
“NoSQL”이란 용어를 들어보신 적이 있는지요? 관계형 DBMS에서 데이터를 조회, 수정, 삭제하거나, DBMS를 조작하는데 사용되는 언어인 SQL(Structured Query Language)은 많이 들어보셨을 텐데, “No”+ “SQL”이라니?
아마 IT 산업에 현재 일하고 계시거나, 관련 전공을 하고 계시는 학생, 또는 해당 용어가 나오는 신문 기사들을 보시고 직접 찾아 보신 분들을 제외하고는 무엇을 의미하는지 이해하기가 어려우실 듯합니다.
하지만 여러분들이 평소에 Facebook, Twitter, Netflix, Instagram, Apple의 iCloud, 삼성의 SCloud 등의 서비스를 사용한다면 이미 NoSQL DB기술을 활용하고 있는 겁니다.
이 사이트들에 여러분들이 올린 사진이나, 메시지들을 저장할 때, 많은 분들이 동시에 웹 쇼핑몰에 접속했을 때, 선호하시는 상품을 실시간으로 추천해 줄 때, 거의 예외 없이 사용되는 기술이 바로 NoSQL DB기술입니다.
이번 기고에서는 여러분들이 인지하고 계시지 못하지만, 다양한 환경에서 이미 활용되는 DBMS의 종류중 하나인 NoSQL에 대해서, 특히 고성능 처리성능으로 떠오르는 ScyllaDB 솔루션에 대해 자세하게 알아보도록 하겠습니다.
NoSQL은 무엇이고, 언제 왜 만들어 졌나요?
NoSQL이 무엇의 약자인지는 사람에 따라 No SQL, Not Only SQL, Non-Relational Operational Database SQL로 엇갈리는 의견들이 있습니다만, 현재 Not Only SQL로 풀어 설명하는 것이 다수를 차지하고 있습니다.
이 말의 의미를 풀어보면, 단순히 기존 관계형 DBMS가 갖고 있는 특성뿐만 아니라, 다른 특성들을 부가적으로 지원한다는 것을 의미합니다.
이 용어가 처음으로 등장한 것은 1998년 카를로 스트로찌(Carlo Strozzi)라는 엔지니어가 공개한 표준 SQL 인터페이스를 채용하지 않은 자신의 경량 Open Source 관계형 데이터베이스를 NoSQL이라고 명명한데서 유래했다고 합니다.
이후 2009년에는 요한 오스칼손(Johan Oskarsson)이라는 엔지니어가 Open Source기반의 분산 데이터베이스 관련 행사를 준비하면서 NoSQL이라는 용어를 사용했다고 합니다.
이때부터 기존의 관계형 데이터베이스 시스템의 주요 특성을 보장하는 ACID(Atomic, Consistency, Integrity, Duarabity) 특성을 제공하지 않는, 그렇지만 뛰어난 확장성이나 성능 등의 특성을 갖는 수많은 비관계형, 분산 데이터 베이스들이 등장했고 NoSQL이라는 용어가 보편적으로 사용되었습니다.
NoSQL이 등장한 이후에도 시장에서는 관계형 데이터베이스가 데이터를 처리하는데 가장 최적의 시스템으로 받아들이고 있었습니다.
특히 기업의 ERP나, MIS 시스템 등 데이터의 정확한 처리가 필수적인 시스템에서는 현재도 관계형 데이터베이스를 사용하고 있습니다. 또한 무엇보다도 SQL 이라고 하는 데이터를 처리하는 언어의 편이성 때문에 NoSQL 등 다른 데이터베이스 시스템들은 많이 활용 되지 않고 있었습니다.
그러나, 2000년 후반으로 넘어오면서 인터넷이 활성화되고, 소셜네트워크 서비스 등이 등장하면서 관계형 데이터 또는 정형데이터가 아닌 데이터, 즉 비정형데이터라는 것을 보다 쉽게 담아서 저장하고 처리할 수 있는 구조를 가진 데이터 베이스들이 관심을 받게 되었고, 해당 기술이 점점 더 발전하게 되면서, NoSQL 데이터베이스가 각광을 받게 된 것입니다.
