

본 아티클에서는 자율 주행 기술의 여러 단계와 컴퓨터 비전(Computer Vision)에 대해 자세히 살펴보겠습니다. 시맨틱 세그먼테이션(Semantic segmentation)이란 이미지를 구성하고 있는 픽셀들을 구별하는 기능입니다. 인스턴스 세그먼테이션 (Instance segmentation)은 고유의 객체 감지 기능이 추가된 시맨틱 세그먼테이션입니다.
인스턴스 세그먼테이션 (Instance Segmentation)
 [그림1] 인스턴스 세그먼테이션 시각 자료. 클래스(class) = "차량(car)"인 여러 인스턴스가 고유의 객체로 감지됨
[그림1] 인스턴스 세그먼테이션 시각 자료. 클래스(class) = "차량(car)"인 여러 인스턴스가 고유의 객체로 감지됨
컴퓨터 비전(Computer Vision)은 자율 주행 기술에서 매우 중요한 부분을 차지하고 있습니다. 한 장면에 등장하는 다양한 객체들을(예 : 자동차, 버스, 트럭, 사람, 신호등, 표지판) 인지하고 분류하는 어려운 기능을 수행해야 하기 때문이죠. 고유한 객체(예 : 사람 1, 사람 2, 자동차 1, 자동차 2)를 분류하고 추적하는 것은 어려운 일입니다. 객체를 현지화하고 분류해서 얻는 정보는 자율 주행의 다양한 단계에서 매우 유용하게 작용합니다. 자율 주행 시스템은 현장에서 여러 객체들을 이해하고(인스턴스 세그먼테이션), 각각의 위치를 파악해 최상의 경로를 찾습니다.
자율 주행(Autonomous Driving)
자율 주행은 [그림 2]의 단계로 구성됩니다.
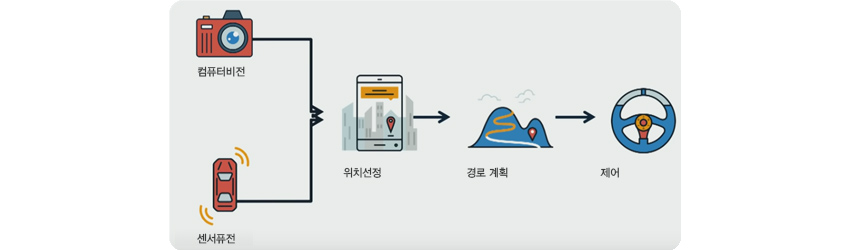 [그림2] 자율주행 단계
[그림2] 자율주행 단계
1) 인식(Perception)
먼저 환경을 정확히 이해해야 합니다. 자율 주행에서는 ‘인식(Perception)’이라고 부르죠.
인식은 다음과 같습니다.
- 컴퓨터 비전(Computer Vision): 자연 이미지는 매우 복잡하기 때문에 기존에는 이 기술을 구현하는 것이 굉장히 어려웠습니다. 그러나 최근 CNN(Convolutional Neural Networks)의 발전으로 이 분야는 상당한 진전을 보이고 있습니다.
- 센서 퓨전(Sensor Fusion): 시각 데이터를 보강하는 단계로, 다음과 같은 센서 데이터를 활용합니다.
- RADAR: 객체의 움직임에 따라 신호를 생성합니다. 하지만 객체를 분류할 수는 없습니다.
비용은 수백 달러에 달합니다. - LIDAR: 3D 포인트 클라우드를 생성합니다. 자율 주행의 다양한 단계에서 매우 유용하게 쓰이며, 비용은 수천 달러 수준입니다.
- 울트라 소닉 센서(Ultra-sonic Sensors): 광파 대신 음파를 사용해 객체 이동 신호를 생성합니다.
RADAR 만큼 안정적이지는 않지만 제조 비용이 저렴합니다.
인식 후에는 위치 선정(Localization), 경로 계획(Path Planning), 제어(Control) 단계가 이어집니다.
2) 위치 선정(Localization)
위치 선정 단계에서는 특정 환경 내 차량의 위치를 결정합니다. 고화질 지도를 사용해 SLAM(Simultaneous Localization And Mapping) 알고리즘을 기반으로 차량의 정확한 위치를 인식합니다.
3) 경로 계획(Path Planning)
경로 계획 단계에서는 다이내믹하게 변하는 환경에서 최상의 경로를 파악할 수 있습니다. 주변 객체와의 거리를 최대화할 수 있는 경로를 찾는 이 기능은 다양한 다중 모델(Multi-Model, MM) 알고리즘이 사용됩니다.
(예: 자율 다중 모델, GPB (Generalized Pseudo-Bayesian) 알고리즘)
4) 제어(Control)
마지막으로 제어 단계는 브레이크, 가속, 스티어링 등의 차량 제어를 통해 기계적인 조작을 실행합니다. 경로 계획대로 동작을 실행합니다.
