[IT에 한 걸음 더 다가가기] SMAC의 분석 부문, 지능화를 지향하는 Machine Learning (1편)

현재 스맥(SMAC) 기술을 주제로 연재가 되고 있는데, 첫 번째는 스맥(SMAC)의 서비스 및 솔루션을 Agile하게 개발 가능토록 해주고 ‘획기적으로 구축 비용을 절감해주는 오픈소스SW’ 기술이었고 [관련 기사 바로 가기 : IT 미래를 혁신할 오픈소스SW, 그것이 알고 싶다! (1편)], 두 번째는 ‘SMAC의 대량 데이터 처리를 위한 DBMS기술’ 이었습니다. [관련 기사 바로 가기 : SMAC의 대량 데이터 처리를 위한 DBMS기술! (1편)] 드디어 세 번째로 다룰 주제는 ‘SMAC의 분석 부문, 지능화를 지향하는 머신러닝(Machine Learning)’입니다.
SMAC의 ‘A’는 Analytics의 첫 글자인데, 최근의 대표적인 Analytics 기술이 무엇인지 물어보면 어느 누구라도 ‘딥러닝(Deep Learning)’을 이야기할 것입니다. 이렇듯 딥러닝이 국내에서 대중 매체를 통해 일반인들에게까지 알려지기 시작한 것은 대략 2013년부터이며 최근에는 거의 매일 같이 딥러닝 기사들이 쏟아져 나오고 있습니다.
대중 매체에서 이처럼 뜨겁게 회자되는 딥러닝의 정보들이 너무 학문 위주라 이해하기 어렵다거나 지나치게 동향/사례 위주의 접근이라 피상적으로 느껴지지는 않으셨나요? 그 이유는 딥러닝의 근저에 깔려 있는 인공 신경망과 머신러닝에 대한 이해가 부족하기 때문일 것입니다. 그래서 딥러닝 자체보다는 기전에 있는 개념들을 가능한 쉽게 살펴보고자 합니다.
☞ 제 1화 : 각광받는 딥러닝의 근원, 인공신경망 (Artificial Neural Network)
제 2화 : 인공신경망의 본류인 머신러닝(Machine Learning,기계학습)
제 3화 : 머신러닝 매커니즘 및 유형
제 4화 : 다양한 머신러닝 알고리즘
제 5화 : 머신러닝의 응용 분야 및 적용 사례

2006년 사이언스에 발표된 토론토 대학의 Hinton 교수의 논문 이후로 활발하게 관심받기 시작한 딥러닝(Deep Learning)은 Deep neural network, Convolutional neural network, recurrent neural network 등 다양한 알고리즘들이 등장하게 됩니다. 딥러닝(Deep Learning)은 MIT에서 선정한 2013년을 빛낼 10대 혁신기술 중 하나이자, 가트너가 2014년 세계 IT 시장 10대 주요 기술로 예측하면서 빅데이터 분석을 위한 도구로 뜨거운 각광을 받고 있습니다. 이제 딥러닝은 인공지능 연구자들을 위한 알고리즘에서 벗어나, 딥러닝의 대가들이 글로벌 IT 업체로 옮겨감에 따라 딥러닝을 기반으로 하는 여러 패턴인식 서비스들이 실제 서비스로 실현되고 있습니다.
<글로벌 업체로의 딥러닝 대가들의 이동>
- 제트리 힌튼(Geoffery Hinton) 캐나다 토론토대 교수 → 구글
- 얀 레쿤(Yann LeCun) 뉴욕대 교수 겸 페이스북 인공지능 연구소장
- 앤드류 응(Andrew Ng) 스탠포드대 교수 겸 바이두 연구소 최고과학자
- 요슈아 벤지오(Yoshue Bengio) 캐나다 몬트리올대 교수
딥러닝은 기계 학습의 한 영역으로, 특히 음성/텍스트/이미지 인식 분야에서 획기적인 발전을 거듭하며 급성장하고 있습니다. 기본 원리는 다수의 계층(Layer)을 갖춘 신경망을 통해 컴퓨터가 태스크를 학습하고 정보를 체계화하여 스스로 패턴을 찾아낼 수 있게 하는 것입니다.
깊게 학습한다는 것이 도대체 무슨 말일까? 우선 정의부터 자세하게 살펴볼까 합니다. 딥러닝이란 인간의 신경망(Neural Network) 이론을 이용한 인공신경망(ANN, Artificial Neural Network)의 일종으로, 계층 구조(Layer Structure)로 구성하면서 입력층(Input layer)과 출력층(Output layer) 사이에 하나 이상의 숨겨진 층(Hidden layer)(본 글에서는 중간층이라 지칭함)을 갖고 있는 심층 신경망(DNN, Deep Neural Network)을 지칭하는 기계학습(Machine Learning) 모델 또는 알고리즘의 집합입니다. 한마디로 짧게 이야기하자면 “딥러닝(Deep Learning)은 심층 계층을 가진 인공신경망”이라 할 수 있습니다.