이러한 배경하에서 어떤 엔지니어들은 NoSQL을 Modern web-scale databases라고 정의하기도 합니다.
NoSQL 데이터베이스의 특징을 살펴보면, 기존의 관계형 데이터베이스 보다 더 융통성 있는 데이터 모델을 사용하고, 데이터의 저장 및 검색을 위한 특화된 매커니즘을 제공합니다.
이를 통해 NoSQL 데이터베이스는 단순 검색 및 추가 작업에 있어서 매우 최적화된 키 값 저장 기법을 사용하여, 응답속도나, 처리 효율 등에 있어서 매우 뛰어난 성능을 나타냅니다. 이 특징들을 요약해보면 기존 관계형 데이터베이스와 다음과 같은 차이점을 보입니다.
- 관계형 모델을 사용하지 않으며 테이블간의 조인 기능 없음
- 직접 프로그래밍을 하는 등의 비SQL 인터페이스를 통한 데이터 액세스
- 대부분 여러 대의 데이터베이스 서버를 묶어서(클러스터링) 하나의 데이터베이스를 구성
- 관계형 데이터베이스에서는 지원하는 Data처리 완결성(Transaction ACID 지원) 미보장
- 데이터의 스키마와 속성들을 다양하게 수용 및 동적 정의 (Schema-less)
- 데이터베이스의 중단 없는 서비스와 자동 복구 기능지원
- 다수가 Open Source로 제공
- 확장성, 가용성, 높은 성능
설명드린 용어들이 다소 어렵습니다만, 정리해보면, NoSQL은 초고용량 데이터 처리 등 성능에 특화된 목적을 위해, 비관계형 데이터 저장소에, 비구조적인 데이터를 저장하기 위한 분산 저장 시스템이라고 볼 수 있습니다.
NoSQL에는 어떤 것들이 있나요?
앞 세션에서 NoSQL의 개념에 대해서 상세하게 알아보았는데, 저장되는 데이터의 구조에(Data Model) 따라 아래와 같이 나누어 볼 수 있습니다.
- Key Value DB
Key와 Value의 쌍으로 데이터가 저장되는 가장 단순한 형태의 솔루션으로 Amazon의 Dynamo Paper에서 유래되었습니다. Riak, Vodemort, Tokyo 등의 제품이 많이 알려져 있습니다.
- Wide Columnar Store
Big Table DB라고도 하며, Google의 BigTable Paper에서 유래되었습니다. Key Value 에서 발전된 형태의 Column Family 데이터 모델을 사용하고 있고, HBase, Cassandra, ScyllaDB 등이 이에 해당합니다.
- Document DB
Lotus Notes에서 유래되었으며, JSON, XML과 같은 Collection 데이터 모델 구조를 채택하고 있습니다. MongoDB, CoughDB가 이 종류에 해당합니다.
- Graph DB
Euler & Graph Theory에서 유래한 DB입니다. Nodes, Relationship, Key-Value 데이터 모델을 채용하고 있습니다. Neo4J, OreientDB 등의 제품이 있습니다.
Wikipedia에서 관련 자료를 찾아보면, 아래 표와 같이 좀 더 다양한 NoSQL 제품들을 볼 수 있습니다. 이들의 특성을 보면 많은 제품들이 자신들만의 비즈니스 요구사항에 의해 만들어져서 적용되었고, 이후 오픈소스로 공개되어 활성화된 경우가 대부분입니다.
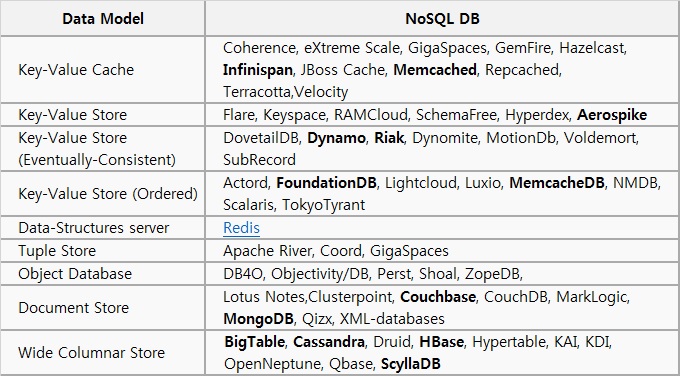 | NoSQL의 종류, Source: wikipedia
| NoSQL의 종류, Source: wikipedia
각 데이터 모델의 종류에 따라 다양한 시스템 특성의 차이가 있습니다.
