![[IT에 한 걸음 더 다가가기] 연산처리의 성능 한계에 도전하는 병렬컴퓨팅 (3편) 썸네일 이미지](https://image.samsungsds.com/kr/insights/__icsFiles/afieldfile/2018/07/12/897_thumb.jpg?queryString=20260529094615)
![[IT에 한 걸음 더 다가가기] 연산처리의 성능 한계에 도전하는 병렬컴퓨팅 (3편)](https://image.samsungsds.com/kr/story/897_1.jpg?queryString=20260529094615)
지난 편에서는 싱글코어에서의 하드웨어적인 병렬컴퓨팅 기법들을 살펴보았습니다. [관련기사 바로 가기: 병렬 컴퓨팅의 다양한 기법I http://www.ictstory.com/933] 싱글코어에서는 클럭 속도를 높이고 명령어 수준 병렬성을 통한 성능 향상을 꾀하였으나, 하드웨어의 여러 제약으로 인하여 발열, 전력 소모, 병렬화 한계 등의 여러 가지 문제점들이 드러나게 되었습니다.
이러한 한계를 극복하기 위하여 멀티 코어가 등장하였으며, 병렬 컴퓨팅은 다수의 프로세서를 활용하는 기술로 진화하게 되었습니다. 이번 편에서는 이러한 멀티 코어 시대의 병렬 컴퓨팅 기법을 자세히 다뤄 보도록 하겠습니다.

멀티 코어 시대의 병렬처리 기법을 본격적으로 소개 드리기 앞서, 멀티 코어의 모체가 되는 병렬컴퓨터와 멀티 코어의 개념에 대해 잠시 살펴보겠습니다.
병렬컴퓨터란 다수의 프로세서들이 수많은 연산을 동시에 병렬처리할 수 있는 형태로 조직된 컴퓨터를 의미합니다. 과거부터 슈퍼컴퓨터는 대규모의 연산을 고속으로 처리하기 위해 이러한 병렬컴퓨터 구조를 갖추어 왔으며, 2000년대 들어서는 일반 PC에도 이러한 구조를 범용적으로 채택하게 됩니다.
병렬컴퓨터는 결합 구조에 따라 강 결합 구조, 약 결합 구조로 구분할 수 있습니다. 강 결합 구조란 다수의 프로세서가 주기억 장치 및 I/O를 공유하며, 하나의 운영체제가 모든 프로세서를 관리하는 구조로써SMP(Symmetric Multi-Processor)라고 합니다. 멀티 코어는 바로 SMP의 한 예라고 볼 수 있는데, 여러 개의 코어(프로세서)가 하나의 칩에 집적된 방식으로 CMP (Chip Multi processor)라고도 부르며 일반 PC에 가장 많이 적용되어 있는 병렬컴퓨터 형태입니다.
멀티 코어의 각 코어들은 메모리 접근 성능을 높이기 위해 명령어 캐시(I$)와 데이터 캐시(D$), 2차 레벨의L2 캐시를 가지고 있으며, 모든 코어는 L3 캐시를 통하여 데이터를 공유하게 됩니다.
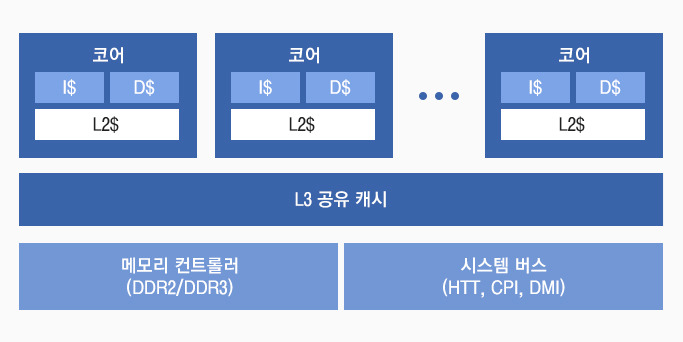 ▲ AMD/인텔의 최신 멀티 코어 프로세서 구조 (출처 : DBGuide.net)
▲ AMD/인텔의 최신 멀티 코어 프로세서 구조 (출처 : DBGuide.net)반면에, 약 결합 구조는 다수의 프로세서가 독립적인 주기억 장치와 I/O를 가지고 있으며, 각각의 운영체제를 지닌 구조입니다. 독립적인 PC들이 네트워크를 통해 상호 연결되는 클러스터나 그리드 컴퓨터 등이 이러한 약 결합 구조로 분류될 수 있습니다.
