
우리가 일상에서 접하는 행정 보고서나 정책 자료는 대부분 복잡한 표, 그래프, 도표로 가득합니다. 지금까지의 인공지능(AI)은 주로 텍스트 중심으로 학습되어 왔기 때문에, 복잡한 표나 그래프 같은 시각적 정보는 거의 이해하지 못했습니다. 대부분의 AI 모델은 텍스트를 중심으로 학습되어 있기 때문에, 복잡한 표 안의 숫자나 그래프나 도표의 전체적인 흐름을 놓치기 일쑤였죠. 이 문제를 해결하기 위해 삼성SDS AI연구팀은 한국 공공 문서에 특화된 새로운 AI 평가용 데이터셋, “SDS KoPub VDR benchmark”을 만들었고 이를 Hugging Face에 공개하였습니다. 여기서 VDR (Visual Document Retrieval)은 “시각 문서 검색”을 의미합니다. 즉, 단순히 문서의 텍스트를 검색하는 것이 아니라 문서 전체의 시각적 맥락(표, 그림, 레이아웃 등)을 함께 이해하고 찾아내는 능력을 말합니다. 이 벤치마크는 AI가 공공 문서의 텍스트, 표, 그림, 레이아웃 등 모든 구성 요소를 종합적으로 이해할 수 있는 능력을 평가하기 위한 최초의 시도입니다.
이번 글에서는 SDS KoPub VDR benchmark의 구축 배경, 목적, 그리고 이를 통해 기대되는 혁신과 변화를 차근차근 소개하겠습니다.
왜 “한국형 멀티모달 문서 이해”가 필요한가?
지금까지의 인공지능(AI)은 문장 중심으로 세상을 이해해 왔습니다. 그러나 현실의 행정 문서는 훨씬 더 복합적입니다. 예를 들어 “기후변화 대응 정책 보고서”에서 핵심 내용은 문장이 아니라 탄소배출량 변화 그래프나 표 속의 수치 관계에 담겨 있는 경우가 많습니다. 그럼에도 불구하고 기존의 AI 모델들은 그래프나 표 등의 시각 정보를 텍스트로 변환된 일부 숫자나 캡션 정도로만 인식했습니다. 결국 중요한 의미를 놓치거나, 문맥을 잘못 해석해 틀린 결론을 내리는 경우도 적지 않았습니다. 이런 이유로 SDS KoPub VDR benchmark(이하 KoPub VDR)는 단순히 “AI의 성능을 측정하기 위한 데이터셋”이 아니라, AI가 문서를 어떻게 ‘이해’해야 하는지를 다시 정의하는 벤치마크로 기획되었습니다. KoPub VDR은 단순한 문서 검색을 넘어, AI가 텍스트·표·그림·레이아웃을 하나의 통합된 맥락으로 이해하고 추론할 수 있는지를 평가합니다.
특히 지금까지는 고품질의 한국어 멀티모달 RAG(Retrieval-Augmented Generation) 평가셋이 존재하지 않았습니다. 대부분의 공개 벤치마크는 영어 중심이거나, 텍스트 기반 질의에만 초점을 맞추고 있었습니다. KoPub VDR은 이러한 한계를 극복하여, 한국어 공공 문서 특유의 시각적 복잡성을 반영하고, 텍스트와 시각 정보가 결합된 실제 질의 상황에서의 RAG 성능을 정밀하게 평가할 수 있도록 설계되었습니다. 또한 KoPub VDR은 단순히 “정답이 포함된 문서 페이지를 찾는” 태스크에 그치지 않습니다. 정답이 명시된 페이지가 주어지지 않은 상태에서, AI가 여러 문서의 시각적·텍스트적 단서를 종합하여 스스로 근거를 찾아내고 답변을 생성하는 진정한 멀티모달 RAG 평가를 가능하게 합니다. 결국 KoPub VDR은 한국어 문서 이해의 새로운 기준이자, “읽는 AI”에서 “이해하는 AI”로의 전환을 이끄는 첫 걸음입니다.
