

AI는 공정한 의사결정을 하는가?
[장면 1]
미국 아마존(Amazon)은 2014년 우수한 역량을 가진 엔지니어 채용을 위해 입사지원서를 인공지능(AI)으로 평가할 수 있는 시스템을 개발하고 시험적으로 사용하기 시작했습니다. 하지만 오래지 않아 이 AI 시스템이 지원자의 성별과 관련해서 중립적인 평가를 하지 않는다는 것을 발견하게 됩니다. 예컨대, 입사 지원서에 ‘여성’임을 유추할 수 있는 데이터가 들어간 경우 평가에 불이익을 받을 수도 있는 ‘편향성’이 드러난 것입니다. 이러한 편향성이 발생한 이유는 채용 AI 모델의 학습에 사용된 과거 10년간의 지원자 데이터가 남성 엔지니어의 것이 압도적으로 많았기 때문입니다. 아마존은 이러한 문제점을 수정하려고 시도했으나 AI 모델이 잘 고쳐지지 않아서 2017년에 이 시스템을 폐기하기로 했습니다1.
[장면 2]
블룸버그(Bloomberg)는 최근에 매우 흥미로운 실험을 했습니다. 이미지 생성형 AI 서비스인 스테이블 디퓨전(Stable Diffusion)으로 14개의 직업을 가진 5,100명의 사람의 얼굴을 생성한 후에, 이것을 피부 색상과 성별을 기준으로 특징적인 패턴이 나타나는지 분석한 것입니다(그림 1). 그 결과 정치인, 법률가, 판사, CEO 등 고연봉의 직업일수록 피부의 명암이 밝고 남성인 경우가 많았습니다. 이 실험을 통해 블룸버그는 사람에게 있던 편견이 생성형 AI에서도 심각하게 발생할 수 있다는 결론을 도출했습니다2.
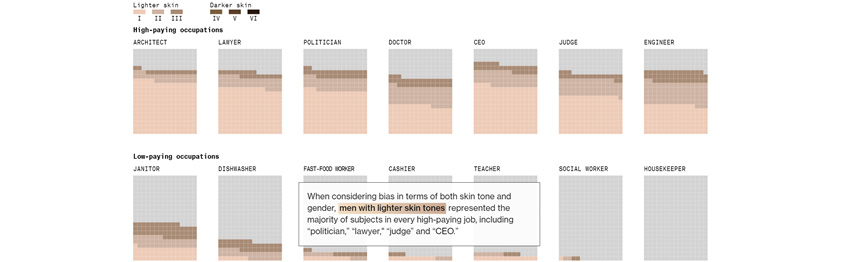 [그림 1] 스테이블 디퓨전으로 만들어낸 직업인 이미지의 분석 결과2
[그림 1] 스테이블 디퓨전으로 만들어낸 직업인 이미지의 분석 결과2
AI 기술의 활용이 비약적으로 증가하고, 특히 생성형 AI가 산업 환경과 일상생활의 대대적인 변화를 초래할 것으로 예견됨에 따라 부작용에 대해서도 사회와 정부 차원의 관심이 고조되는 분위기입니다. 2023년 5월에 히로시마에서 개최되었던 G7 정상회의는 이러한 분위기를 주요 국가들이 공식화하는 자리였습니다. 이 자리에서 각국 정상들은 신뢰할 수 있는 AI를 위해 적절한 통제와 규범이 필요하다는 것에 합의했습니다. 특히, 생성형 AI에 대해서는 2023년 연말까지 각국의 규범 수립을 위한 가이드라인을 마련하기로 하면서 이것을 '히로시마 AI 프로세스(Hiroshima AI Process)'라고 발표했습니다.
OECD가 G7 국가의 전문가를 대상으로 설문한 리포트를 보면 생성형 AI와 관련해서 가장 시급히 준비해야 하는 대책으로 첫째가 프라이버시 보호와 데이터 거버넌스이고, 그다음은 공정성과 편향을 줄이는 것입니다(그림 2). 프라이버시 및 데이터 거버넌스와 관련된 위험이나 AI의 불공정 또는 편향된 판단은 모두 AI 모델 학습을 위한 데이터 준비, AI 모델 학습, 서비스가 시작된 이후 등 모든 단계에서 발생할 수 있다는 점에 주의가 필요합니다.
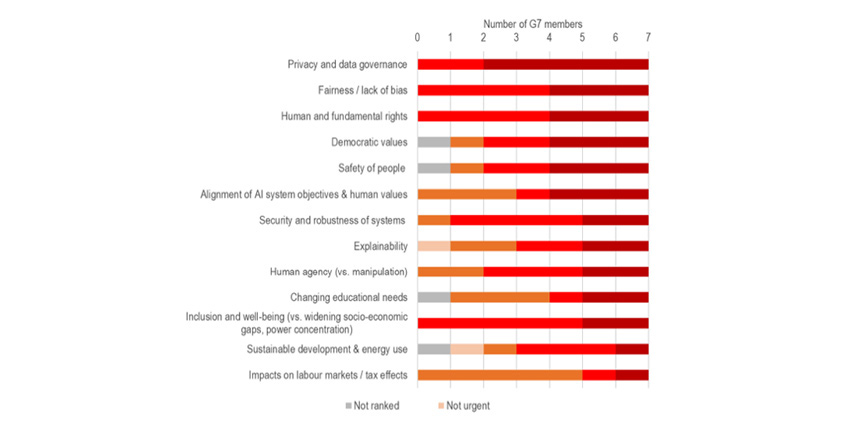 [그림 2] 생성형 AI 대책 우선순위(OECD 설문 결과)3
[그림 2] 생성형 AI 대책 우선순위(OECD 설문 결과)3
앞서 예시된 장면들과 같이 인간의 영역이라고 생각해 오던 ‘공정성’이 AI 시스템에도 요구되고 있으며, 인간의 편견 못지않게 AI가 만들어내는 결과물의 편향성은 고착화되고 다시 데이터로 쌓이면서 재생산될 수 있는 위험이 있다는 것을 부정할 수 없습니다. OECD가 발표한 설문은 이러한 우려가 기우가 아니며, 전 세계적이고 시급히 예방해야 할 과제라는 것에 공감대가 형성되어 있다는 것을 말해줍니다. 특히, 유럽과 같이 개인의 기본권 측면에서 강한 규제가 수립되어 있는 국가에서는 공정한 결과를 만들어 낼 수 있는 AI 시스템이 아니라면 생산과 유통, 서비스 등에서 제재를 받을 수 있는 날이 가까워져 왔습니다. 따라서, 공정성에 관한 이슈를 보다 상세히 이해하고 예방하기 위해 과연 AI의 공정성은 무엇이며, 어떻게 공정한 AI를 만들 수 있는지에 대해서 아래에서 논의해 보고자 합니다.
