![[IT에 한 걸음 더 다가가기] IT 미래를 혁신할 오픈소스SW, 그것이 알고 싶다! (4편) 썸네일 이미지](https://image.samsungsds.com/kr/insights/__icsFiles/afieldfile/2018/07/12/542_thumb.jpg?queryString=20260709040327)

지금까지 오픈소스SW에 대한 기본적인 소개 – 기업에서는 어떤 오픈소스SW를 활용하고 오픈소스SW로 인해 기업의 IT 인프라는 어떻게 바뀌고 앞으로 무엇을 준비해야 하는지, 기업에서 가장 중요한 데이터와 그 데이터를 관리하는 오픈소스 DBMS 기술은 어떤 것이 있는지에 대해 다루었습니다.
오늘은 제4편 “기하급수적으로 늘어나는 빅데이터를 위한 오픈소스SW 기술” 입니다. 기업에서의 핵심인 데이터와 그 데이터를 분석하여 비즈니스에 가치를 부여하는 빅데이터, 이를 저장하고, 계산하고 분석하는 기술인 Hadoop(하둡), Hadoop-ecosystem(하둡 생태계) 및 분석 기술에 대해 소개하고 앞으로 빅데이터 관련 기술들은 어떻게 발전하고 기업에서는 어떻게 활용될 것인지에 대해 이야기하겠습니다.
제3편: 기업의 핵심 데이터를 책임지는 오픈소스 DBMS 기술
제4편: 기하급수적으로 늘어나는 빅데이터를 위한 오픈소스SW 기술
제5편: 오픈소스SW 차세대 트렌드
45억 년 전 인류가 태동하고 난 이후 2003년까지 5 exabytes(엑사바이트)의 데이터가 생성되었다고 합니다. 2012년 한 해에만 45억 년 동안 생성된 데이터의 500배나 되는 2.7 zetabytes(제타바이트)의 데이터가 만들어졌고 2015년 7.9 제타바이트의 데이터가 생성될 것으로 예측되고 있습니다. 어느 정도인지 한번 계산해 볼까요? 1 제타바이트 = 1000 엑사바이트 = 1018 = 260 Bytes 이고, 영화 한편이 2GB(gigabyte) 정도니 2015년 기준으로 영화 3조 9천5백억 편에 해당하는 데이터양입니다. 1 TB 하드디스크 기준으로 영화500편 정도 들어가므로 하드디스크 79억 개가 필요합니다. 하드디스크는 높이가 2.6Cm 정도 되고 길이가15Cm 정도 되니, 하드디스크를 줄을 세우면 40000Km 둘레의 지구를 30바퀴 돌 수 있습니다.
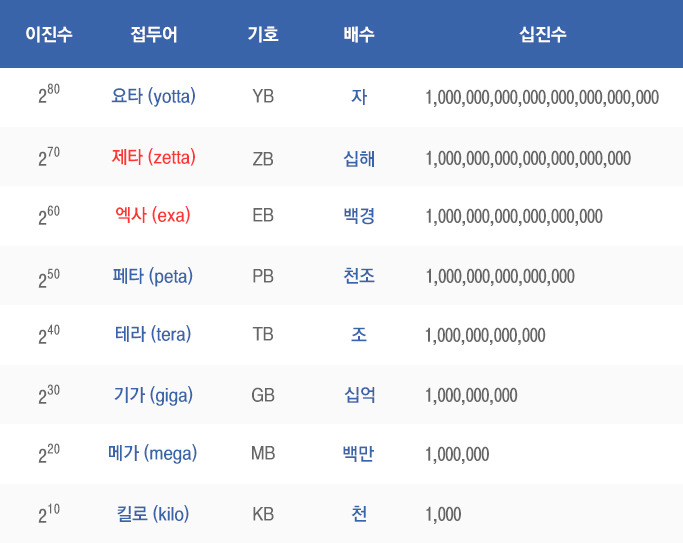
▲ 정보의 크기, 출처 : 위키피디아
전 세계적으로 인터넷 서비스, 소셜미디어, 카메라, 센서, 사용자 생성 콘텐츠 등의 폭발적인 증가로 데이터의 양이 기하급수적으로 늘고 있습니다. 이로 인해 기업에서 서비스하는 시스템의 로그 데이터도 상상을 초월할 만큼 증가하고 있고 문서, 웹 페이지, 전자 메일을 포함한 기업 데이터도 빠르게 증가하고 있습니다.이런 데이터 중 90% 이상은 구조화되지 않은 데이터 들이고 데이터의 양과 복잡성만으로도 기존 시스템으로는 저장이나 분석이 어려운 세상이 되었고 불필요한 데이터가 너무 많아 그 데이터 중에 의미 있는 정보를 찾고 분석해서 다시 서비스에 이용하는 것이 중요한 중요한 빅데이터 시대가 도래했습니다. 빅데이터는 2011년 하반기부터 신문, 방송 및 기술 트렌드 등에 소개되기 시작했고 2012, 2013년 IT업계에서의 핵심 키워드였습니다.
