

많은 조직이 데브옵스를 통해 운영 자동화를 꾀합니다. 자동화는 데브옵스의 중요한 원칙이긴 하나 그것만이 전부는 아닙니다. 진정한 데브옵스의 철학은 애자일 철학과 마찬가지로 고객 중심의 가치를 빠르면서도 안정적으로 전달하는 것입니다. 단순 자동화 툴 몇 개를 도입하는 것으로는 원하는 만큼의 전달 리드타임 단축이나 운영 안정성의 비약적 상승을 기대할 수 없습니다. 데브옵스를 부분적으로 도입하였으나 기대보다 성과가 나지 않는 조직, 또는 데브옵스 도입으로 애자일 가치를 진정으로 향상하고자 하는 조직에게 엔지니어링 관점의 가이드를 제시하고자 합니다.
고객 가치를 MVP(Most Viable Product) 중심으로 신속히 전달하고 지속적으로 개선하는 애자일의 철학이 개발현장에서 많이 확산되고 있습니다. 애자일 문화가 충분하지 않은 조직일지라도 애자일의 기법, 예를 들면 스크럼의 프로세스, 활동 등을 중심으로 활용하는 경우가 많습니다. 애자일이 일정 수준 적용되었다 하더라도 개발된 어플리케이션의 운영과 유지보수 비중이 높아지면 결국 고객 가치의 전달 속도는 떨어지고, 운영 안정성과 품질도 만족스럽지 못하게 됩니다. 어플리케이션이 제공하는 비즈니스 가치의 성장에 따라 운영안정성과 기민성이라는 두 성질은 서로 트레이드오프 관계가 되어 동시 달성이 쉽지 않게 됩니다. 데브옵스는 애자일 기치를 개발에서 운영까지 확장하고 안정성을 더욱 보장하는 것을 목표로 합니다. 데브옵스는 바로 애자일의 운영 확장 버전이라 할 수 있겠습니다. (그림 1)
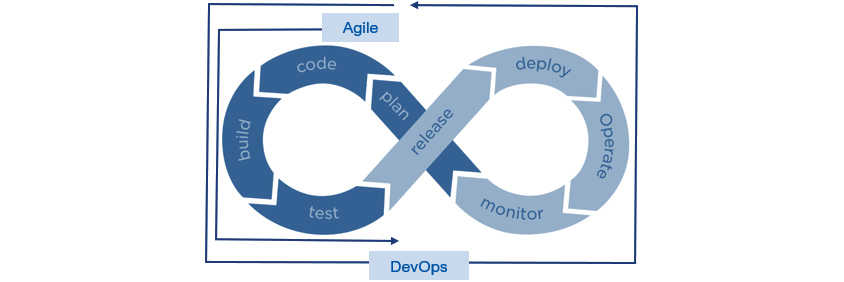
- plan -> code -> build -> test
- -> release -> deploy -> operate -> monitor
데브옵스의 개념을 CI(Continuous Integration)/CD(Continuous Delivery or Deploy)에 한정해서 정의하거나 배포 자동화 관점에서만 보는 경우가 있습니다. 그러나 필자는 비즈니스 성공이라는 하나의 목표를 달성하기 위해 개발과 운영이 협업하는 철학과 프랙티스(기법, 실천사항)의 모음이라고 정의합니다. 데브옵스의 프로세스는 개발과 운영이 하나의 프로세스로 연계되고 지속적으로 개선하는 순환구조를 갖습니다. 이는 애자일의 적용이 단방향, 단발성이 아니며, 운영 유지보수를 통해 어플리케이션 자체와 프로세스, 도구, 프랙티스 등 관련된 모든 것을 개선해 나갈 수 있다는 철학을 보여줍니다. IBM은 2016년 데브옵스의 방법론인 Garage(그림 2)를 공개하며 애자일의 공통 철학(문화)을 기반으로 개발과 운영이 완전히 통합된 순환적 프로세스를 제시하였습니다.
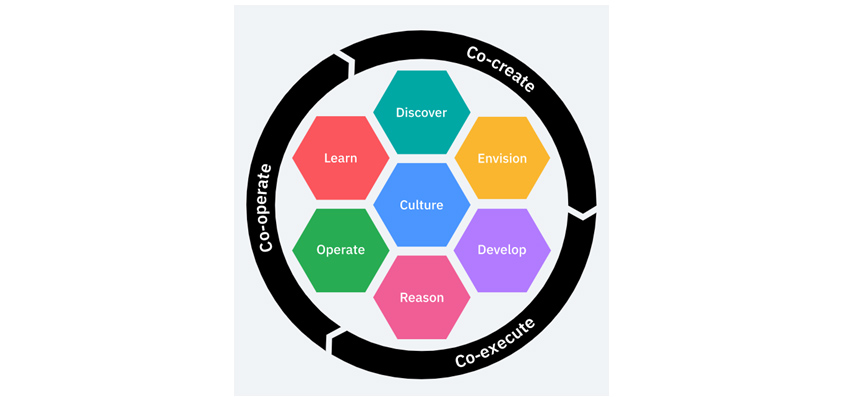
- discover, learn, culture, envision, operate, reason, develop
고객가치는 Design Thinking 기법 (혹은 이의 부분집합)을 통해 도출되고 정제됩니다. 이렇게 정제된 요구사항은 애자일 엔지니어링 프랙티스로 개발이 수행되며 코드기반의 검증과 자동화된 배포를 통해 고객에게 전달됩니다. 운영상 필요한 다양한 지표와 고객가치의 정량적 수치는 실시간으로 수집, 측정되어 개선활동이나 문제예방에 활용됩니다. 자가치유가 가능한 장애는 자동화된 워크플로우에 의해 해결되기도 하고 클라우드 네이티브 아키텍처를 통해 조치되기도 합니다. 고객의 피드백과 이해관계자들의 리뷰, 내부 조직의 회고, 포스트 모템(Post-mortem) 활동은 지속적 개선을 위해 데브옵스의 선두 프로세스로 돌아가 순환됩니다.
이제 애자일과 데브옵스의 가치는 조직에서 추구해야 할 핵심 가치로 대두되었습니다. 심지어 어느 산업군에서는 비즈니스의 존망까지도 영향을 받습니다. 이미 데브옵스를 부분적으로 채택한 조직도 전반적으로 확산될 수 있도록 노력을 기울어야 할 것입니다.