AI 시스템의 편향성과 공정성은 무엇인가
편향(偏向/bias)은 사전적으로는 한쪽으로 치우친 성질을 뜻합니다. 따라서, AI 시스템의 편향성은 AI 시스템을 구성하는 AI 모델의 의사결정이 어느 한쪽으로 치우친 결과를 산출하는 경향성을 의미합니다. 채용에 관한 AI 시스템이라면 [장면 1]에서와 같이 과거에 입사한 사람들의 입사 지원서에 수록된 데이터를 학습하여 평가 모델을 개발할 것입니다. 가령 AI 화상 면접 시스템이라면 피면접자의 얼굴 이미지 데이터를 통해 인종이나 성별이 학습될 수 있습니다. 학습 데이터에 수록된 지원자나 합격자가 특정 인종이나 성별이 월등하게 많았다면 평가 모델은 소수에 대해 편향된 의사결정을 내릴 가능성이 높습니다.
편향의 몇 가지 유형에 대해서 더 알아보겠습니다. 편향의 대표적인 유형으로 ‘역사적 편향’이 있습니다. [장면 1]에서 시사하는 바와 같이 과거에는 여성의 사회진출이 많지 않았지요. 오늘날 채용에서 성차별은 법적으로 금지되고 사회 인식에도 많은 변화가 일어났습니다. 그럼에도 불구하고 남성 위주의 고용시장이 보편적이었던 과거의 경험에 의존해 지원자를 평가하는 경우 나타날 수 있는 편향이 역사적 편향입니다. ‘대표성 편향’도 자주 발생합니다. 신종 바이러스의 발생으로 인해 미국에 있는 글로벌 제약회사가 백신을 개발한다고 가정하겠습니다. 제약회사가 미국에 거주하는 사람들만으로 표본으로 임상 실험을 진행했다면, 해당 백신은 아시아 국가에 사는 사람들에게는 효과가 덜하거나 부작용이 발생하는 경우가 많을 수 있습니다. 이와 같이 표본이 연구 대상으로 하는 모집단을 대표하지 못하는 경우를 대표성 편향이라 합니다. 이 외 다른 유형의 편향도 [표 1]에서 확인하실 수 있습니다.
| 편향 유형 | 설명 |
|---|---|
| 역사적 편향 | 과거의 경험과 데이터가 변화된 현재의 상황을 이해하는데 영향을 끼침 |
| 대표성 편향 | 수집한 표본이 수집자의 환경으로 인해 모집단의 특성을 반영하지 못하여 발생 |
| 측정 편향 | 측정도구나 방법의 오류로 측정결과가 치우치게 나옴 |
| 모집단 편향 | 샘플 데이터의 분포가 모집단의 분포와 다를 때 발생 |
| 표본추출 편향 | 하위집단의 랜덤하지 않은 표본 추출로 인해 발생 |
| 순위 편향 | 상위권의 정보가 상대적으로 과다하게 선택되는 결과 |
그럼 공정성은 무엇일까요? 공정의 사전적 정의는 “공평하고 올바름”입니다. 그렇다면 AI 시스템이 공정하다는 것은 무슨 의미일까요? 이에 대해 여러 논의와 주장을 할 수 있겠지만 AI의 의사결정이 대상을 차별하지 않는 것을 의미한다는 데 의견이 모아지는 것 같습니다5. 최근까지 AI가 가장 자주 사용된 목적이 분류(Classification)를 하기 위한 것임을 고려해 보면 AI로 인해 차별이 발생할 수 있다는 것을 동의하기 어렵지 않을 것입니다.
차별을 직접적 차별(Direct Discrimination)과 간접적 차별(Indirect Discrimination)로 구분할 수 있습니다. 직접적 차별은 명시적으로 특정 집단을 배제하는 경우입니다. 예를 들어 AI 채용시스템이 특정 속성을 가진 집단을 명시적으로 탈락시킨다면 직접적 차별이 될 것입니다. 간접적 차별은 차별 여부를 판단하기가 좀 애매한 경우입니다. 직접적 차별에서처럼 명확하게 구분이 되지는 않지만 결과적으로 차별이 있어 보인 경우이죠. 예를 들어 AI 채용시스템에 성별을 입력하지 않았으나 결과적으로 성별의 차이가 발생하는 경우가 해당할 수 있습니다.
