

들어가며
빅데이터 시대가 도래하면서 데이터 분석과 보안에 대한 관심이 커지고 있습니다. 특히 수많은 데이터의 홍수 속에서 실시간으로 분석 결과를 확인하기 위한 스트림 프로세싱(Stream Processing) 기술 수요가 늘어나는 추세입니다. 본 아티클에서는 스트림 프로세싱의 정의와 주요 프레임워크를 알아보고 최근 주목받고 있는 아파치 플링크(Apache Flink)에 대해 살펴보겠습니다.
스트림 프로세싱이 중요한가요?
스트림 프로세싱은 금융 거래나 시장 및 통화 상태 모니터링, 보안 탐지나 시스템 실시간 분석과 같은 스트리밍 분석(Streaming Analytics) 또는 실시간 분석(Realtime Analytics)에 사용되는 기술입니다. 일정량 또는 일정기간 동안 데이터를 모아서 한꺼번에 처리하는 일괄처리(Batch Processing)와 비교하여 연속되는 실시간 데이터를 처리하기 때문에 빠르고 효율적인 데이터 활용이 가능합니다.
빅데이터의 특징을 나타내는 5V(Volume, Variety, Velocity, Variability, Veracity) 중 속도(Velocity)는 데이터가 실시간으로 생성되고 빠르게 유통되는 것을 의미합니다. 스트림 프로세싱은 실시간으로 데이터를 처리할 수 있으므로 속도를 단축시키는 것과 밀접한 관련이 있습니다.
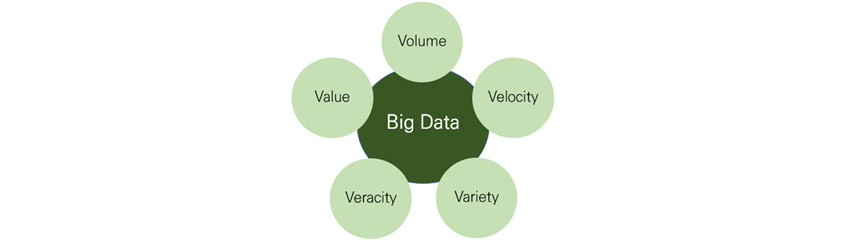 [그림 1] 빅데이터의 5V
[그림 1] 빅데이터의 5V
스트리밍 데이터를 활용하면 처리 속도가 빨라지기 때문에 데이터 공유와 분석에도 이점이 있습니다. 이는 기업의 온라인 상거래나 SNS를 통한 고객 소통과 같이 실시간 대응이 중요한 분야에서 비즈니스 경쟁력 제고에 지대한 영향을 미칩니다. 시장의 반응도 그만큼 뜨거운데 시장조사기관 리서치앤마켓(Research And Markets)이 2021년 1월 발표한 보고서에 따르면, 전 세계 스트림 프로세싱 시장은 2021년부터 2026년까지 연평균 성장률(CAGR)이 20.6%에 달할 것으로 전망됩니다.
스트림 프로세싱이 무엇인가요?
스트림 프로세싱을 검색해보면, 비슷한 용어들이 많아 의미를 혼동하기 쉽습니다. 대표적으로 '이벤트 스트림 프로세싱(Event Stream Processing, 이하 ESP)'이 있는데 이는 '스트림 프로세싱'과 동일한 의미로 사용됩니다. 스트리밍 데이터는 복수의 데이터 소스(Data Source)로부터 연속적으로 생성되는 데이터 레코드로 대부분 KB 단위 크기입니다. 시냇물이 흐르듯 데이터가 연속해서 계속 흘러가기 때문에 처리할 수 있는 기회가 한정되고 처리할 수 없는 데이터는 버려질 수도 있습니다. 또한 시간이 지나면서 모델링 대상의 통계적 특성이 달라집니다. 스트림 프로세싱은 스트리밍 데이터가 레코드나 정의된 단위에 따라 순차적으로 처리되는 것을 의미합니다. 이때 처리 과정은 단순 수집에서부터 합계·평균 계산과 같은 집계, 패턴에 기반한 예측 분석 및 데이터 형식을 변환하거나 다른 데이터 소스와 결합 등을 수반합니다.
