![[IT에 한 걸음 더 다가가기] 연산처리의 성능 한계에 도전하는 병렬컴퓨팅 (5편) 썸네일 이미지](https://image.samsungsds.com/kr/insights/__icsFiles/afieldfile/2018/07/12/826_thumb.jpg?queryString=20260529094615)
![[IT에 한 걸음 더 다가가기] 연산처리의 성능 한계에 도전하는 병렬컴퓨팅 (5편)](https://image.samsungsds.com/kr/story/826_1.jpg?queryString=20260529094615)
지난 4편에서는 병렬컴퓨터를 살펴보았습니다. [관련기사 바로 가기: 병렬컴퓨터] 과거에는 슈퍼컴퓨터에만 적용되어 왔던 병렬컴퓨터 아키텍처가 현재는 일반 PC에도 범용적으로 채택되고 있으며, 컴퓨터의 성능 향상에 많은 기여를 하고 있습니다.그러나 과거에는 하드웨어의 성능에 따라 소프트웨어의 성능도 자연히 향상되었지만, 현재 멀티코어 시대에서는 프로세서 간의 협력을 최상으로 끌어내기 위해 소프트웨어 설계를 어떻게 하느냐가 무엇보다 중요하게 되었습니다. 병렬프로그래밍은 병렬컴퓨터 아키텍처를 효과적으로 활용하는 방법으로 성능 향상을 위한 필수적인 요소라고 볼 수 있습니다. 이번 편에서는 이러한 병렬프로그래밍을 어떻게 구현하는지 자세히 살펴보도록 하겠습니다.
병렬프로그래밍은 순차적인 직렬프로그램을 분할하고 분할된 단위를 동시에 병렬로 수행함으로써 성능을 향상시키는 프로그래밍 기술이며, 이러한 전반적인 과정을 병렬화라고 합니다.
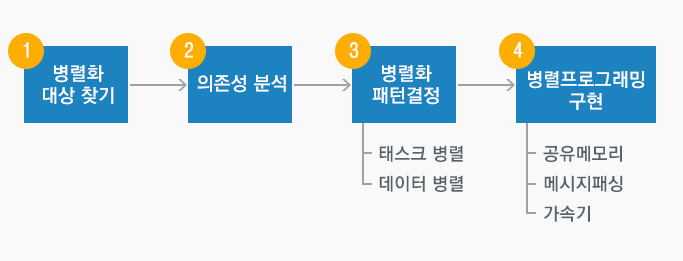 ▲ 병렬화 과정
▲ 병렬화 과정병렬프로그래밍을 구현하기 위해서는 가장 먼저 성능의 병목지점인 병렬화 대상을 찾아야 합니다. 또한 실제 병렬화가 가능한지에 대한 의존성 분석과 병렬화를 어떤 방식으로 진행할 건지에 대한 패턴 결정이 필요합니다. 아래 그림은 병렬화의 전반적인 단계를 나타내고 있습니다.
병렬화를 수행할 때 가장 먼저 해야 할 일은 바로 병렬화 대상을 찾는 것입니다. 즉, 순차적인 코드에서 가장 많은 시간이 소요되는 병목구간을 찾는 것이죠. 이러한 작업은 프로그래머가 직접 코드를 뒤져가며 찾아볼 수도 있지만, 일반적으로 프로파일링 도구의 힘을 빌리기도 합니다. 인텔 사의 VTune, AMD 사의 CodeAnlyst, 오픈소스인 oprofile 등의 프로파일러는 이러한 작업을 도와줍니다.
우리는 병렬화 대상을 찾아내어, 실제 병렬화를 했을 때 성능이 어느 정도까지 향상될 수 있을지 암달의 법칙 계산식을 통하여 예측해 볼 수도 있습니다.
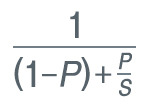
P : 병렬화 비율, S : 성능 향상 배수 (코어나 프로세서의 개수)
예를 들어, 전체 작업 중 40%를 병렬화할 수 있고 프로세서 또는 코어가 2개인 경우 최대 성능 향상은
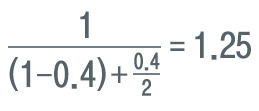 가 됩니다.
가 됩니다.
이처럼 병렬화 대상을 최대한 많이 찾아낼수록 성능은 더욱 향상될 수 있습니다.
![]()
병렬화 대상을 찾았다면, 실제 병렬화가 가능한지 확인해야 합니다. 즉, 병렬화하기 위해 프로그램을 분할해야 하는데 분할된 코드들이 서로 간에 의존성 없이 동시에 수행 가능한지의 여부를 찾아보는 것입니다. 그럼 일반적으로 사용되는 데이터 의존성 분석을 알아보겠습니다.
