인공지능을 위한 인공지능, AutoML

2012년 국제영상인식대회인 ILSVRC(ImageNet Large Scale Visual Recognition Challenge, 이미지넷)를 통해 심층학습(Deep Learning)의 성능이 학계 및 산업계에 입증된 이후, AI는 2차 암흑기(AI Winter)를 지나 다시 세간의 관심을 받기 시작했으며, 2016년 이세돌 九단대 알파고의 대국을 계기로 많은 사람들이 인간보다 뛰어난 슈퍼인공지능이 곧 다가올 것으로 생각하게 되었습니다.
시각지능은 2017년도에 이미 98%의 정확도로 인간의 인지수준에 근접하였으며, 언어/청각 지능도 시각지능에 가까운 성능을 보이기 위해 많은 연구가 진행되고 있습니다. 따라서 AI시장은 연평균 50% 가까운 성장세로 제 3의 황금기로써 대량의 자본투자가 이루어지고 있습니다. 하지만, 연구단계에서 좋은 성능을 보인 AI기술이 실용적인 수준의 결과(Practical Outcome)로 이어지는 것이 쉽지 않다는 것을 깨닫는데는 그리 오랜 시간이 걸리지 않았습니다.
최근 세계적으로 유명한 뉴욕대학교 인지심리학 교수인 Gary Marcus는 Google DeepMind가 18년도 5.7억$ 비용, 구글 스케일의 하드웨어, 3일간 1.2만명이 연속 학습한 비용에 대한 실리적인 성과가 얼마나 이루어졌는가에 대해 다소 냉소적인 의견[2]과 심층학습의 한계에 대해서 피력하였습니다.
또한 최근 Gartner 와 VentureBeat AI리포트에 의하면 80~87% 빅데이터/AI 프로젝트가 실패로 끝나고 있다는 보고서가 발표되었습니다. 이제 3차 AI겨울이 다가오는 것을 준비해야 할까요?
강력한 성능이 증명된 AI가 상용화로 바로 직결되지 않는 이유는 무엇때문일까요? Gary Marcus 언급한 10가지 심층학습의 근본적인 한계[3] 전부다 수용할 것은 아니지만 응용상용화와 직결된 4가지 문제를 짚어 보겠습니다.
첫 번째는 고품질 학습데이터(High Quality Training Data)의 부재입니다.
AI를 대표하는 심층학습의 여러 종류 중 가장 강력한 성능을 가지는 지도학습은 “인위적인 레이블”이 필수요소입니다.
심층학습의 대표사례로 많이 접하는 개와 고양이의 분류는 인위적인 레이블이 달려 있는 학습데이터의 형태이며, 심층학습이 입력공간의 연쇄적 미분변환으로 표적공간으로 사상하기 위한 가장 중요한 조건입니다. 하지만, 실제 세계에서의 머신러닝 환경은 이런 수준의 학습데이터를 준비하는데 많은 비용과 시간이 필요하며, 더 큰 문제는 레이블링이 불가능한 AI문제들이 증가하고 있다는 점입니다.
두 번째는 강건(Robust)한 AI의 부재입니다.
AI는 기본적으로 안정된 정적상태를 가정하며, 데이터가 오염되지 않고, 수학적으로 명확히 설명(Representation)할 수 있는 정제된 데이터를 기준으로 설계되어 있습니다. 하지만 실제 세계는 인과관계를 갖는 주요 설명요인 외에도 환경외란에 인한 인과성 없는 변동요인(노이즈)이 교란을 일으키게 되고, 이는 때로 엉뚱한 결과를 야기하기도 합니다. 측정에 사용되는 센서는 시간에 따라 발생하는 성능저하(Degradation) 현상으로 인해 동적 상태변화가 지속적으로 발생합니다. 이런 원인요소는 직접관측도 불가능하며, 항상 설명요인에 혼합되어 관측이 됩니다. 시각지능의 대표적인 예(MIT Technology Review '17[5])로 이미지에 픽셀 3개를 변화시킴으로써 개를 자동차로 인식하는 오류를 범하는 사례가 있습니다. 여전히 AI 사물인식 방식은 사람의 방식과는 많은 차이가 있다는 것입니다. 환경외란에 의한 변동요인(잡음)에 취약한 문제를 개선하기 위해 앞으로 많은 Robust AI 연구들이 필요할 것으로 보입니다. 관련 내용은 인사이트리포트 “2편 스마트팩토리의 인공지능 활용은 왜 어려울까”에 좀더 내용이 있습니다.