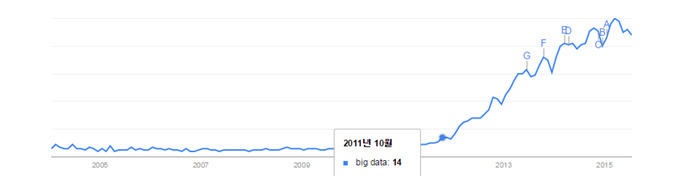
▲ 빅데이터에 대한 관심도, 구글 트렌드
2012년 미국 대통령 선거에서 오바마가 가장 먼저 채용한 사람이 빅데이터 분석가라는 뉴스가 돌고 오바마가 선거에서 당선이 되면서 더 큰 관심을 얻기도 했고 2012, 2013년 동안에는 빅데이터를 모르면 뭔가 큰일이 난 것처럼, 모든 세상이 빅데이터로 인해 바뀔 것처럼 시끄럽고 요란하게 시장과 IT 업계를 휩쓸고 지나갔습니다.
빅데이터란 좁은 의미에서는 엄청난 데이터를, 넓은 의미로는 기존 시스템으로는 수집, 저장, 처리, 분석하기 어려운 정형, 비정형 데이터를 활용하는 기술, 분석방법 및 관련된 인력, 조직을 포괄하는 개념입니다. 저는 “기존 시스템으로 분석할 수 없는 양의 데이터를 분석하기 위한 시스템과 이에 대한 분석 방법”이라고 생각합니다. 데이터의 양이 많아지면 기존 시스템으로는 수시간, 수일이 소요될 수 있고, 전혀 처리를 못하는 상황이 발생합니다. 그렇기 때문에 시스템의 아키텍처, 애플리케이션, 분석 방법, 저장 방법 등 모든 영역에서 새로운 기술, 새로운 패러다임의 접근 방식이 필요합니다.
지금까지는 시스템 확장을 위해서는 서버를 교체하거나 CPU, 메모리, 하드디스크를 늘리는 scale-up 방식을 사용했으나 빅데이터 세상에서는 단순한 scale-up으로는 엄청난 양의 데이터를 수집, 가공, 분석할 수 없습니다. 분산 처리 가능한 scale-out 되는 새로운 구조가 필요하고 이를 위한 기술들이 필요합니다.
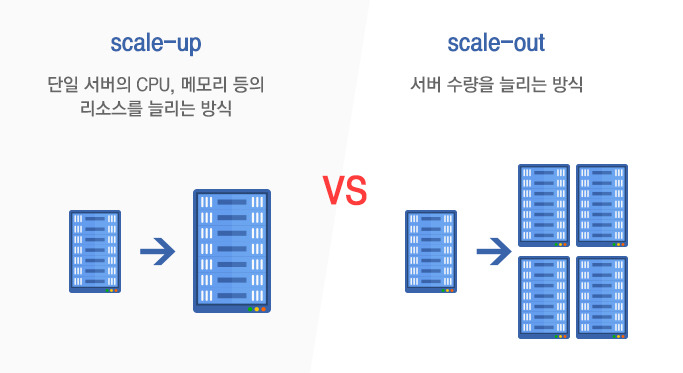
▲ scale-up vs. scale-out
이러한 빅데이터 세상에서 IT 시스템의 문제를 해결하기 위해 새롭게 떠오른 기술이 Hadoop입니다.
Hadoop은 아파치 루씬(Apache Lucene)의 창시자인 더그커팅(Doug Cutting)이 개발하였습니다. Hadoop의 네이밍은 더그커팅의 어린 딸이 좋아하는 노란 코끼리 봉제 인형을 딸이 “Hadoop” 이라고 불러서 만들어진 이름으로 단어에는 특별한 의미가 있지 않습니다.
