Visual AI ① - 역사 돌파구 통념 및 가능성

현재 일고 있는 AI 혁명의 주요 동인 중 하나는 이미지 인식 자동화에 딥 러닝을 적용시켜 성공했다는 데 있습니다.
2012년 인공신경망(Artificial Neural Network) 아키텍처인 AlexNet이 ImageNet 대회에 출전하여 획기적으로 향상된 정확도를 선보이면서 산업계와 학계의 주목을 받았던 것이죠.
(ImageNet:은 사진만 보고 사물을 검출할 수 있도록 컴퓨터를 프로그래밍하는 대회)
연구진들은 이 중요한 사건을 계기로 심층 신경망의 활용을 다양하게 시도했고 이로 인해 사물 인식의 정확도는 더욱 향상됐습니다. 심지어 일부 적용 사례에서는 인간보다 뛰어난 정확도를 보이기도 합니다.
그렇다면 사물의 자세나 움직임을 정확하게 인식하는 능력, 주어진 장면을 문장으로 묘사하는 능력, 자동차나 로봇이 스스로 길을 찾을 수 있도록 주변 3D 구조를 파악하는 능력과 같이 더 일반적인 시각적 능력의 경우는 어떨까요? 사실, 사람의 시각적 인식 능력을 모방하는 Visual AI 기술은 이미 수십 년 동안 연구되어 왔지만 정확도가 낮고 일반화하기엔 제약이 있어 몇몇 분야를 제외하고는 실질적인 적용사례를 찾아보기 힘들었습니다.
하지만 2012년 첫 돌파구가 열리면서 AI 혁명은 사물 인식뿐만 아니라 광범위한 이미지 인식 작업에까지 확산됐고, 이후 비슷한 수준의 성공을 기록하면서 일상 생활과 비즈니스에도 적용이 가능할 것으로 전망되고 있습니다.
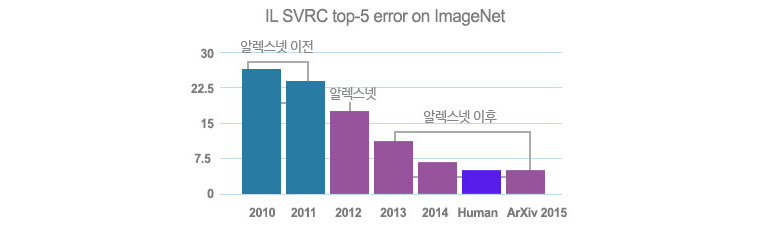 2012년, AI 혁명을 촉발시킨 중요대한 사건
2012년, AI 혁명을 촉발시킨 중요대한 사건
초기 컴퓨터 비전
‘컴퓨터 비전’이라는 학문은 컴퓨터 과학 및 공학 분야에서 수십 년 동안 연구됐습니다.
이것은 사람과 동물의 시각적 처리 과정, 즉 한 장면에서 사물과 사물의 움직임을 인식하고 상위 레벨의 의미론적 이해를 도출하는 과정 등을 자동화하는 학문입니다.
인간이 사물을 인식하는 것은 쉽지만 컴퓨터가 똑같이 사물을 인식하도록 프로그래밍하는 것은 상당히 어렵습니다. 때문에 인간이 수행하는 다양한 작업을 자동화할 수 있는 ‘생각하는 기계’를 개발하는데 있어 이미지 인식 자동화가 핵심적인 역할을 할 것입니다.
컴퓨터 비전 알고리즘의 성능은 신호 처리, 통계 모델링, 수학적 최적화 및 계산 기하학에 기존 이론과 알고리즘을 적용하면서 점차 개선되고 있는 추세입니다.