멀티 프로세싱은 다수의 프로세서가 장착된 컴퓨터에서 프로세서 간의 협력을 통해 연산을 처리하는 방식을 의미합니다. 즉, 멀티 코어에서는 소프트웨어 수준의 멀티 프로세싱을 통해 다수의 코어를 활용하여 병렬처리하는 방식으로 성능을 향상시킵니다.
다만, 제대로 된 성능 향상을 내기 위해서는 처리하고자 하는 연산을 각 코어에 효율적으로 배분할 수 있도록 프로그램을 구현해야만 합니다. 따라서 멀티 코어 시대에서는 병렬 프로그래밍의 중요성이 매우 커지게 됩니다.
그럼 멀티 프로세싱이 어떻게 이루어지는지 살펴보겠습니다. 일반적으로 우리가 컴퓨터를 사용할 때, 윈도 내에서 하나의 작업만 수행하는 것이 아니라 워드프로세서, 음악 감상 등 동시에 여러 작업들을 수행합니다.
싱글코어는 연산을 처리하는 프로세서가 한 개밖에 없기 때문에 여러 개의 작업을 동시에 병렬적으로 수행할 수가 없습니다. 따라서 싱글코어에서는 여러 개의 작업을 동시에 수행하는 방법으로, 운영체제 수준에서 멀티태스킹이라는 기법을 제공하고 있습니다. 이 기법은 다수개의 작업들을 작업 내용이나 우선순위에 따라 일정 시간을 배분하고, 배분된 시간만큼 CPU를 번갈아 가며 점유할 수 있도록 스케줄링 하는 방식입니다.
하지만 멀티 코어는 이에 더하여, 한대의 컴퓨터에 다수의 코어가 장착되어 있으므로 여러 개의 작업을 코어마다 나누어 배분하여 병렬적인 처리가 가능합니다.
멀티프로세싱 기반에서 각 코어로 배분되는 작업은 프로세스 또는 스레드(Thread) 단위로 처리됩니다. 프로세스란 메모리에 적재되어 현재 OS에 의해 실행 중인 프로그램을 의미하는데, 일반적으로 응용프로그램 또는 애플리케이션이라고 하는 것이 Windows 등의 운영체제 입장에서 프로세스라는 단위로 처리가 됩니다.
프로세스는 또다시 스레드라고 하는 경량화된 프로세스들로 나누어질 수 있는데, 이러한 스레드를 여러 개 생성하여 동시에 수행하는 기법을 멀티 스레딩(Threading)이라고 합니다. (여기서 언급 드리는 스레드는 하드웨어 수준에서 구현되는 스레드와는 다르므로 혼동하지 마시기 바랍니다.)
싱글코어에서는 스레드들이 멀티태스킹을 통해 병행적으로 처리되는 반면, 멀티 코어에서는 스레드가 각 코어로 배분되어 병렬적으로 처리될 수 있습니다. 운영체제는 이러한 코어의 전반적인 리소스 상황을 모니터링하여 스레드를 최적의 코어에 배분하기 위한 스케줄링 작업을 수행합니다.