KoPub VDR 설계 철학과 데이터 구성
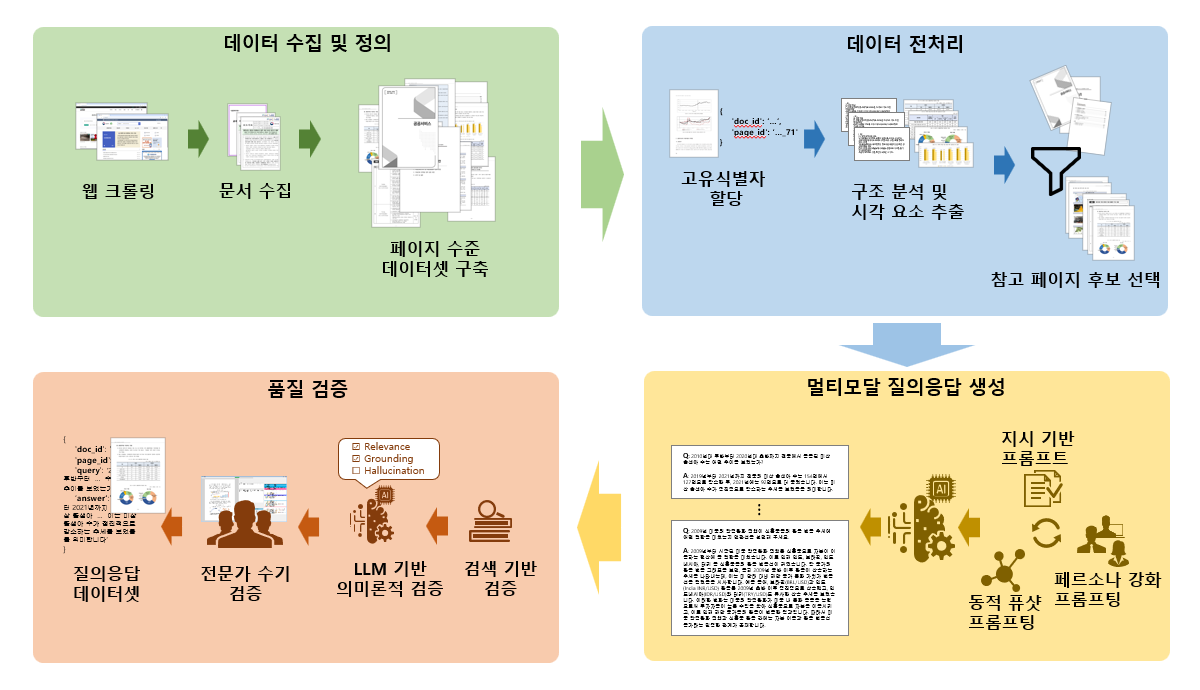 [그림1] 데이터 생성 파이프라인
[그림1] 데이터 생성 파이프라인
데이터 수집 및 정의 (웹 크롤링 → 문서 수집 → 페이지 수준 데이터셋 구축) → 데이터 전처리 (고유식별자 할당 → 구조 분석 및 시각 요소 추출 → 참고 페이지 후보 선택) → 멀티모달 질의응답 생성 (지시 기반 프롬프트, 페르소나 강화 프롬프팅, 동적 퓨샷 프롬프팅) → 품질 검증 (검색 기반 검증 → LLM 기반 의미론적 검증 → 전문가 수기 검증 → 질의응답 데이터셋)
KoPub VDR은 단순히 문서를 모아둔 데이터셋이 아닙니다.
AI가 사람처럼 문서를 읽고 이해할 수 있도록 정교하게 설계된, 4단계의 데이터 생성 파이프라인으로 만들어졌습니다.
