loading...

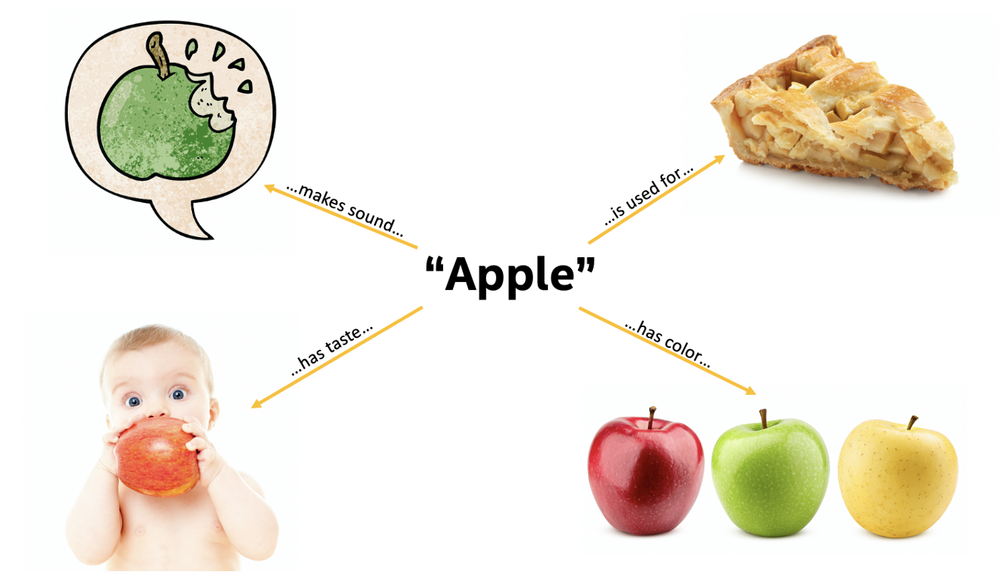 Humans understand an apple in various ways. (Source: Intel Labs)
Humans understand an apple in various ways. (Source: Intel Labs)
Related Articles
- Brity Copilot, Now Evolved into Your Personal Agent! (Featuring the case of CMC Global in Vietnam)
-
Over the Coming Wave
- Part 2 Strategies for AI Risk Management -
Over the Coming Wave
- Part 1 AI Risk Perception and Assessment Framework - What Are AI Agents?
- The Rise of Generative Enterprises: Reshaping the Future of Business With Generative Technologies
- ESG Framework for Sustainable AI Business
Related Solution