아래의 표에서는 이러한 비기능적 품질을 나타내고 있습니다.
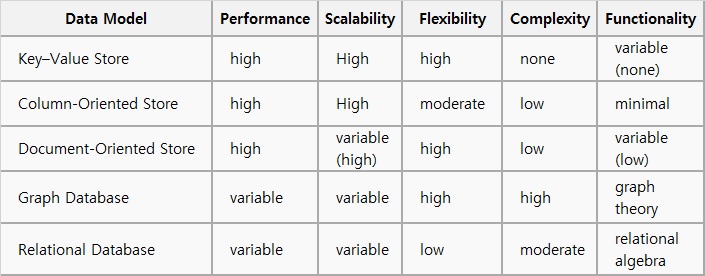 | NoSQL DB별 특성, Source: wikipedia
| NoSQL DB별 특성, Source: wikipedia
가장 많이 사용되는 NoSQL은? 그리고 특성은?
NoSQL 제품을 구글링 해보면 위 테이블에 나와 있는 제품뿐만 아니라 수 백여개의 제품들을 찾아볼 수 있습니다.(2017년 4월 현재 http://nosql-database.org/에 소개된 솔루션은 225개) 이렇게 많은 제품들 중에 실제 시스템에 가장 적합한 제품을 어떻게 선정할 수 있을까요?
필자는 비즈니스에서 요구되는 적합성을 고려하여 선정하는 것과 더불어 시스템을 개발하고 운영하게 될 조직, 개발 커뮤니티의 성숙도도 고려해 봐야 한다고 생각합니다.
더불어 실제 해당 솔루션이 각각의 비즈니스 케이스에 적합한지 PoC가 반드시 필요하다고 생각합니다. 특히 Open Source가 대부분인 NoSQL에 있어서는 필수사항이라고 하겠습니다.
Key-Value 제품을 포함하여 전체 NoSQL제품들 중 현재 시장에서 가장 많이 인기가 있는 제품들은 MongoDB(Document), HBase(Wide Columnar Store), Cassandra(Wide Columnar Store)를 들 수 있습니다.
HBase는 하둡 분산 파일 시스템(HDFS)에서 동작하는 Key-Value 구조 분산 데이터 베이스로, Google의 Bigtable을 참고해서 JAVA로 개발 되었습니다.
Cassandra는 Amazon의 Dynamo의 특징인 Hash 알고리즘을 이용한 “masterless” 아키텍처로 모든 노드가 coordinator 노드와 replica 노드가 될 수 있습니다.
현재 가장 인기가 많은 NoSQL인 MongoDB는 10gen(현,MongoDB inc)이 개발한 document-oriented database로 JSON의 2진 버전인 BSON을 사용하여, C++로 개발되었습니다.
각 제품별 일반적인 특성은 다음과 같습니다.
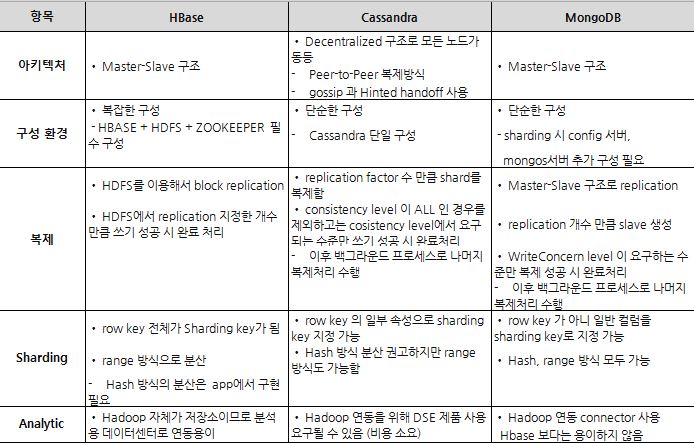 | 주요 NoSQL제품의 일반 특성
| 주요 NoSQL제품의 일반 특성
이러한 일반적인 특성과 함께 시스템적인 견고성도 데이터베이스에서 필수적인 중요한 항목입니다.