첫째, 공공누리 제1유형(KOGL Type 1)과 법제처(MOLEG) 등에서 저작권 문제 없는 행정 문서를 대량 수집했습니다. 둘째, 각 문서를 페이지 단위로 나누어 텍스트와 이미지(표, 차트, 그림, 다이어그램) 를 함께 추출했습니다. 셋째, 최신 멀티모달 LLM(GPT-4o, Qwen2.5-VL 등)을 활용해 각 페이지에서 “질문–답변(QA)” 쌍을 자동 생성했습니다. 이때 KoPub VDR의 핵심은 “질문을 어떻게 설계하느냐”에 있습니다. 단순히 문장 내용에서 답이 가능한 질문(Text Type)만이 아니라, 표나 그래프에서만 정답을 찾을 수 있는 시각형(Visual Type), 그리고 텍스트와 시각 정보를 함께 이해해야 답을 찾을 수 있는 교차형(Cross Type) 질의까지 포함했습니다. 예를 들어 “정책 목표가 무엇인가?”는 텍스트형 질문이지만, “산업별 탄소배출량의 변화 추이는?”은 그래프를 읽어야 하는 시각형 질문이며, “그래프에서 증가 추세를 보이는 부문은 본문에서 어떤 정책의 영향을 받았는가?”는 교차형 질문에 해당합니다. 이처럼 질의 유형을 다양화함으로써, KoPub VDR은 AI가 문서를 ‘읽는’ 수준을 넘어 ‘이해하고 추론하는’ 능력까지 평가할 수 있도록 설계되었습니다. 마지막으로, 연구진이 직접 만든 검수 툴로 모든 질문-답변 쌍을 하나씩 확인하며 질문이 정확히 문서와 일치하는지 검증했습니다. 이 과정을 통해 총 361개의 문서, 40,781개의 페이지에서 AI의 성능을 정밀하게 평가하기 위한 핵심 질문-답변 600쌍이 완성되었습니다. 사회, 환경, 산업, 교육, 외교, 금융 등 6개 주요 도메인을 포함해, 한국 행정문서의 실제 구조를 그대로 반영했습니다. 즉, KoPub VDR은 단순히 데이터가 아니라 한국 행정정보의 축소판이자, AI의 이해력을 시험하는 종합 교과서입니다.