필자는 초대형 백엔드(Super Scalable Backend) 시스템을 개발 운영하는 것에 데브옵스가 어떻게 적용되는지 실질적으로 경험하며 배웠습니다. 성공적인 데브옵스 적용을 위해 교과서적, 문화적 접근보다는 엔지니어링 측면을 중심으로 다음과 같은 5개 항목으로 나누어 이야기하고자 합니다.
1. 아키텍처 측면 - 클라우드 네이티브의 수용
클라우드 네이티브가 데브옵스 구현을 가속화하기도 하지만 반대로 클라우드 네이티브를 실현하기 위해 데브옵스가 활용되기도 합니다. 두 개념은 서로 어느 한 편에 속하는 것이 아닙니다. 고객중심의 가치를 최대한 기민하면서도 안정적으로 전달하고자 하는 데브옵스의 철학이 실제로 구현되려면 클라우드 네이티브 없이는 사실상 불가능합니다.
클라우드 네이티브의 용어는 수 년 동안 매우 혼란스럽게 표현되었습니다. 혹자는 워크로드를 단순히 클라우드에 포팅한 것만으로 표현하였고 일부 벤더는 PaaS(Platform as a Service)에만 집중하여 표현하기도 하였습니다. 이는 잘못된 이해이며 클라우드 네이티브와 클라우드 컴퓨팅과는 간극이 있다고 보시면 됩니다. 클라우드 네이티브란 “클라우드의 이득을 최대한 활용”하는 아키텍처이자 클라우드 도입전략으로 정의됩니다. 기민성과 이식성, 실패복구성, 자동 확장성을 극대화하는 컴퓨팅의 철학이며 데브옵스와 SRE(Site Reliability Engineering)철학을 실천하기에 최적의 기술이자 아키텍처입니다.
가트너는 클라우드 네이티브를 달성하기 위한 접근 방법을 2가지로 정의하는데, 필자는 이 구분을 매우 선호합니다. 첫번째는 컨테이너 네이티브이며 두번째는 CSP(Cloud Service Provider) 네이티브입니다. 전자는 컨테이너와 쿠버네티스로 대표되는 CNCF(Cloud Native Computing Foundation)의 주요기술들을 활용하여 달성합니다. 후자는 클라우드 서비스 제공자의 역량을 활용하여 달성되는데 Azure의 앱 서비스나 Function, 컨테이너 앱 혹은 AWS의 Lamda 등의 어플리케이션 호스팅 PaaS(Platform as a Service)가 이에 해당합니다. 컨테이너 네이티브는 철저히 OSS(Open Source Software)기술로 구현되기 때문에 도입을 검토하는 조직의 오픈소스 역량에 따라 신중히 검토되어야 합니다.
필자의 경험상 쿠버네티스를 직접 설치(일명 바닐라), 구성하여 사용하는 것은 쉬운 일이 아닙니다. 더욱이 쿠버네티스의 수많은 에코 시스템들의 OSS를 직접 구성, 운영하는 것도 왠만한 OSS 역량이 성숙되어 있지 않으면 난이도가 매우 높은 일입니다. 조직의 OSS역량이 충분히 확보되었다면 IaaS나 직접 컴퓨팅 환경을 구축하여 쿠버네티스 에코를 구축, 운영할 수 있습니다. AWS의 관리형 컨테이너(EKS)가 나오기 전, 필자의 조직 역시 일부 마이크로 서비스를 대상으로 kops(https://kops.sigs.k8s.io/)라는 OSS로 쿠버네티스 환경을 VM에 직접 구성하여 운영한 적이 있습니다. 컨트롤 플레인을 관리하고 쿠버네티스의 버전 업그레이드를 감당하면서 최적의 노드 이미지를 유지하며 패치를 해나간다는 것이 당시에는 크나큰 도전이었습니다. kops를 통한 노드 오토 스케일링 구현이 불가능하여 모니터링 환경에 의한 별도의 자동 구성을 해야 한다는 제약사항들도 있었습니다. (현재는 CNCF의 별도 OSS를 통해 구현이 가능합니다). 결론은 역량이 갖춰진 조직에서도 매우 어려움을 겪는다는 것입니다.
반면, 컨테이너 네이티브를 선택한 조직이 이러한 고난이도의 쿠버네티스 관리를 직접 감당할 수 있는 역량을 보유하였다 해도 필요한 Tooling은 신중하게 고려해서 선택해야 합니다. CNCF 랜드 스케이프(https://landscape.cncf.io/, 그림 3)에서 어느 정도 성숙도가 있는 도구들을 선택해야 하는데, 성숙도는 컨트리뷰터 수, 커밋과 릴리즈 빈도, GitHub의 Star수 등으로 판단할 수 있습니다. 물론 적용하기 전 PoC(Proof of Concept)나 파일럿이 반드시 수행되어야 합니다. OSS를 선택한다면 보안취약성을 포함해 기능오류, 성능이슈, 라이선스 문제 등을 항상 살펴보아야 합니다. 사용할 툴들이 결정되면 직접 설치하는 방식보다 Operator 설치방식을 선택해야 합니다. 대부분 툴은 Operator(https://operatorhub.io/)를 제공하는데 쿠버네티스 환경에서 더 쉽게 구성하고 운영 작업을 통합적으로 수행할 수 있게 해줍니다. 이를 테면, 인메모리 퍼시스턴스를 Redis를 사용한다면 Statefulset으로 직접 설치하는 것이 아니라 Redis Operator (https://operatorhub.io/operator/redis-operator)를 통해 구성하고 운영 관리하는 것입니다. Operator Hub에서 제공되는 Operator들은 Capability Level을 제공(그림 4)하는데 Seamless Upgrades 수준 이상으로 선택할 것을 권고합니다. 참고로 Capability Level은 https://sdk.operatorframework.io/docs/overview/operator-capabilities/ 에서 확인할 수 있습니다.
