빅데이터 기술 - 범용 분산 클러스터 컴퓨팅 플랫폼 ' 스파크 '

Spark가 아파치 프로젝트로 릴리즈 된지 3년이 지난 지금, 데이터 배치 처리에 있어서 Spark는 이제 가장 많이 쓰이는 프로젝트가 되었다. Spark가 인기가 있는 이유는 여러가지가 있지만 그 중에서도 엔진의 빠른 속도와, 그 엔진을 기반으로 한 GraphX, MLlib, Streaming, SQL 등과 같은 여러가지 모듈이 지원된다는 점을 꼽을 수 있다. 이런 모듈들이 동작하는데 중요한 역할을 하는 것이 바로 Spark 엔진 이다.
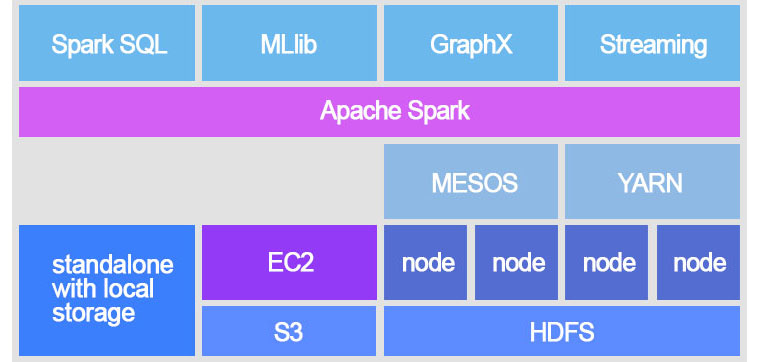
Spark는 데이터 분석을 빠르고 쉽게 하기 위한 기능들이 많이 개발되어 있어, 빅데이터 통계분석과 머신러닝 등에만 특화된 엔진으로 생각 하기 쉽다. 하지만 데이터의 개념을 CSV와 같은 일반적인 데이터뿐 아니라 OS, 어플리케이션, 기타 인터페이스 간의 주고받는 데이터로 확장하면 Spark를 분산처리를 위한 플랫폼으로 사용할 수 있다. 그래서 Spark의 엔진 자체만 놓고 보면 클러스터 컴퓨팅을 하기 위한 프레임워크처럼 추상화, 일반화 되어있고 범용적이다. 사실 Spark의 전신이 된 MapReduce의 경우도 빅데이터 분석이 인기를 얻으면서 데이터 처리에 대부분 조명을 받았지만 중심은 일반적인 작업(Task)의 분산처리를 목적으로 하고있다. 때문에 Spark 문서의 제일 첫 문장이 “아파치 Spark는 빠르고 일반적인 목적의 클러스터 컴퓨팅 시스템 입니다.” 인 것이다. 이번 포스트 에서는 Spark 엔진의 동작 구조를 살펴보고, 이를 어떻게 활용 할지 알아보자.
기본 컨셉
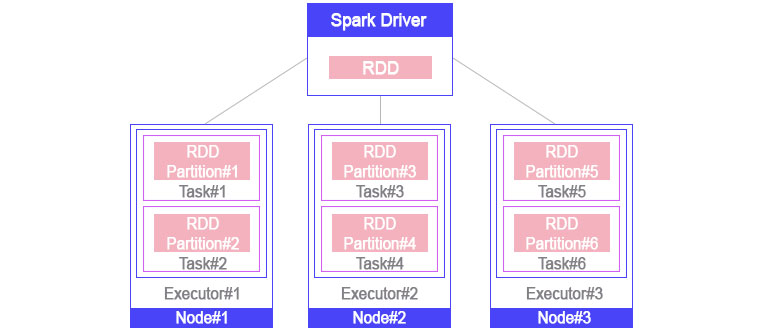
Spark의 기본컨셉은 드라이버(Driver)에서 정의한 여러 파티션(Partition)들에 대해 사용자의 특정한 작업(Task)을 각 노드의 실행기(Executor)가 수행해 주는 것이다. 이때 파티션 수가 여러 개 이고 이들을 각각의 노드에 퍼뜨려 수행하기 때문에 병렬처리 엔진이라고 부른다. 이런 일련의 처리 과정을 보다 효율적으로 수행하기 위해 Pipeline, Cache, DAG Scheduler같은 개념이 들어가 있는 것이 바로 Spark 이다.