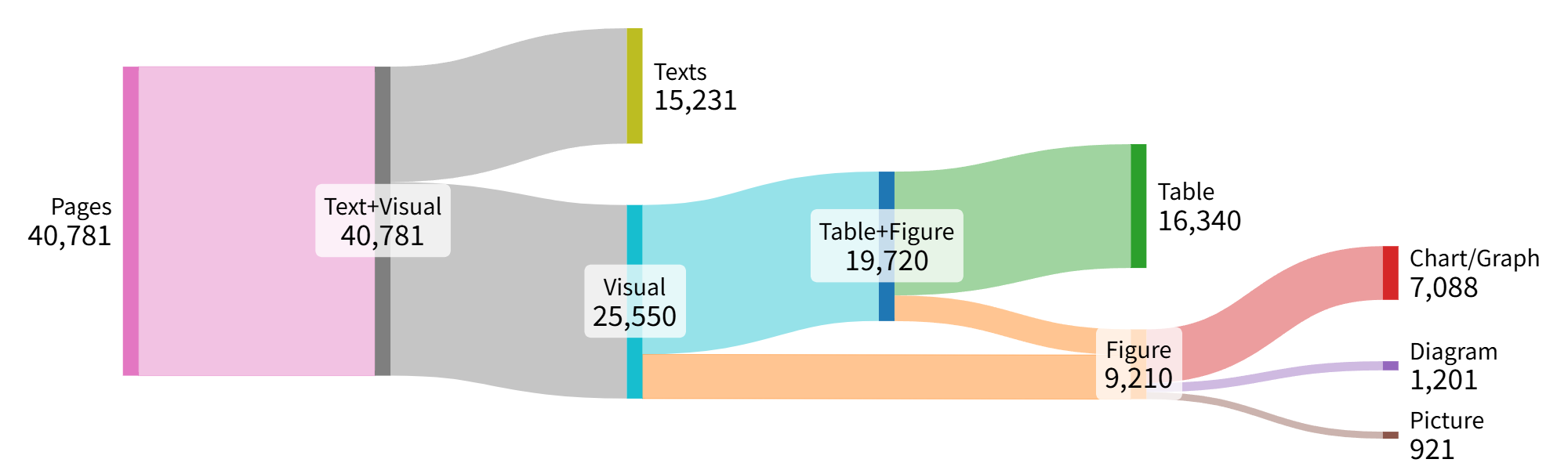 [그림2] 코퍼스 데이터 시각 요소 별 분포
[그림2] 코퍼스 데이터 시각 요소 별 분포
코퍼스 데이터 시각 요소 별 분포 그래프로 pages(40,781) → Text+Visual(40,781) → Text(15,231) / Visual(25,550) → Table+Figure(19,720) → Table(16,340) / Figure(9,210) → Chart/Graph(7,088) / Diagram(1,201) / Picture(921)
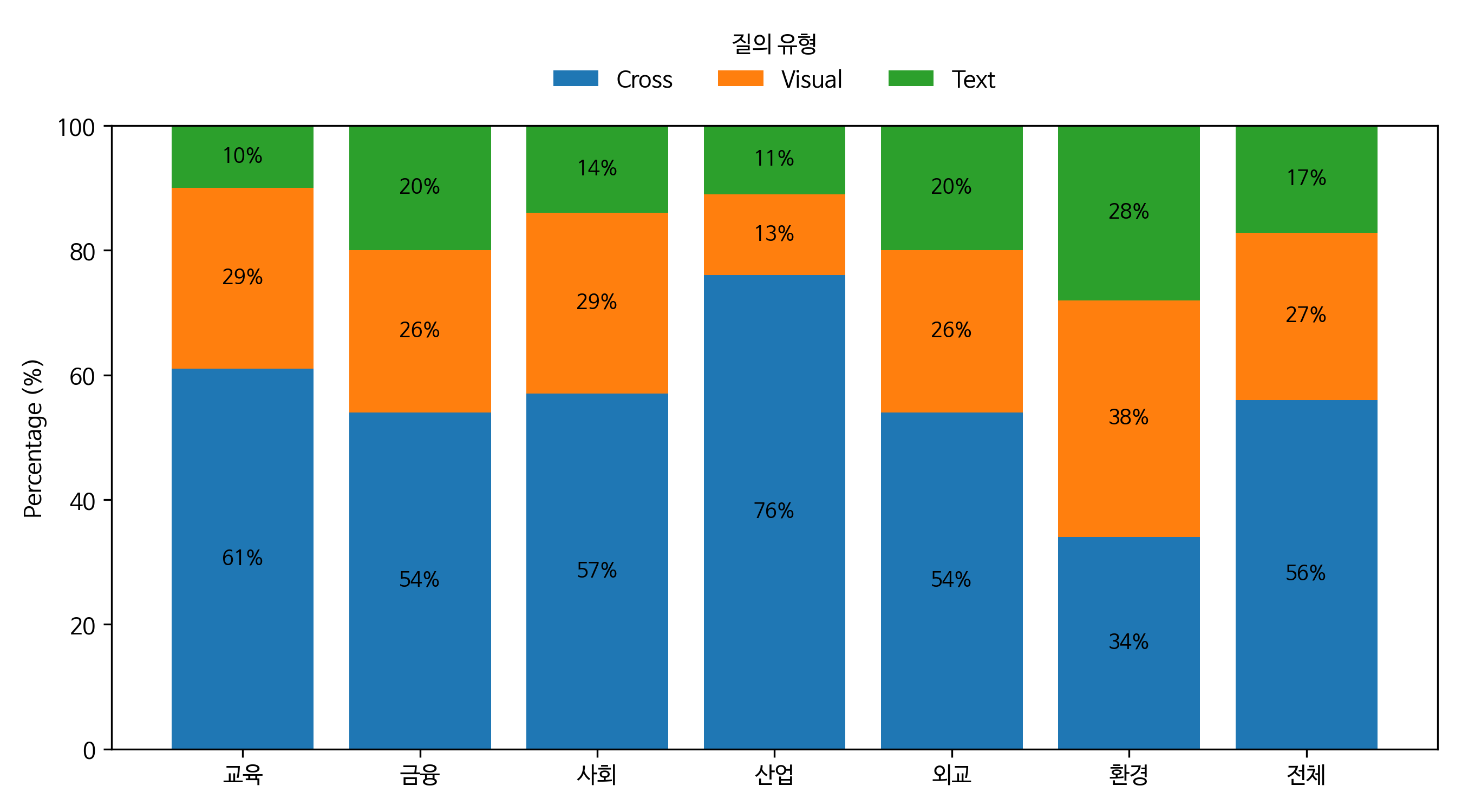 [그림3] 도메인 별 질의 유형
[그림3] 도메인 별 질의 유형
도메인 별 질의 유형 그래프로 퍼센트로 나뉘며 각 도메인 별 유형 순서는 Cross, Visual, Text 입니다.
- 교육: 61%,29%,10%
- 금융: 54%,26%,20%
- 사회: 57%,29%,14%
- 산업: 76%,13%,11%
- 외교: 54%,26%,20%
- 환경: 34%,38%,28%
- 전체: 56%,27%,17%
실험을 통해 검증한 ‘문서 이해력’의 변화
KoPub VDR의 목적은 단순히 “모델을 테스트한다”가 아닙니다.
AI가 어떤 상황에서, 어떤 방식으로 시각 정보를 활용할 수 있는지를 비교 분석하는 것이 핵심입니다. 이를 위해 두 가지 태스크를 설정했습니다:
-
Task 1: PDF를 텍스트로 변환된 데이터 내에서 검색 (텍스트 추출 tool 기반(e.g. pypdf*))