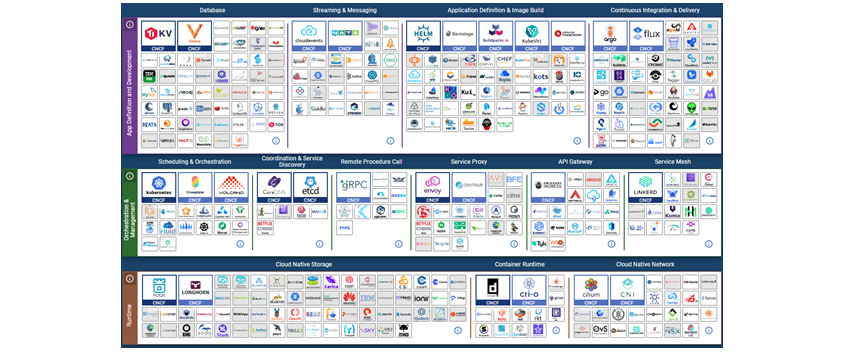 [그림 3] 클라우드 네이티브 랜드스케이프
[그림 3] 클라우드 네이티브 랜드스케이프
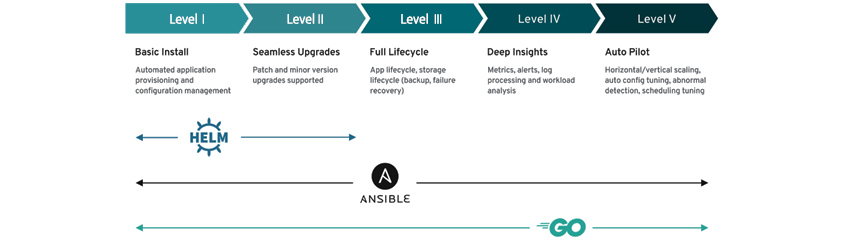
- basic install / seamless / full lifecycle / deep insights / auto pilot
- automated application provisioning and configuration / patch and minor version upgrades supported / app lifecycle, storage lifecycle(backup, failure recovery) / metrics alerts, log processing and workload analysis / horizontal·vertial scalling,auto config turning, abnormal detection, schedulling tuning
반면, CSP 네이티브는 상대적으로 OSS 역량이 확보되지 않은 조직에서 활용하기가 쉽습니다. 기민성, 이식성, 실패복구성, 자동확장성을 보장하는 아키텍처를 설계, 운영하는 고민을 하지 않고 오직 어플리케이션 자체에만 집중할 수 있습니다. Java 앱이면 jar 파일까지만 만들어 어플리케이션 PaaS에 배포하면 됩니다. 애저 앱 서비스, 스프링 클라우드, 클라우드 파운드리 등이 그 예입니다.
CSP 네이티브는 매우 쉽게 어플리케이션을 클라우드 네이티브화 할 수 있으므로 시간과 자원 활용성 측면에서 유리합니다. 물론 조직이 기본적인 컨테이너 역량을 보유하고 있다면 관리형 컨테이터 네이티브의 활용을 검토해볼 수 있습니다. CaaS(Container as a Service)로 불리기도 하는 이 접근방식은 쿠버네티스 운영관리의 대부분을 CSP에 맡기고 그 위에서 작동될 자원들만 조직에서 직접 관리할 수 있기 때문에 더 실용적인 클라우드 네이티브 채택 방법으로 알려져 있습니다. Azure의 AKS, AWS의 EKS, GCP의 GKE가 그 대표적인 예입니다. CSP가 제공하는 관리형 쿠버네티스 클러스터를 사용하게 되면 벤더에 덜 종속적이면서도 클라우드 네이티브가 주는 혜택을 가져갈 수 있습니다.
컨테이너 네이티브이든 CSP 네이티브이든 클라우드 네이티브한 어플리케이션을 운영하려면 어플리케이션 자체도 현대화되어야 합니다. 클라우드 네이티브를 어플리케이션 아키텍처로 한정하는 용어인 클라우드 네이티브 어플리케이션 아키텍처를 한 마디로 하면 현대화된 어플리케이션이라할 수 있습니다. 실질적으로 12 요소 앱 원칙(https://12factor.net/)이나 가트너의 LIFESPAR 원칙(표 1)으로 설계된 어플리케이션을 의미합니다. 이 부분은 다음 기고에서 상세히 설명드릴 기회가 있을 것입니다.
| 12요소 앱 | LIFESAR |
|---|---|
|
· 코드베이스 · 명시적 선언된 종속성 · 벡엔드는 리소스로 취급 · 분리된 빌드, 릴리즈, 실행 · Stateless 프로세스 · 포트바인딩 · 동시성 · Graceful 폐기성 · 개발,프로덕션 패리티 · 스트림된 로그 · 어드민 프로세스 |
· Latency가 있는 것을 인지 · 모든 메트릭은 측정되게 · Failure가 있는 것을 인지 · 이벤트 드리븐 비동기 · 보안 · 동시성(병렬) · 자동화 · 리소스 소비 인지 |
기존 레거시 어플리케이션도 고객 가치 중심의 기민성이 우선 시 되어야 한다면 12 요소 앱으로 리팩토링하는 것이 반드시 고려되어야 합니다. 마이크로 서비스 아키텍처로 재설계되면 이상적이겠지만, 기존 모놀리스 어플리케이션도 12요소 앱의 대부분을 적용할 수 있습니다. 미니 서비스 아키텍처는 그런 요건을 위한 현실적인 대안으로 선택될 수 있습니다.
당연한 얘기지만 처음부터 개발될 어플리케이션은 아키텍처를 구상할 때부터 위의 요소가 반드시 반영되어야 합니다. 클라우드 네이티브로 가기 위해선 어플리케이션이 위와 같이 기본적인 현대화가 되어야 합니다. 어플리케이션이 준비가 안되어 있으면 어떠한 방식의 클라우드 네이티브를 도입하더라도 원하는 목표수준 (예: 전달 리드타임, 운영안정성 지표)에 다가갈 수 없습니다.
클라우드 네이티브는 차세대 프로젝트 수행 같은 빅뱅 접근방식으로 달성하기 어렵습니다. 하나씩 실천해 나가는 여정으로 접근하셔야 합니다. 목표와 비전을 정의한 후 한 단계씩 구현해 나가는 것이 중요합니다. 아래는 필자의 경험한 클라우드 네이티브 여정을 위한 순서와 도구들의 예시입니다.

