
삼성SDS 연구소는 OCR 없이 문서 이미지를 직접 이해할 수 있는 AI 기술을 개발했습니다. 핵심은 'HVFA(Hierarchical Visual Feature Aggregation)'라는 기술로, 다양한 해상도와 스타일의 문서를 빠르고 정확하게 분석합니다. OCR 엔진에 의존하지 않아 처리 속도, 정확도, 유연성이 크게 향상됩니다.
Hierarchical Visual Feature Aggregation for OCR-Free Document Understanding
👉 논문 바로가기
왜 OCR-Free 문서 이해가 필요한가요? 이러한 연구의 어려움은 무엇일까요?
OCR Engine을 사용하지 않고 문서 이미지를 이해(Document Understanding)하는 새로운 프레임워크를 아시나요? 책·영수증 같은 문서를 사진 찍어 컴퓨터에 넣으면, 보통은 먼저 글자를 따로 인식(by OCR Engine)한 뒤에 그 글자들을 분석합니다. OCR-free 방식은 이 중간 단계를 아예 건너뛰고, 이미지 전체를 한 번에 보는 AI(Transformer)가 “여기에 날짜, 금액, 제목이 있다”처럼 구조화된 결과를 바로 뽑아냅니다. 그래서 과정을 단순화해 속도와 정확도를 높이고, 글자 인식 오류 때문에 생기던 문제도 줄일 수 있습니다.
OCR-Free Document Understanding 연구와 관련된 초기 문서 이해 연구는 주로 외부 OCR 엔진을 사용해 이미지 속 텍스트를 분석하여 모델링에 활용 하였고, 이후 연구는 텍스트, 시각, 레이아웃 정보를 동시에 모델링하는 방향으로 진행되었습니다. 하지만 이런 모델은 OCR 엔진의 성능에 의존적*이며, 매끄러운(Seamless) 연결을 위해 복잡한 모듈이 필요하고, 오랜 시간이 소요된다는 한계가 있었습니다.
* 성능의존의 예: 다양한 글꼴, 필기체 텍스트, 손상된 문서 등 어려운 환경이 OCR 엔진 분석 성능에 영향을 줌
삼성SDS의 접근: 다양한 글꼴 및 스타일 처리를 더 적은 입력으로!
이에 저희는 단일 고정 크기가 아닌 다양한 크기(Multiple scales)에 걸쳐 시각적 문서를 처리 할 수 있는 Multimodal Large Language Models(이하 MLLM*)을 만들었고, 이를 통해 문서 이미지 내의 다양한 글꼴 크기 및 스타일을 효과적으로 처리할 수 있는 해결방법을 찾아 내었습니다.
* MLLM : 텍스트 뿐만 아니라 다양한 형태의 데이터를 이해하고 분석하여 텍스트로 답변을 생성하는 모델
한편, 다양한 크기를 통해 추출된 시각적 특징(Visual feature)은 LLM의 복잡도를 제곱으로 증가시키게 되는데, 모델의 증가된 처리 비용을 효율적으로 개선하며 성능 향상을 도모 할 수 있도록 교차 어텐션 기반 풀링(Cross-Attentive Pooling*)과 특징 피라미드(Feature Pyramid**) 구조를 결합한 Hierarchical Visual Feature Aggregation(이하 HVFA) 모듈을 구성하여 적용함으로써, LLM에 입력으로 주어지는 시각적 특징 토큰 수를 효과적으로 줄일 수 있었습니다.