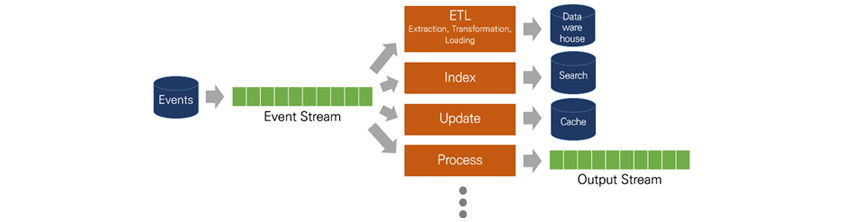 [그림 2] 스트림 프로세싱 개요
[그림 2] 스트림 프로세싱 개요
한편, 콤플렉스 이벤트 프로세싱(Complex Event Processing, 이하 CEP)은 스트림 프로세싱과 유사하지만 분산 환경에서 발생하는 이벤트의 패턴을 분석한다는 점에서 차이가 있습니다.
| 종류 | 목적 | 특징 |
|---|---|---|
| ESP | • 지속적으로 변화하는 이벤트를 빠르게 분석 • 예) 마켓 데이터 분석을 통한 알고리즘 트레이딩 |
• 1990년대 DBMS 관련 회사를 중심으로 실시간 데이터 분석 목적으로 시작 |
| CEP | • 다양한 이벤트로부터 패턴을 분석 • 예) 비즈니스 활동 모니터링(BAM) |
• 1980년대 분산 환경의 다양한 시스템에서 발생하는 이벤트 분석 목적으로 시작 |
앞서 언급한 바와 같이 스트림 프로세싱은 흔히 일괄처리 작업과 비교되거나 대안으로 제시되곤 합니다. 하지만 스트림 프로세싱의 활성화가 모든 일괄처리 작업을 대체하는 것을 의미하지는 않습니다. 일괄처리는 대규모 정적 데이터 세트를 대상으로 작업하는 경우에 알맞으며, 스트림 프로세싱은 동적으로 흘러가는 데이터 처리에 적합합니다. 따라서 [표 2]와 같이 환경 특성을 고려하여 아키텍처를 구성해야 합니다. 두 방식은 상호 보완적으로 사용되며 이들을 결합한 하이브리드 모델도 존재합니다. 예를 들면, 실시간 데이터를 스트림 프로세싱으로 처리한 후 누적된 데이터를 일괄처리로 작업하는 경우를 들 수 있습니다.
| 기준 | 일괄처리 | 스트림 프로세싱 |
|---|---|---|
| 처리 방식 | • 일정기간 단위로 수집하여 한 번에 처리 | • 연속된 데이터를 하나씩 처리 |
| 처리량 | • 대규모 데이터 단위 | • 주로 소량의 레코드 단위 |
| 속도 | • 수분~시간의 지연시간 | • (준)실시간 |
| 사용환경 | • 복잡한 분석이 요구되는 환경 • 데이터 처리량이 많은 환경 • 데이터를 스트림으로 전달할 수 없는 레거시 시스템 환경 |
• 실시간 처리 및 분석 정보가 요구되는 환경 • 고급 메시징 |
| 사용 예 | • 급여 및 청구 시스템 | • 은행 ATM • 부정행위 탐지 및 모니터링 시스템 • SNS 데이터 분석 |
이와 같은 스트림 프로세싱의 특성은 이벤트 처리 보장, 내결함성(Fault Tolerance) 및 상태 관리 등을 통하여 지원됩니다. 이벤트 처리 보장은 분산 데이터 파이프라인에서 데이터를 전달하는 방법으로써 [표 3]과 같이 At-least-once, At-most-once, Exactly-once의 3가지로 나눌 수 있습니다. Exactly-once가 가장 신뢰할 수 있는 방법이지만, 성능 부하로 인한 비용을 고려하여 적절한 방법을 선택해야 합니다.
| 방법 | 설명 |
|---|---|
| At-least-once | • 최소 한 번의 전달 보장 • 데이터 전송 후 전달 완료가 확인되지 않아 타임아웃되면 재전송 • 데이터가 중복으로 수신되어도 무방한 경우에 사용 |
| At-most-once | • 한 번의 전송만 수행 • 지연이나 유실이 발생해도 데이터를 재전송하지 않음 • 데이터를 수신하지 않아도 무방한 경우에 사용 |
| Exactly-once | • 정확하게 한 번의 전달만 보장 |
내결함성은 장애가 발생하면 복구하여 처리 시점부터 재개할 수 있는 기능입니다. 일례로 플링크의 경우 이벤트 스트림이 메모리에 적재되기 때문에 시스템이 갑작스럽게 중단되면 처리 중이던 데이터의 복구가 어려울 수 있습니다. 이를 방지하기 위하여 세이브 포인트(Save Point) 기능으로 현재 메모리에 적재된 내용의 스냅샷을 영구 저장소에 백업하는 기능을 지원합니다.