* pypdf: PDF 파일을 읽고, 조작하고, 생성하 SKTDH는 무료 오픈 소스 Python 라이브러리 - Task 2: PDF 내 이미지 자체에서 검색 (이미지, 표, 레이아웃 등 시각 요소 포함)
저희 연구팀은 다양한 최신 임베딩 모델들의 각 태스크별 성능을 비교했습니다. (BGE-M3, Jina-Embedding-v4, Nomic-Embed-Multimodal-7B, 공공 데이터셋으로 학습 데이터를 생성하고 자체 학습한 SDS-Multimodal-Embedding 7B)
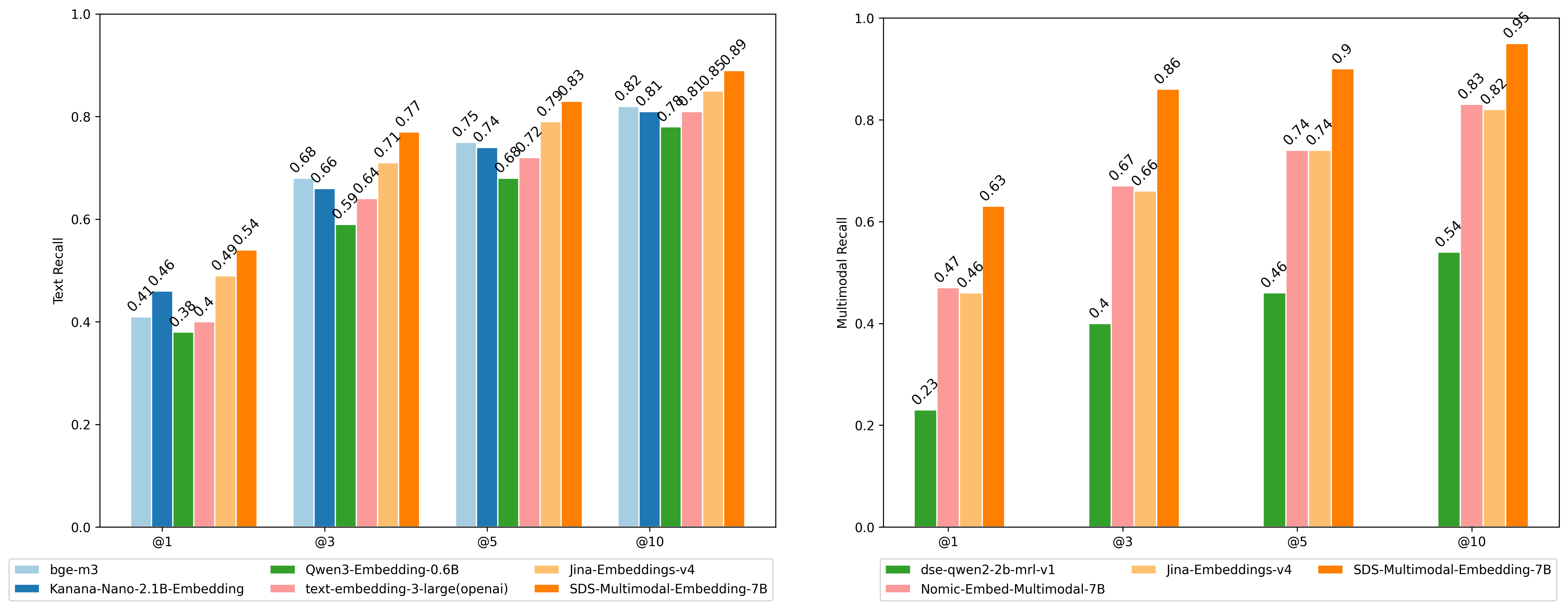 [그림4] Text vs. Multimodal 검색 결과 (Recall@k)
[그림4] Text vs. Multimodal 검색 결과 (Recall@k)
Text vs. Multimodal 검색 결과 그래프 입니다.
왼쪽 그래프
값은 Text Recall 값이며 항목은 @1, @3, @5, @10 이 있고 각 항목 내 값의 순서는 Bge-m3/Kanana-Nano-2.1B-Embedding/Qwen3-Embedding-0.6B/text-embedding-3-large(openai)/Jina-Embeddings-v4/SDS-Multimodal-Embedding-7B 입니다.
- @1 - 0.41/0.46/0.38/0.4/0.49/0.54
- @3 - 0.68/0.66/0.59/0.64/0.71/0.77
- @5 - 0.75/0.74/0.68/0.72/0.79/0.83
- @10 - 0.82/0.81/0.78/0.81/0.85/0.89
오른쪽 그래프
