
Unlike other mammals, humans have established civilization, used tools, and made scientific achievements thanks to several differentiating features. The first is language. Humans communicate with one another and create records using language, thus accumulating knowledge. The second is the human brain’s capacity to accept and understand various visual information. The third is our ability to integrate knowledge, combining various senses and memories -- including smell, taste, and the sense of pain.
For instance, suppose a baby eats an apple for the first time. Even before understanding the word apple, the baby tastes it and experiences its shape, color, size, sweetness, sourness, and the generally smooth but sometimes rough texture. Then he/she learns that there are different kinds of apples – green, unripe, ripe, rotten, or bruised. When the baby starts to learn a language at the age of three or four, he/she integrates all the information and stores the concept in the brain. The exceptional intellectual ability of humans comes from our capacity to integrate various senses and memories.
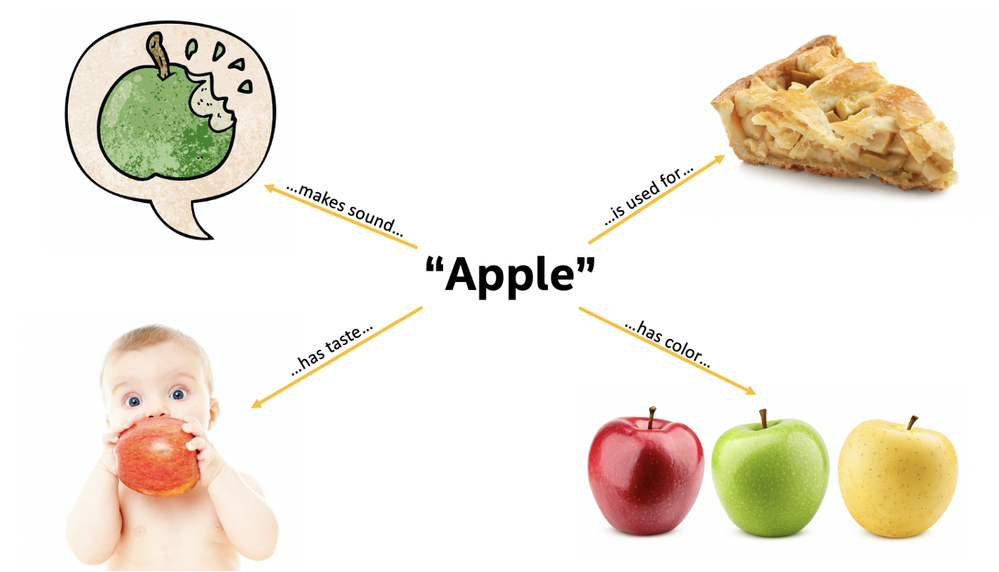
In order to understand the concept of the apple, humans integrated various types of information, including vision, taste, touch, and text.
How Does AI Understand the Apple?
Multimodality was developed based on the idea that AI needs to learn the same way humans do to communicate with them. The word modality refers to a particular mode in which something exists or is experienced. The word modality was already used about ten years ago before AI emerged: unimodality and multimodality. The former refers to a simplified and unified way of displaying or entering user information, as designed by web developers or UI designers. The latter refers to using multi-channels such as a mouse, a keyboard, a screen, and a mic. However, nowadays, multimodal is more about exchanging information through various interfaces, including vision and hearing. AI that learns and thinks by accepting such multi-channel modality is called multimodal AI. In other words, AI learns in the same way humans understand objects in several ways.
Traditional AI vs. Multimodal AI
Traditional AI has focused on understanding text or natural language. The largest amount of data created by humankind is written text. People believed that natural language processing (NLP) to understand human language is a precondition for making propositions and inferences. They believed that AI could generate an answer only after understanding questions asked by humans. However, a problem arises here. AI doesn’t really understand what a particular word means or what it looks like in the real world. For example, in the sentence “a man is riding a horse,” AI does not understand the concept of “riding” and has no idea about the horse’s size or how to ride it. In other words, AI can process data, gather statistics, search and display text, but cannot think like humans. In this regard, the emergence of multimodal AI was essential for AI to perceive our world properly.
DALL-E 2 developed by OpenAI is the most well-known multimodal AI model. It was created using multimodal AI to help understand how AI systems perceive the world. Once you enter a sentence, DALL-E 2 shows you a photo or image that suits the sentence, showing how it understood the sentence. DALL-E 2 divides an image into objects, names them, and then identifies their location, color, and gesture. And DALL-E 2 learns the relationship between images and the text used to describe them.
Simply put, DALL-E 2 learns the countless images of astronauts, cats, and basketballs and understands how they look. Then the model can identify them in any image. In addition, DALL-E 2 learns how astronauts take spacewalks, how cats move, and how basketballs are drawn, so it understands how to utilize objects. If a user asks DALL-E 2 to create an image of “playing basketball with a cat in space,” it generates the images seen below. It can even customize the drawing style, whether it be Monet-like impressionism, Andy Warhol pop art, or a children’s book illustration. The following created by DALL-E 2 resemble children’s book illustrations.
 Once a user enters “playing basketball with a cat in space,” DALL-E 2 generates images like these. (Source: OpenAI)
Once a user enters “playing basketball with a cat in space,” DALL-E 2 generates images like these. (Source: OpenAI)
What Will Change in the Era of Multimodal AI?
In Korea, LG AI Research released EXAONE, which converts text into images. EXAONE is a multimodal AI that works both ways. It can also convert an image into text. WebQA, developed by Intel and Carnegie Mellon University, learns online data and images and answers user questions. For instance, if a user asks what color the ring around the eye of a certain bird species is, WebQA will answer red.

As of now, EXAONE is used to generate and search images. It is currently accumulating knowledge by utilizing a diffusion model whereby AI learns from relations among texts, images, and objects.
When multimodal AI is widely used, it will dramatically change the use of AI, which has only focused on text or images. Most of the AI provided in the example above simply analyzes the natural language spoken by a person to understand the information that the person is trying to find. However, with multimodal AI, if someone sends a photo of a vehicle that is damaged in the front, multimodal AI searches the insurance product that the vehicle owner purchased for the car, predicts the degree of damage caused, and helps the insurance company and customer in reporting and handling the accident. Likewise, multimodal AI can smartly make clearer decisions by accurately understanding situations.
Things that were only possible in a spy movie -- analyzing images of terrorists and locating them using CCTVs in real time -- will become a reality. The auto industry can utilize multimodal AI to combine various information, such as speed, lane violations, driver’s condition, and weather, for autonomous driving. Multimodal AI is expected to play a crucial part in remote medical services or diagnosing early-phase diseases that humans cannot identify visually. Multimodal AI can recognize the world the same way humans do and even analyze situations more sharply and accurately.
Meanwhile, there are concerns related to multimodal AI. The biggest risk in all types of AI is that fake images created by AI, like deepfakes, can be utilized for crimes or generating biased data. Or AI can learn violent images and text, generating undesirable outcomes. In this regard, OpenAI removed violent, hate-related, or adult images from the learning data used in DALL-E 2 and excluded images of individuals, including public figures. Because of this, if you look at the images generated by DALL-E 2, you can see that human faces look slightly unnatural.
In the era of AI, regulatory measures will be needed to hold AI responsible for what it does, just like humans.
.jpg?queryString=20250410013411)
- The Rise of Generative Enterprises: Reshaping the Future of Business With Generative Technologies
- ESG Framework for Sustainable AI Business
- B2B Companies Transforming Into 'Generative AI-Centered'
- The Future of AI as a Service (AIaaS)
- Global Trends and Implications in AI Risk Management
- Copilot: The Key to Hyperautomation