![[IT에 한걸음 더 다가가기] SMAC의 분석 부문, 지능화를 지향하는 Machine Learning (3편) 썸네일 이미지](https://image.samsungsds.com/kr/insights/__icsFiles/afieldfile/2018/07/12/549_thumb.jpg?queryString=20260529094615)

지난 2편에서는 머신러닝의 개념과 유관 기술들과의 관계에 대해서 기본 개념 설명을 위주로 했다면, 이번 글에서는 머신러닝이 어떻게 학습을 하고 예측을 하는지 단순화시킨 도식과 수식 위주로 살펴보고자 합니다. 중간에 일부 등장하는 수식은 더 상세한 설명을 위한 것이니 어려우시다면 살짝 건너 뛰셔도 무방합니다.
제1화 : 각광받는 딥러닝의 근원, 인공신경망(Artificial Neural Network)
제2화 : 인공신경망의 본류인 머신러닝(Machine Learning, 기계학습)
제3화 : 머신러닝 매커니즘 및 유형
제4화 : 다양한 머신러닝 알고리즘
제5화 : 머신러닝의 응용 분야 및 적용 사례

머신러닝을 위해서는 학습 및 검증을 위한 데이터, 학습 모델 또는 알고리즘이 필수적인 구성요소이며, 절차는 ‘가설-검증-결과’의 흐름으로 단순화시켜 바라볼 수 있습니다.
지난 편에서 언급했듯이 사람이 학습(러닝, Learning)하기 위해서는 책을 보거나 다른 사람들의 말을 듣는 등 외부 데이터의 입력을 반복해서 받아들여 학습하게 되는데, 머신(Machine, 기계)도 데이터를 바탕으로 학습하게 됩니다. C 또는 Java 프로그래밍을 처음 배울 때, “Hello, world!” 출력부터 시작하고 영상처리(Image Processing)을 처음 배울 때는 Lenna의 얼굴 사진을 사용하는 것처럼, 판별분석이나 머신러닝 알고리즘을 학습 또는 테스트하기 위한 유명한 데이터 집합(Data set)이 바로 붓꽃 데이터(Iris flower data set)입니다. 붓꽃 데이터는 빅데이터(Big Data)가 아닌 스몰데이터(Small Data)입니다.
* 1편과 2편에서 딥러닝을 언급하며 빅데이터(Big Data)를 이야기하다가 갑자기 왜 스몰데이터(Small Data)를 이야기하는지 궁금할 듯하여 부연 설명을 드리자면,머신러닝의 기본적인 학습 메커니즘의 학습 데이터를 쉽게 설명해 드리고자 스몰데이터(Small Data)를 소개합니다.
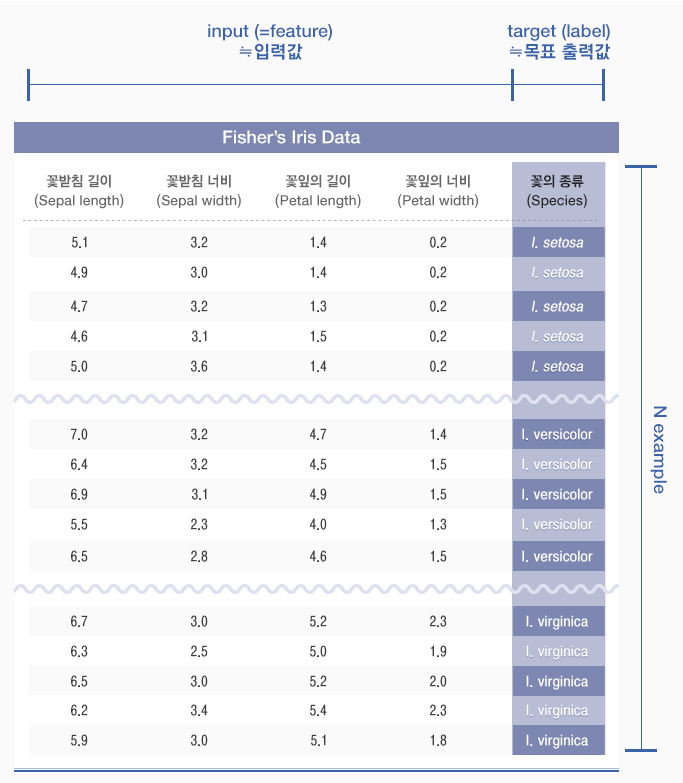
붓꽃데이터는 일명 ‘Iris flower data set’ 또는 ‘Fisher’s Iris data set’이라고 하며, 판별분석(discriminant analysis) 예제로서 1936년 로날드 피셔(Ronald Fisher)에 의해 소개되었습니다. 세 종류 꽃들의 샘플을 각50개씩(150개) 꽃잎의 길이와 너비, 꽃받침의 길이와 너비를 기록했고 그 정보들 사이에서 유용한 상관관계를 찾아냈습니다. 비슷하게 생긴 듯해도 꽃받침(Sepal)과 꽃잎(Petal)의 길이와 너비로 3개의 꽃의 종류(품종)이 구분되었습니다.