세 번째는 소량 데이터(Little Data)만으로 학습 가능 여부입니다.
심층학습 기술이 선호되는 큰 이유 중 하나는 표현학습 자동화에 있습니다. 심층학습에서는 수행할 목적(Target Task)에 맞게 변수(Feature)를 자동으로 변환 및 추출하는데, 정확도가 높은 결과를 얻기 위해서는 빅데이터 수준의 데이터가 필요합니다. 하지만 실제로 높은 정확도가 얻어지더라도 얼마나 효과적일까요? 심층학습을 위한 투자비용은 실리적으로 얻을 수 있는 대가에 비해서 크다고 보고 있습니다.
많은 실제 문제에서는 비정형의 소량 학습데이터(AI-Complete 문제는 10% 이하)만 주어지는 경우가 많으며, 소량의 데이터에서 어떻게든 큰 실용적 효과를 얻고자 합니다. 이런 조건하에서는 분석실무자(AI 개발자 or 분석가)가 직접 복잡한 특징공학(Feature Engineering)을 수행해야 하며, 분석 성능 확보를 위해서 오랜 시간과 시행착오가 요구됩니다. 또한 학습데이터가 소량일수록 전체모수를 반영하지 못하는 부분적인 샘플일 확률이 높아 잘못된 편향된 학습결과로 상용화 시, 큰 오류를 범한다는 문제가 존재합니다.
네 번째는 문제에 최적화된 학습 알고리즘 여부입니다.
우리는 누구나 상용 툴이나 오픈소스가 제공하는 머신러닝 알고리즘을 이용하여, 데이터 분석 문제에 접근할 수 있는 시대에 살고 있습니다. 하지만 일반화된 수학적/통계적 가정들은 고유의 도메인과 애플리케이션의 동특성(動特性) 요인과 맞지 않는 경우가 많기 때문에 경험이 많은 전문실무자들도 먼저 데이터 탐색(EDA: Exploratory Data Analysis)을 통하여, 데이터의 특성과 분포를 파악하고 더 나아가 본인의 필드에서 쌓은 지식을 활용하여 적합한 기법을 선정하거나, 선정한 기법의 내부 파라메터를 튜닝(최적화)하고 때로는 코드수정이나 알고리즘을 만들기도 합니다. 따라서 분석실무자들은 머신러닝 알고리즘의 내부동작뿐 아니라 도메인에 대한 깊은 이해가 필요한 것입니다. 하지만 전세계적으로 한정적인 대학, 기업 및 전문단체만이 이런 수준의 인력과 예산을 확보하고 있어 실무에 적용할 수 있는 AI 알고리즘은 여전히 특정집단에 제한적입니다. 또한 분석전문가라고 하더라도, 새로운 문제마다 해당 도메인지식을 가지고 있어야 하며, 보유실무자의 수에 비해 AI 문제는 너무 다양하게 그리고 급속도로 증가하고 있습니다. 즉, 분석생산성 측면에 있어서 막대한 교육비를 투자할 수 있다 하더라도, 근본적인 해결책이 될 수 없음을 알아야 합니다.
그렇다면 위에 언급된 문제점들을 개선할 수 있는 방안은 무엇일까요?
실용적인 개발생산성을 높이는 방안으로 각 머신러닝 시스템 개발과정에 있어서 “인공지능으로 또 다른 인공지능을 만들어 내는 기술”인 AutoML(Automatic Machine Learning)이 있습니다.
일반적인 머신러닝시스템 개발과정에 있어서 성공적인 상용화를 위해 실무자는 다양한 작업을 해야 합니다. 학습데이터를 더 수집할 것인지, 오염된 데이터는 어떻게 제거할지, 어떤 변수를 선택하고, 어떻게 변환할 것인지, 알고리즘의 수용력(표현력 증대 = 과적합 고려)을 증대할지 혹은 줄여야 할지, 모델구조를 변경할 것인지, 모델코드를 디버깅하여 수정할 것인지 등에 대한 해결방법은 여러 종류의 수학적 지식과 도메인지식을 필요로 하기에 많은 시간(비용)이 소요됩니다.