딥러닝 기반의 컴퓨터 비전
Deep 이란 많은 CNN 레이어가 쌓여있는 것을 의미합니다. 실제로 네트워크가 깊어질수록 복잡한 환경을 이해할 수 있는 학습 능력이 더 높아지는 것이 증명됐습니다. 도시 운전과 같은 것 말이죠.
인스턴스 세그먼테이션 기술 (Instance Segmentation Techniques )
인스턴스 세그먼테이션은 여러 가지 방법으로 수행할 수 있습니다. 이 분야의 연구는 활발히 이루어지고 있는데, 가장 많이 사용되는 방법은 아래와 같습니다.
• Mask RCNN ( 링크 )
• 인스턴스 세그먼테이션을 위한 Path Aggregation Network (링크)
• 비국소적 신경망 (링크)
[그림3]에 나온 것처럼 Mask RCNN 논문에서는 모든 종류의 인스턴스(관심 영역 또는 "RoI")에 대해 세그먼테이션 마스크가 생성되는 아키텍처 예시를 설명합니다. 인스턴스의 세그먼테이션 마스크는 기본적으로 인스턴스에 해당하는 픽셀 위치에 1이 있고, 그렇지 않으면 0이 되는 바이너리 마스크입니다.
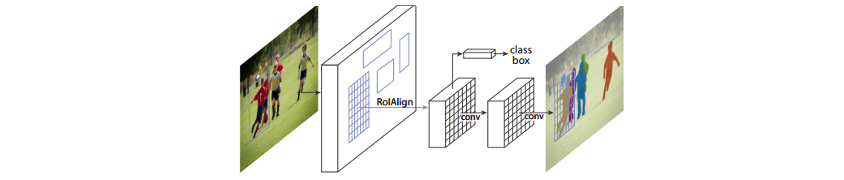 [그림3 ] 마스크 RCNN의 인스턴스 세그먼테이션 아키텍처
[그림3 ] 마스크 RCNN의 인스턴스 세그먼테이션 아키텍처
학습과정
흔히 사용되는 알고리즘(이 경우에는 신경망)은 감독 학습 기술이 적용됩니다. 즉, 훈련 시간 동안 네트워크에는 각 인스턴스에 대한 원본 이미지와 바이너리 마스크가 표시되죠. 예를 들어 (TensorFlow Object Detection API에서는 원본 이미지, 바이너리 마스크 목록, 해당 바운딩 박스(BBs) 목록, 그리고 해당 분류 ID 목록이 하나의 트레이닝 세트를 형성합니다. ([그림4] 참조)
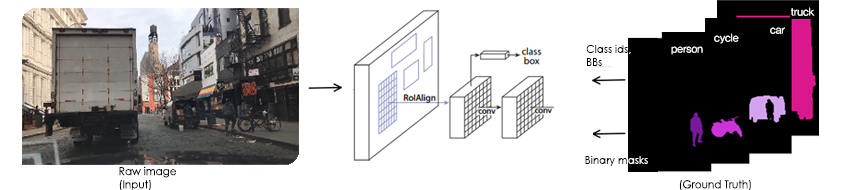 [그림4] 인스턴스 세그먼테이션 학습 과정
[그림4] 인스턴스 세그먼테이션 학습 과정
성공적인 학습 결과는 잘 훈련된 모델을 의미하며 특정 측정 항목으로 평가할 수 있습니다. 예를 들어, 인스턴스 세그먼테이션 작업의 경우 일반적으로 평균 정밀도(Average Precision, AP)를 측정하죠. 평균 정밀도는 정확성(Precision)과 재현율(Recall) 지표를 통합한 영역이며, 이는 바이너리 마스크 페어 (Ground Truth, Predicted Mask)에 대한 IoU(Intersection-Over-Union) 임계 값을 각기 다르게 해 구성할 수 있습니다. 다음은 TensorBoard에서 제시한 평가 측정 항목의 예입니다.