AI 시스템의 직접적 차별을 예방하는 방안으로 집단을 특정하는 변수를 원천적으로 학습에 배제하는 방안이 있습니다. 그러나, 특정 변수를 사용하지 않더라도 결과적으로 차별이 발생하는 간접적 차별까지 예방하여 공정성을 확보하기 위해서는 결과를 직접 통제해야 할 수도 있습니다. 개인과 집단으로도 공정성을 구분할 수 있습니다. 개인에 대한 공정성을 정의하는 ‘개인 공정성(Individual Fairness)’과 성별, 나이 등을 기준으로 서로 다른 구성원들 간의 공정성을 정의하는 ‘그룹 공정성(Group Fairness)’이 그것입니다. 비슷한 능력을 가진 사람은 소득도 비슷할 것이라고 가정한다면 개인 공정성에 해당하고, 모집단의 남성과 여성의 비율이 50%로 동일하면 채용 인원도 남녀 각각 50%가 되어야 한다는 것이 그룹 공정성입니다6. 이상에서 AI 시스템의 편향성과 공정성의 개념에 대해 이해하고 AI 시스템이 어떤 경우에 차별한다고 인식될 수 있는지 사례를 통해 알아보았습니다. 다음으로는 공정한 AI 시스템을 개발하기 위해 어떤 접근을 취할 수 있는지 알아보겠습니다.
공정한 AI 시스템을 개발하는 방법은?
앞의 내용을 통해 짐작하시겠지만 AI 시스템의 차별을 방지하기 위해서는 학습 데이터의 준비 단계부터 관리가 필요합니다. 하지만, 이런 관리를 하였음에도 불구하고 차별이 발생하는 경우가 있어 완벽하게 차별을 막는 것은 어려운 문제입니다. [그림 3]은 데이터 준비 단계부터 알고리즘 개발 단계까지 이해관계자에 의해서 편향이 발생함으로써 결괏값도 불공평하게 출력되는 경우를 예시하고 있는데요, AI 시스템을 공정하게 만들기 위해서는 시스템을 기획하고 설계하는 단계에서부터 운영하는 단계까지 전체 라이프사이클에 거쳐 잠재적 위험을 지속 모니터링할 필요가 있습니다. 각 단계에서 주의해야 할 핵심적인 사항을 중심으로 아래에 설명해 드리고자 합니다7.
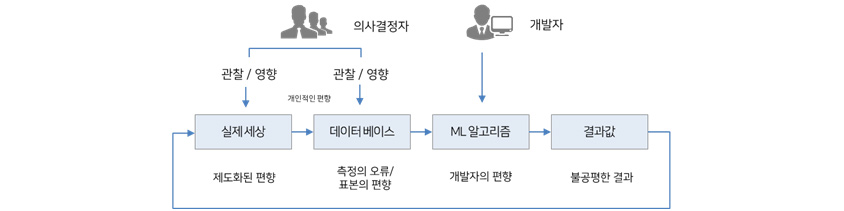 [그림 3] 머신러닝의 불공정 원인5
[그림 3] 머신러닝의 불공정 원인5
(1) AI 시스템 기획 및 설계 단계
AI 시스템의 필요성을 검토하는 기획 단계에서부터 이 시스템이 차별을 유발할 수 있는지 판단해야 합니다. 개와 고양이를 구분하는 AI와 같이 의사결정의 대상이 개인이나 개인이 속한 집단과 관련된 것이 아니라면 차별이 있다고 보기 어렵습니다. 공정성은 윤리의 영역으로 대상이 사람에 관한 것이기 때문입니다. 다만, 사람으로 간주하는 법인, 그것도 1인 기업의 경우에도 공정성 논란은 생길 수 있습니다.
보호 변수의 설정
사람에 대한 판단을 수행하는 AI 시스템이라면 사회적으로 사람의 어떠한 속성에 의해서 차별이 발생하는지 알아야 합니다. 인종, 성별, 연령, 지역, 학력, 재산 등이 우리가 익히 알고 있는 속성입니다. 만약 이러한 속성으로 인해 명시적 차별이 발생한다면 이것이 바로 직접적 차별이 되는 것입니다. 직접적인 차별은 해당 속성을 AI 모델 개발에 사용하지 않는 방법으로 예방할 수 있습니다. 이것을 ‘입력 중심의 접근 방법’이라고 하고, 대상이 되는 속성을 보호 변수(Protected Attribute)7라고 합니다.
예를 들어, 시험 성적을 예측하는 AI 모델을 만들면서 학생의 인종이나 사회 경제적 배경과 같은 속성은 보호 변수로 설정하여 AI 모델 학습 시 이러한 데이터를 사용하지 않도록 할 수 있습니다. 보호 변수를 지정하는 것은 특정 속성을 가진 집단에 대한 직접적인 차별을 줄여서 공정한 AI 시스템을 개발하는 데 도움을 줍니다. 이러한 사실을 공개함으로써 사용자를 안심시킬 수 있는 부대 효과도 있을 것입니다.
데이터 수집 편향 방지
데이터 수집 대상에 대해 수집담당자가 가지고 있는 의식적이거나 무의식적 편향으로 인해 수집된 데이터의 편향이 발생할 수 있습니다. 이를 예방하기 위해서는 샘플링 기준과 검수 기준을 수립하여 수집담당자가 자의적인 기준을 적용하는 것을 방지하고 수집된 데이터의 편향이 있더라도 검수 기준을 수립하여 검수 단계에서 편향을 바로잡도록 해야 합니다. 또한 수집이나 검수하는 사람도 다양성을 가지도록 충분한 인원을 배정하는 것이 필요합니다. 이와 같이 데이터 수집의 편향을 예방하기 위한 방안이 기획 단계부터 고려되어야 합니다.
