

인터넷이 발달함에 따라 정보 공유가 활발해지고 데이터의 양이 증가하고 있습니다.
이러한 데이터는 누구나 손쉽게 접근할 수 있는 뉴스 기사, 블로그, 웹 문서 등이 해당됩니다. 이뿐만 아니라 일반인이 다룰 수 없는, 전문적으로 다뤄지는 문서들도 분야 별로 내부 시스템에 쌓여가는데, 이를 소위 ‘전문가용 문서’라고 지칭합니다. 예로 법률, 의료, 제조, IT 등의 분야에서 생성되고 축적되는 문서들이죠.
그렇다면 이러한 문서들을 어떤 목적을 위해, 어떤 통찰(insight)을 얻기 위해 사람의 손으로 직접분석한다면 어떨까요? 분명 한정된 시간 안에 분석되는 양이 턱없이 부족할 뿐만 아니라, 분석 결과에도 오류가 생길 수 있겠죠.
따라서 이번 아티클에서는 AI 신기술 기반의 전문가용 문서 분석과 그 사례를 살펴보겠습니다.

AI 기반의 Text Analytics(텍스트 분석) 활용
먼저 문서 분석은 AI 기반의 Text Analytics(텍스트 분석) 분야에서 쓰이는 방법들을 활용할 수 있습니다. Text Analytics 분야에서는 그 목적에 따라 분석하는 방법들이 여러 가지가 있습니다.
분류(classification), 군집화(clustering), 감성 분석(sentiment analysis), 트렌드 분석(trend analysis), 연관어 분석(association rule mining) 등이 이에 해당됩니다.
그럼 분석 방법마다 특징들을 살펴보도록 하죠.
분류
‘분류’란 주어진 여러 문서에 대해 미리 정해진 카테고리 값으로 분류하는 것입니다. 예를 들어, 뉴스 문서가 주어졌을 경우 각 문서의 내용을 기반으로 특정 카테고리(스포츠, 경제, 정치 등)로 분류합니다. 이는 학습 과정을 통해 ‘A 문서는 경제 문서야!’ 라고 알고리즘에게 알려주는 과정이 필요하죠.
군집화
‘군집화’는 여러 문서가 주어졌을 때 비슷한 주제의 문서끼리 그룹핑을 하는 것입니다. 분류가 학습 과정을 통해 문서를 분류하는 supervised learning(지도 학습)에 해당된다면, 군집화는 학습 과정 없이 바로 유사 문서끼리 그룹핑을 하는 unsupervised learning(비지도 학습/자율 학습)에 해당됩니다.
감성 분석
감성 분석은 문서 또는 텍스트로부터 기본적으로 ‘긍정’, ‘부정’, ‘중립’의 감성을 추출하는 방법입니다. 감성 분석의 방법은 문서 단위로 할 것이냐, 문서에 포함된 개체 단위로 할 것이냐에 따라 달라집니다. 문서 단위는 문서 그 자체에서 감성을 추출하는 방법이고, 개체 단위의 분석 방법은 문서에 포함된 개체를 찾아, 개체 단위로 감성을 추출하는 방법이죠. 예를 들어 “제품은 좋은데, 포장 상태가 불량이네요!” 라는 문장에서는 ‘제품’과 ‘포장 상태’가 개체명입니다. 각 개체 별로 감성을 분석하면 ‘제품’은 긍정이고 ‘포장 상태’는 부정이 됩니다.
트렌드 분석
트렌드 분석은 어떤 주제(제품, 이슈, 인물 등)에 대해 단어 또는 구문 단위로 어떤 변화가 있는지 분석하는 방법입니다. 실시간으로 데이터가 게재되는 소셜네트워크서비스(SNS)로부터 데이터를 수집하여 분석합니다.
연관어 분석
마지막으로 연관어 분석은 같이 출현하는 단어 간의 관계를 분석합니다. 예를 들어, ‘A단어가 출현하면 B단어도 같이 출현하더라’ 라는 분석을 통해 단어 간의 연관성을 찾아내는 방법이죠.