* Cross-Attentive Pooling : 딥러닝에서 pooling 연산과 attention 메커니즘을 결합한 기법, 특히 서로 다른 두 입력(예: 쿼리와 레퍼런스, 이미지와 텍스트 등) 간의 상호 관계를 고려하여 정보를 집계하는 방법
** Feature Pyramid : 다양한 크기의 객체를 효과적으로 인식하기 위해, 여러 해상도의 feature map(특징 맵)을 계층적으로 쌓아 올린 구조를 의미
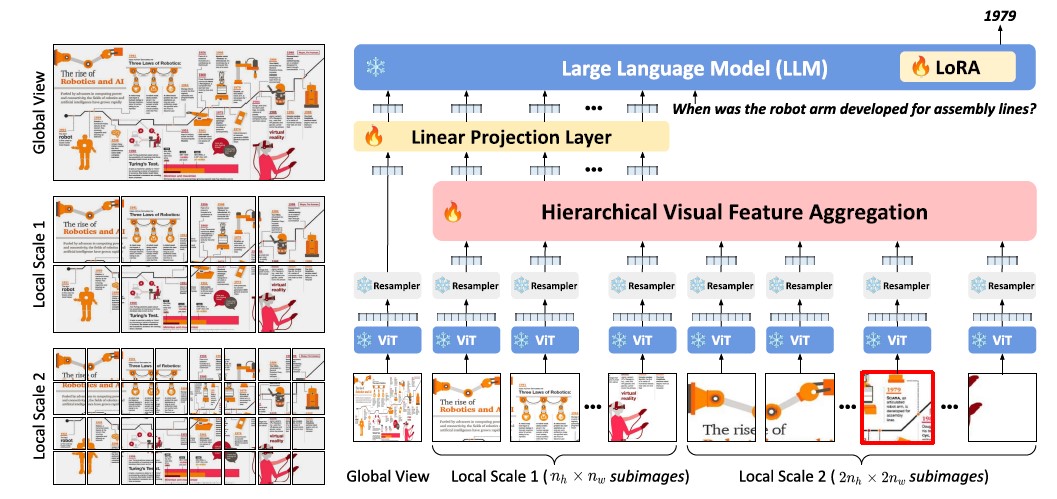 [그림1] 연구에서 제안한 프레임워크의 개요
[그림1] 연구에서 제안한 프레임워크의 개요
본 모델은 다양한 크기에서 시각적 특징을 추출하고 HVFA 모듈을 통해 특징을 집계합니다. 집계된 시각적 특징들은 LLM에 전달되어 자기회귀(Autoregressive) 방식으로 언어 응답을 생성합니다.
연구방법에 대한 상세설명
조금 더 자세하게 연구방법을 설명 해 보겠습니다. 먼저 연구를 위해 비전 인코더, 프로젝터를 이용하여 이미지에서 다양한 스케일의 시각적 입력을 생성하고, HVFA를 도입하여 지역 정보를 보존하면서 시각 특징 벡터의 수를 줄였습니다. HVFA는 앞서 소개한 것처럼 교차 어텐션 기반 풀링을 통해 동작하게 되는데, 교차 어텐션 기반 풀링은 피처 피라미드 구조(Local → Global) 내에서 작동하며 인접한 두 서브 이미지의 시각적 특징을 융합하게 됩니다. [그림2]에서와 같이 먼저 더 세밀한 서브 이미지의 시각적 특징들을 최대 풀링(Max Pooling)하여 저차원 특징 벡터를 얻고 이를 교차 어텐션의 쿼리(Pooled Q)로, 원래 시각적 특징 벡터를 키와 값(Unpooled K, V)로 사용합니다. 이러한 교차 어텐션을 통해 풀링된 특징 벡터가 원본 특징의 정보를 참조함으로써, 상세 정보를 압축 및 보존되게 하는 것입니다. 또한 개선된 풀링 특징 벡터는 더 낮은 해상도 이미지의 특징 벡터에 더해져 최종 집계 특징을 생성(Reconstruction)하게 됩니다. 이를 통해 특징 관계를 학습하고 문맥을 고려한 정보 집계가 가능하게 되었습니다.
또한, 다양한 이미지 스케일을 효과적으로 다루기 위해 다중 스케일 시각 입력 통합 프레임워크를 개발하고, 높은 해상도의 이미지에서도 상세한 정보를 캡처 할 수 있도록 보완하였습니다. 이를 통해 문서 이미지의 다양한 해상도와 비율을 더욱 효과적으로 처리할 수 있게 되었습니다.
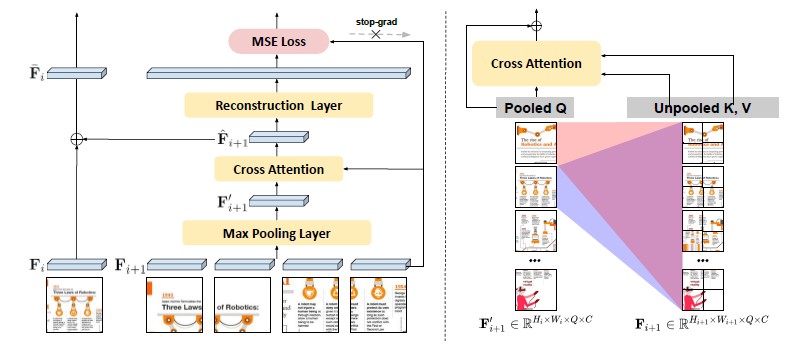 [그림2] Hierarchical Visual Feature Aggregator(HVFA) 모듈의 예제
[그림2] Hierarchical Visual Feature Aggregator(HVFA) 모듈의 예제
(왼쪽) HVFA는 특징 피라미드 계층을 활용하여 고해상도 시각적 특징을 저해상도 시각적 특징에 통합합니다.