- datadog,prometheus,grafana,pagerduty : continuous monitoring
- puffet,terraform : infra as code
- chef : immutable infrastructure
- jenkins blueocean, spinnaker, travis CI : blue green deployment/canary
- grizzly,akka,operators : microservice
- helm chart : containerzation
- kops, eks,iks : orchestration
2. 개발 및 유지보수 측면 - 애자일 개발 프랙티스의 가속화. 제일 어렵고 여전히 중요한…
말그대로 개발자 전성 시대입니다. 개발자의 역량에 따라 생산성 차이가 수십 배가 난다는 말은 이제 놀랍지도 않습니다. 개발자는 클라우드 네이티브, 애자일/데브옵스, 디지털 트랜스포메이션 모든 영역에서 가장 핵심적인 역할을 하는 자원입니다. 기존 SI산업에서 코더로 평가절하되었던 것과 달리, 현재 개발자들은 완전히 차원이 다른 고도의 역량을 가진 전문직 종사자입니다. 과거에는 분석/설계자의 산출물로 코딩역할만 했다고 하면 지금은 분석부터 기능설계, 비 기능설계(아키텍처), 개발, 테스트, 배포, 운영까지 소프트웨어 개발 대부분의 라이프사이클에 직접적으로 참여하기 때문이죠. 직접적으로 참여한다는 의미는 단순 미팅에 참여하고 보고자료를 작성하는 것이 아니라, 코드 역량, 구현 역량을 보유하고 있다는 것입니다. 일부 아마존 같은 테크 기업들은 개발/구현 중심의 소프트웨어 엔지니어임을 강조하기 위해 SDE(Software Development Engineer, 소프트웨어 개발 엔지니어)라는 표현을 쓰기도 합니다. 좁게 보면 개발자는 SDE만을 말하기도 하지만 큰 범주에서 보면 SDET(Software Development Engineer in Test, 테스트 엔지니어), 데브옵스 엔지니어를 포함하기도 합니다. SDET는 테스트엔지니어링을 코드로, 데브옵스 엔지니어는 인프라를 코드로 작성하고 유지보수합니다.
개발자는 Design Thinking이나 User Story 워크샵에 참석하여 고객 가치로 우선순위화 된 기능을 프로덕트 매니저와 함께 도출하고 이를 실현할 기능 설계와 비 기능 요건을 위한 아키텍처를 잡아야 합니다. 툴과 산출물은 중요하지 않지만 기능과 아키텍처는 직접 구현수준 만큼의 기술적으로 높은 역량을 가지고 있어야 합니다. 개발자는 특정 수준의 커버리지를 갖는 단위테스트 코드를 작성해야 하고 통합테스트 코드 또한 작성해야 합니다. 테스트 주도 개발 프랙티스는 테스트 코드를 먼저 짜고 본 기능을 개발하는 순서가 중요한 게 아니라, 테스트가 가능한 기능 코드를 만들고 테스트 코드를 작성하는 것이 중요하게 여겨져야 합니다. 테스트 코드는 테스트 엔지니어만 만드는 것이 아닙니다. 아래 (그림-6)와 같이 개발자는 단위, 통합테스트 코드를 작성하고 테스트 엔지니어는 시스템 테스트와 인수테스트에만 집중합니다.
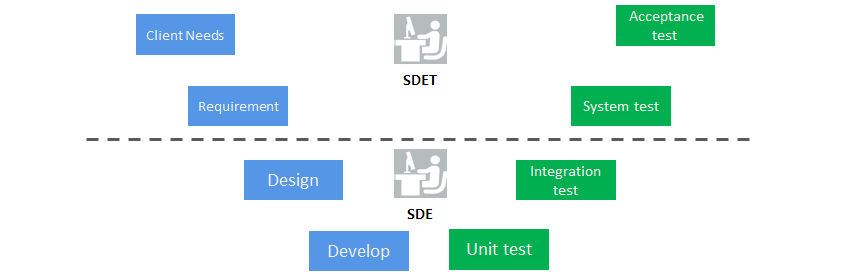
- client needs/acceptance test
- requirement/system test
- design/integration test
- develop/unit test
개발자가 작성하는 테스트 코드는 현대적 개발문화에 있어서 중요한 요소입니다. 아키텍처도 일회성의 비 기능적 요구사항으로 고정되는 것이 아니라 MVP구현 방식처럼 초기의 최소 요건만 가진 아키텍처로 시작하고 끊임없이 개선되고 보완되어야 합니다. 이런 아키텍처의 변경도 테스트코드에 의해 검증되므로 테스트 코드가 있어야 자신감을 갖고 지속적으로 아키텍처의 개선을 시도하고 발전시켜 나갈 수 있습니다. 만약 테스트 코드가 없다면 단순 패키지 구조만 바꾸려 해도 운영 안정성의 불안감이나 부작용 때문에 시도하기조차 어려워집니다. 특히 한창 운영중인 시스템에선 더욱 힘들어집니다. 단위테스트와 통합테스트 코드를 개발자가 다 작성해야 하지만 단위테스트 코드 작성이 더 우선시되어야 합니다. 단위테스트 코드만큼은 개발 공수가 늘어난다 하더라도 초기부터 개발되고 유지보수 되어야 합니다. 단위테스트 코드를 처음 적용할 때는 기능 구현코드 작성보다 더 많은 공수가 소요될 수도 있습니다. 필자의 경험에 의하면 테스트 코드 경험이 없는 개발자가 테스트코드를 작성하는데 기능 코드를 구현하는 만큼 시간이 소요됩니다. 하지만 개발자가 익숙해지고 적응되면 테스트 코드 공수는 개발코드 작성의 20% 이하까지도 내려갑니다. 이런 테스트 코드 작성이 개발문화로 정착되면 테스트 코드만을 통과시키는 최소한의 코드 구현에 집중하고 지속적으로 리팩토링해 나가는 TDD(테스트 주도 개발)에 더 가깝게 다가갈 수 있습니다. TDD는 다양한 애자일 엔지니어링 프랙티스 중 핵심적인 요소입니다.
어떤 조직에서는 테스트 코드를 아웃소싱하기도 하는데 테스트 코드를 테스트주도개발 문화의 산출물로 활용되지 않는 이상 금방 불용되기 일쑤입니다. 테스트 주도 개발문화의 산출물로서 테스트코드가 개발, 유지보수 되어야 합니다. 테스트 엔지니어는 개발자와 협력하여 시스템 간 테스트를 포함하여 성능, Resiliency, 보안 테스트 등을 모두 수행해야 합니다. 인수테스트 역시 테스트 엔지니어의 몫입니다. 테스트 엔지니어와 테스터의 차이는 테스트 코드 작성 여부에 있습니다. 테스트 엔지니어는 API테스트, UI테스트 등의 기능 테스트 뿐 아니라 시스템 테스트를 위한 코드도 작성합니다. 테스트 수행 자체는 CI/CD파이프라인에 의해 수행되고 결과가 수집, 측정되어야 합니다.