지금까지 살펴본 분석 방법들은 텍스트 문서를 다루기 때문에 이전 단계에서 형태소 분석, 구문 분석, 개체명 인식 등 자연어처리(Natural Language Processing) 쪽의 도움을 받아야 합니다.
‘분류’방법을 통한 전문가용 문서 분류
본 아티클에서는 다양한 문서 분석 방법 중 ‘분류’ 방법을 통한 전문가용 문서의 분류에 대해 더 자세히 알아보겠습니다. 앞서 살펴본 바와 같이 ‘분류’는 [그림1]처럼 문서 집합이 주어졌을 때, 학습 과정에서 미리 정의된 카테고리(스포츠, 정치, 경제 등)로 분류하는 것입니다.
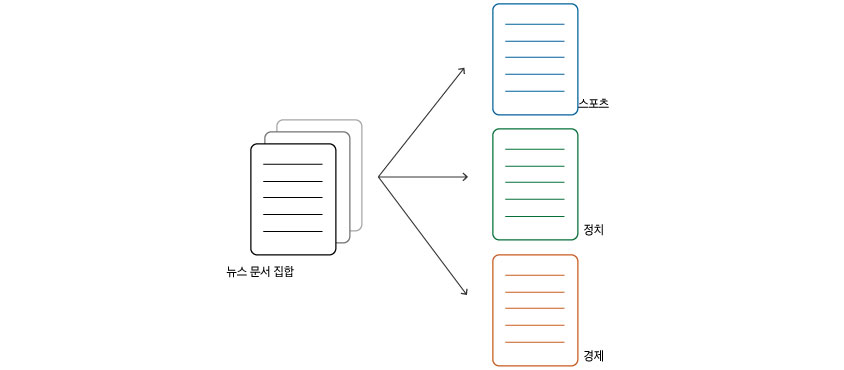 [그림1 - 분류의 개념]
[그림1 - 분류의 개념]
문서 분류의 절차는 [그림2]를 확인하시면 이해하기 쉽습니다.
그럼 분류 과정을 좀 더 자세히 살펴볼까요?
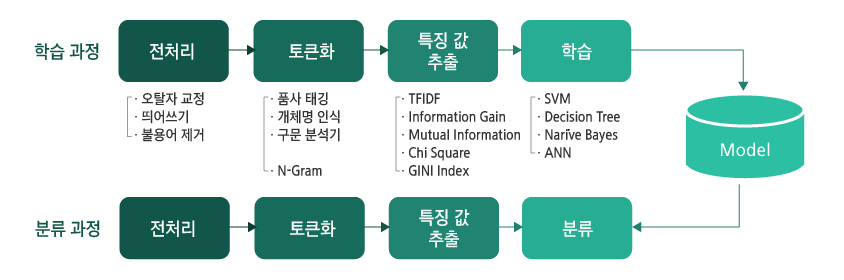 [그림2 - 문서 분류의 절차]
[그림2 - 문서 분류의 절차]
문서 ‘분류’의 절차
① 전처리
정확한 문서 분류를 위해서는 궁극적으로 ‘중요한 특징 값’을 선택하는 것이 중요합니다.
여기서 ‘중요한 특징 값’이란 학습 알고리즘으로, 입력 데이터로 사용되어 학습이 이루어집니다. 중요한 특징 값을 선택하기 위해서는 전처리 단계에서 언어적으로 잘못된 부분을 교정(오탈자 및 띄어쓰기 교정, 불용어 제거 등) 해야 합니다.
② 토큰화
그 후에 단어 단위로 나누는 토큰화(tokenization) 과정을 거치는데, 이 과정에서는 단어를 어떻게 나눌 것인지 결정하게 됩니다. 예로 단순히 공백 단위로 나눌지, 형태소 분석기를 사용해서 명사(noun)에 해당하는 단어만 추출할지 등을 결정할 수 있죠. 그리고 이는 도메인에 따라 다른 방법들을 사용해야 합니다. 예를 들어 감성 분석을 한다고 하면, 감성을 나타내는 품사가 동사, 형용사 쪽에 가깝기 때문에 형태소 분석기를 사용한다면 명사가 아닌 형용사, 동사의 품사를 지닌 단어를 추출하게 될 수도 있습니다.
