

Technology Toolkit 2021 is a technical white paper describing core technologies that
are being researched and developed by Samsung SDS R&D Center. We would like to introduce in this paper a total of
seven technologies concerning AI, Blockchain, Cloud, and Security with details on their technical definition, key
features, differentiating points, and use cases to give our readers some insights into our work.
R&D Cloud for AI
1. Introduction to Technology
Technology Trends and Background
Since the advent of the commercialization of PCs, demand for computing resources has been growing rapidly day by day.
Even the resources that are currently used for basic office work and personal documents are vast compared to the past.
Image and video files of course require far more computing resources than that.
So far, the CPU has been used as a major computing resource. With the rapid development in computation capacity, the
CPU is increasingly equipped with powerful specifications, thereby satisfying the needs of users. But now that the AI
era has arrived, the CPU alone can't afford the computing resources it needs. This is because we now need an
overwhelming level of high capacity and high quality work. While the CPU is responsible for processing complex
computation, the GPU is responsible for processing simple but large amounts of iterations in parallel. It is
completely different from the role of GPU which used to assist the CPU, only helping graphics processing before the AI
era.
 [Figure 1] CPU vs. GPU
[Figure 1] CPU vs. GPUWhen solving a problem with deep learning, the more layers there are, the more variables the computing resource will
take into account and iterative calculations to derive more accurate answers. The more layers there are, the more
accurate the result will be. However, as the number of layers increases, the required resources increase
exponentially. Without the parallel processing of GPU, deep learning is virtually impossible to research with only the
existing CPU.
 [Figure 2]
Parameters that grow exponentially as layers increase
[Figure 2]
Parameters that grow exponentially as layers increaseGPUs required for AI research and development are still expensive. It is a big burden for businesses or schools to
buy large amounts of GPUs for AI research. The GPU resources you purchase are not running around the clock with no
down time. The GPU remains idle, when there is no user or no action is directed.
R&D Cloud for AI is designed to make the most efficient use of GPU resources. It is a technology that clusters,
bundles, and integrates GPUs to utilize and manage. Consolidating GPUs increases overall available capacity. Applying
distribution technology to clustered resources allows users who need them to use them effectively as needed when they
need them. It also supports automatic environment setting to reduce the time spent in the AI development
environment.
Now, users don't have to buy GPUs as much as they need. With R&D Cloud for AI, you can take full advantage of the
GPU already in place. It allows you to reduce the time it takes to purchase equipment and set up the environment, and
to make AI research and development efficient.
Definition
The concept of R&D Cloud for AI is simple. It is a technology that increases the number of available resources by
bundling multiple GPUs, and reduces the idle time of assets that occur when operating separately. In order to provide
R&D Cloud for AI as a service, clustering, resource distribution, and user convenience and scalability enhancement
technology are required. It consolidates computing resources with GPU clustering, and supports users to conveniently
and efficiently utilize the resources they need when they want to use the service.
① GPU Clustering
GPU clustering integrates multiple GPU servers with Kubernetes-based technology. As the most fundamental technology of
R&D Cloud for AI, the key is not just to tie together multiple resources, but to enable stable resource
utilization in a state where multiple resources are integrated.
 Before clustering, it is just tie together multiple="multiple" resources. But after clustering, it
enables stable resource utilization in a state where multiple="multiple" resources are integrated. [Figure 3] before vs. after GPU clustering
Before clustering, it is just tie together multiple="multiple" resources. But after clustering, it
enables stable resource utilization in a state where multiple="multiple" resources are integrated. [Figure 3] before vs. after GPU clustering② Job scheduling
Let's say a user starts working with a clustered GPU. If there are few users, there is no problem with working with
the GPU. However, when there are many users, the clustered GPU cannot process jobs at once to meet the needs of all
users. Depending on the size of the job, the required resources, and the expected time, some jobs are processed
immediately, and other jobs need to wait.
Job scheduling is a technology that determines the order in which jobs are allocated and processed by determining the
current amount of available resources on the clustered GPU server and identifying the characteristics of incoming
jobs. R&D Cloud for AI transforms the basic scheduler provided by Kubernetes to suit the research environment, and
additionally develops and applies the required scheduler.
 [Figure 4] Effect of Job Scheduling Application
[Figure 4] Effect of Job Scheduling Application
③ Distributed Computing
As Deep Neural Network (DNN) technology advances, more and more computations are required to be processed.
State-of-the-art language processing models, etc., are complex enough to not be able to compute at the right time even
with expensive GPUs. DNN performs the task of finding parameters through complex operations. LeNet-5, released in
1998, finds 60,000 parameters, while GPT-3, released in 2020, finds 175 billion parameters. Distributed computing
technology is a technology that simultaneously utilizes multiple GPUs to process complex computations that cannot be
processed with a single GPU. In fact, using GPT-3 for research requires technology that can simultaneously use 1,000
or more GPUs on multiple machines.
R&D Cloud for AI can help researchers who need to perform complex computations quickly achieve results by
introducing distributed learning technologies available in various AI frameworks.