- Driver : Spark Context를 생성하고 작업을 실행하는 사용자 어플리케이션
- Executor : Driver에게서 전달받은 작업을 수행하고, 필요시 결과를 Driver로 전송
- Cache : 수행이 끝난 결과 Partition을 해당 노드의 메모리나 디스크에 임시로 저장
- Pipeline : Lazy Execution 모델을 활용하여 네트워크 전송이 필요한 작업(Shuffle) 전의 작업들을 하나로 묶어 실행하는 방식
- DAG(Directed Acyclic Graph) Scheduler : Driver에 존재하며 작업 실행시 RDD와 RDD간의 순서를 스케쥴링 하고, Task를 어디로 보내야 가장 빠른지(Locality를 기준으로 하는 Preferred Location) 선택하여 전체 작업의 속도를 높임

RDD의 범용성
Spark하면 RDD를 빼놓을 수 없다. RDD는 Resilient Distributed Dataset의 약자 인데, 이 Dataset이라는 표현 때문인지 RDD를 데이터베이스의 테이블 공간 같이 실제 데이터를 담고 있는 것으로 생각하기 쉽다.
하지만 RDD는 깊게 보면 작업명령서에 가까운데 그 이유는 드라이버에서 RDD가 생성될 때 파티션 정의와 실행할 작업, 선후관계에 관한 정보를 담고 있는 객체이기 때문이다. 위 그림에서 노드 별로 있는 Task들과 Partition들이 실제로는 드라이버의 RDD에 있는 객체를 복사한 것이다.
RDD는 추상화된 객체이기 때문에 범용적으로 사용할 수 있고, 이를 상속받아 많은 기능을 구현 할 수 있다. 그래서 목적에 따라 여러 RDD들을 만들어 나가고, 이를 컨트롤 할 수 있는 API들을 더해 다양한 3rd party 라이브러리들이 생겨났다. RDD를 목적에 맞게 구현할 때 필요한 것들을 살펴보자.
- (필수) def getPartitions: Array[Partition]
드라이버에서 처음 한번만 실행되는 함수로, 이 RDD를 실행할 때 각 노드로 보낼 파티션들을 정의한다.
- (선택) def getDependencies: Seq[Dependency[_]]
드라이버에서 처음 한번만 실행되는 함수로, 이 RDD와 부모RDD의 관계를 정의한다.
- (필수) def compute(split: Partition, context: TaskContext): Iterator[T]
각 노드에서 해당 파티션(split)이 주어졌을 때 어떻게 처리할지 실제 비즈니스 로직을 구현한다.
- (선택) def getPreferredLocations(split: Partition): Seq[String] = Nil
파티션에 대한 작업을 수행할 때 어느 host에서 수행하는 것이 가장 좋은지 순서대로 반환. 파티션이 특정 노드에 Locality가 있을 경우 구현한다.
이 함수들의 조합으로 각 파티션별 샘플링을 수행하는 SampleRDD, Cassandra 데이터를 읽어오는 CassandraRDD, OS Command를 실행해서 나온 표준출력을 처리하는 PipedRDD등 수많은 RDD들을 생성할 수 있다. 예를 살펴보자. 가령 HttpRDD는 웹에서 여러 파일을 한번에 다운로드 받아 내용을 라인별로 출력하는 RDD라 하면,
- def getPartitions: Array[Partition] -> URL을 가지고 있는 HttpPartition을 생성하여 Array[HttpPartition]으로 반환.
- def getDependencies: Seq[Dependency[_]] -> 다운로드하는 것은 부모 RDD의 데이터와 연관성이 없으므로 구현하지 않는다.
- def compute(split: Partition, context: TaskContext): Iterator[T] -> split 변수에는 HttpPartition이 들어오게 된다. 이 HttpPartition에 URL이 있으므로 이를 가져와 다운로드 하고, Read Stream을 통해 라인별로 Iterator[String]으로 반환.
- def getPreferredLocations(split: Partition): Seq[String] = Nil -> 웹 접속이므로 어느 노드에서 수행해도 상관없으므로 구현하지 않는다.