값은 Multimodal Recall 값이며 항목은 @1, @3, @5, @10 이 있고 각 항목 내 값의 순서는 dse-qwen2-2b-mrl-v1/Nomic-Embed-Multimodal-7B/Jina-Embeddings-v4/SDS-Multimodal-Embedding-7B 입니다.
- @1 - 0.23/0.47/0.46/0.63
- @3 - 0.4/0.67/0.66/0.86
- @5 - 0.46/0.74/0.74/0.9
- @10 - 0.54/0.83/0.82/0.95
결과는 명확했습니다. 시각 정보가 많은 페이지에서는 멀티모달 임베딩 모델이 훨씬 강력한 성능을 보였습니다. 특히, 저희가 자체적으로 파인튜닝한 SDS-Multimodal-Embedding-7B 모델은 복잡한 문맥이나 시각적 단서가 섞인 질문에서도 안정적인 응답을 보였습니다. 그림 4에서 Recall@1(가장 정확한 문서를 첫번째로 찾아낼 확률)은 기존의 텍스트 임베딩 모델(bge-m3)보다 텍스트 검색 기준 31% 이상(0.41 vs. 0.54), 멀티모달 검색 기준 53% 이상(0.41 vs. 0.63) 향상된 수치를 보였습니다. 텍스트 기반(Task 1)과 이미지 기반(Task 2) 검색을 통합 분석한 결과, SDS-Multimodal-Embedding-7B는 두 환경 모두에서 가장 일관된 성능을 보였으며, 입력 모달리티를 텍스트에서 이미지로 전환했을 때 Recall@5 기준 8.43%(0.83 vs. 0.90) 상승했습니다. 이 차이는 단순히 모델 용량이 아니라, 표의 수치·그래프의 범례·캡션 같은 시각 단서를 정확히 활용하는 능력에서 기인했습니다. 즉, 텍스트로는 포착되지 않던 시각적 구조와 맥락이 AI의 판단에 직접적인 근거로 작용하기 시작한 것입니다.