각 제품의 아키텍처와 기능에 따라 제공되는 견고성이 차이가 있으므로 업무요건을 고려하여 제품을 선정해야 합니다.
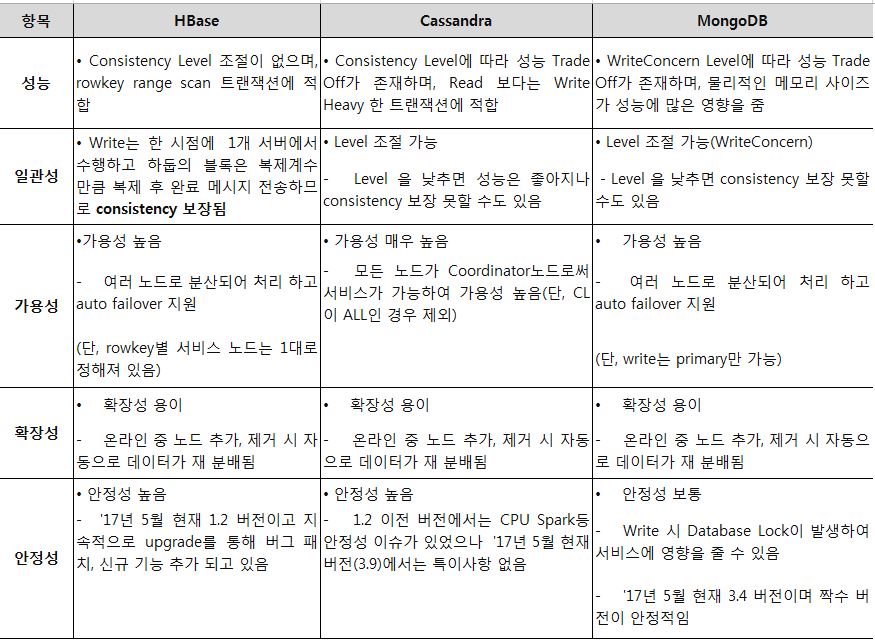 | 주요 NoSQL제품의 시스템 견고성 특성
| 주요 NoSQL제품의 시스템 견고성 특성
ScyllaDB는 어떤 솔루션인가요?
위에서 소개한 글로벌 리서치 회사들의 조사 자료에는 신생 솔루션이라 아직 리스트 업되지 않았지만,획기적인 아키텍처 채택으로 고성능과 안정성을 확보한 ScyllaDB에 대해 살펴보도록 하겠습니다.
ScyllaDB는 이스라엘 Startup에서 ‘16년 4월 GA(General Available)버전이 출시된 Cassandra와 100% 호환성이 있는 고성능 NoSQL솔루션입니다. 이 회사의 창립 멤버들의 백그라운드가 상당히 흥미롭습니다.
클라우드의 가상화 솔루션으로 가장 많이 사용되는 오픈소스 하이퍼바이저인 KVM을 만들고 리딩했던 핵심 엔지니어들이 창업한 회사가 Cloudius System라는 회사입니다.
(Avi Kivity, Dor Laor, Benny Schnaider, http://www.scylladb.com/company/)
최초에는 본인들이 가진 클라우드 관련 기술 역량들을 활용하여, 가상화 환경에서의 어플리케이션들의 성능을 최대화할 수 있는 가상화 OS인 OSv라는 솔루션을 만들었습니다.
이 솔루션의 경우 시장에서 크게 각광받지만 못했지만 이때 만든 서버 어플리케이션 플랫폼을(Seastar) 활용하여 다른 솔루션을 만들기 시작했습니다. 이에 기반하여 Web Server를 만들었는데, Apache Tomcat보다 10배 이상 고성능의 성능을 가졌다고 합니다.