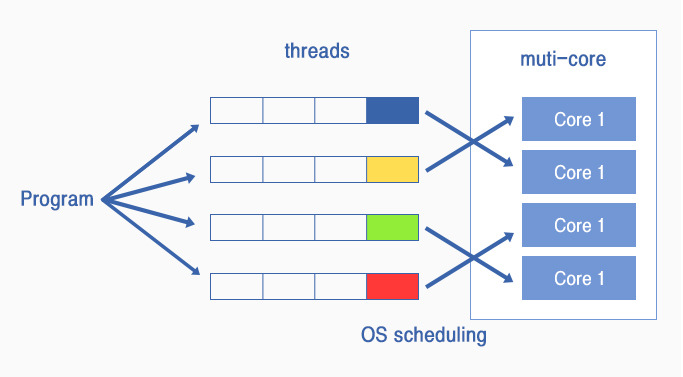 ▲ multi-threading
▲ multi-threading이렇게 멀티코어 환경에서는 컴퓨터가 알아서 병렬처리를 해 주는 것이 아니라, 프로그램을 구현할 때 동시에 수행될 수 있는 대상을 찾아 쓰레드를 만드는 작업, 쓰레드 간의 자원경쟁을 해소하기 위한 동기화 작업 등을 반드시 수행해야 합니다.
서로 다른 종류의 프로세서들을 다수 장착한 시스템을 이기종 컴퓨터 시스템이라고 하며, 이러한 시스템을 이용한 연산처리 방식을 이기종 컴퓨팅이라고 합니다. 이기종 시스템에서는 각 프로세서가 고유의 역할을 담당하며 상호 보완적인 형태로 동작하게 되는데, CPU, DSP, GPU 등 다양한 종류의 프로세서들을 결합하여 구성합니다.
이기종 시스템은 일반적으로 범용 프로세서와 가속기 형태로 구성이 됩니다. 범용 프로세서는 주 연산 및 제어 역할을 수행하며, 가속기는 Coprocessor 형태로 장착되어 범용 프로세서보다 고속으로 수행할 수 있는 특정한 작업을 담당하게 됩니다.
가장 대표적인 이기종 시스템의 예로는 GPGPU를 들 수 있습니다. CPU는 다양하고 복잡한 명령어들 처리할 수 있도록 설계되어 있는 반면, GPU는 그래픽 작업 특성상 단순하고 반복적인 수치계산에 최적화되어 있어서 이러한 수치계산을 GPU에 맡겨 연산 성능을 높이고자 하는 기술을 바로 GPGPU라고 합니다.
그럼 GPU 연산의 원리를 잠깐 살펴보도록 하겠습니다. 3D 모델은 모델을 구성하는 정점(vertex)과 정점들을 잇는 선, 그리고 정점을 이어서 만들어진 면에 대한 색상 및 Texture 이미지 등으로 구성되어 있습니다.
GPU는 이러한 3D 모델을 처리하기 위해 렌더링 파이프라인이라는 절차를 거치게 됩니다. 렌더링 파이프라인은 3D 모델의 정점과 면, 색상 정보 등을 입력받아 각 단계별로 필요한 연산을 거쳐 최종적으로 모니터에 표시되는 2D 이미지를 만들어냅니다. 렌더링 파이프라인에서 수행되는 대부분의 연산들은 하나의 명령이 수많은 정점이나 픽셀 등에 적용되는 방식입니다.
예를 들어 3D 모델을 특정 구간으로 이동 시, 이동 좌표에 대한 행렬이 3D 모델을 구성하고 있는 모든 정점에 적용되는 형태로 동작합니다. 따라서 동일한 명령이 다수의 연산을 처리하는 SIMD 구조로 조직되어 있다고 볼 수 있습니다.
