
오늘날 검색 모델은 단순히 정보를 찾아주는 도구를 넘어, 거대한 인공지능 시스템의 핵심으로 자리 잡고 있습니다. 특히 LLM 기반의 검색 증강 생성(Retrieval-Augmented Generation, RAG) 시스템에서는 검색기(Retriever)의 품질이 전체 성능을 좌우합니다. 하지만 문제는 이들이 시간이 지남에 따라 성능이 점점 떨어진다는 점입니다. 처음 학습했을 때는 매우 뛰어난 결과를 보이지만, 새로운 주제와 용어, 변화된 사용자 관심사가 축적되면서 점차 정확도가 낮아집니다. 그렇다면 어떻게 해야 이러한 문제를 해결 할 수 있을까요?
만약 매번 새로운 데이터가 들어올 때마다 모델을 다시 학습시킨다면 자원 낭비가 극심할 것 입니다. 반대로 오랫동안 업데이트하지 않고 그대로 사용한다면 검색 품질이 크게 저하되어 사용자 경험이 악화될 수 있습니다. 결국 핵심은 ‘업데이트가 반드시 필요한 시점’을 아는 것입니다.
이번에 소개할 논문은 바로 이 질문에 대한 새로운 해법인 GradNormIR(Gradient Norm Information Retrieval) 방법을 제시합니다. 모델이 학습한 데이터와 다른 패턴을 가진 문서가 나타나는 순간을 Gradient Norm*만으로 감지하여, 언제 재학습이 필요한지 알려주는 방법입니다. 아래에서 설명을 이어가겠습니다.
* Gradient Norm : 딥러닝 모델은 파라미터(가중치)를 조정하기 위해 손실 함수의 기울기(Gradient)를 계산하는데, 이 때 Gradient는 벡터 형태이고, 그 크기를 나타내는 값이 바로 Gradient Norm임. 본 논문에서는 새로운 문서가 들어왔을 때, 모델이 이것을 얼마나 “낯설게” 느끼는가를 Gradient Norm으로 측정함.
When Should Dense Retrievers Be Updated in Evolving Corpora? Detecting Out-of-Distribution Corpora Using GradNormIR 👉 논문 바로가기
시간이 지나면서 성능이 떨어지는 검색 모델
밀집 검색기(Dense Retriever)는 텍스트를 의미적으로 이해하는 딥러닝 기반 검색기로, 문서 내 의미적 유사성에 기초해 관련 정보를 더 정확하게 찾아내는 최신 기법입니다. 단어나 문구가 일치해야만 검색이 가능한 키워드 기반 검색과 달리 의미적으로 동일하거나 유사한 의미를 갖는 경우에도 검색 결과를 제공할 수 있기 때문에 최근 많은 산업 분야에서 활용되고 있습니다. 그러나 어떤 모델도 모든 데이터를 완벽하게 이해할 수는 없습니다. 새로운 트렌드가 등장하거나 도메인이 확장되면, 모델이 학습했던 데이터 분포와 실제 운영 환경의 데이터 분포가 달라지게 됩니다. 이 차이가 누적되면 성능 저하로 이어집니다.
기존에는 성능 저하를 방지하기 위해 정기적으로 모델을 업데이트하거나, 데이터가 조금만 바뀌어도 재학습을 실행하는 방식이 주로 사용되었습니다. 하지만 이는 막대한 시간과 비용을 필요로 하고, 반드시 성능 개선으로 이어진다는 보장도 없습니다. 다르게 말하면 실제로는 아직 모델이 충분히 잘 작동하는데도 불필요하게 업데이트하는 경우가 많았습니다. 반대로 중요한 변화가 발생했음에도 이를 인식하지 못해 업데이트가 늦어지는 경우도 있습니다. 결국 가장 합리적인 방법은 데이터 변화가 실제로 모델의 성능에 영향을 미치기 시작하는 지점을 정확히 포착하는 것 입니다.
