크로스 플랫폼을 지향하는 데이터 포맷과 특징

기업 내부에는 수많은 시스템이 존재합니다. 데이터를 생산하는 시스템, 생산된 데이터를 저장하고 관리하는 시스템, 분석하는 시스템 등. 이들은 서로 간 데이터 교환을 통해 연계 작업함으로써 업무를 처리합니다. 이 과정에서 모든 시스템이 동일한 프로그래밍 언어, 플랫폼, 데이터 포맷, 인터페이스를 사용한다면 연동이 매우 쉽겠지만 현실은 대부분 그렇지 않습니다. 이와 반대로 특별한 노력 없이도 새로 추가되는 시스템과 기존 시스템이 같이 잘 동작할 수 있는 능력을 Interoperability, '상호운용성이'라고 합니다. 이 상호운용성을 증가시키고 개방형 시스템을 만들기 위해 항상 논의되는 것이 바로 '데이터의 표준'입니다.
우리가 잘 알고 있는 상호운용성 모델은 '웹'입니다. 운영체제와 브라우저에 상관없이 동작할 수 있는
TCP/IP, HTTP 그리고 데이터 포맷인 HTML 등 웹 표준을 제정해서 상호 간 커뮤니케이션이 가능하죠.
최근 화두로 떠오른 IoT도 마찬가지로 네트워크에 참여하는 사물들이 모두 이해할 수 있는 데이터 표준을 정립하기 위해 각 기관이 노력하고 있습니다.
이를 데이터 분석 관점에서 보면, 데이터 분석가들은 대부분 자신에게 친숙한 언어로 모델을 만들어 수집한 데이터를 전처리하고 분석하길 원합니다. 예를 들어 분석가 A가 R을 이용해 만든 Dataframe 형태의 데이터를 분석가 B는 Python에서 사용하고 싶고, 분석가 C는 Java에서 사용하고 싶어 하죠. 이 경우, 이를 관장하는 엔지니어는 어떤 데이터 포맷을 제시해야 가장 효율적일까요? 다행히 이런 문제를 해결하기 위해 전 세계 여러 개발자들이 많은 데이터 포맷을 만들어 놓았습니다. 이번 포스트에서는 크로스 플랫폼을 지향하는 몇몇 데이터 포맷들의 특징들에 대하여 간략히 살펴보고 이것이 어떻게 발전되어 왔는지 알아보겠습니다.
Schema-free Type
위의 예제에서 가장 먼저 떠올릴 수 있는 데이터 포맷은 CSV 또는 JSON일 것입니다.
이 포맷은 사전에 데이터의 형태(스키마)를 정해놓지 않고도 자유롭게 데이터를 표현할 수 있다는 특징이 있는데, 이런 포맷을 Schema-free 데이터 포맷이라고 합니다. JSON, CSV 이외에도 비슷한 목적을 가진 포맷들의 각 특징을 비교해보겠습니다.
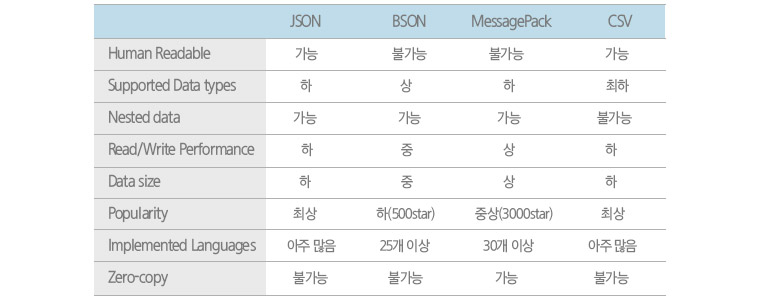
항목 설명
· Human Readable: 결과물을 사람이 읽을 수 있는 형태
· Supported Data types: 지원하는 데이터 형태의 개수(Integer, Double, Map 등)
· Nested data: 2D array 등 다중 데이터 선언이 가능한지 여부
· Read/Write Performance: 해당 포맷으로 읽고 쓸 때의 성능
· Data size: 같은 데이터를 썼을 때, 파일의 크기(작을수록 상급)
· Popularity: 사용자 수, Git star를 종합한 유명한 정도
· Implemented Languages: 읽고 쓰기가 가능한 프로그래밍 언어의 수
· Zero-copy: 일반적으로 한 플랫폼에서 데이터를 읽을 때 원본 데이터를 읽어서 해당 플랫폼의 오브젝트로 변환한
후, 메모리에 저장하여 사용하게 됩니다.