이벤트 처리는 입력 데이터의 가공과 분석을 수반하기도 하므로 현재 상태를 관리하고 갱신할 수 있어야 합니다. 이를 위해 실시간으로 유입되는 데이터에 워터마크나 유한 크기로 분할해 처리하는 윈도우 개념이 적용되기도 합니다.
스트림 프로세싱은 구현하는 방법에 따라 [표 4]와 같이 네이티브 스트림(Native Stream)과 소규모 일괄처리(Micro Batch) 형태로 구분할 수 있습니다. 네이티브 스트림은 지속적으로 유입되는 새로운 데이터(Unbounded Data)를 처리하기 위해 별도의 프로세서를 두기 때문에 상태 관리가 용이합니다. 이 프로세서는 프레임워크에 따라 오퍼레이터(Operator), 태스크(Task) 등으로 불리며 데이터의 가공 처리를 수행할 수 있습니다. 소규모 일괄처리는 일반적인 일괄처리와 비교하여 작업 수행주기의 기간임계치가 짧습니다. 네이티브 스트림과 비교하면 상태 관리가 어렵지만 내결함성 면에서 이점이 있습니다.
| 구현 방식 | 특성 | 대표 제품 |
|---|---|---|
| 네이티브 스트림 | • 지연시간 최소 • 이벤트 처리 보장 방식에 따라 내결함성 유지가 어려움 |
• 플링크(Flink) • 카프카 스트림즈(Kafka Streams) |
| 소규모 일괄처리 | • 네이티브 스트림 대비 지연시간 발생 | • 스파크(Spark) |
스트림 프로세서에는 어떤 것들이 있나요?
대표적인 스트림 프로세싱 제품에는 스파크(Spark), 스톰(Storm), 카프카 스트림즈(Kafka Streams) 그리고 플링크(Flink) 등이 있습니다. 또한 스프링(Spring) 진영의 스프링 클라우드 데이터 플로우(Spring Cloud Data Flow)를 비롯하여 아마존(Amazon), 구글(Google)과 같은 클라우드 서비스 공급업체도 각각 키네시스(Amazon Kinesis), 클라우드 데이터 플로우(Google Cloud Dataflow)라는 브랜드로 스트림 프로세싱 기능을 제공합니다. 주요 스트림 프로세싱 프레임워크의 특징은 다음과 같습니다.
아파치 스파크(Apache Spark)
UC버클리대학교에서 개발하였으며 현재 아파치 재단에서 관리하고 있습니다. 스트림을 소규모 일괄처리하는 형태이기 때문에 지연(Latency)이 발생하지만 가장 활성화되어 있는 스트림 프로세서 중 하나로 Exactly-once의 이벤트 처리를 보장합니다. 사용이 어렵지만 고급 분석 기능을 제공합니다.
아파치 스톰(Apache Storm)
초창기 오픈소스 스트림 프로세싱 프레임워크의 하나로 트위터(Twitter, Inc.)에 의해 오픈소스화되었습니다. 지연이 매우 짧고 복잡하지 않은 스트림에 적합합니다. 하지만, 소규모 일괄처리 스트림 모델인 스톰 트라이던트(Storm Trident)를 사용하지 않으면 At-least-once의 이벤트 처리를 보장합니다. 또한 상태 관리가 지원되지 않아 집계, 윈도우, 워터마크 등을 사용할 수 없기 때문에 고급 분석에 제약이 있습니다.
아파치 삼자(Apache Samza)
삼자는 카프카를 만든 링크드인(LinkedIn Corp.)에서 개발한 아파치 프로젝트로 카프카와 연동하는 환경에 적합한 스트림 프로세서입니다. 하지만 카프카와 밀접하게 연관되어 있는 만큼 다른 제품과 연동이 어렵고 At-least-once 수준의 이벤트 처리를 보장합니다. 이어서 설명할 카프카 스트림즈의 확장 버전으로 볼 수 있습니다.