여기서 주목해야 할 개념이 바로 도메인 이탈(Out of Domain, OOD) 입니다. 도메인 외 데이터란 모델이 학습한 데이터 분포와는 다른 특성을 가진 데이터(문서/쿼리)를 뜻합니다. 모델은 익숙한 분포의 데이터에서는 강력한 성능을 보이지만, 도메인 이탈 상황에서는 예측이 불안정해지고 오류가 늘어납니다. 따라서 도메인 외 데이터를 정확히 감지할 수 있다면, 앞서 언급한 데이터 변화가 모델의 성능에 영향을 미치기 시작하는 점을 파악할 수 있으며 이를 근거로 밀집 검색기를 언제 업데이트 할지에 대한 중요한 기준을 세울 수 있습니다.
모델의 기울기가 말해주는 비밀
삼성SDS 연구소와 대학교의 연구진은 이러한 문제를 해결하기 위해 인덱싱 이전에 도메인 이탈 데이터를 예측하는데 활용할 수 있는 GradNormIR 방법을 제안하였습니다. GradNormIR의 핵심은 새로운 데이터가 들어왔을 때, 이것이 기존 데이터와 얼마나 다른지를 측정하기 위해 복잡한 라벨링이나 추가 쿼리가 필요하지 않고, 대신에 새로운 문서를 임시 쿼리처럼 활용하여 긍정(Positive)과 부정(Negative) 샘플을 자동으로 구성한다는데 있습니다. 여기에 드롭아웃(Dropout)*을 적용해 학습 과정에 변동성을 주고, 이때 생성되는 Gradient Norm의 크기를 측정합니다. * 드롭아웃 : 일반적으로 신경망 학습 시 일부 뉴런을 무작위로 비활성화(0으로 설정)하여, 특정 뉴런이나 경로에 과도하게 의존하는 것을 방지하는 것을 뜻함. 본 논문에서는 새로운 문서가 들어왔을 때, 모델이 이 문서를 임시 쿼리처럼 사용하는데, 이 때 드롭아웃을 적용해서 모델이 문서를 벡터로 표현할 때 일부가 누락된 임베딩 벡터를 생성하게 만듦. 모델이 해당 문서에 대해 강건하다면 벡터의 일부가 누락 되어도 의미가 크게 변하지 않을 것이라는 가정을 기반으로 함.
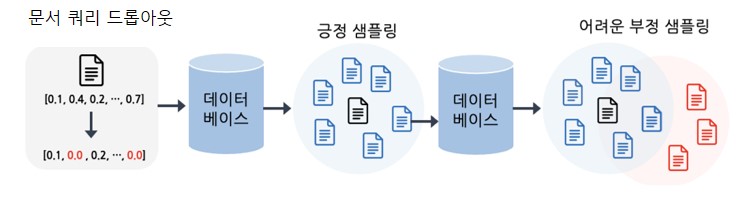 [그림1] 문서 쿼리 표현에 대한 드롭아웃과 긍정(Positive) 및 어려운 부정(Hard Negative) 샘플링
[그림1] 문서 쿼리 표현에 대한 드롭아웃과 긍정(Positive) 및 어려운 부정(Hard Negative) 샘플링
여기서 중요한 점은 Gradient Norm의 크기가 모델이 해당 데이터에 얼마나 “낯설어(Poorly Generalizes)”하는지를 보여준다는 것입니다. 만약 새로운 데이터가 기존에 학습한 분포와 유사하다면 모델은 큰 변화 없이 안정적으로 반응하고, Gradient Norm값은 작게 나타납니다. 반대로 데이터가 낯설다면 모델이 학습 파라미터를 크게 조정하려 하고, Gradient Norm 값이 커지게 됩니다. 이 단순한 계산만으로도 말뭉치 전체가 기존 데이터와 얼마나 다른지를 정량적으로 평가할 수 있습니다. 즉, Gradient Norm은 새로운 데이터가 도메인 외 데이터인지 아닌지를 알려주는 지표로 쓰이는 것입니다.
이 접근법의 장점은 별도의 라벨링 데이터나 복잡한 피드백 수집 과정이 필요 없으며, 운영 환경에서도 쉽게 적용할 수 있다는 것입니다. 실제로 새로운 문서가 추가될 때마다 Gradient Norm을 계산해 분포 차이를 평가하면, 업데이트가 꼭 필요한 시점을 사전에 감지할 수 있습니다. 이는 기존의 ‘성능이 사용자나 운영자가 느낄 수 있을 정도로 현저하게 떨어지는 모습이 보이면 업데이트하는 방식’과는 완전히 다른, 예방 중심의 전략이라고 할 수 있습니다.