(2) 데이터 학습 및 모델링 단계
AI 시스템이 다른 애플리케이션 시스템 개발과 다른 점은 데이터를 학습하여 패턴을 찾아내는 모델링 과정이 있다는 점입니다. 따라서 AI 시스템의 공정성은 편향된 데이터에 크게 기인합니다. 그래서 AI 시스템 기획 및 설계 단계에서 데이터 수집 편향을 방지했습니다. 실제 데이터 학습이 진행되는 모델링 단계에서는 라벨링의 편향이 없어야 하고 모델링 과정에 발견되는 편향의 완화가 필요합니다. 이에 대해서 살펴보겠습니다.
라벨링 편향 방지
AI 알고리즘 중에는 클러스터링과 같이 정답 데이터를 별도로 학습하지 않아도 되거나(비지도학습), 최근의 일부 딥러닝 모델처럼 스스로 정답을 찾아내는 기술(자기지도학습)도 발전하고 있지만, 대부분의 AI 모델들은 주어진 정답 데이터를 학습해서(지도학습) 모델이 만들어집니다. 사전에 학습 데이터에 정답과 오답을 표기하는 작업을 라벨링이라고 합니다.
라벨링 작업 시 편향은 데이터를 수집할 때와 마찬가지로 작업자의 고의나 실수 또는 무의식적인 습관으로 인해서 발생할 수 있고 전문성 부족이나 작업 기준의 일관성 결여 등도 원인이 될 수 있습니다. 편향되어 라벨링된 데이터를 학습한 모델은 편향된 의사결정을 내리기 때문에 라벨링 작업자에 대한 교육, 상세한 검수 기준의 안내, 충분한 검수자를 확보하는 등의 편향 방지 방안이 필요합니다.
모델 편향 제거
AI 모델을 개발하는 과정에서 모델의 종류나 시스템의 목표에 따라 편향이 발생할 수 있습니다. 앞서 언급한 인종 또는 성에 따른 차별과 같은 경우가 있습니다. AI 모델은 데이터에 잠재된 편향을 학습하게 되고, 편향을 더욱 증폭시키기도 합니다. 따라서 모델 개발 과정에서도 편향을 제거하거나 완화하기 위한 기법을 적용해야 합니다.
AI 모델의 공정성이 주목받기 시작하면서 모델에 편향이 있는지를 판단하는 방법에 대해서 많은 논의가 있었습니다. 최근에 와서 연구자들이 대체적으로 합의하는 몇 가지 방법이 도출되었습니다. 그중에서 대표적인 방법인 Fairness Tree를 활용하는 방법을 아래에 소개합니다. 또한 Fairness Tree와 함께 다양한 공정성 지표를 적용하게 되는데, 공정성 지표는 혼동 행렬(Confusion Matrix)의 값을 응용하여 산출해 냅니다.
※ 혼동 행렬(Confusion Matrix)
혼동 행렬(Confusion Matrix)은 ML모델의 예측값과 실제값의 대비를 통해 성능을 분석합니다. TP(True Positive)는 실제값과 예측값이 모두 긍정인 경우, FP(False Positive)는 실제값이 부정인데 반해 예측값이 긍정인 경우, FN(False Negative)은 실제값이 긍정인데 반해 예측값이 부정인 경우, TN(True Negative)는 실제값과 예측값이 모두 부정인 경우를 의미합니다.
| 긍정 | 부정 | ||
|---|---|---|---|
| 예측값 | 긍정 | TP(True Positive) | FP(False Positive) |
| 부정 | FN(False Negative) | TN(True Negative) | |
[Fairness Tree]
지표를 사용해서 정량적으로 측정하는 것은 언제나 객관성과 신뢰성을 확보하는 데 도움이 됩니다. 공정성과 관련해서도 마찬가지입니다. 혼동 행렬로부터 산출되는 계산값을 활용하면 다양한 정량적 지표를 만들어 낼 수 있습니다. 이 중에서 어떤 지표를 어떤 경우에 사용해야 할까요? AI 모델이 적용되는 상황과 공정성의 가치 판단 기준에 따라 적합한 지표를 선택하기 위한 의사결정의 흐름을 [그림 4]와 같이 나뭇가지가 뻗어나가는 형태로 정리한 도구가 Fairness Tree입니다. 시카고 대학의 Center for Data Science and Public Policy에서 제안하였는데요, 혼동 행렬을 기반으로 하여 [표 2]와 같이 최종적으로 적용할 수 있는 지표와 계산 방법을 만들었습니다.
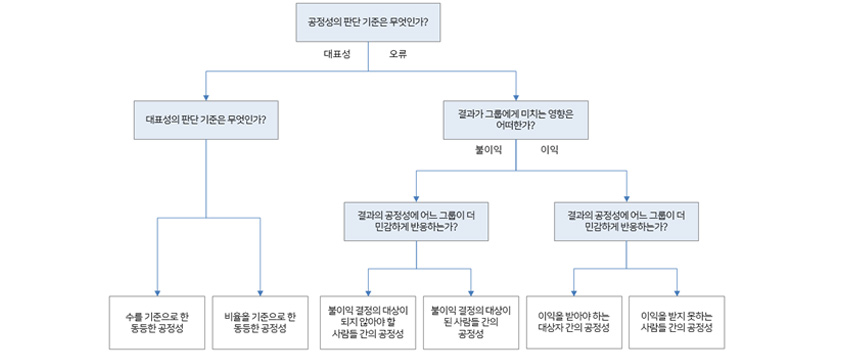 [그림 4] Fairness Tree 구조8
[그림 4] Fairness Tree 구조8
Fairness Tree 활용의 첫 단추는 공정성의 판단 기준을 무엇으로 할 것인가에 대한 의사결정입니다. AI 모델을 활용하는 목적상 대표성이 중요하다고 판단하였다면 [그림 4]와 같이 Tree의 꼭대기에서 좌측으로 내려가고 대표성의 판단 기준을 비교하는 집단 간에 추출된 수(Number)를 공평하게 할 것인지 아니면 비율(Proportion)을 공평하게 해야 하는지를 놓고 다음 의사결정을 내리게 됩니다.