Zero-copy는 이런 과정 없이 원본 데이터를 스트림으로 읽어 바로 사용할 수 있는 기능으로, 이것을 활용하면
메모리 복사 과정이 필요 없기 때문에 성능 향상에 크게 도움이 됩니다.
이 Schema-free 타입들은 스펙이 직관적이고 단순해서 많은 곳에 적용이 가능하고 상호운용성도 매우 높습니다. 하지만 데이터를 표현하는 것 이외에는 추가 기능이 거의 없고, MessagePack을 제외하면 전체적으로 읽고 쓰는 성능이 떨어집니다. 일반적으로 사람이 읽을 수 있는 데이터 포맷일수록 사이즈가 크고, 읽고 쓰는 속도는 느리다고 볼 수 있죠.
Schema IDL Type
IDL은 ‘Interface Definition Language’의 약자로, 데이터 스키마를 표현하는 언어입니다.
데이터베이스에서 테이블 스키마를 정의하는 언어가 SQL로 되어 있듯, 이 카테고리에 해당하는 데이터 포맷들은 각자의 IDL을 가지고 있습니다. 따라서 IDL을 어떻게 정의하느냐에 따라 타입 추가, 디폴트 값 입력, 레퍼런스 객체, 함수 정의, 상수 설정 등 여러 가지 기능이 추가될 수 있습니다.
또한 IDL로 스키마를 정의하는 과정이 프로토콜 또는 메시지 규약을 정의하는 것과 비슷하고, 대부분 읽고 쓰는 과정이 빠르기 때문에 형제 프로젝트로서 이 데이터 포맷에 기반을 둔 메시지 교환, RPC/IPC 네트워크 프레임워크가 있는 경우가 많습니다.
Columnar Data format
이번에 소개할 두 데이터 포맷은 빅데이터 처리와 데이터 분석에 최적화된 데이터 포맷으로, 위의 데이터 포맷들과 다르게 Column-oriented 형태로 데이터를 표현합니다.
특히 Column-oriented 포맷이 데이터 분석에 유리한 이유는 크게 두 가지입니다.
1. Projection push down: 'Column pruning'이라 부르는 이 기능은 칼럼 데이터의 offset 정보를 통해 벌크데이터
중 몇 개 칼럼만 선택적으로 읽어 들이고 나머지 칼럼은 스킵하여 디스크/메모리 IO 감소 효과를 얻음
2. Predicate push down: 데이터를 저장할 때 칼럼 블록별 Min/Max/Avg 등 기초 통계량 정보를 저장해 놓고,
Filter 등과 같은 특정 작업 시 이 통계량 정보를 활용해 아웃풋을 빠르게 만들어 냄
이 두 기능을 활용하면 큰 데이터에서 원하는 부분만 추출하거나 분석할 때, Row-based 보다 우월한 성능을 보입니다. 또한 두 포맷은 본래 병렬처리를 위해 만들어졌기 때문에, 빅데이터를 처리할 때 이 두 포맷으로 데이터를 읽고 쓸 경우, 병렬처리가 가능한 환경에서는 다른 포맷보다 성능이 월등합니다.
다양한 언어로 프로그래밍 할 수 있는 사람을 ‘Polyglot 프로그래머’라고 부릅니다. 새로운 언어가 계속 쏟아져 나오면서 기존 언어들로 작성된 프로젝트들과 연동하는 경우가 많기 때문에 생겨난 용어입니다. 그래서 요즘 프로그래머는 언어를 잘 아는 것보다 잘 배우는 능력이 중요하다고 합니다. 이런 시대에 언어 간 데이터 교환을 위한 포맷들을 바이블처럼 알고 있다면 뛰어난 Polyglot 프로그래머로 성장할 수 있을 것입니다.
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
- #Data Format
- #Data Analytics
- #Polyglot Programming
- #Bigdata
- #빅데이터
- #Cross Platform
- #Samsung SDS
- #삼성SDS

Senior Engineer, Analytics Platform Lab, Samsung SDS
Samsung SDS Certified Professional
삼성SDS 연구소 분석플랫폼Lab 소속이며, 소프트웨어 개발, 빅데이터 아키텍쳐, 머신러닝에 관한 지식과 업무 경험을 바탕으로 현재 삼성 SDS Brightics 솔루션 개발을 담당하고 있습니다.