이러한 개발과정의 정형화된 프로세스를 머신러닝 파이프라인(Machine Learning Pipeline)이라 지칭하며, 아래의 그림1과 같이 데이터 수집/분석/전처리, 피처선택/변환, 최적 ML 선택/튜닝/설계를 거처 배포까지 약 8단계로 실무자에 의해 수행하는 워크플로우와 각 단계별 성능개선 기법들이 존재합니다. 글로벌기업들은 이 파이프라인을 최적화하기 위한 솔루션(IBM AutoAI, Microsoft AzureML, Google AutoML, Amazon SageMaker)을 개발하였으며, 삼성SDS도 Brightics AI에 이 기술을 적용하여 다양한 실무에 적용하고 있습니다.
머신러닝 파이프라인은 아래 그림1과 같이 크게 3개 영역으로 나눌 수 있습니다.
첫 번째는 학습데이터 자동설계 영역입니다. - ①
학습 데이터의 낮은 품질은 매우 중요한 문제로 원시데이터를 머신러닝에 맞게 적절히 수집/정제하는 기술이 필요합니다. 분석실무자가 직접 수행하는 결측, 중복, 특이치, 정규화 등의 작업은 AI를 이용하여 어느 정도 자동화할 수 있습니다.
더 중요한 것은 적합한 데이터가 수집되었냐는 점입니다. 근본적인 통계적 학습이론은 훈련(Training, Validation) 데이터 세트와, 평가(Test) 데이터 세트를 무작위로 충분히 수집하였고, 각 세트마다 독립적이고, 훈련과 평가데이터 세트 간 동일한 확률분포라는 가정하에 수립된 것입니다. 실제 분석에서는 많은 경우 충분히 랜덤화되지 않게 학습데이터가 수집되며, 이는 편향된 학습으로 큰 성능저하를 만들어 냅니다.
하지만 랜덤 샘플링을 빅데이터 수준으로 하는 것 또한 엄청난 비효율이기 때문에 최적의 소량데이터를 인공지능 기법으로 수집하는 연구가 진행되고 있습니다. 한 예로 분류를 할 때, 랜덤 학습데이터보다는 경계조건 위주의 25% 데이터만으로 정확도 90%를 보일 수 있다는 것입니다. 그래서 최근에 '무엇을 먼저 학습할 것인가?'라는 능동학습(Active Learning)이 AutoML에서 많이 접근하는 영역입니다.
두 번째는 피처 엔지니어링 자동화영역으로 주어진 원시데이터를 머신러닝 모델에 적합하게 변형하는 기술입니다. - ②
단일의 모델이 다양한 문제에 일반화하기는 불가능하기 때문에 분석실무자는 도메인과 데이터 특성을 잘 이해하고, EDA를 통하여 원시데이터를 통계적 기법과 시각화 기술을 활용하여 해석을 합니다. 해석 이후, 사용할 후보 머신러닝 알고리즘의 내부동작과 주어진 계산자원(메모리, 실행시간) 내에서 원시데이터를 어떻게 변환할지에 대한 방법론을 도출해야 합니다. 즉, 원시데이터-응용도메인 지식-AI도메인 지식 3가지가 동시에 고려된 최적의 데이터 세트가 만들어져야 합니다.
많은 경우 이 피처엔지니어링 기술이 학습모델 성능을 좌우하는 경우가 많기에 매우 중요한 부분입니다. AI 거장인 앤드류 응 역시 다음과 같이 언급하였습니다.
knowledge. ‘Applied machine learning’ is basically feature engineering.”
— Prof. Andrew Ng.
세 번째는 Machine Learning 알고리즘 자동설계 영역입니다. - ③
과거 메타러닝(Meta Learning)이 추구한 방향은 기계 스스로 문제에 적합한 알고리즘을 선택하고, 알고리즘을 해당 데이터 분포구조에 맞게 수정/변경하는 것입니다.
좁은 의미로는 선택한 머신러닝(알고리즘)의 초매개변수(Hyper-parameter)의 미세튜닝을 위해 다양한 시행착오를 자동화하여 성능을 개선하는 기법부터 넓게는 신경망의 위상구조(Topology)를 스스로 탐색하여 최적의 구조설계를 자동화하는 방법이 있습니다.
앞에서 살펴본 세 영역 중 바로 사용이 가능한 머신러닝 초매개변수의 자동튜닝에 대해서 좀더 살펴 보겠습니다.