AI 모델을 활용하는 목적상 보호해야 할 집단에 대한 AI 모델의 성능의 중요하다고 판단하였다면 Tree의 꼭대기에서 우측으로 분기됩니다. 여기서는 다시 AI 모델의 결과로써 집단 이익을 받는지 불이익을 받는 것인지를 생각해서 Tree에서 좌우 분기가 일어납니다. 최종적으로 공정성에 대해 어떤 집단이 더 민감하게 반응하는지를 판단하여 어떤 지표를 선택할지 결정하게 됩니다.
| 지표 | 비교 방법 | 지표 계산식 |
|---|---|---|
| 수를 기준으로 한 동등한 공정성 | 전체 집단의 긍정으로 예측한 수 중 비교 대상 집단(집단 A와 집단 B라고 가정, 이하 동일)이 긍정으로 예측한 건의 비율 | Selected Number(Equal)= TP + FP / (전체 집단의 TP+FP) |
| 비율을 기준으로 한 동등한 공정성 | 비교 대상 집단에 속한 대상 건 중 긍정으로 예측된 수가 집단 전체 중에서 차지하는 비율 | Selected Proportion= (TP + FP) / (TP + FP + TN + FN) |
| 불이익 결정의 대상이 되지 않아야 할 사람들 간의 공정성 | 비교 대상 집단에서 불이익 대상자로 잘못 분류된 대상과 불이익 대상자가 아닌 것으로 잘 분류된 대상의 합계 중, 불이익 대상으로 잘못 분류된 비율 | FPR (False Positive Rate)= (1 - Specificity)= FP / (FP + TN) |
| 불이익 결정의 대상이 된 사람들 간의 공정성 | 비교 대상 집단에서 불이익 대상자로 잘못 분류된 대상과 불이익 대상자로 잘 분류된 대상의 합계 중, 불이익 대상으로 잘못 분류된 비율 | FDR (False Discovery Rate)= (1 - Precision)= FP / (FP + TP) |
| 이익을 받아야 하는 대상자 간의 공정성 | 비교 대상 집단에서 이익 대상이 아닌 것으로 잘못 분류된 대상과 이익 대상자로 잘 분류된 대상의 합계 중, 이익 대상이 아닌 것으로 잘못 분류된 비율 | FNR (False Negative Rate)= (1 - Recall)= FN / (FN + TP) |
| 이익을 받지 못하는 사람들 간의 공정성 | 비교 대상 집단에서 이익 대상이 아닌 것으로 잘못 분류된 대상과 이익 대상자가 아닌 것으로 잘 분류된 대상의 합계 중, 이익 대상이 아닌 것으로 잘못 분류된 비율 | FOR (False Omission Rate)= FN / (FN + TN) |
(3) AI 시스템 구현 단계
AI 모델을 제품이나 서비스에 연계시키기 위해서는 별도 또는 추가적인 애플리케이션 개발을 통해 완전한 AI 시스템을 구현하게 됩니다. 이 과정에서 AI 시스템의 설계자나 개발자가 가지고 있는 편견이나 지식으로 인해 AI 시스템의 편향이 발생할 수 있습니다. 따라서 시스템 구현단계에서 개발자의 임의적인 판단으로 발생 가능한 편향을 식별하고 차별이 발생하지 않도록 다음과 같은 예방 방안을 고려할 수 있습니다.
소스 코드 편향 제거
전문가 지식을 표현하는 규칙 기반 시스템을 구현하는 경우나 (규칙 기반 시스템은 광의의 AI 시스템에 포함됩니다.) AI 모델을 통해 산출된 결과를 사용자가 보기 쉽게 편집하는 추가 개발이 발생할 수 있습니다. 이와 같은 최종 시스템 구현 과정에서 전문가 또는 개발자의 판단에 의해 특정한 분류나 예측 결과를 편집해서 보여주게 되는 개발자 인지 편향이 나타날 수 있습니다. 이에 대비하여 다수의 전문가를 최종검수자로 참여시키거나 개발자 임의로 결과를 편집하지 않는 가이드라인의 제공이 필요합니다.
사용자 인터페이스 편향 제거
사용자 인터페이스 측면에서도 순위 편향 등이 발생하지 않는지 확인해야 합니다. 순위 편향은 보여지는 정보의 순서에 따라 발생하는 편향입니다. AI 시스템의 사용자는 최상위 결과에 대해 가장 관련성이 높다고 생각하는 경향이 있기 때문에, 상위 노출 결과의 선택 빈도가 높을 수 있습니다. 이를 방지하기 위해 순위 편향이 발생할 수 있는 사용자 인터페이스에 대해 설계 단계부터 고려가 필요하지만 미처 고려하지 못했던 세부적인 표현의 차이가 나타날 있으므로 시스템 구현 단계에 확인하고 검수해야 합니다.
AI 개발의 공정성을 검증하는 도구와 사례
AI 기술의 우위와 이를 통한 서비스 차별화를 핵심 경쟁력으로 내세우고 있는 글로벌 빅테크 기업들은 최근 들어AI서비스와 상품이 개발 단계에서부터 공정성을 확보할 수 있도록 사전에 점검할 수 있는 진단 도구를 개발하고 활용하기 시작했습니다. Google, Microsoft, IBM을 비롯한 몇몇 기업들은 자사 연구원들이 개발한 공정성 평가 도구를 오픈소스로도 배포하였습니다.