워낙 오래전에 만들어진 데이터로써 150개 샘플이지만 데이터 마이닝을 비롯하여 머신러닝 모델(알고리즘) 등의 학습 및 검증을 위한 데이터로 많이 사용하게 되었으며, 입력값(Training Input Data)과 목표 출력값(Training Output Data)으로 이루어진 훈련용 데이터(Training Data)입니다.
* 입력값(4가지) : 꽃받침 길이/너비, 꽃잎의 길이/너비
* 목표 출력값(1가지) : 꽃의 종류
붓꽃 데이터 집합을 비롯하여 수많은 러닝머신 학습 및 검증을 위한 데이터 집합을 제공하는 사이트들이 있습니다.
* UC Irvine Machine Learning Repository
메인 화면 오른쪽의 ‘Most Popular Data Sets(hits since 2007)’에 붓꽃 데이터 집합이 1위로 올라와 있습니다.
사람과 같이 머신도 학습을 하기 위해서는 사고할 수 있는 뇌가 필요하고 뇌를 학습 시키는 방식에는 몇 가지 유형이 있습니다. 그중에서 두 가지 유형을 예를 들어 쉽게 설명하고자 합니다.
첫 번째 사례는 갓난아이가 태어나서 처음 말을 배우는 때입니다. 엄마의 모습을 보여주고 ‘엄마’라 부르고 아빠의 모습을 보여주고 ‘아빠’라 부르며, 사물과 이미지를 보여주고(입력데이터 or 입력값) 그에 맞는 명칭(목표데이터 or 목표값)을 반복적으로 알려주게 됩니다. 그러나 아기는 자라면서 사물, 이미지, 글자, 숫자 등을 학습하게 되는데, ‘6’과 ‘9’를 혼동한다거나 ‘물고기’와 ‘강아지’를 제대로 구분하지 못해 틀리는 경우가 다반사로 일어나게 되고 부모가 이를 정정해주어서 정확하게 구분할 수 있도록 해줍니다. 그렇게 몇 달이 흐르면 아기는 정확하게 인지하고 구분할 수 있는 수준까지 배우게(학습) 됩니다. 이처럼 정답 데이터(입력값과 정답이 되는 목표값의 쌍)로 뇌를 반복적으로 학습시키고 나면, 그동안 동네의 똥개만 보고 학습시켜왔는데도 불구하고 아이는 어느 날 처음으로 진돗개를 보고도 ‘강아지’라 부르고 풍산개를 보고도 ‘강아지’라고 부를 수 있게 됩니다. 이를 ‘지도/교사 학습’(Supervised Learning)이라 할 수 있습니다.
두 번째 사례는 초등학교 이후부터 성인이 되어서 배우는 때입니다. 이때도 통상적으로는 신문이나 책, 대화를 비롯한 다양한 매체 및 사람들에게서 듣고 보고 하면서 지도학습을 하는 경우가 많지만, 그렇지 않은 경우도 꽤 됩니다. 수많은 관찰과 연구 끝에 사람이 DNA 유전자로 구성되어 있다는 것을 밝혀낸다거나‘864386438643…’의 숫자 나열에서 ‘8643’이 수열이 반복된다는 사실 등은 누가 가르쳐 줘서가 아니라 수많은 다양한 데이터와 정보를 받아 들여서 스스로 인지하게 됩니다. 이를 ‘비지도/자율 학습(Unsupervised Learning)이라 할 수 있습니다.