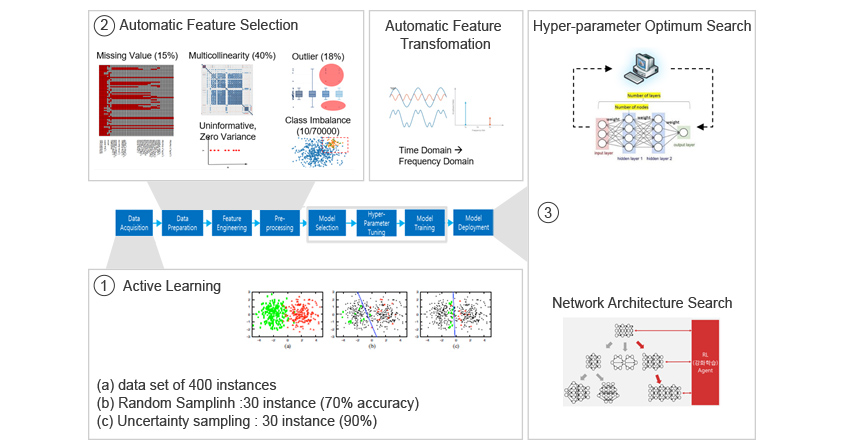 그림1 머신러닝 파이프라인
그림1 머신러닝 파이프라인
AI 활용의 목적(예측, 분류, 제어, 생성)은 도메인 별로 다양한 만큼 데이터의 분포, 피처구조, 가설공간(1차, 2차,..)도 다양할 것입니다. 따라서 주어진 데이터와 환경에 적합한 학습기술은 분석실무자가 미리 고안해야 하는 부분입니다.
예를 들어, AI-Complete 부류인 이미지 기반 물체인식(Object Detection) 문제는 이미지의 공간 상관성을 반영하기 위해 합성신경망을, 음성과 같이 입/출력이 순차열 구조로 자기상관성을 가지는 경우는 순환신경망을 선택해야 합니다. 반면, 상대적으로 복잡도가 낮은 수치 데이터 간의 선형상관을 규명하는 문제의 경우, 간단한 가중치 몇 가지를 찾는 로지스틱 회귀기법이 적합함을 실무자가 파악한 후 알고리즘을 선택해야 합니다. 하지만 이런 수준의 모델 선정이 끝은 아닙니다.
대표적인 신경망을 예로 들어보겠습니다. 알고리즘 성능, 실행시간, 메모리에 영향을 주는 초매개변수는 학습률, 가중치 감쇄계수, 드롭아웃 비율, 합성곱 필터크기, 은닉 단위 개수, 배치 크기(Mini-Batch Size), 레이어수와 같은 것으로, 과소/과대 적합에 큰 영향을 주는 부분으로 매우 중요한 의사결정사항입니다. 전문지식이 없는 사람들은 수용력을 최대한 과도하게 주고 신경망이 내부최적화 알고리즘이 불필요한 변동요인들을 스스로 제거하길 바라지만, 초매개변수와 모델성능과의 관계는 에그 홀더[6] 형태(그림 2)와 같이 복잡한 형상이 많아 과도한 가중치 영향과 적합하지 않은 데이터 분포 설정값들은 오히려 참담한 결과와 비효율적인 학습시간을 만나게 됩니다.
 그림2 초매개변수와 모델성능과의 관계
그림2 초매개변수와 모델성능과의 관계
결국 분석실무자는 초매개변수 간 상호작용, 성능, 훈련오차, 평가(시험)오차, 자원, 수용력 간의 관계를 제대로 파악해야만 가장 적합한 학습모델 성능을 얻을 수 있습니다.
유사한 문제에 대한 경험이 많은 분석실무자일수록 저비용으로 빠르게 의미있는 분석결과를 도출할 것이며 이것이 전문가 확보의 가장 큰 이유입니다. 하지만 이런 전문실무자의 수는 시장에 매우 한정되어 있으며, 전문가들도 새로운 형태의 문제를 만날 때마다 여러 시행착오와 연구를 반복해야 좋은 성능의 학습모델을 얻을 수 있습니다.
그럼 좋은 성능의 학습모델을 얻는 방법으로 어떤 것들이 있을까요?