현재까지 공개된 대표적인 오픈소스 기반의 공정성 평가 도구들은 공정성에 대한 오픈 커뮤니티(기업연구소나 대학 등)에서 발표하는 알고리즘과 방법들을 수용하면서, 기업 내부의AI 개발자들이 실제 활용하면서 지속적으로 개선된 버전도 공개함으로써 공정성의 문제를 기술적으로 해결하는데 기여하고 있습니다. 아래에서 대표적인 공정성 평가 도구의 개요와 주요 기능을 살펴보고 우리가 활용해 볼 수 있는 시사점이 있는지 알아보겠습니다.
IBM – AI Fairness 360
IBM은 신뢰할 수 있는 AI 시스템의 개발을 위해 공정성, 설명 가능성, 투명성 등 주목할 만한 연구를 발표하고 AI 모델의 공정성을 검증할 수 있는 도구를 개발하여 공개하였습니다. 오픈소스 기반 공정성 평가 도구인 AI Fairness 360은 2018년 9월 최초 릴리즈 이후 수차례 업데이트되었습니다10.
AI Fairness 360은 공정성을 측정하고 편향성을 완화하기 위해 70개 이상의 공정성 지표와 11개의 편향 완화 알고리즘을 제공합니다. 지표는 일반적인 성능 지표 외에 그룹 공정성, 개인 공정성 지표가 있습니다. 편향에 대한 체크뿐 아니라 완화 알고리즘 기능에 중점을 두고 있어 AI 모델을 개발하기 위한 데이터 전처리 단계, 모델링 단계, 모델링 사후 단계별로 선택해서 사용할 수 있습니다.
또한, 공정성의 검증에 생소한 AI 개발자도 쉽게 따라 할 수 있는 데모를 제공하고 있습니다. 개발자는 데모에서 공정성을 평가하는 방법을 경험해 볼 수가 있는데, 데이터 선택, 지표 선택, 편향 완화 알고리즘 선택, 비교 분석 4단계로 이루어집니다. 개발자의 이해를 돕기 위해 기본적인 시각화 기능이 제공되므로 별도의 시각화 도구를 추가하지 않고도 간편하게 이해할 수 있다는 장점도 있습니다.
[그림 5]는 소비자의 수입을 예측하는 AI 모델 개발에 대해 공정성 평가를 하는 데모 화면입니다. 차별을 금지해야 할 속성인 ‘인종’을 보호 변수로 설정하였습니다. 비교 집단에 대해 AI Fairness 360이 제공하는 5개의 지표를 통해 검증하고 있습니다. Statistical Parity Difference와 Disparate Impact 지표의 경우 편향이 발생했다는 것을 그래프상에서 시각적으로 확인할 수 있습니다.
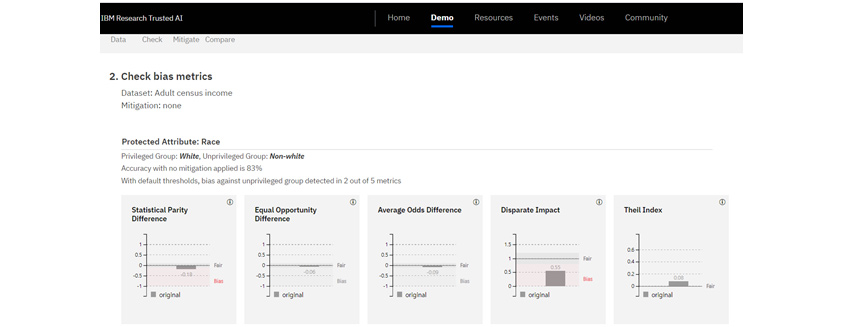 [그림 5] AI Fairness 3609
[그림 5] AI Fairness 3609
Google – Fairness Indicator & What-If Toolkit
Google의 오픈소스 기반 공정성 검증 도구는 2019년부터 공개된 Fairness Indicator10 와 What-If Toolkit(이하 WIT)11 Tensorflow 패키지입니다. YouTube와 같이 AI 시스템을 활용하는 서비스에서 공정성 이슈가 발생하지 않도록 Google의 AI 개발자들도 활용하고 있습니다.
Fairness Indicator는 AI 모델 성능을 비교하는 기능과 관련하여 공정성 지표를 제공하고 있습니다. WIT는 AI 모델 개발자가 확인하고 싶은 공정성 지표를 도표와 차트를 통해 시각적으로 제시하여 이해와 선택을 용이하게 합니다. 특히, 여기서 제공하는 Data point의 조작 기능은 특정 데이터 속성값을 조작한 이후에 공정성 지푯값은 얼마나 민감하게 변화하는지 시뮬레이션해 봄으로써 개발자의 직관적 이해를 제고할 수 있습니다.
[그림 6]은 Fairness Indicator의 예시 화면입니다. 좌측 패널에서는 공정성 측정과 관련된 지표 중 개발자가 원하는 지표를 선택할 수 있고, 우측 패널에서는 전체 분석 대상자 전체 그룹의 평균을 의미하는 초록색 막대와 비교 대상 개발 그룹에 해당하는 주황색 막대 간의 지표 비교가 가능합니다. 좌측 패널에 있는 지표를 복합적으로 선택하여 다각적인 비교 분석도 가능합니다.