③ 특징 값 추출
그 다음으로 특징 값을 추출하는 과정을 거치는데, 이 과정은 ‘중요한 단어’를 선별하는 과정이라고 할 수 있습니다. 여기서 ‘중요한 단어’로서의 특징은 적은 수의 카테고리에 분포되어 있어야 하고, 카테고리 내에서도 빈번하게 출현해야 합니다. 또한 특정 텍스트를 통해 카테고리를 구분 짓는 것이기 때문에 어떤 단어가 모든 카테고리에 분포되어 있다면 이는 차별성이 없는 단어입니다. 따라서 중요한 단어 선별 과정에서 제외되죠.
④ 분류
이렇게 추출된 ‘중요한 단어’는 학습/분류를 위한 특징 값이 되어 기존에 알려져 있는 학습 알고리즘에게 학습을 시키고 모델을 생성한 뒤에, 분류에 사용됩니다.
‘토큰화’ 과정에서의 분류
본 아티클에서는 문서 분류 절차의 각 단계를 세부적으로 살펴보지는 않습니다.
다만 Text Analytics(텍스트 분석)에서 자연어처리 쪽의 도움을 어떻게 받을 수 있는지 알아보기 위해, 토큰화 과정에서의 형태소 분석, 개체명 인식, 구문 분석, n-gram 조합을 살펴보고자 합니다.
먼저 [그림3]을 통해 각 방법의 예를 확인해보겠습니다.
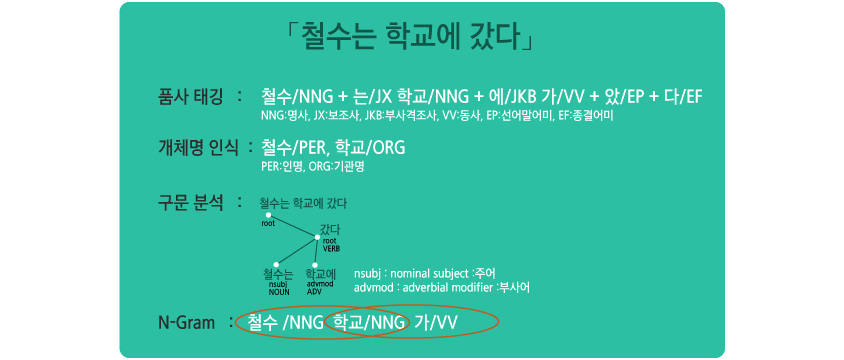 [그림3 - 토큰화의 예]
[그림3 - 토큰화의 예]
품사 태깅
품사 태깅은 형태소 분석기를 이용해서 형태소 단위로 품사를 태깅하는 것입니다. 이를 통해 주요 품사(명사, 동사, 형용사 등)가 아닌 것들은 제거하여 특징 값을 선택할 수 있습니다.
개체명 인식
개체명 인식은 인명, 기관명, 장소명 등을 태깅합니다. 이는 광범위하게 명사로 태깅하는 형태소 분석기와 달리, 세부적으로 개체명을 태깅하여 정밀하게 분석을 수행할 수 있죠.
구문 분석
의존 구문 분석은 주어진 텍스트로부터 주어, 동사, 목적어 등을 찾을 수 있고, 각 단어 간의 관계 또한 찾아낼 수 있습니다. 최우선적으로 동사를 찾아내고 동사를 중심으로 각 단어의 관계를 찾습니다. 예를 들어, [그림3]에서 ‘갔다’를 중심으로 ‘철수’는 주어이고, ‘학교에’는 부사어로 인식하는 것을 볼 수 있습니다.
N-gram
N-gram은 단어를 묶는 방법입니다. N-gram에는 uni-gram, bi-gram, tri-gram이 있는데 각각 하나, 둘, 세 단어 또는 음절씩 묶는 방법이 있습니다. 언어에서는 한 단어보다는 몇 단어씩 결합을 해야 보다 구체화 될 수 있습니다. 예를 들어, ‘하지 않았다’ 라는 문장에서 한 단어씩만 쪼갠다면, ‘하다’와 ‘않았다’의 상반된 의미의 두 단어가 됩니다. 그러나 두 단어씩 묶는다면 ‘하지 않았다’ 라는 본래의 부정적인 의미를 인식할 수 있게 되죠.