수동 선택법(Manual Search)은 머신러닝 초매개변수들을 분석실무자가 하나하나 값을 변경하고 각 경우마다 생성된 머신러닝 학습모델의 성능측정값(Performance Measurement: 정확도, 평가데이터 세트 오류율 등) 중 제일 좋은 성능을 보이는 학습모델을 선택하는 방법을 말합니다. 반복적인 시행착오를 거치며 적절한 성능을 보이는 매개변수 조합을 실무자의 직관에 의해 탐색하는 방식으로, 경험과 운(?)에 의해 성능이 결정되는 경우가 많습니다. 과거 초매개변수가 2~3개인 다항회귀, SVM과 같은 경우에는 이런 방식이 큰 문제가 아니었으나, 초매개변수가 굉장히 많아지는 심층학습의 경우에는 이런 방법은 적용하기 어렵습니다.
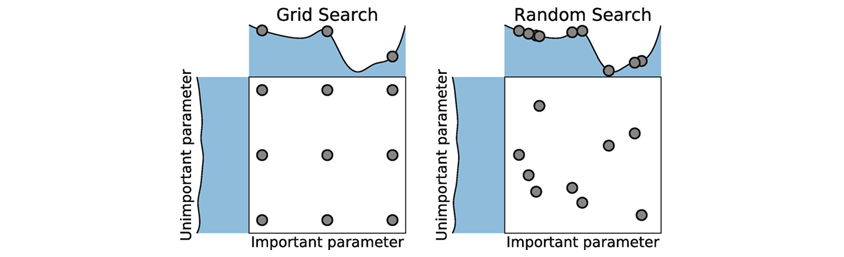 그림3 격자 탐색법(Grid Search)
그림3 격자 탐색법(Grid Search)
상대적으로 조금 세련된 방법은 격자 탐색법(Grid Search)으로, 각 매개변수별 구간을 임의의 격자(Grid)로 나누어, 각 구역별로 배치 단위의 학습모델을 수행하여 성능이 가장 높은 조합을 선택하는 방법입니다. 그림3의 왼편과 같으며 배치자동화로 일괄처리가 가능하나, 매개변수의 수가 증가할수록, 실험횟수가 기하급수적으로 증가하는 비효율성과 격자 간격 사이에 존재할 수 있는 최적해(현재보다 더 좋은 학습모델)를 못 찾는다는 한계를 가지고 있습니다.
성능과 시간에 가장 크게 직결되는 학습률(Learning Rate) 매개변수를 0.1 씩 간격을 주어(0.1, 0.2, …, 0.9) 각각 9가지 격자를 실험해 본다고 하면, 문제가 없지만 이런 매개변수가 50개(차원) 경우 매우 엄청난 조합(약 5*10^47 회)을 실험해야 합니다. 더 중요한 것은 최적의 학습률이 0.013일 경우 격자탐색으로는 찾을 수가 없습니다.
또 다른 방법으로는 랜덤 탐색법(Random Search)이 있습니다. 매개변수의 확률분포를 사전에 알 수 있다면, 알고 있는 확률분포 정보를 이용하여 샘플링을 하면서 좋은 성능이 나오는 경우를 선택하는 방법으로 그림3의 오른편과 같습니다 (하지만 대부분 실제 확률분포를 사전에 알지 못합니다). 격자탐색에 비하여 공간정보를 이용하기 때문에 불필요한 실험을 하지 않아 좀 더 효율적이며 격자 사이의 최적조합을 찾을 수 있습니다.
하지만 50개에 가까운 초매개변수 간 교호작용과 학습모델의 성능변동을 동시에 고려하는 요구사항은 이런 단순자동 선택법으로는 해결하기엔 오랜 시간이 소요되거나 좋은 해가 아닐 경우가 많습니다. 이런 유형의 문제를 효율적으로 탐색하는 기술로 대표적으로 수치최적화 기법이 있습니다.
수치최적화(Numerical Optimization)는 반복적 시행착오(Trial and Error)에 의해 최적화 필요조건을 만족하는 값 X∗를 스스로 탐색하는 기법으로, 아래 그림4에서 도식화한 강화학습(동적 최적화)의 프로세스와 유사합니다. 사전지식을 이용하여 매 반복시행마다 수치 알고리즘이나 베이지안 확률과정으로 더 좋은 초매개변수의 최적조합을 자동 탐색합니다.