RAW (Read-After-Write)라고도 불리는 Flow dependency는 이전 명령의 연산 결과를 후속 명령에서 읽으려고 시도할 때 발생하는 의존성 문제입니다.
예)
a = b + c; // 명령1
d = a + e; // 명령2
위의 예와 같이 명령2는 명령1의 연산이 완료되어 a값이 결정되어야만 수행이 가능하므로 두 명령은 병렬화 수행이 불가능합니다.
WAR (Write-After-Read)라고도 불리는 Anti-dependency는 후속 명령이 이전 명령에서 값을 읽기 전에, 값을 쓰려고 할 때 발생하는 의존성 문제입니다.
예)
a = b + c; // 명령1
b = d + e; // 명령2
위의 예와 같이 명령1에서 b값을 먼저 읽은 후, 명령2에서 b값을 써야 하므로 두 명령은 병렬화 수행이 불가능합니다.
WAW (Write-After-Write)라고도 불리는 Output dependency는 이전 명령에서 값을 쓰기 전에, 후속 명령이 값을 쓰려고 할 때 발생하는 의존성 문제입니다.
예)
a = b + c; // 명령1
a = d + e; // 명령2
위의 예와 같이 명령1에서 a값을 먼저 쓰고 나서, 명령2에서 a값을 써야 하므로 두 명령은 병렬화 수행이 불가능합니다.
병렬화가 가능한지 분석을 마쳤다면, 이제 병렬화 대상의 속성에 따라 어떠한 방식으로 병렬화를 진행할지 패턴을 결정해야 합니다. 병렬화 패턴은 크게 데이터 병렬화와 태스크 병렬화로 구분될 수 있습니다.
데이터 병렬화란 어떠한 데이터 집합을 분해한 뒤, 각 프로세서에 할당하여 동일한 연산을 동시에 수행하는 기술로써 흔히 벡터화라고도 부릅니다.
 ▲ 데이터 병렬화
▲ 데이터 병렬화예를 들어, A[n]+B[n] = C[n]이라는 연산을 처리할 때, 순차처리 방식에서는 For문 내의 각 데이터 연산이 순서대로 수행되기 때문에 시간이 많이 소요됩니다. 하지만 연산을 처리하는 Core가 n개이고 각 연산이 서로 의존성이 없는 경우, 동시에 병렬처리가 가능하게 됩니다. 이러한 방식을 바로 데이터 병렬화라고 하며, 인텔의 SSE나 AVX 등의 SIMD 아키텍처 및 GPGPU 기술은 이러한 데이터 병렬화에 최적화된 기술이라고 볼 수 있습니다. 물론 데이터 병렬화는 멀티코어의 멀티스레드 방식이나 메시지 패싱 등을 통해서도 가능하지만 SIMD나 GPGPU를 통해 더 큰 효과를 거둘 수 있습니다.
태스크 병렬화는 수행해야 할 작업들을 기능 별로 분해한 뒤, 각 프로세서에 할당하여 서로 다른 기능들을 동시에 수행하는 기술입니다.
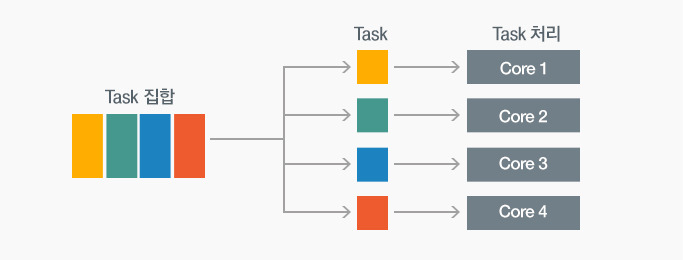 ▲ 태스크 병렬화
▲ 태스크 병렬화예를 들어, Task1에는 I/O 작업, Task2에는 연산 작업 등을 맡겨 서로 다른 기능들이 동시에 수행할 수 있게끔 하는 기술이 바로 태스크 병렬화라고 합니다. 보통 기능적 단위로 수행되기 때문에 범용 CPU를 활용한 병렬컴퓨터 구조에서 주로 구현이 가능하며, 멀티스레드 방식에서는 하나의 스레드가 하나의 Task를 맡아 수행하는 구조로 동작됩니다.
병렬 프로그래밍은 공유 메모리 프로그래밍 모델, 메시지 패싱 프로그래밍 모델, 가속기 프로그래밍 모델 이렇게 크게 3가지로 나뉩니다.