이렇게 하면 프로그램을 구성하기에 따라 웹 에있는 데이터를 Spark에 있는 기능을 사용해 바로SQL을 실행하거나 머신러닝을 수행 할 수 있다. 대표적인 원격 데이터 스토리지인 S3에 있는 Bucket밑의 파일들을 병렬로 읽어오는 기능을 이런식으로 구현하면 된다.
Spark의 메세지 프레임워크
RDD외에도 클러스터 컴퓨팅을 구현하기 위하여 Spark 내부에 Netty를 활용한 RpcEnvironment와 같은 메세지 프레임워크가 내장되어 있는데, 이를 이용하면 런타임때 클러스터간 메시지 전송에 관련된 기능을 구현할 수 있다. 1.x버전까지의 Spark는 이부분이 Akka(http://akka.io)로 되어있었으나 2.x에서 Akka 종속성을 제거하고, RpcEnv라는 이름으로 새로 구현되었다. RpcEnv를 Akka에 대응하는(괄호안의 객체) 구성요소에 맞춰 비교해보면 구조 자체는 변한 것이 없는 것을 알 수 있다.
- RpcEndpoint(Actor) : RpcEnv(ActorSystem)에 등록하여 전송된 메세지를 어떻게 처리할지 메세지 종류별 로직을 구현한다.
- RpcEndpointRef(ActorRef) : 원격 RpcEndpoint를 접근하기 위한 주소 정보를 가지고 있는 참조 객체.
- RpcEnv(ActorSystem) : RpcEndpoint들을 가지고 있는 하나의 시스템을 의미. 여러 시스템이 한 어플리케이션에 존재할 수 있다.
딥러닝에의 활용
클러스터링과 분산처리가 필요한 분야는 많지만 그 중에서도 최근에 가장 많이 언급되는 분야는 딥러닝일 것이다. 학습과 데이터 양이 방대한 딥러닝 모델을 만들기 위해 파라미터 서버를 활용한 스케일 아웃 방식이 많이 사용 된다.
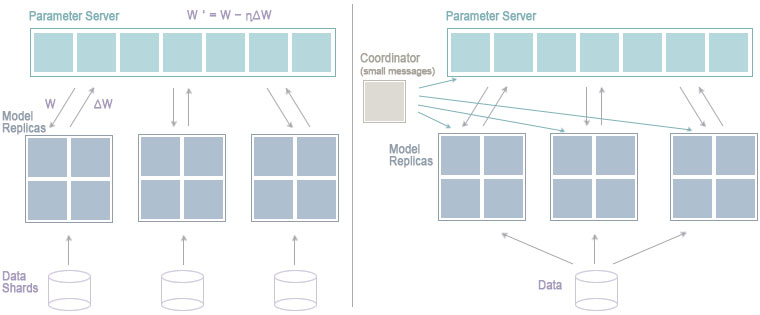
이 모델을 위에 열거한 Spark의 특징을 활용하여 처리 하는 방식에는 크게 두가지가 있다.
- Spark에 연계하여 동작하는 방식
- Spark 엔진 자체를 확장하는 방식
1번의 경우 Spark에서 단순히 병렬실행만 하고 모델 동기화를 위한 파라미터의 업데이트와 실제 데이터의 처리는 다른 어플리케이션에서 하는 특징을 가지고 있다. CaffeOnSpark, Keras(Elephas), MXNet, Paddle, TensorFlowOnSpark 가 여기에 속한다.
2번의 경우 대부분 Spark의 자체 기능만을 사용 또는 개선하여 구현된 형태를 말하고, BigDL, DeepDist, DeepLearning4J등이 여기에 속한다.
최근 필자가 관심있게 보고있는 프로젝트는 BigDL이다.
BigDL은 인텔에서 개발하고 있는 딥러닝프로젝트로 2017년부터 오픈소스로 공개되었다. 이 프로젝트의 컨셉이 다른 딥러닝 프로젝트에 비해 차별성을 가지는 이유는, 기존에 쓰고 있던 빅데이터 에코시스템에 자연스럽게 녹아드는 것이 목표 이기 때문이다.
예를들면, 이미 빅데이터 분석을 하기 위해 서버를 많이 확보한 고객이 딥러닝을 통해 분석모델을 보완 하고 싶을 때 기존시스템과의 연계성, 성능을 고려하지 않을 수 없는데, 대부분의 고객들이 가지고 있는 서버는 원래 목적이 딥러닝이 아니기 때문에 GPU가 존재하는 서버가 거의 없다.
