AI가 이상한 말을 하는 이유,
바로 ‘선호 불일치’ 때문입니다
– 언어모델 학습 품질을 높이는 셀프 큐레이션(Self-Curation) 기술을 소개합니다.

언어모델이 사람처럼 답하지 못하는 이유 중 하나는 '선호 데이터의 일관성 부족'입니다. 삼성SDS 연구소는 이러한 문제를 해결하기 위해 AI가 스스로 데이터를 정제하는 '셀프 큐레이션(Self-Curation)' 기법을 연구했습니다. 본 기술은 최대 2배 이상의 응답 품질 향상을 입증했으며, AI 튜닝의 정확도와 효율성을 획기적으로 개선하는 기반 기술로 주목받고 있습니다.
Preference Consistency Matters: Enhancing Preference Learning in Language Models with Automated Self-Curation of Training Corpora
👉 논문 바로가기
선호학습 데이터 셋의 한계 : 왜 AI는 때때로 이상한 답을 할까?
인간이 선호하는 응답을 하도록 언어 모델을 정렬(alignment)하는 것은 배포하는 모델의 신뢰성을 높이는데 있어 매우 중요합니다. RLHF나 DPO 같은 선호 학습 방법은 상대적으로 좋은 응답과 나쁜 응답을 제시하는 선호 학습 데이터셋을 활용하여, 하나의 모범 응답만 제시하는 지시문 미세 조정(Instruction Fine Tuning, IFT) 보다 더 나은 선호 정렬을 달성할 수 있도록 합니다.
그러나, 선호 학습 데이터셋은 다양한 문화적 배경을 가진 레이블 작업자에 따른 선호 차이 등 두 개의 응답에 대한 선호가 일관되지 않음으로 인한 노이즈에 취약합니다.
삼성SDS의 접근: ‘셀프 큐레이션(Self-Curation)’이란?
이를 해결하기 위해, 본 연구에서는 타겟 선호 학습 데이터셋으로 먼저 프록시 모델을 훈련하고 이를 데이터 선택에 활용하는 셀프-큐레이션 방법을 제안합니다. 이 방법은 브래들리-테리 모델 [Bradley & Terry, 1952]을 사용하여 타겟 선호 학습 데이터셋의 선호 패턴을 학습한 프록시 모델의 예측과 선호 학습 데이터셋에 함께 주어진 레이블 간의 일치 여부를 식별함으로써 프록시 모델이 예측한 선호 패턴과 일관성 있는 데이터만 선택할 수 있도록 합니다. 그 결과 선호 학습의 품질이 향상되고, 언어 모델이 더 안전하고 신뢰할 수 있는 방식으로 동작하도록 하는데 기여하게 됩니다.
데이터 큐레이션의 목표는 최초에 준비된 기본 데이터셋에서 모델의 성능을 최적화할 수 있는 부분집합을 선택하는 것입니다 [John and Draper, 1975]. 언어 모델 관련 문헌에서의 데이터 큐레이션은 대부분 모범 응답을 제시하는 지시문 튜닝, 즉 IFT의 효율성을 높이기 위한 목적으로 제안되었습니다. 이와는 달리 본 연구에서는, 더 효과적인 선호 학습을 할 수 있도록 일관성 없는 선호 데이터셋의 문제를 해결하고자 합니다.
유용함, 무해함 같은 단위 선호 목표(objective)로 학습된 개별 보상 모델(reward model)을 조합하는 방식으로 다양한 선호를 반영한 보상 모델을 만들어 선호 학습에 활용하는 연구들도 있으나, 각 선호 데이터셋에 포함된 일관성 없는 선호 레이블의 문제는 여전히 해결되지 않습니다. 본 연구에서는 경험에 의존하지 않고 완전히 자동화된 방식으로, 선호 학습 데이터셋 자체에서 학습하여 추출된 선호 패턴을 일관성 있게 따르는 데이터만 선택하는 방법을 제안합니다. 이를 통해 개별 선호 학습 데이터셋의 품질을 높이고 그로 인한 학습 효과도 향상시키는 것을 목표로 하였습니다.
선호 일관성: 나은 응답을 생성하기 위한 핵심 포인트
선호 학습 데이터셋의 일관성 없는 혼란스러운 레이블은 레이블 기준이 모호하거나 상충하는 선호를 유발할 수 있는 종류의 질문으로 인해 발생하는 경우가 많습니다. 특히 아래 예시 데이터처럼 선호-비선호(거절) 응답 간의 품질에 거의 차이가 없는 경우에, 언어 모델이 의미있는 선호에 대한 명확한 기준을 학습하기가 더욱 어렵게 됩니다.