 그림4 하이퍼파라메터 최적화(Hyper-Parameter Optimization)
그림4 하이퍼파라메터 최적화(Hyper-Parameter Optimization)
개념적으로만 간단히 본다면 하이퍼파라메터 최적화(Hyper-Parameter Optimization: HPO)는 무수히 많은 성능평가 결과 중에서 가장 낮은 오류를 가지는 초파라메터 조합을 찾기 위한 반복적인 피드백 과정입니다. 그림4의 Action이 초파라메터 조합의 다양한 시도이며, Reward가 그에 대응되는 학습모델 평가결과가 되는 것입니다.
최적화 기법은 17세기부터 오랜 기간 발전되어 온 기술이지만, 그 중 하이퍼파라메터 최적화는 1990년대 출현하여 수치미분 계열의 경사구배법, Model 기반의 베이지안 최적화, 휴리스틱 기반 진화학습, 강화학습 등이 적용되어 왔습니다.
그림 5의 첫 번째 그래프는 초매개변수 한 공간에서 임의의 두 값(Observation: 검은색 점)에 대한 학습모델 오류율(목적함수)을 표기한 그림입니다. 파란색 영역의 폭은 두 점 사이 불확실성(최적해 기대 추정량) 정도이며 두 점에서 거리가 멀어질수록 폭이 넓어지게 됩니다. 두 점의 중간지점이 가장 불확실성이 높기 때문에, 가운데 공간을 탐색(Exploration)하면 더 좋은 해의 가능성이 높다는 생각을 해 볼 수 있습니다. 그리고 두 점 중 오른쪽 지점의 목적함수값이(오류율 최소화 문제) 왼쪽값보다는 더 좋은 값이라는 확정된 사전정보(Exploitation)를 이용하여, 두 점의 중간지점보다 오른쪽으로 좀더 치우친 어딘가의 위치에 좀더 개선된 최적해가 존재할 것이라고 추정할 것입니다. 이러한 과정을 가우시안 프로세스 회귀와 베이지안 확률추정을 반복과정이며, 최종적으로 Acquisition Function으로 다음 최적해의 사후확률을 계산하는 것으로 Bayesian Optimization이라 불립니다.
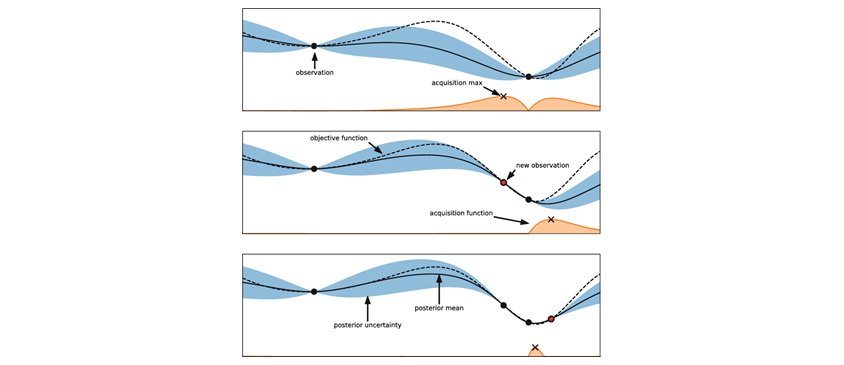 그림5 순차 근사(모델) 전역최적화(Sequential Model-Based Global Optimization)
그림5 순차 근사(모델) 전역최적화(Sequential Model-Based Global Optimization)
개념으로도 매우 논리적이고 한때 HPO 전역최적화(Global Optimization) 문제에 있어서 최선의 방법으로 논의되기도 했지만, Egg-Holder 형태(U & V커브 조합형태)의 문제에서 다른 최적화 기법 대비 특별히 다른 효율성을 보이진 않습니다. 고차원 공간에서 차원 증가에 비례하여 탐색시간이 기하급수적으로 증가하는 알고리즘의 특성을 고려할 때 Bayesian Optimization 기법은 반드시 선택해야 할 방법은 아니라는 것입니다.
