

어느 날 웹서핑을 하다 보면 갑자기 글자가 이상하게 깨져 보이는 현상을 경험해 보셨을 거예요. 보통 이런 경우 '인코딩이 잘못되었다'라고 하는데요. 이 현상이 왜 발생하는지 여러분은 알고 계시나요? 이건 세계 각국의 다양한 언어를 표현하는 컴퓨터 내부 방식이 서로 달라서 발생하는 현상입니다. 보통 컴퓨터에서는 Character Set라고 부르는 문자 집합이 OS에 내장되어 있고, 국제 표준으로도 등록되어 관리되고 있습니다. 그런데, 특정 웹페이지에서 내용을 불러올 때 잘못된 문자 집합의 설정을 사용하게 되면 내용의 글자가 전부 깨져서 보이는 현상이 발생하는 겁니다.
우리나라에서는 한글을 표현할 때 EUC-KR과 유니코드라는 2가지 방식을 기본으로 가장 많이 사용하고 있는데요. 한 가지 방식으로 사용하면 될 텐데 왜 이렇게 다른 방식을 혼용해서 사용할까요?
# 초창기 컴퓨터에서는 문자를 표현할 필요가 없었습니다
컴퓨터 역사를 아는 분들이라면 ENIAC(에니악), EDVAC(에드박) 이런 이름의 컴퓨터를 들어보셨을 겁니다. 고대 역사의 컴퓨터들은 1과 0 조합을 이용해서 프로그래밍을 했고, 결과는 불빛으로 반짝여서 보여주거나 특정 신호를 별도로 해석해야만 하는 구조를 가지고 있었습니다. 특히, 인간의 언어 체계로는 이해하기 쉽지 않은 방식으로 계산이 이루어졌기 때문에 문자를 딱히 표현해야 할 필요가 없었습니다.
그러나, 점차 개발 언어가 생겨나면서 인간이 이해하기 쉬운 문자와 문법을 이용하는 프로그래밍 언어가 만들어졌고 문자를 컴퓨터 안에서 표현해야 할 필요가 생겨났죠. 만들어진 문제 데이터를 서로 교환하기 위한 최초의 표준으로 만들어진 것이 바로 ASC II (American Standard Code for Information Interchange)라는 인코딩 방법입니다.
ASC II는 영어에서 사용되는 A~Z까지의 문자에 일련번호를 붙여 이 번호에 대응하는 문자를 출력하거나 입력받는 방식을 사용했는데요, 문자 체계의 용량도 무척 작았습니다. 이러한 인코딩 방식이 최초로 등장한 것이 바로 최초의 컴퓨터인 ENIAC 등장하고 나서 15년도 지난 후라고 하니 문자를 컴퓨터 내부에 이해할 수 있도록 만드는 일이 쉽지는 않았다는 걸 알 수 있죠. 특히 ASC II 코드는 알파벳만 표현이 가능해서 숫자와 특수 문자 등을 표기하기 위해 확장된 ASC II 코드가 만들어져서 총 255개의 문자를 표현하는 ISO-8859라는 국제 표준으로 정해지게 됩니다.
이미 눈치를 채셨겠지만, 알파벳 26글자에서 255글자까지 새로운 문자를 정의하게 된 아스키코드의 역사에서 보셨듯이 문자 체계가 복잡할수록 문자 집합, 즉 인코딩 방식은 복잡해지고 정착하는 데 오랜 시간이 걸리게 됩니다. 한글처럼 초중종성이 분리되어 무한대의 소리를 표현할 수 있는 언어는 그만큼 인코딩 방식을 설계하는 방법이 쉽지 않았으니까 말이죠.
# 한글 인코딩의 역사, 우리 말을 컴퓨터에 쓰고 읽을 수 있게 되다
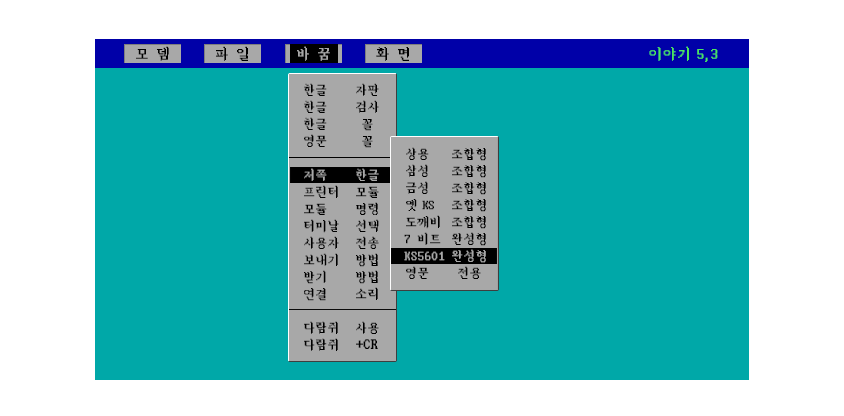
8비트 컴퓨터가 등장하면서 한글을 자소 단위로 표현하는 n 바이트 조합형이라는 방식이 만들어졌는데요. 3바이트/2바이트 조합형 등으로 불리던 여러 방식의 조합형 인코딩이 있었습니다. 당시 삼성, 금성, 삼보 등 여러 회사에서 컴퓨터를 판매하면서 각자 회사에서만 사용하는 조합형 폰트를 사용했는데요. 삼보 조합형 코드를 중심으로 통합되어갔습니다.
그런데, 윈도우가 등장하면서 한글 사용 방식이 대거 바뀌게 됩니다. 바로 CP949라고 불리는 완성형 한글을
MS에서 채용했기 때문이죠. 2바이트로 1개의 글자를 표현하는 이 방식은 완성형 한글로 불렸습니다.
그러나, 완성형 한글은 표현할 수 있는 문자 개수에 제한이 있었고, 확장 완성형이라고 덩치를 키운 이 인코딩 방식은 한글 문자 체계에 대한 인식이 부족했던 MS가 시장을 장악하면서 어쩔 수 없이 보편적으로 사용되게 됩니다. 윈도우 98이 CP949 완성형을 도입한 이후, 조합형 한글은 완전히 시장에서 사라지게 되는데요(초중종성을 조합해서 한글을 표현하는 것이 가장 효과적임에도 불구하고 말입니다). 이러한 완성형 한글의 가장 큰 단점을 보여주는 사례가 바로 KSC 5601이라는 코드입니다.
당시 이 한글 인코딩 방식은 모든 한글로 표현할 수 있는 글자의 21% 밖에 표현하지 못하다 보니 '똠방각하'라는 드라마를 'ㄸㅗㅁ방각하'라고 표현하거나, '펩시'를 '펲시'라고만 쓰게 되는 우스운 일이 발생하곤 했습니다(이 사례는 한글 인코딩 문제의 대표 사례로 아직도 인용되고 있습니다). 즉, 한글을 한글대로 사용할 수 없는 문제가 계속 지적되었습니다. 그러다 보니 완성형 한글로 통합되어 가는 과정에서 많은 한글 체계가 혼용되어 사용되었습니다.
MS가 8,822자를 추가한 CP949를 윈도우에 적용하고 시장을 통합하지 않았다면 아직도 한글 체계는 더욱 복잡하게 사용되고 있었을 겁니다. 최근에는 2,350글자를 표현 가능한 EUC-KR, 11,172자를 표현 가능한 CP949가 대중적으로 많이 이용되고 있죠.
# 전세계 공통 코드, 유니코드로 한글을 표현해요
유니코드는 전 세계에서 사용하는 모든 문자 집합을 하나로 모았다는 의미에서 Unicode라고 불립니다. 우리나라 한글은 유니코드 2.0 버전에서 한글 11,172자가 모두 포함되었는데요. 유니코드는 31비트의 문자 집합이라서 거의 무한대에 가까운 문자 표현이 가능하다는 게 특징이며, 각 나라에서 사용하는 특수한 문자 체계도 여러 영역으로 나누어 표현할 수 있는 장점이 있죠. 특히, 초중종성을 사용하는 한글의 자모와 소리마디, 자모 확장을 서로 다른 영역에 배치함으로써 체계적인 한글 표현이 가능해졌습니다. 특히, 유니코드는 아래에서 보는 것처럼 현대 한글에서 표현할 수 없는 옛 한글까지 표현할 수 있는 장점까지 갖추고 있습니다.