이후 2015년 초부터 다른 고성능 솔루션 개발로 방향을 돌렸는데, 바로 Cassandra 호환 NoSQL인 ScyllaDB입니다. Cassandra는 단순하며 견고한 아키텍처로 Colum Family NoSQL 중에서 가장 시장에서 많이 사용되는 솔루션입니다. Apple의 iCloud가 1200여대의 Cassandra로 운영되고 있고, Netflix도 1000여대의 Cassandra를 하나의 DB로 구성하여 대량의 데이터를 처리하고 있습니다.
ScyllaDB 이름의 유래도 상당히 재미있는데, Scylla + DB의 합성어입니다.
네이버 지식백과에서 Scylla를 찾아보면 아래와 같습니다.
스킬라 [Scylla] - 괴물 (그리스로마신화 인물백과)
그리스 신화에 나오는 바다 괴물이다. 상체는 처녀이지만 하체는 여섯 마리의 사나운 개가 3중의 이빨을 드러내고 굶주림에 짖어대는 모습이다. 원래는 아름다운 님프였는데, 해신 글라우코스를 사이에 두고 마녀 키르케의 미움을 사 그녀의 마법에 의해 흉측한 바다 괴물이 되었다.
Scylla라는 용어를 채택한 배경은 Scylla라는 괴물이 갖고 있는 모습에서 NoSQL의 특성인 많은 동시 데이터를 처리 가능하다는 데서 기인하여 명명한 것으로 생각됩니다.
Cassandra와 무엇이 다른가?
이제 ScyllaDB와 Cassandra의 차이점을 알아보도록 하겠습니다.
Application에서 활용되는 기능들은 100% 호환성을 가져가면서도, 내부에서 데이터 처리 아키텍처를 혁신적인 구조를 채택하여 안정성과 고성능을 구현했습니다.
먼저 Cassandra는 JVM(Java Virtual Machine) 기반 DB Engine입니다.
Java로 개발되어 JVM위에 실행되기 때문에 다른 운영체제로의 우수한 이식성을 갖지만, 이것은 또한 JVM 기반 어플리케이션이 공통적으로 갖고 있는 메모리 관리나, Garbage Collection과 같은 필수 작업으로 인해 성능제약이 필연적입니다.
또한 Job Scheduling, Memory 관리, Networking 작업이 모두 운영체제 Kernel에 의존하는 구조로 갈 수밖에 없는데, 이는 운영체제에서의 병목 현상과 HW자원을 공유하여 멀티 프로세싱으로 인한 Context Switch시 고비용이 발생하는 치명적인 단점이 있습니다.
이에 반해 ScyllaDB는 Server단의 고성능 Application Framework인 Seastar 기반으로 되어 있습니다.
C++로 개발되어 있고, Event 기반 Processing 구조로 고성능 처리가 가능하고, 특히 JVM의 메모리 관리 등 구조적 제약을 극복하였습니다.
또한 CPU Core별 Data Sharding, 단일 thread기반 processing으로 Cassandra가 갖고 있었던 lock관리나Context Processing이 원천적으로 불필요하여 효율화가 가능합니다.
마지막으로 Network Packet 처리시에도 운영체제에 의존하는 것이 아니라, Intel DPDK(Data Plane Development Kit) 기반 Application에 최적화된 고성능 Packet processing으로 처리가 가능해 졌습니다.
종합해 보면, ScyllaDB는 Cassandra와 호환되며, core별 sharding 및 multiprocessing, C++기반 구조로 고성능을 확보한 솔루션입니다.
실제 비즈니스 업무에서의 ScyllaDB 성능은?
필자의 Job은 Data Architect이기 때문에 DB영역의 이머징 기술에 관심을 갖고 ScyllaDB에서 0.1 버전이 나올 때부터 주시하고 있었습니다.
마침 ‘16년 초 사내에서 운영중인 솔루션의 Cassandra에서 성능 및 운영 안정성 이슈가 빈번하여 이를 대체하기 위한 ScyllaDB PoC를 진행할 기회가 있었습니다.
아래 그림은 ‘16년 5월 Cassandra와 ScyllaDB의 Scale-out 성능을 비교한 자료입니다.