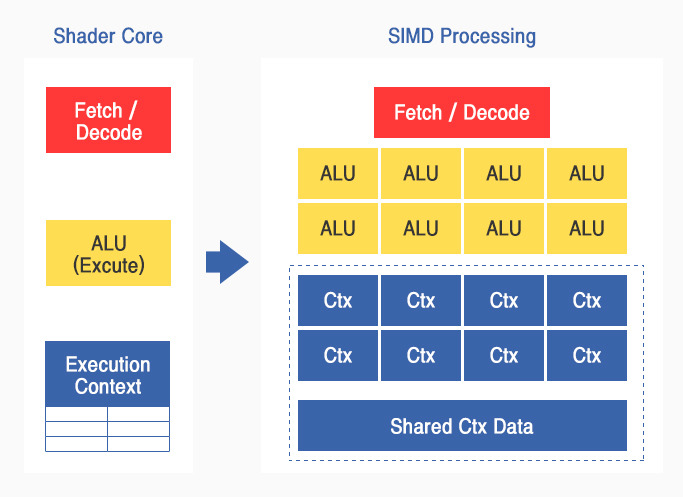 ▲ Shader Core
▲ Shader Core렌더링 파이프라인은 단계별로 전용 하드웨어로 구성되어 있지만 Shader라는 기술을 통하여 특정 단계들을 프로그래머블(Programmable) 하게 구현할 수 있으며, 다수의 Shader Core를 통해 병렬처리가 가능한 구조로 되어 있습니다.
Shader Core는 수치계산에 적합하도록 ALU에 자원이 집중되어 있으며, GPGPU는 이러한 Shader Core를 범용적인 연산에 활용합니다. 벤더마다 이러한 Core를 부르는 용어가 다양한데, NVIDA에서는 CUDA Core, AMD에서는 Stream Processor라고도 부릅니다.
이기종 시스템을 단일 칩으로 집적하는 형태를 이기종 멀티 코어라고 하며, 이를 비대칭형 프로세서 (AMP)라고도 부릅니다. 대표적인 이기종 멀티 코어로는 IBM Cell BE나 TI OMAP, APU (Accelerated Processing Unit) 등을 들 수 있습니다.
IBM Cell BE는 소니의 플레이스테이션이라는 게임기에 탑재된 프로세서로, 주 연산과 제어를 담당하는 코어인 PPE(Power Processor Element)와 보조 연산을 담당하는 코어인 SPE(Synergistic Processing Elements)들로 이루어져 있으며, SPE를 통하여 고속의 벡터 연산을 수행하여 성능을 높입니다.
또한 텍사스 인스트루먼트(TI)의 OMAP은 스마트폰 등에 사용되는 프로세서로 ARM을 기반으로 하는 CPU에 DSP (Digital Signal Processor)라는 장치를 통합하여 고속의 신호처리 및 수학적 계산에 활용합니다.
마지막으로, APU는 CPU와 GPU를 통합하여 단일 칩에 집적하는 프로세서입니다. 이기종 컴퓨팅에 있어서APU의 진정한 목적은 단순한 결합뿐만 아니라, 주 기억장치를 공유하여 CPU와 GPU 사이의 병목을 없애고, GPU를 애플리케이션 수준에서 손쉽게 다루도록 하는데 있습니다.
최근에는 이러한 아키텍처를 연구하기 위해 AMD가 주도로 하여 이기종 시스템 아키텍처(HSA)라는 협회를 설립하였으며, 다양한 모바일 칩셋 벤더사들이 참여하여 표준화 작업을 진행하고 있습니다.
분산컴퓨팅은 병렬컴퓨터의 약 결합 구조를 활용하는 기술로써, 멀티 코어와 다르게 독립적인 PC를 네트워크에 연결하여 협력하는 컴퓨팅 모델입니다. 분산컴퓨팅에서는 이러한 독립 PC들을 노드(Node)라고 부릅니다.
분산컴퓨팅은 여러 노드들을 네트워크를 통해 연결하기 때문에 공간적 제약이 없고 수많은 PC의 컴퓨팅 능력을 활용할 수 있어 대규모, 대용량 데이터를 처리하기에 매우 적합합니다. 대표적인 기술로는 클러스터 컴퓨팅과 그리드 컴퓨팅이 있습니다.
