvious that productivity will decrease when manually running model experiment management, such as model candidates, related datasets, and test results. Kubeflow helps perform model experiments automatically and manage the model experiment with a pipeline tool. Although productivity was not measured in the Samsung SDS build case, as mentioned above, Spotify has significantly improved productivity by as much as 700% after adopting Kubeflow Pipelines. Domestically, Karrot has also adopted and used Kubeflow pipelines effectively. However, using Kubeflow Pipeline requires somewhat difficult work for users to create a pipeline, such as preparing the elements of each pipeline stage as container images and configuring required resources in each stage separately. Therefore, Samsung SDS has been improving features that allow users to make Kubeflow pipelines more easily.
* Values measuring model performance using the dataset for verification instead of one for training
* Perceptual evaluation of speech quality
How Samsung SDS effectively supports ML E2E workflows
As shown above, Samsung SDS effectively supports the execution of complex ML E2E workflows, including model development, training, deployment, and operation, by offering the Kubeflow-based MLOps platform. We are also constantly trying to support user-friendly AI development at an enterprise level for users and data scientists.
- How Samsung SDS effectively supports ML E2E workflows
- As shown above, Samsung SDS effectively supports the execution of complex ML E2E workflows, including model development, training, deployment, and operation, by offering the Kubeflow-based MLOps platform. We are also constantly trying to support user-friendly AI development at an enterprise level for users and data scientists.