Cassandra 대비 최대 8배의 고성능을 나타내고 있으며, Node수를 증가함에 따라 선형적인 성능 증가를 보여주고 있습니다.
Latency의 경우도 ScyllaDB가 매우 우수한 것을 알 수 있습니다.
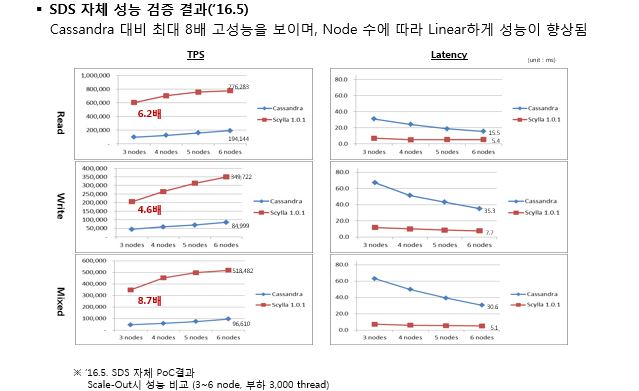 | '16년 5월 삼성SDS 자체 Scale-Out 성능 비교 (16 Core 64GB memory, 3~6 node, 부하 3,000 thread)
| '16년 5월 삼성SDS 자체 Scale-Out 성능 비교 (16 Core 64GB memory, 3~6 node, 부하 3,000 thread)
상기 Scale-out 성능 검증 외에, 기능성, 가용성, 확장성, 안정성 측면에서도 Cassandra와 동등한 우수한 특성을 나타내었습니다.
다음 그림은 삼성전자 미주연구소의 Memory Solution Lab에서 ScyllaDB와 Cassandra를 Benchmarking한 결과를 보여주고 있습니다.
이들의 테스트에서는 ScyllaDB가 Cassandra 대비 최대 37배 고성능을 보이며, 더 많은 대량의 Data 처리가 가능하다고 검증하였습니다.
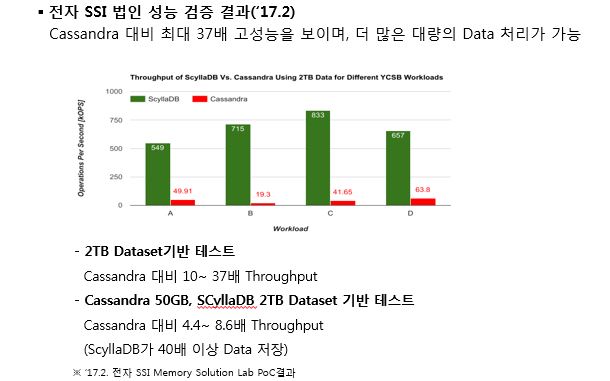 | '17.2월 삼성전자 NoSQL 성능 비교
| '17.2월 삼성전자 NoSQL 성능 비교
좀 더 구체적으로 보면 두 솔루션의 2TB Dataset기반 테스트에서는 ScyllaDB가 Cassandra 대비 10~ 37배 Throughput을 나타내었다고 합니다.
Cassandra 50GB, ScyllaDB 2TB Dataset 기반 테스트에서는 ScyllaDB가 Cassandra 대비 4.4~ 8.6배 Throughput이 측정되었으며, ScyllaDB가 40배 이상 Data를 더 처리할 수 있었다고 합니다.
ScyllaDB를 비롯한 NoSQL은 어떤 방향으로 진화되어 가고 있나요?
‘15년 기준으로 Top 5 DBMS Vendor가(Oracle, Microsoft, IBM, SAP, Teradata) 전체 데이터베이스 시장의 92.6% 매출을 올리고 있다고 합니다.
이들 대부분이 관계형 데이터베이스에서 출발한 Vendor들인데, 최근 들어 NoSQL에서만 지원하던 JSON, Key-Value, Graph와 같은 데이터 모델을 지원하는 제품들을 내놓거나, 기존 제품을 업그레이드하고 있습니다. 즉, Big Data를 처리할 수 있는 새로운 비즈니스 요구사항에 대해 적극적으로 대응하고 있는 것입니다.
