

This article discusses various stages of autonomous driving and explores Computer Vision aspects of it in detail. Semantic segmentation is the partition of an image into coherent parts. Instance segmentation is Semantic Segmentation with the addition of identification of each unique entity in the image.
Instance Segmentation
 Fig 1. Instance segmentation visual description. Various instances of class = 'car' are identified as unique entities.
Fig 1. Instance segmentation visual description. Various instances of class = 'car' are identified as unique entities.(Source: Berkeley DeepDrive dataset)
The most challenging task in Computer Vision, which is very relevant for self-driving technology, is the localization and classification of various objects in a scene (e.g. car, bus, truck, person, traffic lights, signs). It is a challenge to classify and track unique entities (e.g. person 1, person 2, car 1, car 2). For various stages in autonomous driving pipeline, such information is very valuable. Autonomous driving systems need to understand what various entities in a scene are (Instance Segmentation) and where they are in order to find best possible path.
Autonomous Driving
As shown in Fig 2, autonomous driving consists of following stages in a pipeline.
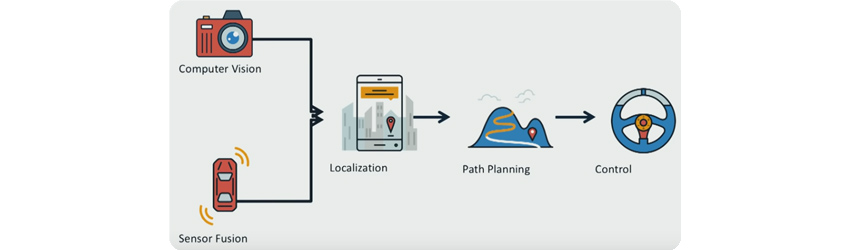 Fig 2. Autonomous Driving pipeline
Fig 2. Autonomous Driving pipeline
1) Perception
It is necessary to develop rich understanding of the environment. In autonomous driving, this is called Perception.
- Computer Vision: Traditionally, this has been the most difficult problem due to complexity arising in natural scenes. Due to recent advances in Convolutional Neural Networks (CNNs), there has been significant progress in this area.
- Sensor fusion: This is the step of augmenting visual data with data from sensors such as:
- RADAR: Radar generates signals about movements of objects but cannot classify objects. Typically, Radar costs are on the order of few hundreds of dollars.
- LiDAR: LiDAR generates 3D point clouds. It is very useful for various stages in self-driving pipeline. Typical costs are in the tens of thousands of dollars.
- Ultra-sonic sensors: These use sound waves instead of light waves to generate object movement signals. These are not as reliable as RADAR but cheaper to manufacture.
Perception is followed by Localization, Path Planning, and Control stages.
2) Localization
Localization involves the task of determining positions within an environment. Using high definition maps, the software localizes the precise location of the vehicle using Simultaneous Localization And Mapping (SLAM) algorithms.
3) Path Planning
Path Planning figures out best path in a dynamically changing environment. A method is to find a path that maximizes distances from surrounding objects. Various Multi-Model (MM) algorithms are used (e.g. autonomous multiple-model, generalized pseudo-Bayesian algorithms).
4) Control
Control is the final stage which generates mechanical maneuvers to update car controls (braking, acceleration, steering, etc.). Control executes actions as found by the Path Planner.
Computer Vision using Deep Learning
Deep means many stacked layers of CNNs. It is shown empirically that the deeper the network, the more learning capacity it has for understanding complicated scenes, such as urban driving.
Instance Segmentation Techniques
One of most difficult tasks in Computer Vision is Instance Segmentation which is relevant to Autonomous Driving.
There are several schemes to perform Instance Segmentation and this is an active area of research. The most popular methods in use are:
• Mask RCNN ( link )
• Path Aggregation Network for Instance Segmentation ( link )
• Non-local Neural Networks ( link )
As shown in Fig 3, from the Mask RCNN paper, describes an example architecture where segmentation masks are generated for every possible instance (Region of Interest or 'RoI'). A segmentation mask for an instance is basically a binary mask with 1s at pixel locations corresponding to an instance and 0s otherwise.
 Fig 3. Architecture of Mask RCNN for instance segmentation.
Fig 3. Architecture of Mask RCNN for instance segmentation. (Source: Mask RCNN paper on arXiv)
Learning process
The most of the popular algorithms (neural networks in this case) learn via supervision, where raw images and binary masks for each instance of interest are shown to the network during training time. For example, in the TensorFlow Object Detection API, along with raw images, a list of binary masks, a list of corresponding bounding boxes (BBs), and a corresponding list of classification IDs form the training set, as shown below pictorially.