Hadoop은 오픈 소스 기반 분산 컴퓨팅 플랫폼으로, 일반 PC급 성능의 컴퓨터들로 가상화된 대형 스토리지를 형성하고 그 안에 보관된 거대한 데이터를 병렬로 처리할 수 있도록 개발된 자바 SW 프레임워크입니다. 2002년 자료와 정보를 검색하는 크롤러(crawler)인 너치(Nutch)의 분산 처리를 지원하기 위해 개발이 시작되었고 초기에는 검색 페이지 수에 한계가 있었는데, 2003년 구글에서 분산 파일 시스템(GFS: Google File System)의 구조를 논문으로 공개하면서 이를 해결할 수 있는 너치 분산 파일 시스템(NDFS: Nutch Distributed File System)을 2004년 구현하게 되었습니다. 2006년 NDFS( = 이후 HDFS: Hadoop Distributed File System)와 분산 계산을 위한 구글의 MapReduce(맵리듀스)를 묶어 Hadoop이라는 아파치 프로젝트가 진행되었습니다. 더그커팅은 비슷한 시기에 야후에 합류하여 하둡을 웹 시스템으로 전환하였고, 2008년 야후의 검색 색인 제품이 1만 코어 하둡 클러스터에서 구현되었습니다.
빅데이터 처리를 위한 분산, 병렬 처리(수집/저장/계산/관리)를 위한 Hadoop은 분산 컴퓨팅 OS 로서 다음 두 가지의 중요한 기본 서비스를 제공합니다.
- HDFS(Hadoop Distributed File System): 하둡 분산 파일 시스템으로 대용량 데이터 (terabytes, petabytes, …) 를 저장하도록 고안되었고, 이를 위해서 데이터를 여러 대의 컴퓨터에 나누어 저장합니다.
– 수천 대 규모의 대용량 단일 클러스터 구성이 가능한 파일 시스템
– 파일을 64Mbytes, 128Mbytes 단위로 나누어 여러 개로 복제하여 저장
– 외부 스토리지가 아닌 저가의 x86 장비를 로컬 디스크로 사용
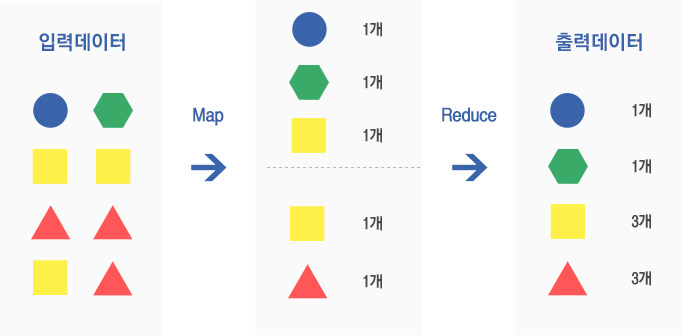
- MapReduce: HDFS 파일을 이용하여 분산 컴퓨팅 기능을 제공하는 프레임워크로 클러스터를 이루는 각 서버가전체 처리 작업의 일부를 병렬로 수행합니다.
– HDFS 파일을 이용하여 분산 처리 방법을 제공하는 프레임워크
– Map 함수를 통해 데이터를 처리하고 Reduce 함수를 통해 결과값을 계산
Hadoop은 저장, 병렬처리를 할 수 있지만 빅데이터를 관리하고 분석하여 시각화하기 위해서는 Hadoop-ecosystem 들이 필요합니다.
- Flume(플룸): 원격 로그 데이터 수집
- Sqoop(스쿱): RDBMS로부터 데이터 수집
- Hive(하이브): 하둡 데이터 Query를 위한 SQL 언어
- HBase: 하둡 기반 NoSQL DBMS
- Pig: 데이터 처리를 위한 대화식 스크립트 언어
- Oozie(우지): 복잡한 데이터 처리 작업을 위한 워크플로
- Tajo(타조): RDBMS, HDFS, 아마존 S3 등 다양한 저장소 데이터 처리를 위한 SQL 언어(한국에서 개발 시작)
- Spark(스파크): 메모리를 활용해 빠르게 데이터를 처리
- R(알): 대용량 통계 분석, View를 제공하는 분석 도구
- Mahout(머하웃) : 기계학습 알고리즘 라이브러리를 제공하는 분석 도구
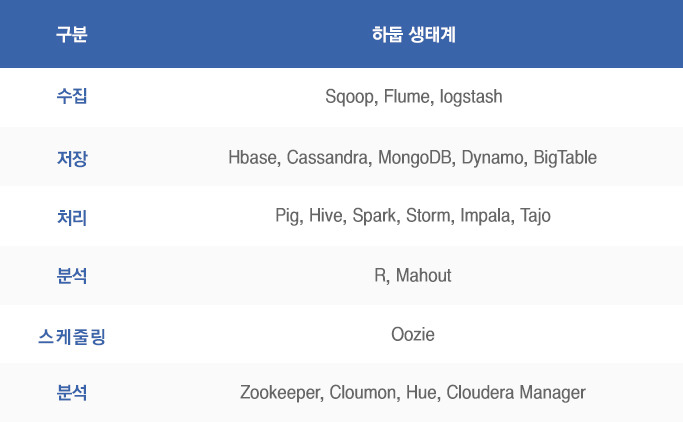
▲ 활용 영역별 하둡 생태계
빅데이터 분석을 위해서는 통계 라이브러리 및 시각화를 위한 도구들이 필요하고 빅데이터 속에서 분석을 통해 비즈니스 가치를 찾을 수 있는 빅데이터 분석 전문가가 필요합니다. 이런 빅데이터 전문가들에게 꼭 필요한 SW가 “R”과 “Mahout”입니다.