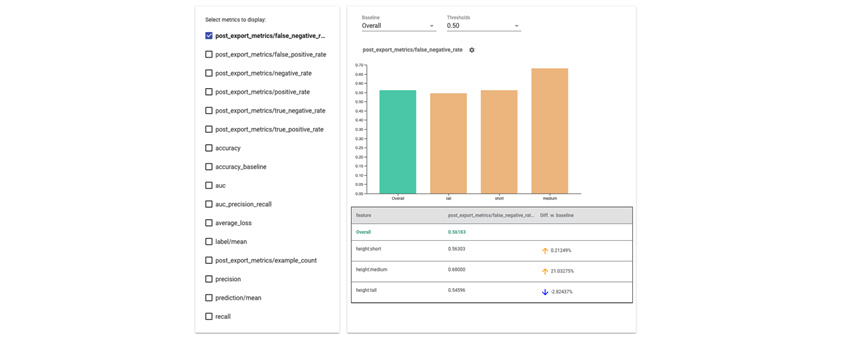 [그림 6] Fairness Indicator12
[그림 6] Fairness Indicator12
Microsoft - Fairlearn
Microsoft는 2020년에 Fairlearn이라는 공정성 검증 도구를 발표했습니다. Fairlearn은 공정성 지표와 완화 알고리즘 두 가지로 구성됩니다. AI 모델의 공정성을 검증하면서 지표를 수정하여 새롭게 정의할 수 있는 기능이 특징적이며 완화 알고리즘도 6개를 제공하여 활용할 수 있습니다. 또한 파이썬 라이브러리가 제공하는 기능을 활용하여 기본적인 시각화 기능을 제공하고 있습니다. Microsoft의 Azure 클라우드를 이용하는 경우 대시보드 기능을 활용할 수 있습니다.
[그림 7]은Fairlearn을 활용한 공정성 검증 예시 화면입니다. 차별이 금지되어야 하는 ‘인종’을 보호 변수로 설정하고 인종 그룹에 대한 AI 모델의 예측 정확도(Accuracy)를 비교하고 있습니다. 예측 오류를 과소 예측(Under-prediction)과 과대 예측(Over-prediction)으로 각각 구분해서 비교를 하고 있다는 점은 다른 도구와 다른 특징입니다. 즉, Amer-Indian-Eskimo의 그룹을 보면 과소 예측은 실제값이 1인데 0으로 예측한 경우(1종 오류) 이고 과대 예측은 실제값이 0인데 1로 예측하여(2종 오류)로 1종 오류가 더 많이 발생했다는 것을 알 수 있습니다.
개발자는 공정한 AI 모델을 개발하면서 AI 모델의 예측 오류 발생 시 어떤 유형의 오류가 공정성의 측면에서 사회적 비용을 줄일 것인지 감안하여 적합한 모델을 선정할 수 있습니다. 물론 이에 대한 기준은 개발자에게 일임하는 것은 아니고 최초 AI 시스템을 기획·설계하는 단계에서 정해져야 합니다.
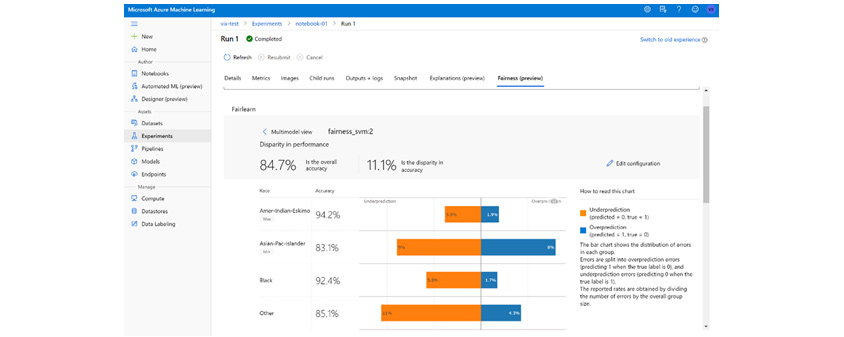 [그림 7] Fairlearn13
[그림 7] Fairlearn13
이번 장에서는 오픈소스 기반의 AI 공정성 검증 도구들을 비교해 보았습니다. IBM, Google, Microsoft가 공개한 AI 공정성 검증 도구들은 나름의 강점과 특징을 가지고 있는 것을 확인할 수 있었습니다. Fairness 360은 가장 많은 공정성 관련 지표와 완화 알고리즘을 내재하여 개발자가 참고할 수 있도록 지표의 다양성에 강점이 있었습니다. Fairness Indicator는 AI 모델 비교를 통해 편향성이 완화된 AI 모델을 선택하는 데 편리합니다. What-If-Tool은 시각화 기능을 가지고 Data Point를 실시간으로 변경해 봄으로써 빠르게 인사이트를 제공하는 장점이 있었습니다. Fairlearn은 공정성 지표를 커스터마이징할 수 있는 기능도 있습니다.
어떤 도구를 사용할지는 AI 시스템이 지향하는 서비스의 내용과 기업의 공정성 전략 그리고 AI 모델을 개발하는 개발자가 검증하고자 하는 목적에 따라 선택할 수 있습니다. 그렇지만 하나의 도구를 선택하는 것보다 여러 도구를 활용해서 효과적인 편향 분석 및 해결을 수행하는 것을 권장합니다. 공정성 검증 도구는 앞으로 더 큰 개선이 기대되고 있으므로 최신 정보를 확인하는 것도 필요합니다.
인간과 더 공존하는 AI를 생각하며
생성형 AI의 등장과 더불어 AI 기술의 활용이 비약적으로 증가하고 범위가 확산하면서, 그 안전성에 대해 전 세계적으로 관심과 우려도 확산하고 있습니다. 종래에는 공정성이라는 윤리적 판단이 사람에게 요구되었지만, AI가 사람의 판단을 대체하는 경우가 많아지고 AI의 판단이 사람의 판단과 구분이 어렵게 되면서 AI가 공정한 판단을 할 수 있도록 규제해야 한다는 요청이 늘어나고 있습니다.