(오른쪽) 교차 어텐션 기반 풀링에서 각 그리드는 세분화된 시각적 특징 모두에 관여하며, 보다 상세한 정보를 보존하기 위해 세분화된 특징을 반영하여 요약합니다.
성능 실험: 얼마나 잘 작동하나요?
저희는 문서 분석 모델을 훈련하기 위해 다양한 종류의 문서 이미지(표, 차트, 자연 이미지, 웹 페이지 스크린샷 등)를 포함하는 문서 지시 데이터셋 코퍼스를 사용하였으며, 이를 활용하여 문서 분석 모델을 훈련하고 평가했습니다.
데이터셋에는 다양한 유형의 문서 이미지 약 65만개가 포함되어 있고, 모델은 각 데이터셋의 테스트 분할을 활용하여 평가하였습니다. 구현 세부사항으로는 BLIP-2와 mPLUG-Owl라는 두 개의 리샘플러(Resampler) 기반 MLLM을 사용하였고, 비전 인코더는 동결상태로 유지하며, LoRA*를 이용하여 언어 모델을 미세 조정하였습니다. 또한, 다중 스케일 HVFA 모듈 구성, Reconstruction Layer Loss 통합, 상대 텍스트 위치 예측 작업 등을 수행하였습니다.
* LoRA(Low-Rank Adaptation) : 대규모 모델의 파인튜닝 시 전체 가중치를 업데이트하는 대신 저랭크 행렬을 추가하여 학습 파라미터 수를 크게 줄여 효율성을 높인 방식
결과적으로, 제안된 알고리즘은 대부분의 벤치마크에서 UReader*를 능가하였고, 사전 훈련된 MLLM의 지식을 문서 분석 모델에 성공적으로 전달하였음을 보여주었습니다.
* 사전학습된 MLLM을 기반으로 문서 분석 Instruction Tuning을 제안. 상대적으로 낮은 Training 비용과 더 다양한 문서 이미지를 처리할 수 있음(관련논문; UReader: universal ocr-free visually-situated language understanding with multimodal large language model.)
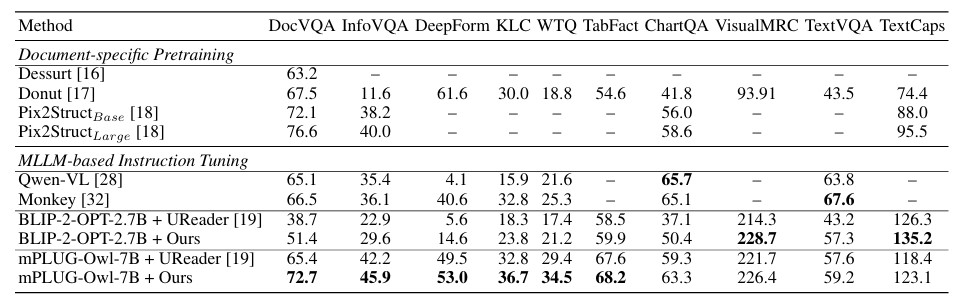 [표1] 다른 OCR-Free 문서이해 Baseline 모델과 비교(굵은 숫자가 각 열에서 가장 좋은 성능)
[표1] 다른 OCR-Free 문서이해 Baseline 모델과 비교(굵은 숫자가 각 열에서 가장 좋은 성능)
본 연구의 의미는?
이제 이번 연구의 결론을 정리 해 보겠습니다. 저희는 사전 훈련된 대규모 멀티모달 모델을 활용하여 OCR-Free로 문서 분석을 수행 할 수 있는 새로운 모델 학습 프레임워크를 제공 하였습니다. 또, 다양한 크기의 시각적 특징을 효과적으로 통합하여 문서 이미지 내의 다양한 글꼴 크기를 수용하고, 상세한 시각적 입력에 따른 비용증가를 줄이기 위해 교차 어텐션 기반 풀링을 활용한 HVFA 모듈을 제안 하였습니다. 이러한 접근 방식을 통해 다양한 문서 크기를 유지하면서 정보 보존과 계산 효율성을 균형 있게 조정 할 수 있었습니다. 더 나아가 이번 논문을 통해, 이미지 내 텍스트의 위치 정보를 고려하여 모델 가독성을 강화하기 위한 새로운 지시 튜닝 작업(Instruction Tuning Task)를 소개하고, 광범위한 실험으로 다양한 문서 이해 작업에서 탁월한 성과를 거두는 프레임워크의 효능을 입증하는 결과를 얻었습니다.
👉 논문 바로가기