 [그림1] 혼란스러운 선호 레이블 예시: (좌) 사람이 레이블한 것, (우) GPT-4로 레이블한 것
[그림1] 혼란스러운 선호 레이블 예시: (좌) 사람이 레이블한 것, (우) GPT-4로 레이블한 것
GPT-4를 레이블 작업자로 사용한 UltraFeedback 데이터셋으로 선호 일관성의 영향을 조사한 결과, 일관된 선호 학습 데이터로 훈련하면 같은 양의 일관성 없는 데이터로 훈련한 모델 대비 더 나은 응답을 약 2배 더 자주 생성하는 것으로 나타났습니다. 또한, 일관성 없는 데이터의 선호 레이블을 뒤집어서 학습해도 응답의 품질 수준은 거의 바뀌지 않았습니다. 이는 이 데이터가 잘못 레이블 (mislabel)된 것이 아님을 보여줍니다.
이렇게 선호 일관성이 결여되었거나 높은 선호 불확실성을 가진 모호한 데이터를 포함하여 학습을 방해하는 경향이 있는 데이터들을 본 연구에서는 'Better-not-to-learn' 데이터라는 새로운 카테고리로 지칭합니다. 이 카테고리에는 선호 레이블이 상충되거나 선호 레이블의 불확실성이 높은 데이터들이 포함됩니다. 레이블 작업자조차 자신의 선택을 확신하는 것을 어렵게 만드는 이런 데이터들은 원본 선호 데이터셋에서 적게는 10% 이내에서 많게는 30% 이상의 비중을 차지합니다.
셀프 큐레이션 방법이란 무엇이며 성능은 어느정도일까?
본 연구에서 제안하는 선호 학습 데이터셋에 대한 셀프-큐레이션 방법은 응답 품질 점수를 제공하는 프록시 모델을 학습하고 이를 사용하여 일관되지 않은 데이터를 식별하고 제거하는 과정이 포함됩니다.
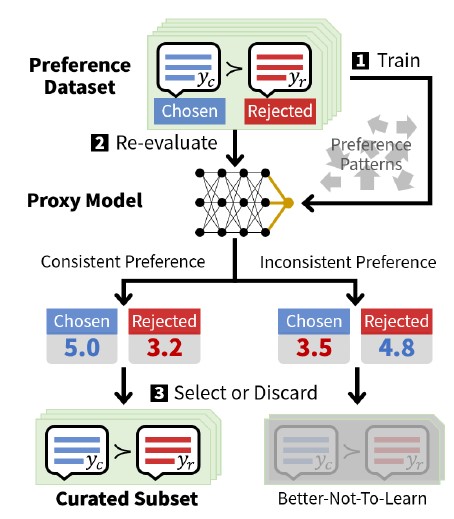 [그림2] 셀프-큐레이션 작동 방식
[그림2] 셀프-큐레이션 작동 방식
셀프-큐레이션의 세부적인 작동 방식은 그림2에 정리되어 있습니다. 앞에서 밝힌 것처럼 선호 학습 데이터셋의 일관되지 않은 레이블은 효과적인 선호 학습을 크게 방해하는데, 제안된 셀프-큐레이션은 아래와 같이 프록시 모델을 통해 일관성 없는 선호 레이블을 자동 식별하여 학습에서 배제함으로써 이 문제를 해결합니다.
(1) 타겟 선호 학습 데이터셋을 사용하여 응답의 품질 점수 출력을 통해 선호 응답을 예측할 수 있도록 프록시 모델을 훈련합니다
(2) 프록시 모델의 선호 예측과 데이터셋의 선호 레이블 간의 불일치를 식별합니다
(3) 일관된 선호를 나타내는 데이터만 학습에 사용하여 선호 학습의 효과를 높입니다.
그림3은 다양한 선호 데이터셋에 대해 대표적인 선호 학습 방법인 DPO에 셀프-큐레이션을 적용한 경우 원본 데이터를 사용하는 경우보다 더 높은 품질의 응답을 제공하게 됨을 보여줍니다. GPT-4에 의한 응답 품질 평가에서 셀프-큐레이션이 일관되게 그리고 현저하게 더 나은 응답을 생성하고 있음을 알 수 있습니다.