실험으로 증명된 GradNormIR의 힘
GradNormIR의 효과는 BEIR(Benchmarking Information Retrieval, 정보검색 성능평가) 벤치마크 실험에서 입증되었습니다. BEIR는 뉴스, 학술 논문, 위키피디아 등 다양한 도메인을 포함해 도메인 이탈 탐지를 평가하기 적합한 데이터셋 입니다. 본 논문에서는 여러 검색기 모델을 대상으로 실험을 진행했고, 그 결과 GradNormIR 방법이 기존 방법들보다 훨씬 높은 정확도로 도메인 외 데이터를 탐지할 수 있음을 확인했습니다.
아래 표의 결과를 통해 알 수 있듯이 GradNormIR은 데이터셋 전반에 걸쳐 낮은 문서 검색률(Document Retrieval Rate, DRR)*을 유지하여, 검색 실패(Retrieval Failure)를 정확히 식별함을 보여줍니다. 문서 검색률 값이 낮을수록 더 정확한 도메인 이탈 탐지를 나타냅니다.
* 문서 검색률 : 문서 검색률로 관련 질의를 위해 문서를 정확하게 검색할 확률을 측정함. 만약 문서가 해당 질의에서 자주 검색된다면, 모델은 그 문서에 대해 잘 일반화한 것임. 반대로, 문서가 자주 누락된다면 이는 검색 실패 일 가능성이 높음
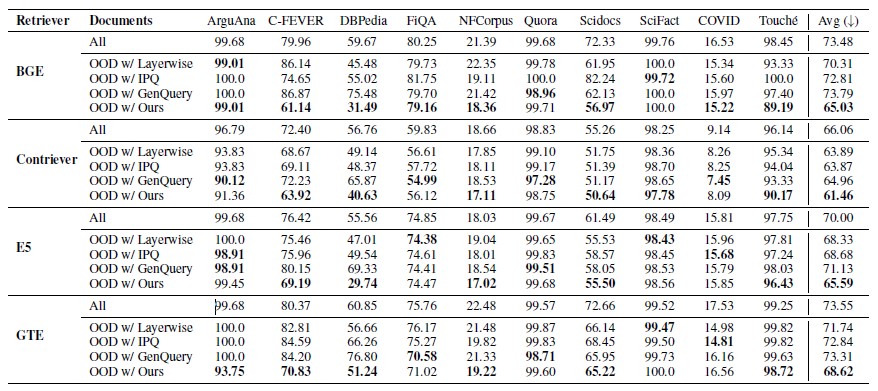 [표1] BEIR 벤치마크에서 다양한 검색기 간 도메인 이탈 문서 탐지 비교
[표1] BEIR 벤치마크에서 다양한 검색기 간 도메인 이탈 문서 탐지 비교
더 흥미로운 점은, GradNormIR로 검색 실패를 예측하는 것 외에도 검색기 선택의 기준으로 활용 될 수 있다는 점입니다. 실험에서 도메인 이탈 비율이 낮다고 평가된 검색기는 실제 검색 성능에서도 가장 높은 점수를 기록했습니다. 이는 GradNormIR가 단순히 경보를 울리는 도구가 아니라, 운영환경에서 어떤 검색기를 사용하는 것이 최적인지를 알려주는 나침반 역할을 할 수 있다는 의미입니다.
또한 이 방식은 계산 비용이 낮고 추가적인 데이터가 필요하지 않아 실용성이 매우 높습니다. 실제 서비스 운영자는 “이제 업데이트해야 할까?”라는 불확실한 고민에서 벗어나, 데이터 분포의 변화 패턴을 근거로 합리적인 결정을 내릴 수 있습니다. 불필요한 낭비를 줄이면서도 검색 품질은 안정적으로 유지할 수 있는 것입니다.