빅데이터 분석을 위해서는 확률, 통계, 개발, 시각화 기술이 필요한데, R은 기본적인 통계 지식만 있으면 필요한 통계 알고리즘 기반에서 시각화까지 제공하여 빅데이터 분석을 위해서는 꼭 필요한 도구입니다.
▲ R 분석을 통한 시각화
Mahout은 하둡에서 동작하기 때문에 대용량의 데이터에 대해 분석이 가능하며 클래스로 구성되어 데이터를 이용해 실행만 하면 원하는 결과를 얻을 수 있습니다. 통계를 공부한 사람들에게는 익숙한 Naive Bayes, Neural Networks, Support Vector Machines, Logistic Regression, Locally Weighted Linear Regression, k-Means, Independent Component Analysis, Gaussian Discriminative Analysis 등의 추천 엔진, 군집, 분류 등의 다양한 알고리즘을 제공합니다. Mahout의 결과는 Text 기반으로 제공되어 아직은 일반인이 분석하기에는 쉽지 않지만 기계학습을 활용하여 빅데이터 분석이 가능한 아파치 오픈소스SW 프로젝트로 앞으로의 발전이 기대됩니다.
기업에서는 빅데이터를 잘 활용하여 비즈니스에 가치를 부가하려고 많은 노력을 합니다. 빅데이터 분석을 위한 기술인 하둡은 scale-out 구조의 유연한 분산 아키텍처를 갖고 있지만 기존에 사용하던 전통적인 서버 아키텍처를 활용하지는 않습니다. 이로 인해 기존 개발자나 운영자는 새롭게 바뀐 아키텍처를 잘 이해하기 어렵고 이해를 위해서는 오랜 시간의 학습이 필요합니다. 뿐만 아니라 기존에 사용하던 애플리케이션, 관리 시스템도 빅데이터 인프라에 맞춰 모두 변경되어야 하기 때문에 기존 운영 시스템보다는 분석이 필요한 업무를 대상으로 활용도를 높이고 있습니다.
통신사, 은행, 카드사 등 대국민을 대상으로 서비스하는 사업자의 경우는 고객의 행동 패턴, 고객의 소비패턴을 분석하여 관심 있어 하는 서비스를 추천하는 마케팅 도구로 빅데이터를 많이 활용합니다. 이에 반해IT기업에서는 내부에서 활용하는 IT 자원들을 분석하여 원가 절감을 위한 도구로도 많이 활용합니다. 서버,네트워크 장비 등을 몇 년 동안 운영하는 것이 가장 효과적인지 이전 HW fault 정보 등을 바탕으로 통계적으로 예측하여 일반적으로 5년 정도 사용하고 폐기하는 장비 사용 연한을 늘리거나 오랜 기간 동안 사용해도 장애가 발생하지 않는 디바이스를 재활용하여 원가를 절감하는데 활용하기도 합니다.
IT 시스템을 운영하는 회사에서는 수만 대에서 수백만 대의 서버, 네트워크 장비뿐 아니라 OS, DBMS, WAS, Web Server, Application 등의 SW를 운영하는데 하루에도 수건에서 수십 건 이상의 장애가 발생합니다. 장애를 적기에 예측하는 것은 IT 시스템을 운영하는 회사의 손실을 최소화하고 서비스하는 고객의 비즈니스 영속성을 제공하기 때문에 기업에서는 장애를 사전에 예측하여 장애를 최소화하기 위한 도구로 빅데이터 분석을 하고 있습니다. 개인적으로 빅데이터 분석 중 가장 어려운 부분이 다양한 시스템에서 발생하는 장애를 사전에 예측하는 부분이라고 생각합니다. 인적 실수로 인한 장애, 장비 노후화로 인한 장애, HW fault, 애플리케이션 오작동 등 다양하고 예측하기 어려운 장애에 대해 빅데이터 기술을 활용하고 있습니다.아직은 완벽한 장애 예측은 어렵지만 빅데이터 관련 기술의 안정화 및 기계학습의 발전을 통해 장애 유형 자산화, 장애 패턴 자동 학습을 통해 예측 시스템의 정확도는 계속 높아질 것입니다.