위의 예시를 일반화시켜 학습 단계와 예측 단계로 2단계로 학습 매커니즘을 단순화 할 수 있습니다.
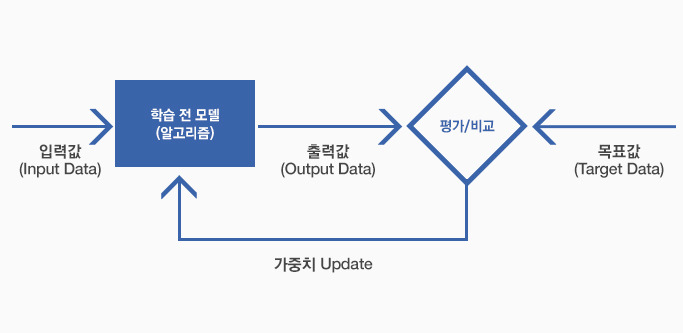
이미 알려진 입력값과 목표 출력값으로 이루어진 훈련 데이터(Training data)를 준비해서 비어 있는 모델(함수,알고리즘)을 완전한 학습 모델로 만드는 단계입니다.
1) 학습되기 전에 비어 있는 모델(알고리즘) 준비
2) 출력값과 목표값으로 구성된 학습 데이터(Training Data) 준비
3) 입력값을 모델에 넣어서 나온 출력값과 목표값을 비교해서 허용 가능한 임계치(Threshold) 이상의 차이가 나면 모델 내의 가중치 조정(Update)
4) 준비한 모든 학습 데이터의 입력값들이 모델을 통과하여 출력값이 목표값에 모두 수렴하도록 반복 적용
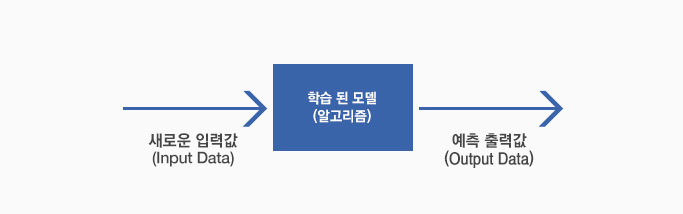
학습된 모델(알고리즘)에 새로운 값을 입력하면 적절한 결과값을(예측 또는 인식)얻을 수 있습니다. 학습이 잘 된 경우는 정확하게 예측/인식이 될 것이고, 학습이 잘 안 된 경우는 예측/인식이 부정확하게 나오게 됩니다.
앞에서 언급한 학습을 위한 훈련용 데이터(Training Data)와 학습 메커니즘의 개념을 이용하여 설명하자면,머신러닝은 주어진 데이터를 훈련(Training)시켜 학습된 지식(모델)을 기반으로 새로운 입력에 대해 적절한 답을 찾고자 하는 일련의 과정입니다. 이 때 훈련시키는 데이터가 질문(Training input)과 정답(Training output)이 모두 주어진 경우가 있고 질문만 주어진 경우가 있는데, 전자의 경우를 라벨링(Labeling) 되었다고 합니다. 머신러닝은 이러한 라벨링의 유무에 따라 네 가지로 분류할 수 있습니다.
가장 널리 사용되는 머신러닝 방법으로 지도(or 교사) 학습(supervised learning)과 비지도(or 자율) 학습(unsupervised learning)을 꼽을 수 있습니다. 머신러닝의 대부분(약 70%)이 지도 학습이며, 자율 학습은 약10~20%를 차지합니다. 이 밖에도 반지도(semi-supervised) 및 강화 학습(reinforcement learning)이 가끔씩 사용됩니다.