최초에는 사람과 동물이 시각적 신호를 처리하는 방식을 모델링하고 모델링 된 동작을 컴퓨터가 모방하도록 프로그래밍했습니다. 예를 들어 뇌 해부학과 동물 행동학 연구에서는 뇌가 사물을 인식하기에 전에 에지, 컬러, 텍스처 등과 같은 하위 레벨의 비주얼 요소를 먼저 추출하는 것으로 나타났습니다. 또, 모션 인식은 운동 제어를 담당하는 뇌의 영역과 근접한 곳에서 처리되는 듯한 결과가 나왔죠. 이러한 결과를 바탕으로 개발된 알고리즘은 국방 분야에서 자동 표적 인식 기술로, 의료 영상 분야에서 임상적 의미가 있는 이상 탐지 기술로, 또는 컴퓨터 애니메이션 제작을 위해 사람의 움직임을 모델링 하는 등의 기술로 실제 현장에 적용됐고 결과도 성공적이었습니다. 하지만 이러한 모델은 수용 가능한 특정 조건에서는 정확도가 높았지만 약간 다른 장면이나 환경에 적용할 때에는 정확도가 떨어졌습니다. 각 모델마다 조정해야 할 파라미터가 많거나 특정 이미지 요소를 모델링 할 방법이 없었기 때문입니다.
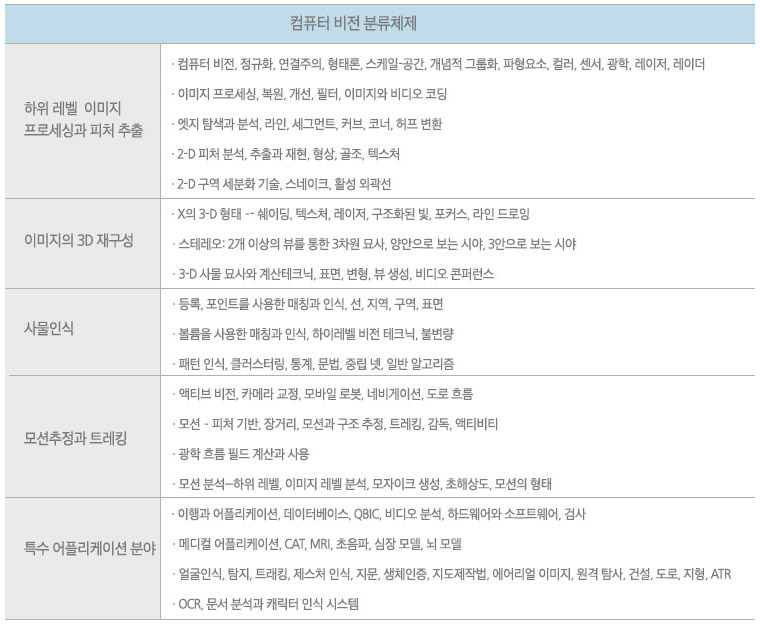 표1 : 문학적 분류용 컴퓨터 비전 분류체계
표1 : 문학적 분류용 컴퓨터 비전 분류체계
(source: http://iris.usc.edu/vision-notes/bibliography/contents.html)
머신 러닝의 도약
이러한 한계를 극복하기 위해 학계는 1990년대의 이미지 데이터 통계에 기반을 둔 접근 방식을 채택하기 시작했습니다. 자연 장면에서 직접 산정된 통계 모델이 비슷한 종류의 이미지를 훨씬 효율적으로 나태내기 때문입니다. 이후 ‘통계적 머신 러닝’ 분류 알고리즘이 많이 개발됐으며, 인기가 높은 분류자로는 Support Vector Machine, Boosting, Random Forest 등이 있습니다. 인공신경망 역시 초반에는 높은 관심을 받으며 채택됐지만 앞서 언급된 알고리즘들이 성공을 거두면서 상대적으로 인기가 떨어졌습니다. 결국 이 모든 현대 머신 러닝 접근법이 컴퓨터 비전 알고리즘의 발전에 기여했다고 볼 수 있습니다.