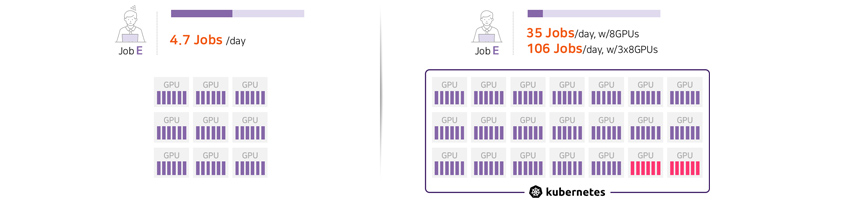 With
a single GPU you can only handle 4.7 jobs per day. But with the distributed computing technology, you can handle 35
jobs per day with 8 GPUs or 106 jobs per day with 3x8 GPUs. [Figure 5] Distributed
training using multimode GPS at the same time
With
a single GPU you can only handle 4.7 jobs per day. But with the distributed computing technology, you can handle 35
jobs per day with 8 GPUs or 106 jobs per day with 3x8 GPUs. [Figure 5] Distributed
training using multimode GPS at the same time
2. Key Features
R&D Cloud for AI provides various functions to make using clustered GPUs more convenient and effective for
users.
Personalized Machine Learning R&D Environment
If you need to carry out a project using a large amount of GPUs, such as in machine learning research, you should of
course purchase GPU equipment with the required specifications. However, even if you buy GPU equipment, the
environment and pattern are different for each user, so the number of users who can use the purchased equipment is
bound to be limited. Even if someone tries to develop new development using the GPU, it will be difficult to configure
and set up the necessary environment.
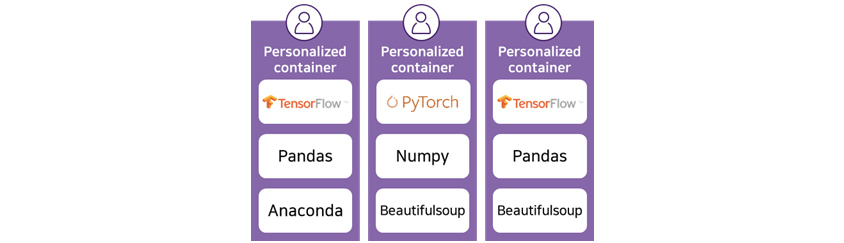 R&D Cloud for AI
provides personalized container, for example, one container with TensorFlow, Pandas, and Anaconda, another contains
with PyTorch, Numpy, Beautifulsoup, the other with TensorFlow, Pandas, Beautifulsoup.
[Figure 6] Examples of personalized containers provided by R&D Cloud for AI
R&D Cloud for AI
provides personalized container, for example, one container with TensorFlow, Pandas, and Anaconda, another contains
with PyTorch, Numpy, Beautifulsoup, the other with TensorFlow, Pandas, Beautifulsoup.
[Figure 6] Examples of personalized containers provided by R&D Cloud for AI
R&D Cloud for AI reduces the time required to set up the environment by providing the user's desired environment
as a virtualized container. It is also possible to reuse the environment set by other users by utilizing the
characteristics of the clustering environment, or to change and use the required configuration.
AI Optimized Job Scheduling
It would be nice if a clustered GPU could handle all users and jobs all the time, but the reality isn't. Most
companies and schools always run out of resources, and even if GPUs are clustered and provided, it is natural that the
total amount of clustered resources is less than the total amount of jobs. Scheduling technology is a technology that
distributes jobs that need to be queued according to the set policy, in what order and in which node to process.
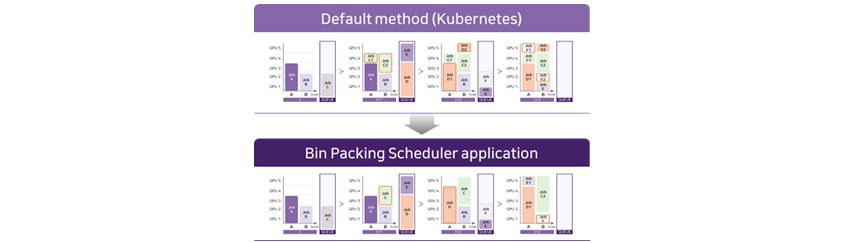 Bin packing scheduler application more efficient than the default method. It adjusts the order and
placement of jobs, reducing the time to complete the entire job execution.
[Figure 7] The scheduler provided by Kubernetes vs. the bin packing type scheduler applied to
R&D Cloud for AI
Bin packing scheduler application more efficient than the default method. It adjusts the order and
placement of jobs, reducing the time to complete the entire job execution.
[Figure 7] The scheduler provided by Kubernetes vs. the bin packing type scheduler applied to
R&D Cloud for AI
R&D Cloud for AI has 3 schedulers specialized for AI research. Each scheduler distributes the most efficient
processing according to fairness or job characteristics. R&D Cloud for AI is developing AI Optimized Scheduler
based on various schedulers developed so far. When Samsung SDS reaches the target scheduling technology level, R&D
Cloud for AI can maximize resource utilization efficiency by adjusting the order and placement of jobs, reducing the
time to complete the entire job execution.