개발자는 클라우드 네이티브 어플리케이션 아키텍처를 충분히 고려해야 합니다. 클라우드 네이티브는 “클라우드가 주는 혜택을 최대한 활용하여 구현”이라는 매우 쉬운 정의이지만 그 구현을 위해 체득해야 할 기술들은 결코 쉽지 않습니다. 컨테이너, CI/CD, 마이크로 서비스 아키텍처, 어플리케이션 현대화 등 폭넓은 영역에 대해 구현하는 수준으로 이해와 역량을 갖추어야 합니다. 즉, 개발되어야 할 어플리케이션은 구체적으로 마이크로 서비스나 미니 서비스 아키텍처로 설계되고 각각의 경계를 가지고 있으며 각각의 업무 특성에 맞게 퍼시스턴스가 RDB나 NoSQL로 구현됩니다. 마이크로 서비스 간 통신은 REST API로 구현되며 적절한 캐시능력을 보장하고 수평적 확장력을 위해 Stateless하게 구축됩니다. 대규모의 분산 아키텍처라면 이벤트 기반 기술이나 CQRS(Command Query Responsibility Segregation) 등의 기술로 설계되고 컨테이너 오케스트레이션을 통해 스케줄링이 자동화되도록 어플리케이션을 구성해야 합니다. 거기에 수많은 오픈소스 소프트웨어를 적재 적소에 활용하여 안정성과 생산성을 높이면서도 오픈소스의 취약점이나 라이선스 등을 지속적으로 검토해야 합니다.
개발자가 구현한 기능들은 CI/CD로 각종 점검 자동화, 배포 자동화를 통해 배포될 것이고, 배포되면 모니터링 및 장애대응까지 개발자가 수행해야 합니다. 이렇게 벅찬 업무들을 감당하기 위해서는 “극단적 자동화”를 선택하지 않을 수 없습니다. 예전 SI개발/유지보수에서는 소프트웨어 아키텍트, 인프라 아키텍트, 데이터 아키텍트, 테스터, 어플리케이션 운영자, 시스템 운영자, 데이터베이스 관리자 등이 각각의 조직에서 수행했던 일이므로 여전히 “이렇게 일하는 게 가능해?”라는 질문을 필자는 아직까지 계속 받습니다. 데브옵스가 더 가속화되기 위해 자동화의 중요성이 강조되어야 하는 이유입니다. 자동화에 대해서는 다음 장에서 더 자세히 다루겠습니다.
모든 개발자(SDE, SDET, 데브옵스 엔지니어)는 형상 관리 툴을 통해 코드를 관리하며 모든 브랜치(단위 요구사항이 반영된 논리적 분리 공간)의 작성을 완료 후 코드리뷰를 수행해야 합니다. 개발자간 코드품질과 생산성은 100배까지 차이가 나기도 합니다. 특히 함수형 프로그래밍이 대세로 확산되는 가운데 개발 생산성과 유지보수성의 차이는 전통적인 프로그래밍 방식과 비교하여 비약적으로 차이가 발생하게 되었습니다. 코드리뷰는 함수형 프로그래밍과 같은 선진 기법을 적용할 때 더욱 더 중요하게 작동됩니다. 코드 리뷰를 통해 수십줄의 코드를 단 몇 줄의 코드로 추상화하는 방법을 배우고 코드 품질을 향상시키며 개발자 간 성장과 학습에 대한 동기부여를 자극합니다. 이러한 개발문화의 적용은 결국 어플리케이션의 생산성과 품질에 그대로 녹아들고 선순환적 개선을 가져옵니다.
따라서, 코드리뷰는 개발 라이프사이클 상에서 필수 활동으로 여겨져야 하며 개발 공수에 반드시 포함시켜야 합니다. 정적점검에서 발견되지 않지만 기술부채를 늘일 수 있는 코드 스멜(오류는 아니지만 유지보수성, 생산성을 저하시키는 코드)을 개발자 간 상호 코드 리뷰를 통해 찾아내 코드 기술 부채를 지속적으로 줄여가야 합니다. 각 개발자만의 코드 기술, 팁, 알고리즘 등을 코드리뷰 함으로써 개발 역량 향상과 공유 문화를 실천할 수 있습니다. 트렁크기반 코드관리가 아니라면 반드시 기능 브랜치에서 메인 브랜치로 병합되는 코드들은 코드리뷰와 CI가 수행되어야 합니다.
3. 인프라 자동화 측면 - 자동화 어디까지 해봤니? 완전히 Immutable한 인프라 스트럭처
가장 기본이 되는 CI부터 이야기를 시작합니다. CI는 개발자가 작성한 코드가 문제를 일으키지 않고 통합되는지를 점검합니다. 그리고 작성된 단위/통합테스트 코드가 자동으로 수행되어 커버리지, 성공/실패율, 테스트 추이 등을 리포트로 뽑아 냅니다. 코드 취약점이나 스타일에 대한 기본적인 정적점검을 수행하고 보안점검, 오픈소스 라이선스/취약점 점검 등을 포함시킵니다. 일반적으로 CI의 끝은 패키징입니다. 어플리케이션 패키지를 라이브러리 리파지토리에 배포할 수도 있고 컨테이너로 패키징하여 컨테이너 레지스트리에 배포할 수도 있습니다. 패키징된 아티팩트를 중앙 집중적으로 관리하며 CD 파이프라인에서 쉽게 활용할 수 있기 때문입니다.
아래는 간단한 CI/CD 파이프라인의 예시들을 보여주는데 파이프라인의 스테이지(작업의 집합)는 각 프로젝트 상황에 맞게 구성할 수 있습니다.