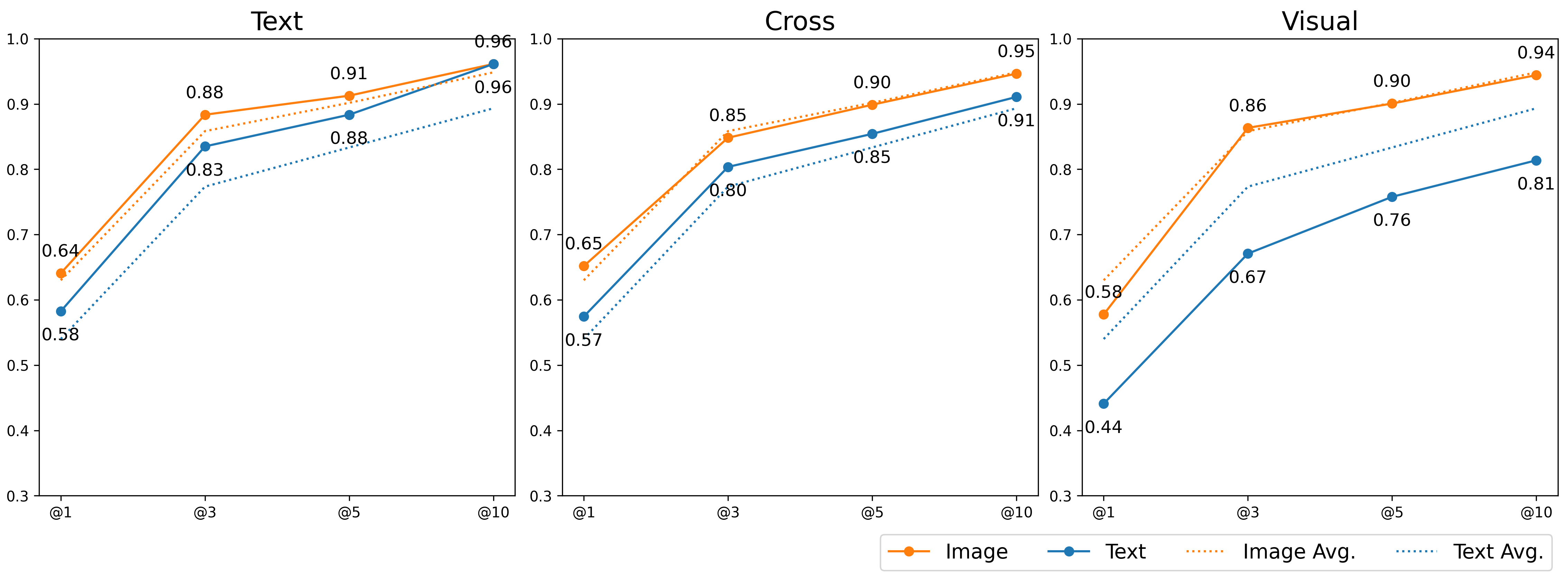 [그림5] 질의 유형 별 Recall@k 성능 비교 (Task 1 vs. Task 2)
[그림5] 질의 유형 별 Recall@k 성능 비교 (Task 1 vs. Task 2)
질의 유형 별 Recall@k 성능 비교 (Task 1 vs. Task 2) 그래프로 Cross,Text,Visual 총 3개의 그래프가 있습니다. 각 그래프 별로 항목은 @1, @3, @5, @10 이 있으며 각 항목 내 값의 순서는 Image/Text 입니다.