클러스터 컴퓨팅과 그리드 컴퓨팅의 의미는 매우 유사하나 그리드 컴퓨팅은 노드들이 원거리 통신망(WAN)에 연결되어 있다는 점에서 약간의 차이가 있습니다.
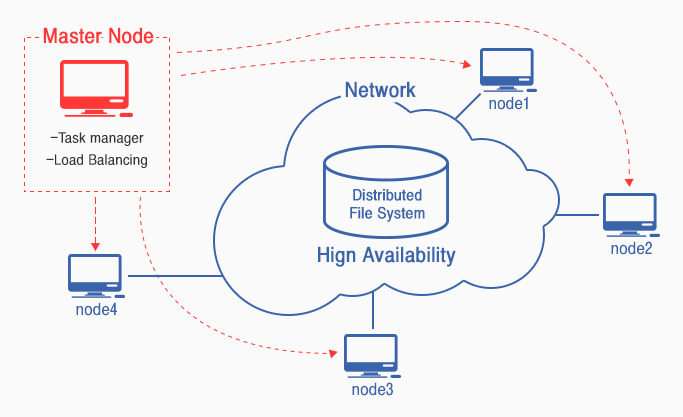 ▲ 분산컴퓨팅
▲ 분산컴퓨팅분산컴퓨팅은 각 노드가 별도의 독립적 환경을 가지고 있으므로, 무엇보다 각 노드 간의 유기적인 관계가 매우 중요하며 아래와 같은 특징을 가지고 있습니다.
첫 번째, 고가용성 (HA : High Availability)입니다.
분산컴퓨팅 환경에서는 여러 대의 노드가 묶여 있어 한대의 노드가 고장이 발생하더라도 다른 PC에 의해 Failover 및 Load Balancing이 수행 됨으로써 서비스 연속성을 가질 수 있습니다.
두 번째, 위치 투명성입니다.
네트워크에 연결된 모든 노드들의 자원을 로컬의 자원처럼 다룰 수 있는 위치 투명성이 보장되어야 합니다. 분산컴퓨팅 환경에서는 이러한 위치 투명성을 보장하기 위해 분산 파일시스템(DFS : Distributed File System)을 제공합니다.
세 번째, 수평 확장성(Scale-Out)입니다.
수평 확장성은 노드 자체의 성능을 올리는 것이 아니라 노드를 단순히 추가 함으로써 시스템의 성능을 향상시키는 것을 말합니다. 네트워크에 연결된 각 노드들은 메시지 전달 인터페이스 등의 프로토콜을 통해 서로의 정보를 교환하고 병렬처리를 위한 노드 간 협력을 수행함으로써 성능을 향상시킵니다.
한편, 아파치 재단에서는 클러스터 컴퓨팅을 응용하여 분산파일시스템인 HDFS(Hadoop Distributed File System)와 분산 병렬처리를 수행하는 맵리듀스 엔진 등으로 구성된 Hadoop이라는 프레임워크를 오픈소스로 공개하였습니다. 이후, Hadoop은 빅데이터 처리에 뛰어난 성능을 발휘하면서 빅데이터 처리의 표준 프레임워크로 자리매김하게 되었습니다.
지금까지 멀티 코어 시대의 병렬 컴퓨팅 기법에 대해 알아보았습니다. 서두에도 잠시 소개가 되었지만 병렬컴퓨터 분야는 과거 컴퓨터가 탄생한 초기부터 꾸준히 연구되어 왔으며, 컴퓨터 성능 향상을 위한 기반이 되었습니다. 다음 편에서는 이러한 병렬컴퓨터의 역사, 분류, 구조 등을 자세하게 다뤄 보도록 하겠습니다.
<참고자료>
위키백과, http://ko.wikipedia.org
Kayvon Fatahalian (2008). ‘From Shader Code to a Tefaflop: How Shader Cores Work’ Stanford University