딥러닝의 정의를 가능한 상세히 적다 보니, 처음 듣는 생소한 단어들의 집합으로만 이루어진 듯합니다. 정의만으로는 딥러닝은 어느 별에서 온 것인지? 2006년에 ‘짜잔’하고 새롭게 나온 개념인지 여부도 알기 어려운 상황이라 위의 정의에서 언급한 단어들을 하나씩 풀어서 살펴보겠습니다.
사람의 뇌는 250억 개의 신경세포로 구성되어 있다고 추정됩니다. 뇌는신경세포로 이루어지며, 각각의 신경세포(뉴런, Neuron)는 신경망을 구성하는 신경세포 1개를 지칭합니다. 신경세포는 1개의 세포체(cell body)와 세포체의 돌기인 1개의 축삭(Axon or nurite) 및 보통 여러 개의 수상돌기(dendrite or protoplasmic process)를 포함하고 있습니다. 이러한 신경세포들 간의 정보 교환은 시냅스라고 부르는 신경세포 간의 접합부를 통하여 전달됩니다. 신경세포 하나만 떼어 놓고 보면 매우 단순하지만, 이러한 신경세포들이 모이면 인간의 지능을 지닐 수 있습니다.
수상돌기에서 다른 신경세포들이 보내는 신호를 전달받는 부분(Input)이고 축색돌기는 세포체로부터 아주 길게 뻗어가는 부분으로 다른 신경세포에 신호를 전달하는 부분(Output)입니다.
신경세포들 사이의 신호를 전달해주는 축색돌기와 수상돌기 간을 연결해주는 시냅스라는 연결부가 있는데,신경세포의 신호를 무조건 전달하는 것이 아니라, 신호 강도가 일정한 값(임계치, Threshold) 이상이 되어야 신호를 전달하는 것입니다. 즉, 각 시냅스마다 연결강도가 다를 뿐만 아니라 신호를 전달할지 말지를 결정하게 되는 것입니다.
인공지능의 한 분야인 인공신경망(ANN)은 생물학(통상 인간)의 뇌 구조(신경망)를 모방하여 모델링한 수학적 모델입니다. 즉, 인공신경망은 이러한 생물학적 신경세포의 정보처리 및 전달 과정을 모방하여 구현한 것입니다. 인간의 뇌가 문제를 해결하는 방식과 유사하게 구현한 것으로써 신경망은 각 신경세포가 독립적으로 동작하는 하기 때문에 병렬성이 뛰어납니다. 또한 많은 연결선에 정보가 분산되어 있어서 몇몇 신경세포에 문제가 발생해도 전체에 큰 영향을 주지 않으므로 일정 수준의 오류에 강하고 주어진 환경에 대한 학습 능력을 갖고 있습니다. 1950년대까지 거슬러 올라가는 인공 지능 연구는 신경망의 성공과 실패로 점철되어 왔는데, 인공신경망의 개략적인 주요 시점을 살펴보면 다음과 같습니다.
- 1949년, Hebbian learning
- 1958년, Single layer perceptron
- 1986년, Multilayer perceptron (Back propagation)
- 2006년, Deep neural networks
Deep neural network는 인공신경망의 후손이라 볼 수 있으며, 기존의 한계를 뛰어넘어서 과거에 수많은 인공 지능 기술이 실패를 겪었던 영역에 성공 사례를 거두고 인공신경망의 최신 버전입니다.
생물학적 신경망을 모방하여 인공신경망을 모델링한 내용을 살펴보면 처리 단위(Processing unit) 측면에서는 생물적인 뉴런(neurons)이 노드(nodes)로, 연결성(Connections)은 시냅스(Synapse)가 가중치(weights)로 모델링 되었습니다.
| 생물학적 신경망 | 인공신경망 |
| 세포체 | 노드(Node) |
| 수상돌기(dendrite) | 입력(Input) |
| 축삭(Axon) | 출력(Output) |
| 시냅스 | 가중치(Weight) |
인간 뇌를 기반으로 한 ‘추론 모델’을 모델링한 인공신경망의 주요 특징을 살펴보면, 생물학적인 뇌(인간의 뇌)를 기반으로 모델링 하였고 인간 뇌의 적응성을 활용하여 적응 학습 능력과 병렬구조를 구현하고자 하였습니다. 인공신경망의 모델링을 구조를 매우 단순화하면 아래와 같습니다.