Text 그래프
- @1 - 0.64/0.58
- @3 - 0.88/0.83
- @5 - 0.91/0.88
- @10 - 0.96/0.96
Cross 그래프
- @1 - 0.65/0.57
- @3 - 0.85/0.80
- @5 - 0.90/0.85
- @10 - 0.95/0.91
Visual 그래프
- 0.58/0.44
- 0.86/0.67
- 0.90/0.76
- 0.94/0.81
질의 유형 별(Text, Visual, Cross) 성능 비교에서 멀티모달 검색의 효과는 압도적이었습니다(그림 5). 특히 시각적인 내용을 알아야 하는 Visual 타입에서 SDS-Multimodal-Embedding-7B 모델은 Task 2에서 Visual 질의 Recall@3 = 0.86, Recall@10 = 0.94를 기록했습니다. 이는 동일 모델에 대한 Task 1의 Visual 질의 성능 대비 Recall@3 기준 +28% (0.86 vs 0.67), Recall@10 기준 +16% (0.94 vs 0.81) 향상된 결과입니다. 또한 다른 질의 유형들에서도 일관적으로 텍스트로 검색하는 것보다 멀티모달로 검색하는 것의 검색 성능이 높게 나왔습니다.
결국, 문서 내 시각적 표현이 정보의 핵심 단서로 작동하는 환경에서는 “시각 정보 접근이 가능한 구조”가 곧 모델의 질의응답 정확도를 결정한다는 결론에 도달했습니다. 이는 공공문서처럼 표와 그래프가 핵심 정보를 담고 있는 데이터셋에서 멀티모달 검색이 선택이 아니라 필수 요건임을 명확히 입증한 결과입니다.
지금까지 말씀드린 데이터 수집과 전처리, 멀티모달 질문과 답 생성 방법, 그리고 실험 과정과 결과 등에 대한 보다 자세한 내용은 테크니컬 리포트(SDS KoPub VDR: A Benchmark Dataset for Visual Document Retrieval in Korean Public Documents) 를 통해서 확인해 보실 수 있습니다.
앞으로의 방향 - 공공 AI의 새로운 표준으로
KoPub VDR은 Hugging Face를 통해 대외 공개된, 한국형 공공 문서 이해 벤치마크입니다.
단순한 연구 결과물이 아니라 “공공 문서를 이해할 수 있는 한국형 AI 생태계”를 위한 출발점이죠. 이 벤치마크는 앞으로 멀티모달 RAG(문서를 찾고, 읽고, 답변하는 AI), Vertical LLM/LMM(산업별 특화 AI) 등 다양한 기술의 기반이 됩니다. 예를 들어, 정부 보고서에서 관련 통계를 자동으로 찾아 해석하거나, 정책 문서의 표·그래프를 요약해주는 AI 서비스에도 직접 응용할 수 있습니다.
공개를 통해 국내외 연구자들은 동일한 데이터와 기준으로 모델 성능을 비교·분석할 수 있으며, 한국어 멀티모달 AI 연구 생태계의 투명성과 확장성 또한 함께 높아질 것입니다. QA 생성과 검수도 점차 자동화되어, 더 빠르고 큰 규모의 멀티모달 데이터가 만들어질 것입니다. 결국 KoPub VDR은 “AI가 공공 문서를 제대로 읽을 수 있는가?”라는 질문에 대한 가장 체계적이고 실용적인 답변이 될 것입니다. 한국형 공공 AI의 새로운 표준이, 지금 이 벤치마크에서 시작되었습니다.
👉 관련 링크 바로가기