Real-time Monitoring
The R&D Cloud for AI can secure and cluster additional GPUs as needed. The service provider must determine
whether the currently clustered GPU server is oversupplied, appropriate, or should be additionally equipped. R&D
Cloud for AI provides real-time monitoring to check usage and users by server and node. Service providers and
administrators can easily see how much assets are being used by using thsese monitoring tools, without the need to
read code when aggregating demand needs.
The monitoring function is also useful for users. You can determine when to use R&D Cloud for AI through
monitoring, and check which nodes are occupied by which projects in real time. In addition, it shows the core
utilization rate of the allocated GPU, so that you can check and improve whether the training task is efficient or if
there is any performance degradation due to I/O, etc.
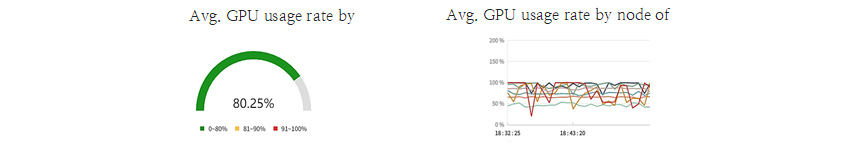 [Figure 8] Part of the real-time monitoring screen of R&D Cloud for AI
[Figure 8] Part of the real-time monitoring screen of R&D Cloud for AI
3. Differentiating Points
Samsung SDS's R&D Cloud for AI is meaningful in that it does not utilize the existing Kubernetes-based
technologies and various technologies as they are, but has built an optimized environment for AI R&D environment.
It provides separate pages for schedulers and monitoring tools to enhance operations. In addition, the AI framework,
which AI researchers need the most, is applied, and 10 types of environment assets are provided so that machine
learning environments can be easily set up, which is the differentiating point of R&D Cloud for AI.
4. Use Case
Support for Samsung SDS R&D AI R&D Environment
Prior to the establishment of R&D Cloud for AI, Samsung SDS R&D Center had difficulties in purchasing and
managing GPUs. This is because we predicted and purchased the GPU specifications and quantity required for each
project, but whenever the project ended or the scope changed, who should manage the GPU became unclear. In addition,
we even encountered heat and noise problems as researchers worked with the GPU server in their seats.
Since the establishment of the R&D Cloud for AI, we have been able to physically integrate these assets into data
centers to store and manage them. The R&D Cloud for AI enables us to start developing right away without having to
go through the asset purchase process when launching a project. Since the R&D Cloud for AI is in charge of
purchasing and managing assets, researchers can focus on the AI research itself, and thereby reducing the time spent
on environment preparation.
After completing the first development in 2020, Samsung SDS R&D Center applied its own pilot service to provide
considerably satisfactory convenience to AI R&D and improved functions and performance through the Voice of
Customer (VoC) received. In 2021, we will increase the number of equipment to accelerate research and development, and
at the same time, we will work on the Computing, Network, and Storage available based on Kubernetes.
5. Closing
R&D Cloud for AI provides a realistic alternative to building a GPU-based research environment where demand is
constantly increasing. The various functions provided for AI R&D allow you to make the most of the resources you
have when you need to purchase servers, by gradually increasing servers without purchasing huge amounts of resources
at once. However, the current R&D Cloud for AI needs to be further improved. In particular, networks are an area
of research that requires performance improvement.
The R&D Cloud for AI has great significance in that it has achieved technological results by improving simple and
clear points. Starting from the simple concept of ‘integrated use', we continue to expand our technology to find
more realistic and effective solutions.

▶ The content is proected by law and the copyright belongs to the
author.
▶ The content is prohibited to copy or quote without the author's permission.
- The First Step to Smart Textual Analysis, KoreALBERT
- Smart QA Model That Understands Even Complex Tables
- I Will Give You Data, Label It~ Auto Labeling!
- The Connecting Link for Everything in the World, It’s in the Knowledge Graph
- Easy and Simple Blockchain Management, Nexledger!
- No More Short of GPU!
- In the Age of When Customer Data Must Be Treated as a King, PET Will Take on the Responsibility
- It is Important to Prevent Security Risks from Development Phase! Trust CAFA+ to Do the Job

Cloud Research Team at Samsung SDS R&D Center
Inseok Seo is in charge of planning of Samsung SDS Cloud Research Team. He is also an SDS reporter. He explains cloud technologies including R&D Cloud for AI in simple terms.
If you have any inquiries, comments, or ideas for improvement concerning technologies introduced in Technology Toolkit 2021, please contact us at techtoolkit@samsung.com.
- Innovations in Contents Management to Keep Customers Stay Longer and Visit More Frequently
- Smart Office to Support Business Innovation
- Samsung SDS Earns Recognition as 2023 Asia-Pacific Climate Leaders
- The Chronicles of Cloud Computing
- Finding the Best Cloud Adoption Strategy
- Cloud-First Strategy to Accelerate Digital Transformation