가트너(Gartner) Hype Cycle을 보면 Cloud, Bigdata, IoT, SDx 기술이 진화 발전하고 있고 Cloud 기술은 안정화 단계 진입의 초입이고 빅데이터는 시장에서의 거품이 사라지고 관심은 조금 줄었지만 기술적으로는 좀 더 성숙해지는 안정화기로 가고 있습니다. 그 뒤를 IoT, SDx 기술이 시장의 이슈로 떠오르고 있습니다.
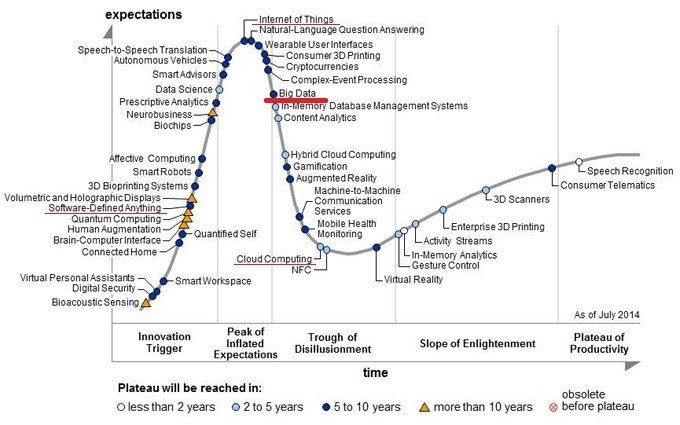
▲ 출처 : 가트너 Hype Cycle 2014
빅데이터의 시작은 데이터를 가지고 노는 것입니다. 기업에서 개발자, 분석가 양성을 통해 기업 데이터를 가지고 노는 것에서부터 시작하면 새로운 개선과 혁신, 새로운 기회가 빅데이터와 함께 하리라 생각합니다.아직은 어디서부터 시작해야 할 지, 어디로 가야 할지 시행착오를 거치는 단계지만 비즈니스 모델 별로 준비해 나가다 보면 어마 어마한 데이터 자체가 아니라 데이터를 시각화 하여 핵심만 볼 수 있는 시대가 올 것이고 이러한 기반은 경영자의 의사결정을 위한 중요 정보가 될 것입니다.
저는 빅데이터가 태풍의 중심으로 이동하여 지금은 가장 고요하고 맑은 태풍의 눈에서 다음 단계로 도약을 준비하는 시기라 생각합니다. 빅데이터 기술을 뒷받침할 Hadoop, Hadoop-ecosystem, 실시간 수집, 분석 및 인공지능 등의 오픈소스SW 기술들이 하나 둘씩 안정화 되어가고 사용자들이 사용하기 편한 상태로 진화 발전하고 있으니 3~4년 후면 다시 한번 이슈가 되고 일반화된 기술로 정착할 것이라 생각합니다. 그때는 기업에서도 수십 년 동안 변화가 거의 없었던 지금의 IT 인프라 구조와는 다른 새로운 패러다임의 기술들을 수용할 수 있는 인프라 구조가 안정화 되어 준비되어 있을 것입니다.
시장의 큰 방향성은 Mobile, SNS, Cloud, IoT, SDx 기술들과 빅데이터 기술의 결합입니다. 저는 빅데이터와 함께할 미래가 기대됩니다. 그 중심에는 IT 미래를 혁신할 오픈소스SW기술들이 함께할 것이라 생각합니다. 빅데이터의 핵심 기술인 Hadoop 과 Hadoop-ecosystem, 빅데이터 분석 기술, 기업에서의 활용사례 및 앞으로의 빅데이터 방향성에 대한 “기하급수적으로 늘어나는 빅데이터를 위한 오픈소스SW 기술” 소개는 여기까지입니다. 연재의 마지막 편인 다음 편에서는 IT 미래를 혁신할 오프소스SW 기술의 향후 트렌드에 대해 소개 해드리겠습니다. 그럼 5편 “오픈소스SW 차세대 트렌드”에서 다시 만나도록 하겠습니다.
<참고자료>
http://www.intel.com/Bigdata, 인텔
http://ko.wikipedia.org/, 위키피디아
https://www.r-project.org/, 통계계산 R 홈페이지
http://www.gartner.com/home, 가트너
Hadoop: The Definitive Guide Third Edition, Tom White, O’REILLY