공유 메모리 병렬프로그래밍 모델은 SMP나 CMP 등의 공유 메모리 시스템 구조에 적합한 방식으로써 다수의 코어(멀티코어인 경우)의 협력을 통해 병렬화를 수행하는 모델입니다. 이 모델에서는 여러 개의 스레드를 생성한 후 다수의 코어로 분배하여 병렬처리를 수행하게 되는데, 스레드의 생성 및 처리를 위해 일반적으로 UNIX계열 POSIX 표준의 pthread라는 API를 활용합니다. 물론 Windows 계열에서도 pthread를 지원하고 있습니다.
하지만 이러한 pthread는 스레드 생성에서부터 병렬화, 동기화 등 신경 써야 할 부분이 너무 많습니다. 그래서 나오게 된 도구가 OpenMP입니다. OpenMP는 C/C++/Fortran 기반의 병렬 프로그래밍 API로써 병렬처리를 위한 다양한 기능들을 추상화하여 손쉽게 프로그래밍 할 수 있는 환경을 제공합니다. 이 외에 인텔의 TBB(Thread Building Block)나Cilk++ 등도 C++ 기반에서의 병렬프로그래밍 도구로써 많이 사용되고 있습니다. 또한 .NET Framework 버전 4.0 이상부터는 TPL(Task Parallel Library)라는 병렬 라이브러리를 제공하여 C#에서도 손쉽게 병렬 프로그래밍을 구현할 수 있게 되었습니다.
MPI (Message Passing Interface)는 분산 메모리 시스템 구조에 적합한 병렬 프로그래밍 모델입니다. MPI는 메모리 공유 방식이 아니기 때문에 노드 간에 서로 네트워크를 통해 메시지를 주고받는 형태로 정보를 공유하게 됩니다. 따라서 네트워크 상의 통신 속도가 성능의 매우 중요한 요소로 작용하며, 고속의 연산처리를 필요로 하는 슈퍼컴퓨터에 많이 사용됩니다.
반면, 하둡 클러스터에 사용되는 맵리듀스는 빅데이터 처리에 적합하게 설계된 모델로써, HDFS라는 분산 파일 시스템을 사용하여 대규모의 데이터를 저장하고 이를 처리하는 메커니즘을 가지고 있습니다. 또한 특정 노드에 장애가 발생되더라도 다른 노드를 통하여 중단 없이 작업을 진행할 수 있는 특징을 가지고 있습니다.
지금까지 살펴본 모델은 모두 범용 CPU를 활용한 병렬 프로그래밍 모델입니다. 하지만 범용 CPU가 아닌 특정 연산에 특화된 가속기를 활용하여 병렬화하는 모델을 가속기 병렬 프로그래밍 모델이라고 합니다. 지난 3편에서도 소개 드렸다시피, 이러한 가속기를 활용한 연산처리 방식을 이기종 컴퓨팅이라고 하며, 단순하고 반복적인 수치계산에 최적화된 CPU, DSP, GPU등을 활용하는 프로그래밍 모델이라고 볼 수 있습니다. 가속기 프로그래밍 모델은 수치계산에 최적화되어 있으므로 데이터 병렬화에 주로 사용됩니다.
현재 병렬컴퓨팅 시장에서 가장 각광받고 있는 것이 바로 GPU를 활용한 GPGPU 기술인데, GPGPU를 지원하기 위한 다양한 프레임워크들이 시장에 나와있는 상태입니다. NVIDA에서 만든 CUDA가 가장 대표적이며, CUDA를 추상화해서 손쉽게 프로그래밍 할 수 있는 OpenACC라는 것도 있습니다.
반면, OpenGL로 유명한 크로노스 그룹에서는 OpenCL(Open Computing Language)이라는 병렬 프로그래밍 프레임워크를 만들어 내놓았습니다. OpenCL은 GPU뿐 아니라 CPU, DSP, Cell 등 다양한 이기종 컴퓨팅 환경에서 사용할 수 있도록 표준화된 환경을 제공하고 있습니다.
OpneCL은 크게 OpenCL 컴파일러와 OpenCL 런타임 라이브러리로 구성되어 있습니다. 연산용 프로세서(가속기)에서 동작하는 프로그램은 OpenCL C언어로 작성하며, 이를 컴파일하여 바이너리 코드로 변환하는 도구가 바로 OpenCL 컴파일러입니다. 또한 CPU에서는 연산 프로세서용 프로그램을 실행하거나 관리하기 위한 제어용 프로그램도 개발해야 하는데, 이는 OpenCL 런타임 라이브러리를 통해 C나 C++을 이용하여 작성됩니다.