일반적으로 우리가 사용하는 한글 유니코드 표현방식은 UTF-8이라는 방식입니다. 그렇다면, 앞에서 말씀드린 대로 웹브라우저에서 한글이 깨져서 보이는 현상은 왜 발생하는 걸까요? 그건 브라우저 인코딩 값과 서버 인코딩 값이 서로 다르게 설정되었기 때문입니다. 즉, 웹서버에서는 EUC-KR 방식으로 한글을 저장해두고 보여주는데, 웹 브라우저에서는 그것을 UTF-8 코드에 맞춰 해석해서 보여준다면 당연히 서로 다른 방식으로 암호 해석을 하는 것처럼 글자가 깨져 보이게 되는 것이죠.
요즘 프로그래머들은 웹사이트를 개발하면서 'EUC-KR', 'UTF-8', 'ISO8859-1' 등 여러 한글 인코딩 방식을 인지하여 보여줄 수 있도록 호환성을 확보하고 있습니다. 그렇기 때문에 웹페이지에서 한글이 깨져 보이는 페이지를 찾아보기 힘들죠. 한글이 깨져 보일 때 "인코딩이 깨져서 그러는 거야"라고 이제 여러분도 아는척하실 수 있겠죠? 10월을 보내면서 한글 인코딩의 역사에 대해 알아봤습니다.

![]()