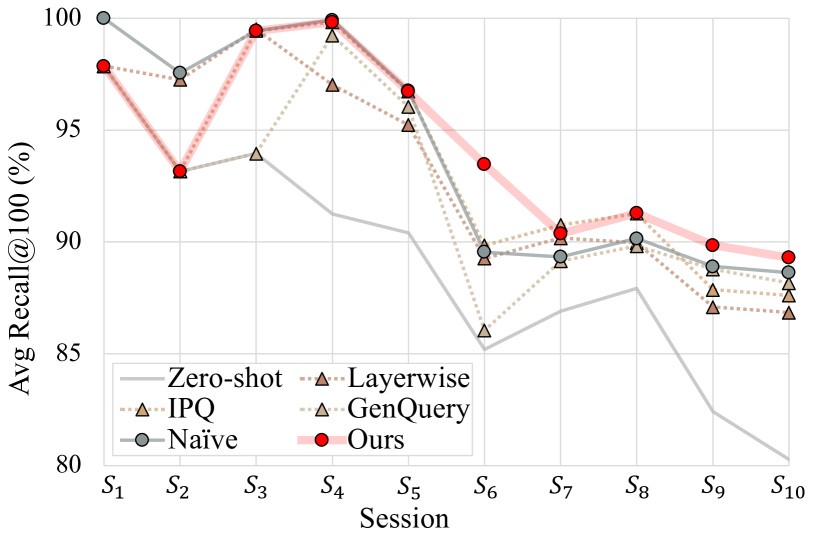 [표2] 문서집합이 순차적으로 늘어나는 상황(S1→S10)에서 업데이트 전략 별 검색성능의 변화 비교
[표2] 문서집합이 순차적으로 늘어나는 상황(S1→S10)에서 업데이트 전략 별 검색성능의 변화 비교
위 그림은 문서집합이 순차적으로 늘어나는 상황(S1→S10)에서 업데이트 전략별 검색성능(Avg Recall@100, 각 데이터셋의 상한 대비 비율)이 어떻게 변하는지를 보여줍니다. 비교군은 Zero-shot(업데이트 없음), Naïve(매 세션 재학습), 기존 방법들(IPQ, Layerwise, GenQuery) 이었습니다.
문서집합이 커질수록 전체적으로 성능은 조금씩 내려가는 경향이 있는데 이는 검색 난이도가 증가한다는 의미입니다. 특히, Zero-shot의 경우 업데이트가 없기 때문에 80% 수준으로 크게 떨어지는 것을 볼 수 있습니다. GradNormIR의 경우 초반(S1, S2)엔 업데이트를 미뤄 타 방법에 비해 낮게 시작했지만, 도메인 이탈로 판단될 때만 선택적으로 업데이트하면서 성능하락을 막고, S6 이후엔 모든 방법보다 높은 결과를 유지하는 것을 볼 수 있습니다. 즉, “필요할 때만” 재학습하는 것이 “매번” 재학습하는 것보다 더 좋다는 것을 시각적으로 증명합니다.
앞으로 더 다양한 데이터 환경에서 확장 기대
GradNormIR는 밀집 검색기 업데이트 문제에 대해 의미 있는 해답을 제시했지만, 그 잠재력은 훨씬 더 큽니다. 멀티모달 데이터, 다국어 말뭉치, 실시간 데이터 스트림 등 더 복잡한 환경에서도 유용하게 활용될 수 있습니다. 특히 소셜 미디어나 뉴스처럼 시시각각 변화하는 데이터에서 GradNormIR는 빠르게 분포 변화를 감지해 모델 업데이트 전략을 최적화할 수 있습니다.
이 연구의 진정한 기여는 단순히 성능을 높이는 것이 아닙니다. 더 중요한 점은 ‘언제 모델을 업데이트해야 하는가’라는 오랫동안 풀리지 않았던 운영상의 난제에 새로운 기준을 제시했다는 것입니다. 이는 학계뿐만 아니라 실제 산업 현장에서도 중요한 전환점을 만들어낼 수 있습니다. 앞으로 GradNormIR 같은 기법은 검색 모델 운영의 표준 도구로 자리 잡으며, 더 똑똑하고 효율적인 인공지능 시스템 구축에 기여할 것입니다.
👉 논문 바로가기