지금까지 프로그램의 성능을 향상시키기 위해 병렬화하는 과정을 함께 살펴보았습니다. 하지만 병렬 프로그램 코드를 작성할 때, 매우 중요한 요소가 있는데 바로 “동기화”입니다.
여러 개의 Task들이 병렬로 실행될 때, 동일한 자원을 공유해야 하는 경우가 발생합니다. 이러한 자원을 공유자원이라고 하는데 다수의 Task가 공유자원을 동시에 변경하고자 하는 경우 공유자원은 우리가 예상치 못한 값이 되어버릴 수가 있습니다.따라서 하나의 Task가 공유자원을 변경하는 동안 다른 Task가 해당 자원을 변경하지 못하도록 원자성을 보장해야 할 필요가 있으며, 이를 해결하기 위한 방법이 바로 동기화입니다.
그럼 공유 메모리 병렬 프로그래밍 모델의 멀티스레드 방식을 예시로 하여 동기화에 대해 짚어보도록 하겠습니다.
두 개 이상의 스레드들이 공유자원에 동시에 접근하는 상황을 바로 데이터 레이스라고 합니다. 모든 스레드들이 공유자원을 단순히 읽는 것은 문제가 되지 않으나 하나 이상의 스레드가 “쓰기” 작업을 시도하는 경우, 다른 스레드들은 공유자원에 대하여 전혀 예측하지 못한 엉뚱한 값을 참조할 수 있기 때문에 매우 치명적입니다.
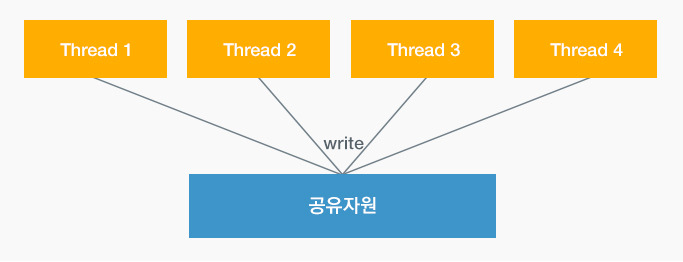 ▲ 데이터 레이스
▲ 데이터 레이스따라서 이러한 문제를 해결하기 위해서는 하나의 스레드가 작업을 진행하는 동안 다른 스레드들은 작업을 멈추고 대기하게끔 하는 메커니즘이 필요합니다.
위에서 설명드린 바와 같이, 데이터 레이스를 방지하기 위해서는 하나의 스레드가 작업을 진행하는 동안 다른 스레드들은 작업을 멈추고 대기하게끔 해야 합니다. 즉, 동기화는 기본적으로 작업을 진행 중인 스레드는 “lock”을 통해 작업에 대한 원자성을 확보하고 나머지 스레드들은 “wait”를 통해 대기하는 메커니즘을 가지고 있습니다.
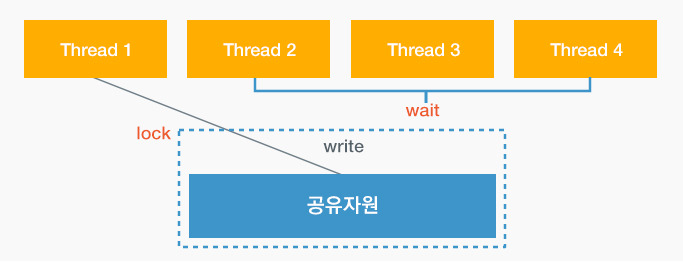 ▲ 동기화
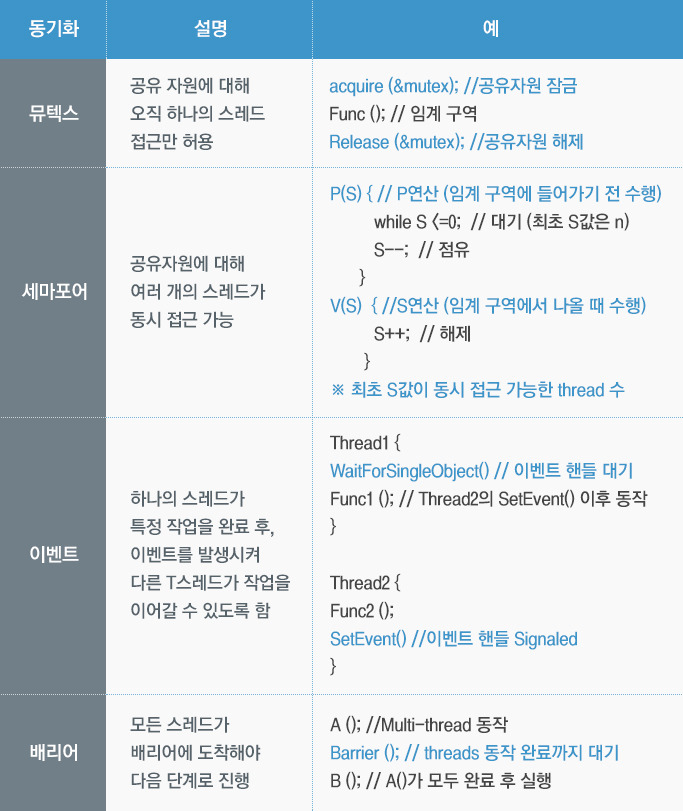
▲ 동기화소프트웨어적으로도 이러한 동기화 알고리즘을 구현할 수 있지만 운영체제에서도 동기화를 위한 여러 장치들을 제공하고 있으므로 이를 활용하면 매우 편리하게 구현할 수 있습니다. 아래는 운영체제에서 제공하는 다양한 동기화 장치들에 대한 설명이니 참고하시기 바랍니다.