 문제(Training input)와 정답(Training output)을 알려 주고 가르치는 방식
문제(Training input)와 정답(Training output)을 알려 주고 가르치는 방식
(Predict a target y from input x)
지도학습은 이미 알고 있는 답이 있는 데이터로 알고리즘(모델)을 학습시킨 후, 새로운 데이터를 학습 모델(알고리즘)에 적용시켜 결과값을 예측합니다. 즉, 과거의 데이터로 미래 이벤트를 예측하는 경우에 주로 사용합니다.
간단한 예를 들자면, 연령별/성별로 선호하는 음악장르가 있다고 하면 훈련용 데이터 (Training Data)로 연령, 성별, 선호하는 음악장르를 학습 시킨 후 새로운 입력값으로 연령과 성별을 넣으면 이에 맞는 선호하는 음악장르가 나오는 것입니다. 실제로 신용 카드 거래의 사기성 여부나 보험 가입자의 보험금 청구 가능성을 미리 예측할 수 있습니다.
지도학습은 예측 모델(Predictive model)로써 결과물의 형태에 따라 회귀(Regression)와 분류(Classification)로 나눌 수 있습니다.
◆ 분류(classification)
– 어떠한 대상 객체를 특정 클래스에 할당하는 것으로서 예를 들어 제품의 품질을 자동 검사하여 제품의 합격 또는 불합격을 분류하는 것.
– 주어진 입력 값이 어떤 종류의 값인지 표시하는 것. (y represents a category or ‘class’)
– 알고리즘 : k-Nearest Neighbors, Bayesian Network, Support Vector Machine
◆ 회귀(regression)
– 분류를 모형화된 모델로 일반화(generalization)시켜, 시험 데이터로 해당 모델에서 유효한 결과를 얻을 수 있는 것으로서 예를 들어 과거의 실적과 주가에 근거하여 어떤 회사의 주식에 대한 배당 가치를 예측하는 것 [4]
– 유추된 함수에서 연속적인 값을 출력하는 것 (y is a real-value number)
– 알고리즘 : Linear regression, Lasso
문제만 있고 정답이 없는 수많은 임의의 데이터로 학습시키는 방식
(no explicit prediction target y)
사전 정보가 없고 입력에 대한 목표 결과값이 주어지지 않은 임의의 데이터를 학습에 이용합니다. 따라서 알고리즘은 현재 보여지고 있는 이미지가 무엇인지 알아내고, 궁극적으로 데이터를 탐색하여 내부 구조를 파악해야 합니다. 즉, 훈련 데이터 없이 임의로 주워지는 입력값으로 한다고 생각하면 되는데 예시로는 군집화(Clustering)과 딥러닝(Deep Learning) 등이 있습니다.
자율 학습은 특히 트랜잭션 데이터에서 효과를 발휘합니다. 예를 들어, 유사한 속성을 지닌 고객 세그먼트를 파악한 후, 그 유사성을 근거로 하여 마케팅 캠페인에서 고객 세그먼트를 관리할 수 있습니다. 또는 각각의 고객 세그먼트를 구분 짓게 해주는 주된 속성을 찾을 수도 있습니다.
◆ 군집화 (Clustering)
– 개체들을 유사한 속성을 지닌 집단으로 그룹 지은 후 각 그룹의 특성을 파악하는 것 미리 정의된 특성에 대한 정보를 가지지 않는다는 점에서 분류와 다름
– 많은 수의 객체를 여러 개의 유사성이 높은 클러스터 그룹으로 나뉘는 것 (discover underlying structure in data)
– 알고리즘 : K-Means, fuzzy, Meanshift
이번 편에서는 학습과 검증을 위한 훈련용 데이터, 학습 메커니즘, 학습 유형에 대해서 기본적인 내용 위주로 살펴보았으며, 다음 편에서는 학습 유형에서 소개된 학습 알고리즘에 대해서 보다 구체적으로 살펴보도록 하겠습니다.
<참고 자료>
- Wikipedia
- SAS
- 신경망 이론과 응용(I), 김대수, 하이테크정보
- 패턴 인식 개론, 한학용, 한빛아카데미
- T-Robotics Blog