전문가용 문서 분류 사례
실험 1. 법률 계약 문서의 분류
이러한 분석 방법들을 통해 법률 계약 문서와 제조 현장에서 발생하는 문서를 대상으로 분류 실험을 해보았습니다. 법률 계약 문서로 하려고 했던 것은 kirasystems.com과 유사한 시스템을 만들기 위한 것으로, 세부적으로 분류 시스템이 적용되어야 했습니다.
계약 문서는 계약의 명칭과 조항 단위로 문서가 구성되는데, 이 때 조항 단위는 조항의 제목과 내용이 들어갑니다 예를 들어, ‘제 1조 목적’이 조항의 제목이 되는 것이죠. 그러나 계약서에 따라 조항의 의미는 같은데 조항의 제목을 다르게 쓰는 경우가 있습니다. 이럴 경우에는 내용을 분석해서 조항의 제목을 식별하는 게 필요합니다.
처음에는 조항에 포함된 전체 문장을 대상으로 학습을 하고 분류 실험을 해보았습니다. 결과적으로 만족할만한 성능을 보였지만, 잘못된 분류 사례를 분석해보니 성능을 개선시킬 방향이 보였습니다. 정리하면, 전체 문장보다는 ‘첫 번째 문장’을 대상으로 하는 것이 분류 성능을 높일 수 있었습니다. 조항 내용 중반에서 후반으로 갈수록 표현된 문장들이 다른 카테고리와 겹치는 부분이 있었기 때문에, 이를 사용하지 않기 위해 첫 번째 문장만 사용했기 때문입니다.
실험 2. 제조 문서의 분류
제조 현장에서 발생한 문서로 실험을 한 것은 문서의 내용을 기반으로 해당 문서가 보고서인지, 설계서인지를 분류하기 위해서였습니다.
문서에는 25개 이상의 세부적인 카테고리가 존재했습니다. 그리고 텍스트가 아닌 파워포인트, 엑셀, 워드 문서로 구성되어 한 파일 안에 여러 장의 문서로 구성됐습니다. 실험을 위해 텍스트 변환 도구로 Apache POI를 사용했습니다.
특징 값 추출은 전체 페이지를 대상으로 하지 않았습니다. 템플릿 형태로 구성된 문서라 목차, 제목, 부서명, 작성자 등과 같이 모든 문서마다 공통적으로 발생하는 부분은 앞의 한 두 페이지 정도였습니다. 따라서 한 두 페이지 내에서 특징 값을 추출하여 분류 실험을 수행했을 때 만족할 만한 성능을 보였습니다.
정리하면, 전통적인 기계학습 방법을 통해 문서 분류를 수행한다면 문서의 특성을 파악하는 것이 우선시되어야 합니다. 뉴스 문서를 분류한다면 본문만 볼 수도 있지만, 이메일을 분류한다면 본문 이외에 보낸 사람, 첨부 파일 등도 분석의 대상이 될 수도 있습니다. 그리고 문서의 특성이 파악된 뒤에는 [그림2]에 명시된 각 단계에서 어떤 방법을 사용해야 할지도 결정되어야 합니다.
사실 처음부터 정해진 방법은 없습니다. 그렇기에 실험을 통해 최적의 성능을 보이는 방법들의 조합을 찾아내는 것이 필요합니다.
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
- #TextAnalytics
- #Document
- #Classification
- #Artificial
- #Intelligence
- #AI
- #NaturalLanguage
- #Processing
- #자연어처리
- #삼성SDS
![]()

삼성SDS AI서비스기술Lab
텍스트마이닝, 감성분석 관련 박사학위를 가지고 있으며, 삼성SDS AI서비스기술Lab에서 텍스트 분석 업무를 담당하고 있습니다.