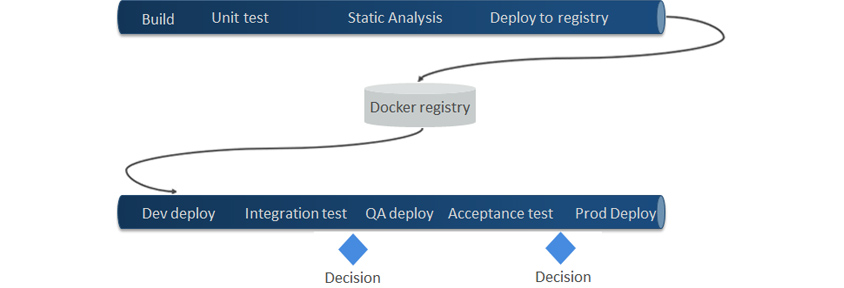
- build/unit test/static analysis/deploy to registry ->
- docker registry ->
- dev deploy/integration test/(decision)/QA deploy/acceptance test/(decision)/prod deploy
특히 아래 파이프라인을 보면 Git의 Tag를 구성하여 트리거링하는 예시를 보여주는데, Tag를 버전으로 설정하여 Release Candidate 버전은 테스트계에 배포되도록 하고 Release 버전은 운영계에 배포되도록 파이프라인의 설정을 구성할 수 있습니다.
CI/CD 자동화에서 어려운 부분 중 하나는 Immutable Infra의 철학입니다. “한 번 배포된 인프라는 불변한다”라는 다소 기이한 정의는 IaC(Infra as Code)의 대표적인 특징을 나타냅니다. 코드로 구성된 인프라와 실제 인프라는 완전히 일치해야 하며, 변경사항은 기존 코드를 수정하여 다시 배포해야 한다는 강박적인 철학을 내포합니다. 코드로 인프라를 완전히 관리한다는 것은 인프라의 이력관리와 손쉬운 롤백, 어디서든 재현 가능한 인프라를 구성할 수 있다는 것을 의미합니다. 운영계와 테스트계, 개발계의 각각 다른 환경 때문에 어플리케이션 장애 상황은 매우 흔하게 발생합니다. 개발계에서는 잘되는데 운영에 배포하면 문제가 발생하는 사례입니다. 따라서 인프라 구성 오류에 따른 장애를 막고 재현 가능한 인프라 구성상의 문제점을 쉽게 찾아내기 위해 IaC를 도입해야 합니다. 또한 BCDR(Business Continuity and Disaster Recovery)상황 시 인프라 구성을 빠르게 프로비저닝 하기 위한 자동화의 도구로 활용되기도 합니다.
IaC의 Immutable 인프라 철학은 클라우드 리소스를 프로비저닝할 때보다는 어플리케이션 호스트 환경(어플리케이션이 작동할 VM이나 컨테이너)을 구성할 때 더 잘 맞게 적용됩니다. PaaS성의 클라우드 리소스를 변경할 때마다 기존 리소스를 삭제하고 재생성하면 퍼시스턴스들의 데이터들을 복구해 내는데 불필요한 공수가 들기 때문입니다. 따라서 Stateless한 어플리케이션의 컨테이너를 중심으로 Immutable 인프라 원칙을 적용하는게 일반적입니다. 어플리케이션을 VM에 호스팅할 경우 VM의 모든 구성을 Chef나 Puffet과 같은 도구를 사용하여 완전히 코드화하여 선언하고 이미지로 생성되어야 합니다. 새로운 버전의 어플리케이션 패키지(JVM이면 jar나 war)를 배포하려면 기존 VM을 폐기하고 코드를 재생성해서 만들어진 VM을 재생성하여 교체되어야 합니다. 즉, 코드를 통해 생성된 이미지의 새로운 VM들이 기존 VM을 교체해 나가는 방식입니다. (롤아웃 배포라고 합니다.) 기존 VM과 신규 VM을 동시에 배치해 놓고 검증이 완료되면 앞 단 라우팅을 변경하는 방식이 블루그린 배포이며 배포 안정성을 세밀하게 검증하기 위해 1~2개의 배포를 먼저 실행하는 카나리 배포를 선택할 수도 있습니다. 코드로 작성된 VM의 이미지는 자동 스케일링 확장 시 사용되기도 합니다. Immutable 인프라의 철학을 철저히 따르는 조직은 VM의 수동 변경을 막기 위해 크론잡을 통해 형상 구성 변경을 추적하고 강제로 오버라이드하는 프랙티스를 수행하는 곳도 있습니다. 그만큼 코드와 인프라를 강박적으로 일치시키려는 철학을 실천하고자 하는 것입니다.
어플리케이션 구동을 위해 Kubernetes와 같은 컨테이너 오케스트레이션 툴을 사용한다면 Kubernetes Manifest나 Helm Chart로 더욱 쉽게 Immutable과 선언적 인프라를 관리할 수 있습니다.
IaC는 CD pipeline내 구성이 되지만 클라우드 리소스를 프로비저닝 하는 코드들은 어플리케이션 CD pipeline과 별개의 것으로 구성되는 것이 관리효율성 측면에서 유리합니다. 예를 들면, 컨테이너로 구성된 어플리케이션이 변경되었다고 해서 Kubernetes클러스터 구성이나 PaaS DB가 매번 변경되지는 않을 것이기 때문입니다.
인프라 코드를 Git으로 형상관리할 경우 개발코드와 동일하게 브랜치 전략과 코드 리뷰 등의 개발 프랙티스를 수행해야 합니다. 인프라 코드가 커밋되면 인프라가 바로 적용되도록 GitOps환경을 순수 Git의 기능만으로 구현 가능하며, ArgoCD나 FluxCD와 같은 전문 GitOps툴을 활용할 수도 있습니다.
다음은 어플리케이션의 코드와 테스트, IaC의 리파지토리 구조의 예시를 보여줍니다. 어플리케이션에서 중앙관리를 할 수도, 테스트와 인프라를 분리해서 관리할 수도 있는데, 소규모의 어플리케이션과 MSA환경에서는 하나의 리파지토리에서 관리할 수도 있고, 데브옵스 팀이 분리되어 있는 경우 별개의 리파지토리에서 관리할 수도 있습니다. 각 조직 구성과 어플리케이션 특성에 맞게 리파지토리 전략을 가져가시면 됩니다.
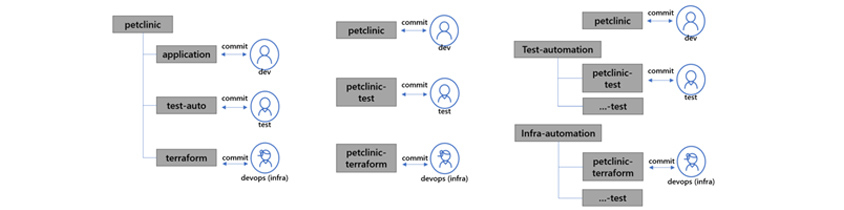
- petclinic ->
- application <-> (commit) dev
- test-auto <-> (commit) test
- terraform <-> (commit) devops(infra)
- petclinic <-> (commit) dev
- petclinic-test <-> (commit) test
- petclinic-terraform <-> devops(infra)
- petclinic <-> (commit) dev
- test-automation ->
- petclinic-test / ...-test <-> (commit) test
- infra-automation ->
- petclinic-terraform / ...-test <-> devops(infra)
4. 스케일아웃 측면 - 스케일 아웃을 버틸 운영능력을 가지고 있는가?