아파치 카프카 스트림즈(Apache Kafka Streams)
카프카는 링크드인에서 개발해 아파치 오픈소스로 등록되었습니다. 이후 링크드인에서 카프카를 개발한 몇몇 엔지니어들이 컨플루언트(Confluent, Inc.)를 창립해 지금까지 카프카를 발전시키고 있습니다. 카프카 스트림즈는 카프카 기능의 일부로 스트림 프로세싱을 위한 경량 라이브러리입니다. 스파크나 플링크보다 강력하진 않지만 Exactly-once의 이벤트 처리를 보장합니다. 다른 스트림 프로세서들이 실행 프레임워크인 것에 비해 사용이 쉽다는 이점이 있습니다.
아파치 플링크(Apache Flink)
플링크(Flink)는 독일어로 민첩함을 뜻하는 단어로 베를린 TU대학교에서 시작된 아파치 프로젝트입니다. Exactly-once의 이벤트 처리를 보장하는 네이티브 스트림 방식으로, 지연 발생이 적고 처리량은 높으며 비교적 사용하기 쉬운 이점이 있습니다. 일괄처리 기능도 제공하지만 스트림 프로세싱을 목적으로 주로 사용됩니다.
이 외에 구글 클라우드 데이터플로우(Google Cloud Dataflow)에 사용되는 아파치 빔(Apache Beam)과 같은 데이터 프로세싱 파이프라인 정의용 모델을 비롯해 아카 스트림즈(Akka Streams), 아파치 나이파이(Apache NiFi), 아파치 에이펙스(Apache Apex), 아파치 펄사(Apache Pulsar), 아파치 트위터 헤론(Apache Twitter Heron) 등 수십여 종의 스트림 프로세싱 제품이 시중에 나와 있습니다.
부상하는 플링크
아파치 플링크는 2011년 첫 릴리즈된 비교적 오래된 프레임워크입니다. 개발 초기에는 많은 관심을 끌지 못했으나 빠르게 성장해 현재 주요 글로벌 대기업들이 사용하는 스트림 프로세서로 자리 잡았습니다. 우버(Uber Technologies Inc.)는 전 세계에서 수집되는 데이터를 분석할 플랫폼으로 구축한 AthenaX에 플링크를 사용하였습니다. 세계 최대 전자상거래 업체인 알리바바(Alibaba Group Holding Limited)는 플링크를 기반으로 한 블링크(Blink)를 개발하여 실시간 검색순위 최적화를 수행하고 있습니다. 또한 AWS의 스트림 프로세싱을 위한 완전 관리형 클라우드 서비스인 키네시스 데이터 애널리틱스(Kinesis Data Analytics)도 플링크를 사용하고 있습니다.
이들 업체는 왜 플링크를 채택했을까요? 우버는 초기에 스톰을 이용하였지만 고급 기능에 대한 요구가 커짐에 따라 자사 플랫폼에 플링크를 적용했습니다. 알리바바는 데이터가 폭발적으로 증가하면서 일괄처리와 스트림 프로세싱이 모두 필요하였고 그 해답으로 스트림 프로세싱을 기반으로 일괄처리까지 가능한 플링크를 채택했습니다.
스트림 프로세싱의 기존 선두주자는 스파크를 꼽을 수 있습니다. 스파크는 플링크보다 높은 프로젝트 성숙도와 점유율을 보여왔습니다. 하지만 플링크는 스파크 다음 세대의 빅데이터 분석 프레임워크로서 짧은 지연시간 내에 스트림 데이터를 처리하면서도 강력한 상태 관리가 필요한 경우에 최적의 선택이 될 수 있습니다. 플링크의 네이티브 스트림과 스파크의 소규모 일괄처리로 인해 발생하는 지연시간은 데이터가 적은 환경에서는 그 차이가 미미할 수 있지만 하루에 1조 개 이상의 데이터가 생성되는 환경이라면 결코 무시할 수 없을 것이기 때문입니다.
플링크가 다른 프레임워크와 차별화되는 주요 특징은 다음과 같습니다.
- 네이티브 스트림(Native Stream): 플링크는 일괄처리도 지원하지만 스트림 프로세싱을 주목적으로 사용합니다. 경량의 분산 스냅샷을 구현하여 오버헤드는 낮으면서도 Exactly-once의 이벤트 처리를 보장할 수 있습니다.