데드락이란, 두 개 이상의 스레드들이 서로 다른 스레드가 점유하고 있는 자원이 해제될 때까지 무한정으로 대기하는 상태를 의미합니다. 즉, 하나의 스레드가 동기화를 위해 특정 자원을 lock한 이후에 해제되지 않아서 다른 스레드가 해당 자원을 점유하지 못한 채로 계속 대기하고 있는 상태를 나타냅니다.
이러한 데드락은 크게 3가지 경우에 발생하게 됩니다.
첫 번째, 스레드가 공유자원을 lock한 이후 unlock을 하지 않은 경우입니다. 이는 주로 프로그래머의 실수로 공유자원을 해제하는 코드를 넣지 않은 경우 많이 발생하게 됩니다.
두 번째, 스레드가 공유자원을 lock한 이후, 해당 스레드가 종료되는 경우입니다. 이는 스레드가 어떤 오류로 인해 강제 종료 되는 경우 주로 발생하게 됩니다. 따라서 이러한 경우 예외 처리를 해야 하며, 예외 처리 시에도 공유자원을 해제하는 구문을 반드시 추가하여야 합니다.
마지막으로, 아래 그림과 같이 thread간에 서로 자원을 요청하면서 대기 상태에 빠져 버리는 경우입니다. 자원을 점유하는 순서를 잘 조정하여 이러한 상황이 발생하지 않도록 예방이 필요합니다.
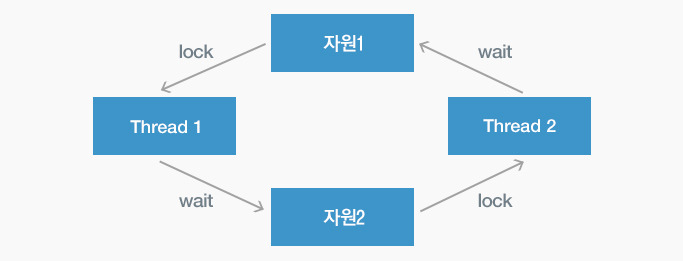 ▲ 데드락
▲ 데드락지난 1편부터 5편까지 병렬컴퓨팅에 대한 전반적인 내용을 소개 드렸습니다. 쭉 살펴보았던 것처럼 병렬컴퓨팅은 컴퓨터의 성능 향상에 큰 영향을 끼쳤으며, 현대 컴퓨팅 기술에 있어서 없어서는 안될 필수적인 요소로 자리매김하게 되었습니다. 그리고 현재까지도 성능 향상에 대한 지속적인 연구와 다양한 시도를 통하여 병렬컴퓨팅 기술은 끊임없는 진화를 하고 있습니다.다음 편에서는 마지막으로 이러한 병렬컴퓨팅의 미래의 모습과 향후 전망에 대해 살펴보도록 하겠습니다.
[참고자료]
위키백과, http://ko.wikipedia.org
대릴고브(2012). ‘멀티코어 애플리케이션 프로그래밍’ 한빛 미디어
FIXSTARS(2012). ‘OpenCL 프로그래밍’ 한빛 미디어
김민장(2010). ‘프로그래머가 몰랐던 멀티코어 CPU 이야기’ 한빛 미디어
글 : 삼성SDS 기술사회