꼭 전역최적해에 집착할 필요가 없다면(수학적으로 전역 최적 해는 보장할 수 없음), 함수(Derivative)를 이용하여 방향을 탐색하는 Gradient-Based Search와 특정패턴을 반복적으로 배치하여 최적화하는 Pattern Search 등 빠른 수렴의 국소최적화 기법을 먼저 생각해 볼 수 있으며, 다소 시간이 걸리나 전역해를 찾을 가망성이 높은 자연모사 기반 탐색(Ant Colony, Particle Swarm Search)이나 진화이론을 토대로 한 Evolutionary Search 기법인 휴리스틱 계열을 생각해 볼 수 있습니다.
| Category | Method | Description | Evaluation | Accuracy |
|---|---|---|---|---|
| Derivative-Free Local (Deterministic) |
Mesh Adaptive Search | 초기값 기준으로 안정적으로 최적해탐색 | 157회(48Hour) | 99.01% |
| Derivative Global (Heuristic) |
Evolutionary Algorithm | 교배, 변이 기반 진화알고리즘 | 283회(78Hour) | 98.88% |
| Derivative Global (Heuristic) |
Single Object Genetic Algorithm | 1세대 Populatoin에서 우연한 탐색 | 5회 강제멈춤(1Hour) | 98.01% |
MNIST(0부터 9까지 손으로 쓴 숫자 이미지를 수집해놓은 대용량 데이터) 분류 문제를 테스트한 결과 중 일부가 표1와 같습니다. 국소최적화 계열인 Mesh Adaptive Search가 전역최적화 기법인 Evolutionary Algorithm 대비 약 절반의 시간으로 거의 동일한 결과를 보이고 있습니다. 다른 국소최적화 기법도 문제마다 약간 다를 뿐이지만 거의 유사한 양상을 보이며, 결과를 보면 국소최적해임에도 성능상 충분한 결과를 얻을 수 있음을 알 수 있습니다.
하지만 3번째 유전자(Genetic) 알고리즘의 결과는 특이한 경우로, 단지 5회만에 최적해를 찾은 것처럼 보이지만 랜덤샘플링의 우연한 산물입니다. 하지만 이런 우연 외 다루는 HPO문제가 자주 보이는 에그홀더와 유사한 형태일 경우 초기수렴이 좋다는 실험결과들이 있으므로, 고려대상에서 검토해야 할 항목은 분명합니다. 하지만 어떤 기법이 더 좋은가는 각 문제상황마다 다르기 때문에, 항상 그렇듯이 다양한 알고리즘으로 문제속성과 환경에 맞게 선택을 해야 한다는 것이 분석실무자에게 주어지는 숙제입니다.
수치최적화 기법을 쓰는 근본적인 이유는 좋은 성능을 가지는 학습모델의 자동선택이지만, 또 다른 중요한 이유는 어느 정도 탐색시간이 효율적이기 때문입니다. 하지만 순수 알고리즘이 지원하는 효율화 외 적극적인 처리를 해야 할 필요가 있습니다.
HPO 결과를 얻는데 소요되는 시간(비용)은 단순회귀(Regression) 문제의 경우, 2~5분 이내로 얻을 수 있습니다. 반면 간단한 심층학습(필기체 인식) 최적화의 경우 일반 워크스테이션(CPU) 기준으로 3일이 걸리기도 합니다.
보다 복잡한 심층학습 문제의 경우, 한번 성능평가(Evaluation)하는데 2일이 걸리는 경우가 있기도 합니다. 1회 평가에 24H가 소요되는 문제라면 157회, 283회의 성능평가는 매우 부담스러운 시간일 것입니다. 따라서 좀더 적극적인 개선안이 필요합니다.
첫 번째 개선안은 고성능 H/W(GPU)를 이용하여 성능평가 1회 시간을 단축하는 방안입니다. 두 번째 개선안은 최적화 알고리즘에서 성능평가를 순차방식에서 병렬방식으로 전환하는 것입니다. 대표적으로 진화기법(Evolution Search) 계열이 탐색공간의 샘플링 시 병렬실험을 지원하며, 최근 들어 HW와 고성능 알고리즘의 조합이라는 측면에서 많은 업체가 접근하는 방식입니다. 하지만 대부분의 분석실무자들의 자원은 이러한 병렬컴퓨팅 환경을 지원하기 어렵습니다. 이러한 상황에서 최선의 방법은 탐색 차원 자체를 줄이는 세 번째 개선안입니다.