오픈소스 DBMS인 PostgreSQL의 경우도 2년전부터 NoSQL에서나 처리 가능했던 JSON을 지원함으로서, 시장의 주목을 많이 받았고, 더불어 다른 오픈소스 데이터베이스 업체들도 JSON을 지원하게 되었습니다.
Application 시장에 있어서도 NoSQL 기술을 활용한 다양한 시도들이 가속되고 있고, 이 개발 속도는 개발자들이 선호하는 특히 Document Style NoSQL기술의 Flexible한 schema처리에 기인하고 있습니다.
하지만 Data Governance 측면에서는 Flexible한 데이터 모델관리는 데이터 품질과 관리의 적합성에 있어서 많은 Concern을 만들어 내고 있기도 합니다.
글로벌 리서치 기관에 의하면 응답한 조직의 52%가 개발자들이 NoSQL기반의 데이터베이스에 새로운 응용프로그램들을 구축하는 것을 막을 수가 없다고 응답한 한편, 42%는 자사의 인프라에 구축된 NoSQL 데이터베이스들을 관리하는 데 많은 어려움을 겪고 있다고 응답했다고 합니다.
또한 NoSQL 솔루션들에 저장된 데이터는 자사의 비즈니스에 데이터 사일로들을 발생시켰다는 응답은 30%에 달했습니다. Data Governance 측면에서 NoSQL에 대해서도 이러한 부작용을 피할 수 있도록, 데이터 모델링과 제품의 선정, 데이터의 관리에 있어서 일관된 정책과 전략수립이 선행되어야 할 것으로 보입니다.
최근의 시장동향을 보면, IoT 데이터의 처리와 활용과 같은 새로운 비즈니스 케이스가 지속적으로 발굴됨에 따라 NoSQL 기술은 점점 더 매력을 가져가게 될 것입니다.
특히 기존 기술과 비용, 성능, 관리용이성 측면에서 우위에 있습니다.
글로벌 유명 리서치펌 따르면, 최근 시장에서 Document-style DBMS, 특히 MongoDB.에 대한 시장의 투자가 확대되고 있습니다.
또한 DataStax, Hadoop 관련된 NoSQL Vendor들도 크게 성장하고 있습니다. 최근 ‘14년에 진행된 NoSQL업체에 대한 투자를 살펴보면, Couchbase(60만불), Datastax(45만불), Aerospike(20만불)에서 보듯이 활성화 되고 있습니다.
이중 Aerospike의 경우 In-Memory NoSQL로 성능을 극대화 하는 제품으로 차별화 하고 있습니다.
또한 Cassandra도 최근 In-Memory기능을 추가하는 등 다양한 혁신적인 시도들이 NoSQL 제품에 채용되고 있는 추세입니다.
본문에서 상세하게 소개해드린 ScyllaDB의 경우도 C++기반의 혁신적인 아키텍처 채용으로 고성능을 확보한 사례가 되겠습니다.
당사에서는 본문에서 소개한 ScyllaDB기술에 대해 ScyllaDB 본사와의 전략적 협업 기반 하에 기술지원체계와 전문인력을 확보하였고, 이를 기반으로 ScyllaDB 도입/전환 관련 컨설팅 서비스와 기술지원 서비스를 제공하고 있습니다. 관심 있는 분들께서는 연락 주시기 바랍니다.
향후 AWS 등의 Public Cloud 기반으로 Managed Service와 DBaaS 서비스를 준비하고 있고, AWS의 DynamoDB와 같이 사용자가 직접 DB서비스를 활용할 수 있는 서비스를 제공할 예정입니다.
참고자료
http://en.wikipedia.org/wiki/NoSQL, 위키피디아
http://www.gartner.com/home, 가트너
http://www.forrester.com/home, 포레스터
http://www.scylladb.com, ScyllaDB
DB 서비스 기술 Lab 내부 자료
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

삼성SDS 클라우드사업부
ICT Industry에서 Architect, IT Consultant, Project Manage로 20여년의 경력을 가진 엔지니어입니다. 현재 Emerging DB기술의 센싱과 검증, Cloud 환경에서의 DB서비스 기술을 연구하고 있습니다.