 [그림3] 셀프-큐레이션 vs 원본 데이터 학습 모델의 응답 품질 비교
[그림3] 셀프-큐레이션 vs 원본 데이터 학습 모델의 응답 품질 비교
DPO 외 cDPO(conservative DPO, Mitchell 2023) 및 rDPO(robust DPO, Chowdhury et al. 2024) 등의 다른 선호 학습 방법을 사용할 때도 그림4에서처럼 셀프-큐레이션은 일관되게 그리고 현저하게 원본 데이터를 사용하는 경우보다 더 나은 결과를 보입니다.
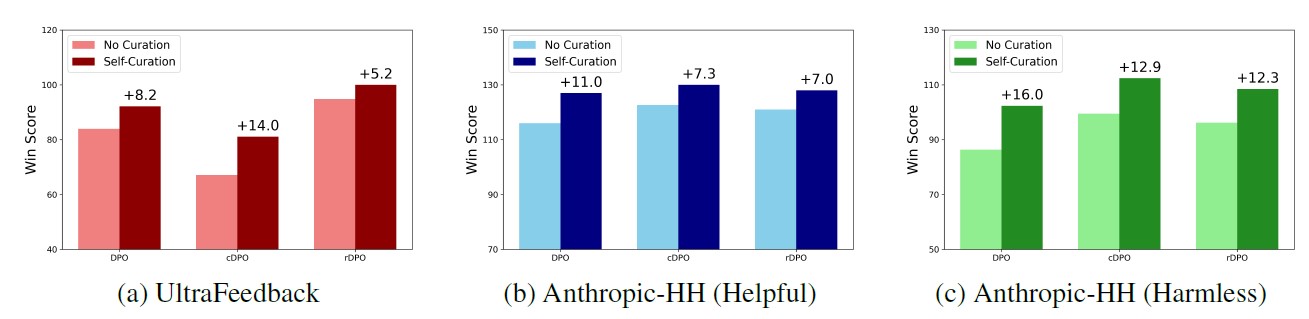 [그림4] DPO, cDPO, rDPO에서 셀프-큐레이션의 효과 비교
[그림4] DPO, cDPO, rDPO에서 셀프-큐레이션의 효과 비교
또한, 프록시 모델이 선호 데이터셋에서 일관된 선호 패턴을 추출할 수 있는 정도의 능력을 가지고 있는 한 (이를테면, 파라미터 수 30억개 이상의 사전학습 모델 기반) 어떤 프록시 모델을 선택하더라도 셀프-큐레이션이 효과적이라는 것을 실험을 통해 추가로 확인했습니다. 이상의 결과들은 모델 성능을 향상시키는 선호 학습을 수행할 때 셀프-큐레이션이 신뢰할 수 있는 전략임을 보여줍니다.
그 밖에도 셀프-큐레이션은 선호 데이터셋 규모가 작을 때도 빠르게 최고 성능으로 수렴하도록 하며, 선호 학습 수행 시간을 평균 71.7% 단축합니다. Vicuna/MT-Bench와 같은 일반화된 지시문 이행 능력을 평가하는 벤치마크에서도 우수한 성능을 보입니다. 프록시 학습을 위한 초기 계산 비용 오버헤드가 있지만, 셀프-큐레이션을 적용한 학습이 완료된 후 지속적으로 제공되는 높은 응답 품질이 초기 오버헤드를 충분히 상쇄합니다. 알고리즘1(아래 참고)은 셀프-큐레이션 과정을 좀 더 엄밀하게 표현한 것입니다. 선호 레이블의 일관성을 판단하기 위한 선호 응답과 비선호 응답 간의 보상 점수 차이(lambda)의 임계값은 기본으로 0을 사용하지만, 조금 더 큰 양의 값을 가지도록 튜닝하면 성능을 더욱 향상시킬 수 있음을 추가 실험을 통해 확인할 수 있었습니다.

연구의 의미와 앞으로 고민해야 할 포인트는?
본 연구에서는 언어 모델 학습에 사용되는 선호 데이터의 레이블 일관성 문제를 해결하기 위해 셀프-큐레이션 방법을 제안하였습니다. 프록시 모델을 활용하여 일관된 선호를 가진 데이터를 식별하고 선택하도록 하는 셀프-큐레이션을 통해서, 선호 학습 성능이 크게 향상됩니다. 이 방법은 다양한 데이터셋, 다양한 선호 학습 방법, 다양한 프록시 기반 모델 조건에서 지시문 이행 능력 비교를 통해 원본 데이터를 사용하는 경우 대비 일관되게 그리고 현저하게 효과가 있음이 검증되었습니다. 최적의 임계값을 찾는 것은 향후 연구 과제로 남아 있습니다.
👉 논문 바로가기