![Google의 시각화 도구인 TensorBoard에서 볼 수 있는 인스턴스 세그먼테이션의 성능 측정 항목 / validation_metrics/AP@0.6 & Precision at IOU CASE : 259.5.0k 0.722, 261.8k 0.7145, 263.0k 0.715, 264.5k 0.726, 266.5k 0.7217, 268.5k 0.7225, 269.5k 0.7245, 273.0k 0.7145 / validation_metrics/AP@0.75 & Precision at IOU=0.75 CASE : 259.5k 0.5825, 263.0k 0.560, 264.8k 0.571, 266.5k 0.572, 269.8k 0.588, 273.0k 0.561 / validation_metrics/AP@[0.50:0.95] & Average Precision at itegrated area between IOU=[0.5,0.95] CASE : 259.5k 0.511, 261.5k 0.508, 263.2k 0.5077, 264.5k 0.5145, 268.0k 0.517, 269.9k 0.516, 271.5k 0.518, 273.0k 0.5038](https://image.samsungsds.com/kr/insights/autodriving_img05.jpg?queryString=20260529094615) [그림5] Google의 시각화 도구인 TensorBoard에서 볼 수 있는 인스턴스 세그먼테이션의 성능 측정 항목
[그림5] Google의 시각화 도구인 TensorBoard에서 볼 수 있는 인스턴스 세그먼테이션의 성능 측정 항목
학습 과정을 성공적으로 마친 모델은 원본 이미지로 표시되고, 해당 이미지에는 클래스 레이블, 바운딩 박스 그리고 바이너리 마스크가 생성됩니다. 이때 각 ROI에 대한 마스크가 하나씩 생성됩니다. ([그림6] 참조)
![인스턴스 세그먼테이션 학습 예제 / Raw image(input) -> RolAlign -> conv ( 이 단계에서 class box 추출) -> conv -> [Predictions] (Class ids BBs, Binary masks)](https://image.samsungsds.com/kr/insights/autodriving_img06.jpg?queryString=20260529094615) [그림6] 인스턴스 세그먼테이션 학습 예제
[그림6] 인스턴스 세그먼테이션 학습 예제
다음 그림은 학습된 모델이 임의의 도시 운전 상황에서 인스턴스 세그먼테이션을 적용한 결과입니다.
왼쪽은 원본이미지이며, 오른쪽은 바이너리 마스크가 원본 이미지 위에 덮어씌워진 것을 확인 할 수 있습니다. 이때 모든 객체는 각각 다른 색상으로 표시되죠.
 [그림7] 인스턴스 세그먼테이션 학습 된 결과 예제
[그림7] 인스턴스 세그먼테이션 학습 된 결과 예제
Brightics Deep Learning (SBrain)
본 아티클에서는 ‘컴퓨터 비전’을 중심으로 자율 주행 수행 단계에 대해 논의했습니다. 컴퓨터 비전의 알고리즘 분야에 많은 노력이 들어가고 있지만, 거대하고 복잡한 네트워크를 교육하기 위해 필요한 장비 필요 사항 때문에 심층 콘볼루션 신경망(Deep Convolutional Neural Networks)을 훈련하는 것은 여전히 큰 과제로 남아 있습니다. 대부분의 고성능 네트워크 내에는 수 억에서 수십억 개의 매개 변수가 존재하죠. 이러한 매개 변수를 훈련하려면 엄청난 양의 컴퓨터 리소스가 필요합니다. 또한, 이러한 알고리즘 샘플이 지닌 복잡성 때문에 만족스러운 성능을 보장하려면 수백만 개의 이미지 순서에 따른 대량의 데이터가 필요합니다.
Brightics 딥러닝 플랫폼은 분산된 방식으로 인스턴스 세그먼테이션 교육을 수행할 수 있는 완벽한 도구입니다. 익숙한 Jupyter 환경으로 액세스할 수 있는 최상의 딥러닝 (Distributed Keras 및 Distributed Tensorflow)을 제공하며Docker, Kubernetes 및 Cluster 프로그래밍의 하위 레벨 프로그래밍이 필요하지 않습니다. 또한Spark 프로그래밍 지식 없이도 Apache Spark 기술을 사용하는 기본 클러스터에서 센서 퓨전과 같은 작업을 수행할 수 있습니다.
Brightics 딥러닝 플랫폼은 AI 거버넌스, GPU 통합, 분산 데이터 변환, Hyper-Parameter 검색을 통해 자동 실험뿐만 아니라 Data Scientist에게 익숙한 Jupyter 노트북 환경에서 분산 추론을 제공합니다.
* 이미지 출처
[그림1] https://bdd-data.berkeley.edu/
[그림3] https://arxiv.org/abs/1703.06870
[그림4] https://bdd-data.berkeley.edu/
[그림6] https://bdd-data.berkeley.edu/
[그림7] https://bdd-data.berkeley.edu/
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
- #Brightics
- #DeepLearning
- #딥러닝
- #플랫폼
- #자율주행
- #인공지능
- #AI
- #컴퓨터비전
- #ComputerVision
- #SLAM
- #Jupyter
- #ApacheSpark
- #SamsungSDS
![]()

삼성SDS America
삼성SDS에서 대규모 딥러닝 기반 AI 애플리케이션 및 시스템을 개발하는 업무를 맡고 있습니다. 과거에는 비트코인과 이더리움 블록체인 분석 솔루션을 위한 대규모 머신러닝 시스템을 개발하고 구현하는 데 주력했습니다.