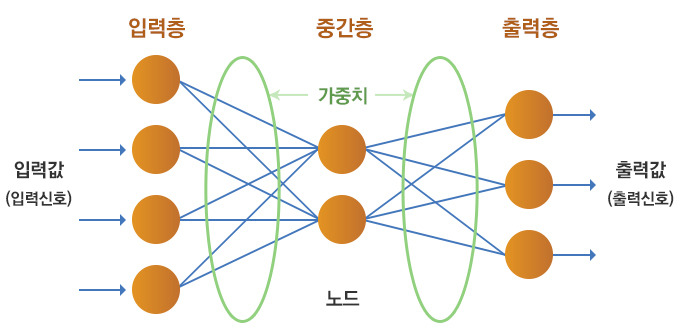
각 노드들은 가중치가 있는 링크들로 연결되어 있고, 전체 모델은 가중치를 반복적으로 조정하면서 학습을 합니다. 가중치는 장기 기억을 위한 기본 수단으로서 각 노드들의 중요도를 표현합니다. 단순화 시켜서 이야기하자면 인공신경망은 이들 가중치를 초기하고 훈련시킬 데이터 셋으로 가중치를 갱신하여 조정하여 전체 모델을 훈련시키는 것입니다. 훈련이 완료된 후에 새로운 입력값이 들어오면 적절한 출력값을 추론해 내게 됩니다. 인공신경망의 학습원리는 경험의 일반화로부터 지능이 형성되는 과정이라고 보면 되고bottom-up 방식으로 이루어지게 됩니다. 위의 그림에서 중간층이 2개 이상(즉 5~10개)일 경우를 층이 깊어진다고 보고 심층신경망(Deep Neural Netowkr)이라 하며, 이러한 심층신경망을 통해서 이루어진 학습과 추론 모델을 딜러닝이라고 지칭합니다.
인공신경망은 입력과 출력을 제외하고 하나의 중간계층(통상적으로 은닉계층, ‘hidden layer’라 지칭함)을 가지고 있어도 어느 정도의 역할을 수행할 수 있지만, 문제의 복잡도가 커지면 노드의 수 또는 계층의 수를 증가시켜야 합니다. 이 중에서 계층의 수를 증가시켜 다층구조 모델을 가져가는 것이 효과적인데, 아래와 같이 효율적인 학습이 불가능하고 네트워크를 학습하기 위한 계산량이 많다는 한계로 인해 활용 범위가 제한적이었습니다.
- 인공신경망 학습에 소요되는 시간이 너무 오래 소요
- 부분최적화(local optima)로 인해 현실적인 사용이 어려움
- 사전 훈련 데이터(Training data set)에 지나치게 맞추어져(over-fitting) 제대로 작동이 안 되는 등의 문제가 발생
이렇게 잊혀 가는 듯한 인공신경망은 다음의 3가지 이유로 다시 재조명 받기 시작했습니다.
◆ 알고리즘의 개선
– 한계점 : 사전학습 데이터에 지나치게 맞추지는(over-fitting) 등의 효과적인 알고리즘의 부족
– 개선점 : 한꺼번에 학습이 어려우니 층마다 개별 학습을 한다거나, 몇 개의 노드를 끈다던가(dropout) 하는 식으로 개선
◆ 빅데이터의 출현
– 한계점 : 인공신경망을 학습시킬만한 충분한 데이터가 부족
– 개선점 : 빅데이터로 인한 이용 가능한 검증된 활용 가능한 대량 데이터 확보
◆ 하드웨어의 발전
– 한계점 : 계층이 늘어날수록 상당한 컴퓨팅 파워의 부족
– 개선점 : 강력한 GPU(Graphics processing unit)들은 복잡한 매트릭스와 벡터 계산이 혼재해 있는 경우 몇 주 걸리던 작업을 며칠 또는 몇 시간으로 줄어드는 컴퓨팅 성능의 비약적 향상
위와 같이 기존의 한계점이 극복됨으로써, 인공신경망은 깊은 구조(Deep Structure)를 가져갈 수 있게 되었습니다. 이로 인해 복잡하고 표현력 높은 모델을 구축할 수 있게 되어 음성인식, 얼굴인식, 물체인식, 문자인식 등 다양한 분야에서 획기적인 결과들이 발표되고 있습니다.
심층계층을 가진 인공신경망이라 정의되는 딥러닝. 지금까지 딥러닝의 정의 속 용어들을 살펴보며 딥러닝에 대해 이해하는 시간을 가졌습니다. 다음 연재에서는 딥러닝 정의의 마지막 키워드인 ‘머신러닝(Machine Learning)’에 대해서 소개해 드리도록 하겠습니다.
<참고자료>
http://en.wikipedia.org, 위키피디아
http://www.slideshare.net, 슬라이드쉐어
http://www.youtube.com, 유튜브