 Fig 4. Learning process for Instance Segmentation
Fig 4. Learning process for Instance Segmentation
A successful outcome of the learning process is a well-trained model, evaluated on certain metrics. For Instance Segmentation tasks, Average Precision (AP) is commonly used. The AP is the integrated area under the Precision-Recall curve, which, in turn, is constructed by varying the Intersection-over-Union (IoU) threshold for binary mask pairs (Ground Truth, Predicted Mask). The following is an illustration of the evaluation metrics presented by TensorBoard.
![Performance metrics for Instance Segmentation as seen in TensorBoard(a visualization tool from Google). / validation_metrics/AP@0.6 & Precision at IOU CASE : 259.5.0k 0.722, 261.8k 0.7145, 263.0k 0.715, 264.5k 0.726, 266.5k 0.7217, 268.5k 0.7225, 269.5k 0.7245, 273.0k 0.7145 / validation_metrics/AP@0.75 & Precision at IOU=0.75 CASE : 259.5k 0.5825, 263.0k 0.560, 264.8k 0.571, 266.5k 0.572, 269.8k 0.588, 273.0k 0.561 / validation_metrics/AP@[0.50:0.95] & Average Precision at itegrated area between IOU=[0.5,0.95] CASE : 259.5k 0.511, 261.5k 0.508, 263.2k 0.5077, 264.5k 0.5145, 268.0k 0.517, 269.9k 0.516, 271.5k 0.518, 273.0k 0.5038](https://image.samsungsds.com/en/insights/autodriving_img05.jpg?queryString=20250410013411) Fig 5. Performance metrics for Instance Segmentation as seen in TensorBoard(a visualization tool from Google).
Fig 5. Performance metrics for Instance Segmentation as seen in TensorBoard(a visualization tool from Google).
After a successful learning process, the model can simply be presented a raw image and, from that raw image, generate a set of binary masks, along with a corresponding set of class labels and bounding boxes, where one mask is generated for each Region of Interest (illustrated below).
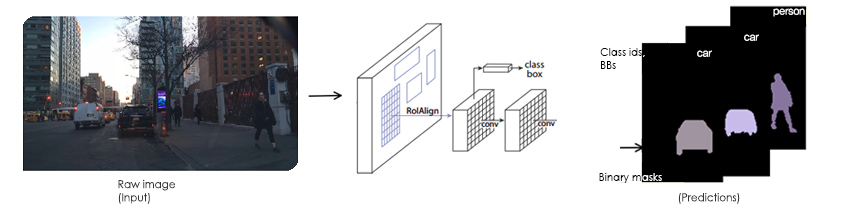 Fig 6. Instance Segmentation training example
Fig 6. Instance Segmentation training example
Following illustration shows the result of a trained model applying Instance Segmentation to an arbitrary urban driving scene.
 Fig 7. Output example from a model trained for Instance Segmentation task
Fig 7. Output example from a model trained for Instance Segmentation task
Brightics Deep Learning (SBrain)
This article discussed the autonomous driving pipeline with a focus on the Computer Vision aspects of it. Although much effort has gone into the algorithmic side of Computer Vision, training Deep Convolutional Neural Networks remains a big challenge due to computational demands of training large, complex networks. Most of high performing networks have from hundreds of millions to a few billions parameters. It takes an enormous amount of computational resources to train these parameters. Further, the sample complexity of these algorithms require a large amounts of data, on the order of millions of images, in order to achieve acceptable performance.
Brightics Deep Learning platform is the perfect tool to perform instance segmentation training tasks in a distributed manner. It provides the best of Deep Learning (Distributed Keras and Distributed Tensorflow), accessible through a familiar Jupyter environment and does not require any low-level programming of Docker, Kubernetes and Cluster programming. In addition, tasks like sensor fusion are achieved on a cluster with underlying Apache Spark technology, without any spark programming knowledge.
Brightics Deep Learning platform provides AI Governance, GPU Consolidation, Distributed Data Transformation, Automated Experiments with Hyper-Parameter Search, Distributed Inference in a Jupyter Notebook Environment familiar to Data Scientists.
▶ The contents are protected by copyrights laws and the copyrights are owned by the creator.
▶ Re-use or reproduction as well as commercial use of the contents without prior consent is strictly prohibited.
- #Brightics
- #DeepLearning
- #Platform
- #AutomatedDriving
- #AI
- #ComputerVision
- #SLAM
- #Jupyter
- #ApacheSpark
- #SamsungSDS
- #InstanceSegmentation
- #Semanticsegmentation

Yogesh develops AI applications and systems with particular focus on large scale Deep Learning tasks.
In past, he worked on developing and deploying large scale Machine Learning systems for Bitcoin and Ethereum blockchain analytics solutions.
- The Rise of Generative Enterprises: Reshaping the Future of Business With Generative Technologies
- ESG Framework for Sustainable AI Business
- B2B Companies Transforming Into 'Generative AI-Centered'
- The Future of AI as a Service (AIaaS)
- Global Trends and Implications in AI Risk Management
- Copilot: The Key to Hyperautomation