인공지능 경량화 기술 동향

Deep Neural Network 경량화의 필요성
2012년 이미지 분류 대회인 ILSVRC(ImageNet Large-Scale Visual Recognition Challenge)에서 Deep Neural Network 기반의 Alexnet이 2위(Top 5 Error 26.2%)보다 월등한 성능(Top 5 Error 15.4%)으로 우승하였습니다. 이를 통해 Deep Neural Network가 이미지 분류에 탁월한 성능을 보인다는 것이 많은 사람에게 알려지면서, 많은 연구자가 Deep Neural Network에 관심을 갖게 되었습니다. Alexnet은 8개의 Layer로 구성된 Neural Network 모델이었습니다. 이후 연구자들은 Neural Network를 더 깊게 쌓기 위해 노력하였습니다. 2014년에 발표된 VGG는 19 Layer, GoogleNet은 22 Layer로 Deep Neural Network를 구성하여 ILSVRC에서 우수한 성능을 보입니다. 2015년에는 ResNet이 등장하는데, ResNet은 Neural Network의 Layer 수가 일정수준 이상으로 많아지는 경우 Loss의 Gradient 역전파가 잘 안 되는 문제를 해결하는 구조를 제안하였습니다. ResNet은 이러한 구조 덕분에 매우 깊게 Layer를 쌓는 것이 가능해졌고, ResNet 저자들은 무려 152 Layer를 쌓아 올린 Neural Network를 구성합니다. ResNet은 2015년 ILSVRC를 3.57%의 오류율로 우승을 하게 되는데, ILSVRC의 Dataset을 분류하는 문제에서 인간의 오류율이 5.1%라는 것을 고려하면 ResNet이 인간보다 우수한 정확도를 보였다고 평가할 수 있습니다. 그 후 2016년에 DenseNet이 발표되었는데, DenseNet은 ResNet에서 사용된 Gradient 전달경로를 층마다 더 촘촘히 두어 Loss의 Gradient가 더 잘 전달되도록 하는 구조를 제안하였습니다. DenseNet 역시 100개 이상의 Layer(논문에서 제안한 구조의 Layer의 수는 121, 169, 201, 264개입니다)를 두고 있으며 이미지 분류 문제에 있어 좋은 성능을 나타내는 Neural Network 구조 중 하나로 알려져 있습니다.
 GoogleNet, 이미지 출처 2
GoogleNet, 이미지 출처 2
기업 환경에서 Neural Network를 사용하는 경우 앞서 말씀드린 GoogleNet, ResNet 또는 DenseNet과 같이 잘 알려진 구조에서 출발하여 Neural Network를 구성하는 경우가 많이 있습니다. 문제는 이 Neural Network들이 매우 깊은 Layer 구조와 수백 MB를 넘을 정도로 많은 수의 파라미터를 갖고 있기 때문에 학습 시뿐만 아니라 추론(Inference) 시에도 많은 양의 연산이 필요하다는 것입니다. 실시간 처리가 필요한 응용 애플리케이션 또는 모바일 환경 등과 같이 리소스 사용에 제한이 있는 경우에는 연산에 필요한 자원이 부족할 수 있습니다. 이러한 경우 더 적은 연산량으로 추론을 수행할 수 있도록 해 주어야 합니다. Neural Network를 배포하는 데 있어서 추론에 필요한 연산량을 줄이기 위해 어떤 방법이 사용될 수 있는지 알아보겠습니다.
Neural Network Pruning
Neural Network Pruning 방법은 Neural Network의 파라미터 중에서 중요도가 떨어지는 파라미터를 찾아 제거하는 방법입니다. 많은 경우에 학습을 시작할 때는 몇 개의 파라미터를 사용하는 것이 최적인지 알 수 없기 때문에, 충분한 수의 파라미터를 사용할 수 잇도록 Neural Network를 구성합니다. 이런 구조로 학습을 완료한 뒤에 파라미터의 상태를 확인해 보면 결과에 영향을 주지 않는 파라미터가 상당수 존재하는 것을 확인할 수 있습니다. Neural Network Pruning 방법에서는 결과에 영향이 적은 파라미터를 선택하여 Neural Network로부터 제거합니다. 영향도가 적은 파라미터라 하더라도 제거를 하면 이에 따른 정확도 손실이 발생할 수 있는데, 이러한 정확도 손실을 보정하기 위하여 Pruning을 한 상태에서 다시 추가 학습을 하는 방법도 있습니다. 여기에 더해 적절한 수준에 도달할 때까지 파라미터 제거와 추가 학습을 여러 차례 반복하기도 합니다. 또한 더 발전된 형태로 파라미터를 적절하게 Grouping하여 Pruning하는 방법에 관한 연구도 있습니다.