기존에는 개발조직과 운영조직이 별도로 구성되어 어플리케이션의 개발이 완료되면 운영조직으로 이관하고 운영조직이 안정성을 담보로 변경을 최소화하여 보수적으로 운영하는 것이 흔한 일이었습니다.
데브옵스는 개발과 운영의 벽을 허물라고 하지만 그 벽을 허무는 가장 확실한 방법은 개발이 운영을 하고 운영이 개발을 하는 것입니다. 즉, 하나의 조직에서 개발과 운영을 다 감당한다는 말입니다. 개발조직이 운영까지 맡아서 하는 것은 쉬운 일은 아니지만 개발조직은 개발만 하고 운영은 운영조직에 이관하는 것도 데브옵스의 지속적 개선 순환의 원칙에 맞지 않습니다. 넷플릭스나 마이크로소프트 같은 테크 기업의 개발팀은 소프트웨어 개발 철학을 “You build it, you run it (당신이 개발하고 당신이 운영한다. 혹은 운영하려면 당신이 개발해라)”로 선언합니다. 극단적 자동화를 통해 운영을 효율화하여 데브옵스의 가치를 실현하려면 개발부터 그렇게 구현이 되어야 합니다. 개발할 때 운영의 경험이 없으면 운영 효율화를 위한 방법을 상상해낼 수가 없습니다. 개발자의 역량측면에서도 운영을 경험해보지 않는 개발자는 비 기능적 설계인 아키텍처 역량이 부족해질 수밖에 없습니다. 운영 경험을 통해 어느 부분을 자동화하고 아키텍처를 어떻게 최적화하며 대규모의 트래픽은 어떻게 관리하고 모니터링하는 방법을 체득할 수 있으며, 이 경험으로 운영 효율적인 개발코드를 만들어 낼 수 있는 것입니다. 어플리케이션과 테스트, 인프라 코드 모두 해당되는 이야기입니다.
신규서비스일 경우 개발팀의 전체가 운영으로 모두 이관되지 않더라도 운영팀은 모두 개발팀이었어야 합니다. 개발자, 테스트 엔지니어, 데브옵스 엔지니어 모두 해당되며, 운영역량 없이 개발역량 향상은 달성하기 어렵다는 것을 인지해야 합니다.
운영의 대표적인 업무가 시스템 모니터링과 이상 시 조치하는 일일 텐데 고수준의 자동화를 통해 자가조치적(Autonomous) 모니터링 환경을 구현할 수 있습니다. 쉬운 예로, 오토 스케일링 아웃은 부하가 몰리면 CPU나 메모리 사용량이 증가하고 이에 따라 수평적으로 스케일아웃을 할 수 있도록 구성하는 것입니다. 여기서 더 나아가 사용자 요청이 늘거나 외부 이벤트 (날씨 변화에 따른 트래픽 증가, 특정 시간 트래픽 증가)에 따라 시스템 자원 조율을 자동화할 수 있습니다. 어플리케이션 호스팅 환경이 VM이라면 오토 스케일링 시간은 이미지 프로비저닝으로 인해 최소 수 분 ~ 수 십분까지 소요될 수 있습니다. 컨테이너 환경에서는 이 시간을 수 초로 줄일 수 있기 때문에 컨테이너 환경 채택이 선호되는 이유이기도 합니다.
운영을 위한 자동화 사례는 수도 없이 찾아볼 수가 있는데요. 메시지 큐에서 인바운드와 아웃바운드 메시지 수의 차이가 임계치 이상으로 발생할 때 메시지 클라이언트들을 재 시작하여 자가 조치를 하도록 구성할 수도 있을 것이고, Redis 캐시환경에서 메모리 부족으로 Eviction이 다수 발생할 경우 Expire가 되지 않는 캐시들 중 가장 적게 사용된 데이터들을 선제적으로 지우도록 자동화할 수도 있을 것입니다. (참고적으로 필자가 글로벌 개발팀에서 가장 많이 받아본 모니터링 Slack 메시지는 “복구됨(Recovered)”이었습니다. 수많은 시스템 오류 알람의 90% 이상은 자가 조치되었습니다.)
기존의 모니터링이 특정 상황에 대한 위험 경보나 알림이었다면 이제는 다양한 자동화 도구와 지능적 모니터링 환경을 활용하여 자가 조치적 운영환경을 구성할 수 있습니다. 이 말은 운영 자원을 큰 수준으로 줄여 나갈 수 있다는 의미이며 이것이 메타나 IBM 같은 테크 기업에서 몇 명의 담당자가 수천, 수만 가지의 인프라 환경을 관리할 수 있는 방법이기도 합니다. 선진 기업들은 생각하는 것 이상으로 자동화를 구현한다는 것을 배워야 합니다.
5. 조직적 측면 - 우리는 진정 한 배를 타고 있는가?
본 항목은 엔지니어링 측면은 아니지만 성공적인 데브옵스 도입을 위해 고려해야 할 핵심적인 부분입니다. 애자일팀은 스크럼이나 스쿼드라는 이름으로 개발자(SDE), 테스트 엔지니어(SDET), 데브옵스 엔지니어, 프로덕트 매니저 역할을 가진 팀원들로 구성됩니다. 각각의 역할은 개발팀, 테스트팀, 데브옵스 팀, PM팀 등의 원소속이 있으면서 매트릭스 조직으로 팀이 구성되는 것이 흔한 데요. 원 소속 조직을 운영하는 것은 리소스의 공유정도를 늘리고 각 역할별 전략 공유나 직무 교육, 사례 전파, 일관된 평가체계 등을 유지하는데 유리하기 때문이죠. 이러한 조직 구성은 애자일의 성숙도와 관계없이 대다수 기업에서 유사한 형태로 운영합니다. 그러나 스쿼드 팀이 애자일과 데브옵스의 철학에 맞게 잘 작동되려면 원 소속 여부와 관계없이 팀내 공통의 목표 공유와 평가 설정이 필요합니다.