사람의 의사결정은 복잡한 상황과 사건의 맥락, 그것을 둘러싼 개개인의 감정에 따라 객관적이고 일관적이지 않게 판단을 내리거나 판단의 오류를 범할 수 있습니다. 그에 비하면 AI의 의사결정은 매우 신속하고 일관적인 판단을 내릴 수 있는 장점이 있지만 오류가 발생하는 경우에는 범위가 넓고 책임 소재는 모호합니다. 따라서 AI의 공정성은 인간의 판단으로 인해 발생하는 공정성 이슈와 대비하여 위험성이 적지 않습니다.
생성형 AI의 활용이 증가하고 일상화될 것으로 전망되고 있어, AI가 어떻게 판단을 내렸는지 파악하고자 하는 투명성에 대한 관심도 증가하였습니다. 그러나, 어떤 데이터를 학습해서 얼마나 공정하고 합리적인 판단을 내렸는지를 추적하고 감시하는 것은 비교적 작동 원리가 간단했던 전통적 AI와 비교하면 한층 어려워졌습니다.
공정성의 개념에 대해 차별을 금지하는 것이라고 쉽게 설명할 수는 있지만 실생활에서 이해관계를 두고 공정성을 따지는 경우에는 사회적으로나 법률적으로도 판단을 내리기 쉽지 않습니다. 공정성은 사회적 맥락을 고려할 수밖에 없는데 과거에는 공정하다고 용인하던 것도 지금은 이의가 제기될 수 있으며, 따라서 과거의 데이터로 학습된 AI 모델로 불공정 AI 서비스가 제공될 수 있는 것입니다.
이러한 배경하에 우리는 공정성에 대한 이해와 AI 공정성의 문제 발생 상황, 그리고 이를 예방하는 방법과 활용할 수 있는 도구에 대해 살펴보았습니다. 기업의 경우 제품이나 서비스의 유형에 따라 차별화된 AI 공정성 전략을 수립하고 이를 빠르게 검증할 수 있는 기준과 도구가 필요할 것입니다. 이런 도구들은 MLOps나 AIOps와 같은 AI 개발의 자동화를 지원하는 플랫폼과 연계해서 사용하는 것이 효율적일 것으로 생각합니다.
공정성의 확보를 위한 기술의 개발은 완성 단계가 아니고, 기술의 발전과는 별개로 이러한 기술을 활용하는 AI 서비스의 기획자나 개발자들의 편견을 예방하기 위한 노력도 병행해야 합니다. 공정한 AI 개발을 통해 더 인간과 가깝게 공존할 수 있는 AI로 성장하기를 기대합니다.
References
1. Jeffrey Dastin. (2018, October 7). Amazon scraps secret AI recruiting tool that showed bias against women. Reuters. https://www.reuters.com/article/us-amazon-com-jobs-automation-insight-idUSKCN1MK08G
2. Leonardo Nicoletti and Dina Bass. (2023). HUMANS ARE BIASED. GENERATIVE AI IS EVEN WORSE. Bloomberg. https://www.bloomberg.com/graphics/2023-generative-ai-bias/
3. OECD. (2023). G7 Hiroshima Process on Generative Artificial Intelligence (AI): Towards a G7 Common Understanding on Generative AI. OECD Publishing. https://doi.org/10.1787/bf3c0c60-en
4. Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K., & Galstyan, A. (2021). A survey on bias and fairness in machine learning. ACM computing surveys (CSUR), 54(6), 1-35.
5. 고학수. (2022). 『AI는 차별을 인간에게서 배운다 : 인간과 기술의 공존을 위해 다시 세우는 정의』. 21세기북스
6. Mehrabi, N., Morstatter, F., Saxena, N., Lerman, K., & Galstyan, A. (2021). A survey on bias and fairness in machine learning. ACM computing surveys (CSUR), 54(6), 1-35.
7. Tao Zhang. (2022). Privacy vs. Protected Attributes: The Interconnected Opposite Forces that Underpin Fairness. https://medium.com/seek-blog/privacy-vs-protected-attributes-the-interconnected-opposite-forces-that-underpin-fairness-179d637aeb1c
8. Data Science Public Policy. (2018). Aequitas. http://www.datasciencepublicpolicy.org/our-work/tools-guides/aequitas/
9.AI Fairness 360 (AIF360). (n.d.). https://aif360.res.ibm.com/
10. Fairness Indicators. (n.d.). https://github.com/tensorflow/fairness-indicators
11. Wexler, J., Pushkarna, M., Bolukbasi, T., Wattenberg, M., Viégas, F., & Wilson, J. (2019). The what-if tool: Interactive probing of machine learning models. IEEE transactions on visualization and computer graphics, 26(1), 56-65.
12. Fairness Indicators. (n.d.). https://github.com/tensorflow/fairness-indicators
13. Azure Machine Learning studio. (2020). https://techcommunity.microsoft.com/t5/ai-machine-learning-blog/azure-machine-learning-studio-a-web-interface-for-managing-the/ba-p/1521780
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

이재호 | 삼성 SDS 금융컨설팅팀
첨단 기술의 활용이 기업과 사회에 미치는 영향에 대해서 연구하고 있습니다. 세상을 더 나은 방향으로 만들기 위해 항시 노력하는 금융·서비스 고객사와 함께 혁신 과제 수립과 실행에 IT 컨설턴트로 참여하고 있습니다.
조남용 | 삼성SDS 금융컨설팅팀
기업 고객 대상으로 AI, Digital Transformation 컨설팅을 담당하고 있습니다. 신뢰할 수 있는 AI 시스템을 개발하고 운영할 수 있는 환경을 조성하여 사용자와 오래 공존하는 유비쿼터스 AI 세상을 실현하고자 합니다.