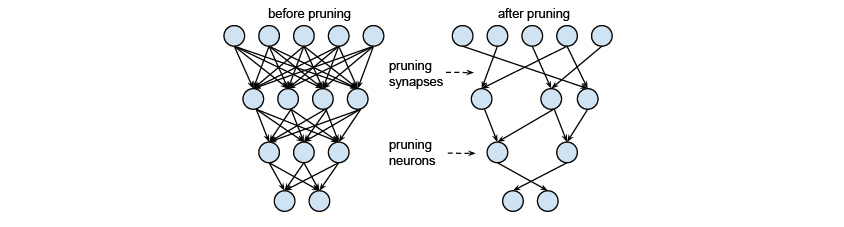 Pruning 이전과 이후의 Neural Network, 이미지 출처 3
Pruning 이전과 이후의 Neural Network, 이미지 출처 3
Low-Rank Approximation
CNN(Convolutional Neural Network)에서는 많은 양의 Convolution 연산을 하게 되는데, 일반적으로 4차원 데이터와 3차원 Filter-Bank 간 Convolution을 수행합니다. Convolution 연산은 행렬 곱셈을 통하여 연산이 이루어지는데, Low-Rank Approximation에서는 행렬 곱 연산 시 Rank를 줄여 연산함으로써 근사해를 구하더라도 더 빠른 속도로 연산을 할 수 있게 합니다. Rank를 줄이기 위해 사용할 수 있는 대표적인 방법으로 SVD(Singular Vector Decomposition)가 있으며, 4차원 데이터와 3차원 Filter-Bank의 형태나 특성을 고려하여 Rank를 줄이는 방법 등 다양한 알고리즘들이 연구되고 있습니다.
Quantization
Neural Network를 구성하여 학습, 추론해 보면 파라미터를 위하여 32bit 또는 64bit 부동 소수점 수준의 Precision이 필요하지 않은 경우가 많이 있습니다. Quantization은 파라미터의 Precision을 적절히 줄여서 연산 효율성을 높이는 방법입니다. 16bit, 8bit Precision을 사용하는 방법의 경우, 비교적 적은 정확도 손실로 고속 연산이 가능한 경우가 많습니다. 또한 하드웨어에 따라 병렬 연산의 효율이 더 높아지는 경우도 있으며, NVIDIA나 Intel과 같은 하드웨어 업체에서 관련 라이브러리를 제공하기도 합니다. 좀 더 과감하게 4bit, 2bit, 1bit를 사용하는 알고리즘도 연구되고 있습니다. 이렇게 적은 수의 Bit를 사용하는 알고리즘의 경우에는 학습이 완료된 파라미터를 단순 Quantization하는 것에 더해 학습 시에도 적은 수의 Bit를 고려하여 학습하도록 하는 알고리즘도 연구되고 있습니다.
Knowledge-Distillation
Knowledge-Distillation은 Teacher Network로부터 Student Network를 학습시키는 모델로 Teacher-Student Network로 언급되기도 합니다. 학습하고자 하는 Dataset D가 있을 때 Teacher Network T가 Dataset D를 먼저 학습합니다. 그 후 Teacher Network보다 작은 규모의 Student Network S가 Teacher Network T를 활용하여 Dataset D를 학습합니다. 이 과정을 Distillation이라는 용어로 표현하는데, 이는 Teacher Network T가 Student Network S에게 Dataset D에 관한 지식을 응축하여 전달하는 것이라고 할 수 있습니다. 이렇게 학습된 Student Network S는 Teacher Network T 없이 Dataset D를 직접 학습한 S’보다 더 높은 성능을 보인다는 것이 여러 논문을 통해 확인되었습니다. 이것은 보다 큰 Neural Network인 Teacher Network T의 지식이 작은 Neural Network인 Student Network S로 Distillation 되었다고 하여 Knowledge-Distillation이라고 합니다. T의 지식을 S로 어떻게 전달할 것인가에 대해 2015년 Geoffrey Hinton 교수가 발표한 ‘Distilling the Knowledge in a Neural Network’을 비롯하여 다양한 연구가 진행되고 있습니다.
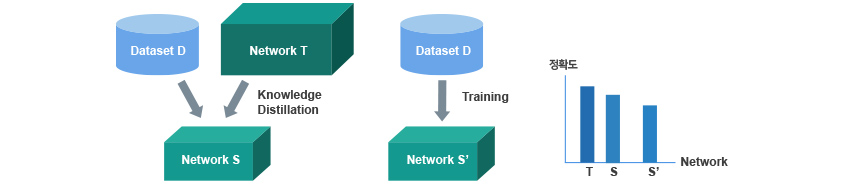 Knowledge Distillation, 일반 학습 비교
Knowledge Distillation, 일반 학습 비교
마치며
모델 경량화 방법으로 본 글에서 언급하지 못한 다른 방법의 연구들도 있습니다. 인공지능이 다양한 분야의 다양한 환경에서 더 널리 활용되기 시작하면서 경량화에 대한 필요성은 더 늘어날 것이고 더 다양한 연구가 진행될 것으로 예상됩니다. 앞으로 어떤 새로운 기술이 개발될지 기대됩니다.
참고 자료
[1] http://image-net.org/challenges/LSVRC/
[2] Szegedy, Christian, et al. "Going deeper with convolutions." Proceedings of the IEEE conference on computer vision and pattern recognition. 2015.
[3] Han, Song, et al. "Learning both weights and connections for efficient neural network." Advances in neural information processing systems. 2015.
[4] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531(2015).
[4] Cheng, Yu, et al. "A survey of model compression and acceleration for deep neural networks." arXiv preprint arXiv:1710.09282 (2017).
[5] Cheng, Jian, et al. "Recent advances in efficient computation of deep convolutional neural networks." Frontiers of Information Technology & Electronic Engineering 19.1 (2018): 64-77.
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.

삼성SDS AI Core Lab
AI Core Lab에서 AI플랫폼 연구개발 업무를 담당하고 있습니다. 주요 연구 및 관심 분야는 Automatic Neural Network Proposal, Neural Network Compression, Continual Learning입니다.