- 인메모리(In-Memory): 자바 애플리케이션으로 JVM(Java Virtual Machine)에서 실행되지만 JVM GC(Garbage Collector)에 전적으로 의존하지 않습니다. 대신 커스텀 메모리 매니저를 구현하여 안정적인 메모리 사용량을 유지하면서 성능 향상을 꾀하고 있습니다.
- 낮은 지연과 높은 처리량(Throughput): 경쟁 제품에 비하여 지연과 처리량에서 우수한 성능을 보입니다. 플링크는 데이터를 처리하는 과정에서 변경된 부분만 재처리하도록 설정하여 처리 속도를 더 높일 수도 있습니다.
- 손쉬운 설정과 사용 그리고 강력한 부가 기능: 스파크는 파라미터 설정이 복잡하지만 플링크는 별다른 설정 없이 사용할 수 있습니다. 입력되는 이벤트 스트림에 개별로 접근할 수 있고, 강력한 윈도우 연산자를 사용하여 분석을 수행할 수 있습니다. [그림 3]과 같이 고급 분석용 API부터 상세한 제어가 가능해지는 상태 저장 이벤트 기반 애플리케이션 수준까지 계층에 따른 API를 제공합니다.
 [그림 3] 플링크의 계층화된 API
[그림 3] 플링크의 계층화된 API
플링크에 한 걸음 다가서기
플링크에서 데이터는 소스(Source)로 시작해 싱크(Sink)로 끝납니다. 데이터가 입력되어 처리가 완료되기까지 각 단계는 스트림으로 이동하고 오퍼레이터에 의하여 데이터가 처리됩니다. 소스는 데이터 입력을 정의하는 단계로 원천시스템의 로그, 클릭 이벤트, IoT 장치 등에서 발생하는 데이터를 실시간 이벤트 스트림이나 데이터베이스, 파일, 키-밸류 스토어(Key-Value Store) 따위의 매체로부터 수신합니다.
 [그림 4] 플링크의 데이터 흐름
[그림 4] 플링크의 데이터 흐름
트랜스포메이션(Transformation)은 데이터를 가공하는 작업입니다. 스트림 내의 특정 값에 가중치를 주거나 분석하여 새로운 스트림을 형성할 수도 있고 특정 키(Key) 값 기반 스트림을 처리할 수도 있습니다. 스트림 처리 시스템의 기본 개념인 윈도우(Window) 관련 기능도 제공합니다. 윈도우는 [그림 5]와 같이 제한이 없는(Unbounded) 데이터 흐름에서 집계 및 가공 처리 수행을 위해 유한한(Bounded) 단위로 구분하는 개념입니다.
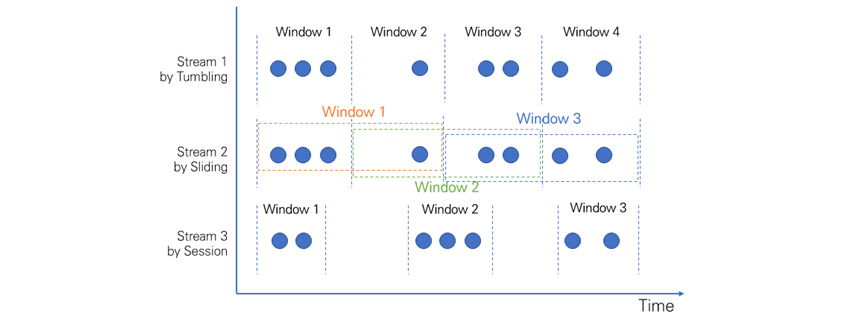 [그림 5] 스트림 내의 윈도우
[그림 5] 스트림 내의 윈도우
플링크는 윈도우 할당 방식으로 텀블링(Tumbling)·슬라이딩(Sliding)·세션(Session)·글로벌(Global) 윈도우를 지원합니다. 각 방식을 간략하게 살펴보면 [표 5]와 같습니다.