일반적으로 머신러닝에 관련된 초매개변수를 전부 고려할수록 좋은 성능을 보이는 조합을 찾을 가능성이 높습니다. 하지만, 매개변수의 개수(차원) 증가는 탐색공간의 계산량을 기하급수적으로 높입니다. 각 도메인 문제마다 주요 매개변수와 영향력은 각기 다르기에 어떤 매개변수가 학습모델의 성능에 유의한 영향을 주는지 분석하는 기법이 필요합니다. 전산 실험계획법(Design Of Experiment)은 최소 실험횟수로 최대한 많은 정보량을 통계적으로 분석하는 기법(매개변수 조합)입니다. 대표적으로 직교배열표(Taguchi Method)를 이용하여 최소 실험계획을 수립 후, 각 매개변수별 통계적 유의성 검증을 수행하여, 낮은 영향력을 가지는 매개변수는 최적화에서 누락하여 효율적으로 수행합니다.
지금까지 학습지능의 한 분야인 AutoML의 등장배경과, 그 가운데 핵심기술 중 하나인 머신러닝 알고리즘 자동설계(Automated Algorithm Design)에 대해서 간단히 살펴보았습니다. 알고리즘 자동설계는 적용이 가능한 HPO부터 근본적인 신경망 아키텍처의 위상구조 자체를 재설계하는 수준으로 발전하고 있습니다. 이외에 전이학습을 동시에 반영하여 효율성을 높이는 방안, 분석실무자에게 가장 고통스러운 피처 엔지니어링의 자동설계, 그리고 학습데이터의 품질을 올리기 위한 능동학습(통계학의 아버지인 로널드 피셔의 실험계획법)에 의한 데이터가 단순수집한 데이터 대비 얼마나 좋은 결과를 가져오는지 우리는 잊고 있습니다. 지금 설명하지 못한 다양한 학습지능 기술들을 적극적으로 검토 해야 합니다.
심층학습과 알파고 이후 AI는 빠르게 실체화되어 일상생활에 큰 변화를 줄 것으로 생각했습니다. 하지만 예상과 달리 AI 응용상용화는 현실적으로 쉽지 않고, 실용적인 결과로 이어지기까지 또 다른 많은 솔루션이 필요하다는 것을 인지하게 되었습니다.
각 도메인과 애플리케이션별 고품질의 학습데이터 준비, 적합한 피처의 자동생성 그리고 최적의 머신러닝 설계를 무인화하는 학습지능 기술과 고성능 AI 기술과 동시 제공되어야 합니다.
다행히 AutoML은 과거의 학습지능과는 달리 실용적이고 구체적인 형태로 적용되기 시작했고, 많은 AI 영역의 비효율성을 조금씩 개선하기 시작했습니다. 하지만, 인공지능을 위한 인공지능이라는 이 기술도 사람의 반복적인 시행착오에 의한 머신러닝 초매개변수를 자동미세조정하는 수준일 뿐입니다. 궁극적인 머신러닝 파이프라인 전체를 해결해야 한다는 목표는 아직도 아득히 먼 미래이고, 해결해야 할 문제들은 우리들에게 아직도 많이 남아 있습니다.
References:
[1]“ICT R &D 기술로드맵 2023”, 인공지능·빅데이터, 한국과학기술정보통신부, 2017
[2]“DeepMind's Losses and the Future of Artificial Intelligence”, NYU, Gary Marcus, 2019
[3] Deep Learning: A Critical Appraisal, Gary Marcus, 2018
[4] A Tutorial on Bayesian Optimization, Peter I. Frazier July 10, 2018
[5] Hyperparameter Optimization, Springer, 2019
[6] One Pixel Attack for Fooling Deep Neural Networks, MIT technology review, 2017
[7] https://en.wikipedia.org/wiki/Test_functions_for_optimization
[8] On the saddle point problem for non-convex optimization. Pascanu, R., Dauphin, Y., Ganguli, S., and Bengio, Y., 2014
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.

주민식 프로는 대학원에서 기계공학&컴퓨터사이언스를 전공하였고 주요 연구분야는 Applied mathematics(응용수학)기반 Manufacturing 데이터분석 및 최적화를 했습니다.
현재 전자 및 관계사 데이터기반 무인설계기술과 공정최적제어 관련 컨설팅을 수행중이며,삼성SDS Brightics AI 알고리즘 중 Optimization 기술리더입니다. 관심분야는 능동학습(Active Learning)과 전이학습(Transfer Learning) 이용한 전통적인 AI기술 (강화학습을 비롯한 머신러닝)의 비효율성 해결과 자율학습 기술 연구중입니다.