BigDL은 이런 점에 집중해서 기존에 있는 자원에 쉽게 적용하고, CPU 만으로도 딥러닝 학습에 좋은 효율을 내도록 만들어 틈새시장을 공략한 것이다. 물론 최대 성능을 내기 위해서 인텔 CPU만의 라이브러리를 사용해야 되므로 자사제품의 Lock-In효과를 얻고, 딥러닝 분야에서 GPU에 매번 비교당하는 CPU의 위상을 다시 높이려 한 것으로 보이지만, 인텔의 서버용 CPU 시장 점유율이 2017년 기준으로 99%에 달한다는 것을 생각하면, 많은 고객이 적용하기 쉽다는 데서 얻는 이익을 무시할 수가 없을 것이다.
인텔에서 말하는 BigDL을 사용해야 하는 이유는 다음과 같다.
- 딥러닝에 사용할 많은 양의 데이터가 이미 저장되어 있는 기존의 Spark/Hadoop 클러스터를 활용해 모델을 만들고 싶을 때
- 기 구축된 Spark 빅데이터 분석 시스템에 딥러닝 기능을 추가하고 싶을 때
- Spark/Hadoop 클러스터를 딥러닝 시스템으로 업그레이드 하고 싶을 때
- 딥러닝 전문가가 아닌 데이터 사이언티스트가 딥러닝을 쉽게 접근하고 싶을 때
BigDL의 기능을 잠깐 살펴보면, 위에 언급한 “Large Scale Distributed Deep Networks”를 구현하기 위해 Spark의 Rpc네트워크를 파라미터 서버로 활용해 P2P Reduce 알고리즘을 구현하고 있다.
또한 SparkAPI에 자연스럽게 녹아들어 있다 보니 사용하던 MLlib의 Pipeline에 직접 연결할 수 있다는 점도 눈에 띈다. 이렇게 되면 기존에 사용하던 Transfomer Pipeline(데이터의 전처리를 수행) 끝에 BigDL모델을 붙여서 하나의 Pipeline으로 구성할 수 있다.
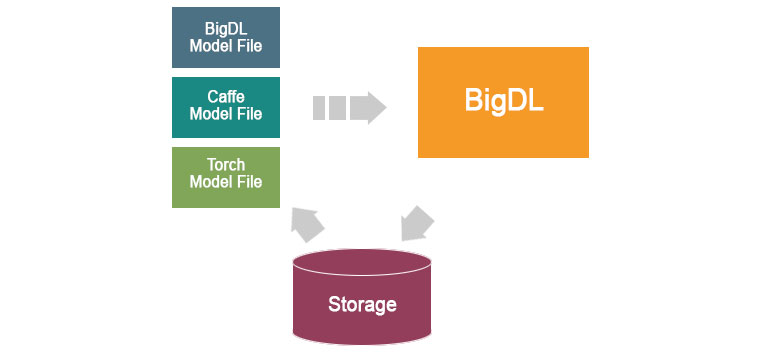
다른 딥러닝 프로젝트의 모델을 로드해서 사용 할 수 있다는 것도 장점이다. 아래 그림과 같이 BigDL은 물론 Caffe나 Torch의 모델을 로딩하여 스냅샷으로 저장하고 다른사람과 공유하거나, 나중에 불러와 튜닝할 수도 있다.
지금까지 Spark에 대해 소개하고 딥러닝에 활용된 모습까지 살펴보았다.
AI시대에 접어들어 데이터 사이언티스트의 역할이 점점 중요해 지는 시점에, 분석역량과 더불어 이러한 기술적인 부분에도 지속적으로 관심을 갖고 학습한다면, 고급 데이터 사이언티스트로써 한단계 더 발전할 수 있는 계기가 될 것이라고 확신한다.
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.

Senior Engineer, Analytics Platform Lab, Samsung SDS
Samsung SDS Certified Professional
삼성SDS 연구소 분석플랫폼Lab 소속이며, 소프트웨어 개발, 빅데이터 아키텍쳐, 머신러닝에 관한 지식과 업무 경험을 바탕으로 현재 삼성 SDS Brightics 솔루션 개발을 담당하고 있습니다.