| 윈도우 | 설명 |
|---|---|
| Tumbling | • 고정된 단위시간에 따라 윈도우를 나누어 데이터 중복 없음 • 지정된 기간을 윈도우 크기로 하여 각 윈도우 안의 데이터 처리 |
| Sliding | • Tumbling의 윈도우 크기에 slide 기간만큼 + or - 중복 허용 • 특정기간 내의 평균값 처리 등을 목적으로 할 때 |
| Session | • 윈도우의 크기가 일정하지 않음 • 임계치 이상의 session gap 간격을 갖는 경우 다른 윈도우로 구분 |
| Global | • 하나의 동일한 키 단위나 윈도우로 모든 데이터 처리 |
마지막으로 싱크는 처리한 스트림을 출력·저장하는 단계입니다. 플링크는 계산의 결과 값이 필요할 때까지 계산을 늦추어 불필요한 연산을 피하는 느긋한 계산법(Lazy Evaluation) 방식을 채택하고 있습니다. 따라서 싱크 단계를 수행함에 따라 처리 결과를 소비할 애플리케이션, 이벤트 로그 또는 데이터베이스 등으로 출력하게 됩니다. 플링크는 위와 같은 데이터 흐름 중에 체크포인트(Checkpoint)를 설정해 내결함성을 높이고 Exactly-once를 보장합니다. 아울러 이벤트가 발생한 시간(Event Time)과 처리된 시간(Processing Time)을 구분하고 워터마크를 활용하여 지연 데이터를 처리함으로써 신뢰성과 고성능을 지원하고 있습니다.
마치며
빅데이터가 급부상하면서 스트림 프로세싱 분야도 꾸준히 성장하고 있습니다. 특히, 스트림 프로세싱 프레임워크는 데이터 처리 과정에서 각 애플리케이션이 자신의 데이터와 상태를 관리할 수 있기 때문에 현재 많은 인기를 끌고 있는 MSA(Microservices Architecture) 환경에도 적합합니다.
스트림 프로세싱을 수행할 수 있는 제품은 수십여 가지에 이르지만 각 제품마다 분명한 특성이 존재하므로 사용 환경을 고려한 선택이 필요합니다. 예를 들어 IoT와 같은 분야에서 단순한 알림 시스템을 구축하는 경우에는 카프카 스트림즈가 적합한 반면 스트림 데이터의 집계, 통합 및 가공과 같은 고급 기능을 활용한 분석이 필요할 때에는 플링크나 스파크를 고려하는 것이 좋습니다. 플링크와 스파크는 유사하지만 각각 스트림 프로세싱과 소규모 일괄처리에 기반한 특성을 감안한 선택이 필요합니다. 필요에 따라 2개 이상의 프레임워크를 활용하여 최적의 데이터 파이프라인을 구성하는 것도 방법입니다.
플링크는 수요가 지속적으로 증가하고 있는 프레임워크로 타제품에 비해 실시간 처리와 상태 관리를 통한 고급 기능을 제공한다는 강점이 있습니다. 따라서 스트림 프로세싱을 기반으로 하는 환경에서 일괄처리를 비롯해 스트림 데이터의 복잡한 처리가 필요하다면 플링크를 고려해보시길 바랍니다.
References
[1] Big data issues in smart grid systems, IEEE 23 International Conference on Renewable Energy Research and Applications (ICRERA), 2016년
[2] https://hazelcast.com/blog/what-is-stream-processing-and-why-is-it-important-to-your-business/
[3] https://hazelcast.com/glossary/event-stream-processing/
[4] https://www.businesswire.com/news/home/20210331005495/en/Global-Event-Stream-Processing-Market-2021-to-2026---Growth-Trends-COVID-19-Impact-and-Forecasts---ResearchAndMarkets.com
[5] https://ably.com/blog/a-look-at-8-top-stream-processing-platforms
[6] https://spark.apache.org/docs/latest/streaming-programming-guide.html
[7] https://storm.apache.org/about/integrates.html
[8] https://samza.apache.org/learn/documentation/latest/architecture/architecture-overview.html
[9] https://www.confluent.io/blog/introducing-kafka-streams-stream-processing-made-simple/
[10] https://www.confluent.io/blog/enabling-exactly-once-kafka-streams/
[11] https://flink.apache.org/
[12] https://eng.uber.com/athenax/
[13] https://www.alibabacloud.com/blog/why-did-alibaba-choose-apache-flink-anyway_595190
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

에스코어㈜ 소프트웨어사업부 컨버전스SW그룹
컨버전스SW그룹에서 클라우드 플랫폼 관련 연구 개발을 담당하고 있습니다.