상기 알고리즘들은 굉장히 일반적이며 모델 파라미터 값 추정을 위한 샘플만 충분히 제공된다면 정확도 개선에 많은 도움이 될 것입니다. 그러나 이 접근법의 주된 문제점은 분류자에 입력되는 데이터의 속성(또는 피처)에 따라 정확도가 크게 달라질 수 있다는 것입니이다. 문제의 모델 추정에 기반해서, 혹은 시행착오를 통해 최선의 피처를 찾는 역할은 종종 컴퓨터 비전 연구진들의 몫이었습니다. 이 단계를 ‘피처 엔지니어링(Feature Engineering)’이라고 부르는데, AlexNet이 등장하기 전까지 컴퓨터 비전 알고리즘 성능의 점진적 개선을 이끈 주된 원동력이었습니다. 그러나 이 단계는 시간이 많이 걸리고 새롭게 개발된 피처가 최선일 것이라는 보장도 없이 시험에 많은 시간을 투자해야 합니다.
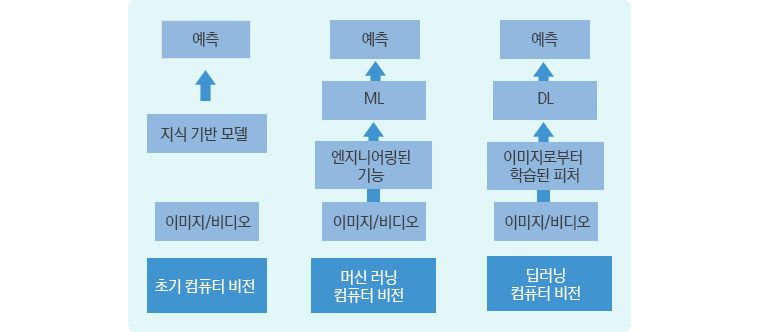 그림 2: 모델 기반 vs 머신 러닝 기반 vs 딥 러닝 기반 컴퓨터 비전 파이프라인
그림 2: 모델 기반 vs 머신 러닝 기반 vs 딥 러닝 기반 컴퓨터 비전 파이프라인
딥러닝의 돌파구
모두가 알고 있듯이 딥러닝은 Visual AI의 연구 개발 활동과 산업계 적용보다 더 중요해졌습니다. 딥러닝의 성공에는 3가지 주요 동력이 있습니다. 인터넷의 풍부한 시각적 데이터, 계산력의 빠른 향상과 비용 저하, 인공신경망 기술의 새로운 알고리즘 혁신.
딥러닝은 근본적으로는 머신 러닝 기술이지만 한 가지 중요한 차이점이 있습니다. 딥러닝 훈련 알고리즘을 통해 그 피처와 분류자가 자동적으로 학습되기 때문에 수동 ‘피처 엔지니어링’ 이 필요하지 않다는 것입니다.
딥 네트워크는 여러 레이어로 구성되어 있으며, 피처 식별자와 분류자의 역할이 동일한 통합 구조로 볼 수 있습니다.
이러한 접근 방식은 이전 기술들과 차별화되는 몇 가지 고유한 강점들로 해석됩니다.
(1) 높은 정확도 향상: 2012년 AlexNet 이후, 새로운 네트워크 아키텍처가 개발되면서 사물 인식의 정확성은 인간의 능력을 뛰어넘어 더욱 향상되었습니다.
(2) 기능 확장성: 방대한 작업을 다루기 위해 일반적인 딥 신경망 네트워크 프레임워크가 특화될 수 있으며, 공통 소프트웨어(Caffe, Tensorflow, Torch, etc.) 와 하드웨어 플랫폼(GPU + CUDA) 을 쉽게 처리할 수 있습니다.
(3) 기계의 머신 러닝 (전이학습): 수 천 개의 사물 범주 인식을 통해서 학습된 이미지 피처들은 (ImageNet과 같이) 다른 시각적 작업을 수행하기 위한 여러 네트워크의 일부로, 다시 활용할 수 있습니다.
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.

삼성SDS Research America
Samsung SDSRA에 입사하여 현재는 AI 리서치 그룹에서 근무하고 있습니다. 이전에는 NEC 연구소와 HRL 연구소에서 연구 과학자로 일했으며, Visual AI R&D 경력은 1996년 University of Maryland Collage Park의 자동화연구센터(Center for Automation Research)에서 박사과정을 밟으며 시작됐습니다. AI 붐에 큰 기대를 걸며 다양한 비즈니스 use cases에 딥러닝을 적용하면서 Visual AI의 역량을 확장해 나가고 있습니다.