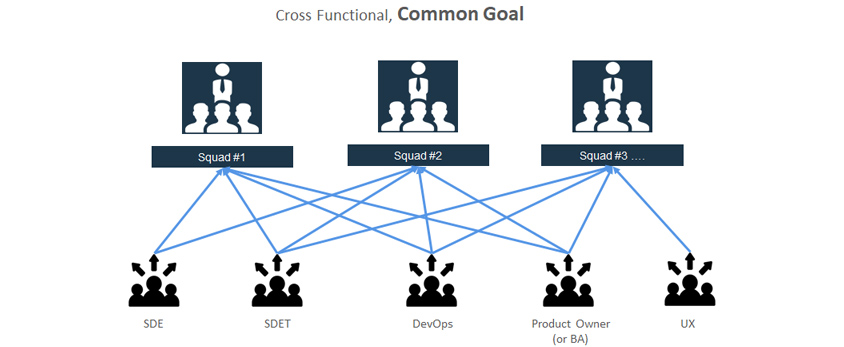
- squad #1 / squad #2 / squad #3
- SDE,SDET,DevOps,Product Owner(or BA) / SDE,SDET,DevOps,Product Owner(or BA) / DevOps,Product Owner(or BA),UX
위의 예시를 보면 스쿼드 팀별 각 구성원들은 원소속의 개발팀일 수도 있고 다른 전문 Shared 조직에서 파견되어 구성될 수도 있습니다. 스쿼드 팀은 기능적, 매트릭스로 구성되어 있는 것이죠. UX는 UX그룹에서, 데브옵스 엔지니어는 전사 인프라 엔지니어링 팀에서, 테스트 엔지니어는 테스트 Shared 팀에서 파견형태로 팀에 참여하는 것을 말합니다. 이러한 구조는 자원 활용성과 고도의 전문성을 유지하기 위해 당연한 구조일 수 있습니다. 이 때, 팀이 다양한 조직에서의 인원으로 구성되었다 하더라도 이들 모두의 최우선 목표는 무조건 하나이어야 합니다. 스쿼드 팀이 개발/운영하는 어플리케이션의 성공 그리고 이것을 통한 고객가치 실현, 비즈니스 성과 창출 등으로 정의되어야 한다는 것이죠. 테스트 엔지니어의 경우 1순위 KPI (Key Performance Indicator)나 OKR(Objectives & Key Result)은 스쿼드 팀에서의 테스트 엔지니어링 지표와 완전히 정렬되어 있어야 합니다. 원소속의 테스트 Shared팀에서 받은 성과목표는 항상 후순위여야 하거나 비중이 스쿼드 팀의 목표보다 더 작아야 합니다. 스쿼드 팀의 목표달성을 위해 팀에 소속된 역할들은 스쿼드 팀이 최대한 잘 작동되는데 기여하도록 최대치의 동기부여를 받아야 합니다. 팀워크를 최대치로 끌어올리기 위해 스쿼드 팀에 소속된 개발자, 테스트 엔지니어, 데브옵스 엔지니어, 프로덕트 매니저들의 노력은 완전하게 스쿼드 팀에 집중되어야 합니다. 스쿼드 팀 전체가 역할과 관계없이 오직 하나의 목표, “제품의 성공”을 위해 비전을 공유하고 공동의 목표를 설정하고 성과지표도 단일하게 가져가야 합니다. 각 역할의 평가는 스쿼드 팀에서의 평가가 우선시 되어야합니다. 그래야 스쿼드 팀의 성공, 즉, 스쿼드 팀이 개발 운영하는 어플리케이션의 정량, 정성 지표 (ex: 전달 리드타임, 품질, 고가용, 사용자수, 고객 피드백 점수, 매출액 등)의 달성을 위해 개발자, 테스트 엔지니어, 데브옵스 엔지니어들이 전략과 비전을 완전히 공유하며 지속적 개선 Loop를 유지하려고 노력하기 때문입니다.
이상 데브옵스의 성공적인 도입과 지속적인 운영 방법에 대해 엔지니어링 관점으로 살펴보았습니다. 여기서 다룬 내용 이외에도 데브옵스를 위한 더 많은 고민이 필요할 것입니다. 이를 테면, 고객 가치의 정의와 정제 방법, 개발/운영상의 지표 설정 및 측정, 평가 방식 등도 살펴보아야 합니다. 애자일과 데브옵스 프랙티스 중 현장에서 잘 적용되지 않는 것들 위주로 다루었으므로 전체 프랙티스를 펼쳐놓고 추가적인 적용을 고려해야 할 것입니다. SRE와 관련된 프랙티스도 포함해서 말입니다.
데브옵스를 통해 보다 많은 조직이 더 많은 것들을 달성하는데 본 글이 조금이나마 기여되기를 희망합니다.
References
[1] “마이크로소프트 데브옵스 블로그”, https://devblogs.microsoft.com/devops/
[2] “A CTO’s Guide to Cloud-Native”, 가트너, 2022
[3] “Top Strategic Technology Trends for 2022: Cloud Native Platforms”, 가트너, 2022
[4] “클라우드 네이티브 트랜스포메이션”, O'Reilly (에이콘), 2022
[5] “디지털 트랜스포메이션 필드매뉴얼”, 미래의창, 2021
[6] “IBM Garage”, https://www.ibm.com/kr-ko/garage/
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

SI회사에서 솔루션개발센터, SI, ITO, 데브옵스Lab 등의 부서에서 다양한 개발현장을 체험하였습니다. 이후 IBM Watson(Weather) 글로벌 개발팀에서 세계 10대 트래픽의 초대형 백엔드를 클라우드 네이티브 아키텍처로 개발, 운영하는 리드 소프트웨어 엔지니어 역할을 수행하였습니다. IBM 개발자 컨퍼런스, KT, 국민은행(KB)그룹, 하나은행, 한국 정보과학회, 한국 정보시스템 감사통제협회, 경희대학교 등 다수의 기관에서 클라우드 네이티브와 데브옵스를 주제로 강연하였습니다. 현재는 마이크로소프트에서 어플리케이션 혁신과 인프라 현대화를 위한 클라우드 네이티브 컴퓨팅 아키텍트 역할을 수행하고 있습니다.