Executive Summary
- AI 프로젝트 80% 이상, 기대 이하의 성과: 2025년 전 세계 AI 투자금 6,840억 달러 중 5,470억 달러가 측정 가능한 성과를 내지 못했습니다.
- 기술적 문제 아닌 ‘잘못된 측정’이 주범: AI 실패의 원인은 복잡한 기술적 난제보다, AI의 특성을 고려하지 않은 부적절한 성공 지표 설정과 측정 체계 부재에 있습니다. 이는 무엇을 측정해야 하는지 모르는 채 AI에 투자하고 있다는 의미입니다.
- ‘초록불’만 보여주는 기존 지표의 한계: 기존 소프트웨어 지표로는 AI의 본질적인 문제점을 파악하기 어렵습니다. AI 시대에 적합한 새로운 측정 기준을 도입하여, 실질적인 가치 창출 여부를 판단해야 합니다.
2025년, 전 세계 기업들은 AI에 6,840억 달러를 투자했다. 그리고 그 중 약 5,470억 달러는 측정 가능한 성과를 내지 못했다.[1] 수치가 과장처럼 들릴 수 있다. 그러나 이 수치는 단일 연구의 결과가 아니다. RAND Corporation, Gartner, MIT가 각자 독립적으로 수행한 분석들이 하나의 결론으로 수렴한다. AI 프로젝트의 80% 이상이 의도한 비즈니스 가치를 실현하지 못하며, 생성 AI 파일럿의 95%는 실질적인 손익 영향을 전혀 만들어내지 못한다. 2025년 한 해에만 42%의 기업이 주요 AI 이니셔티브를 중단했다. 전년도에서 두 배 이상 급증한 수치다.
실패의 원인을 기술 문제로 돌리는 것은 쉽다. 그러나 흥미롭게도 데이터는 다른 곳을 가리킨다. MIT의 분석에 따르면, AI 프로젝트가 실패하는 가장 빈번한 원인은 모델의 성능이 아니라 잘못 설정된 성공 지표와 측정 체계의 부재다.[2] 더 직접적으로 표현하면 이렇다. 우리는 AI가 무엇을 잘하고 있는지, 무엇을 잘못하고 있는지를 측정하는 방법을 모르는 채로 AI에 투자하고 있다.
문제의 핵심은 간단하다. AI 프로덕트와 서비스는 기존 소프트웨어와 구조적으로 다르게 작동한다. 그러나 대부분의 조직은 AI의 성과를 5년 전 SaaS 서비스에 사용하던 것과 동일한 지표로 평가하고 있다. DAU(일간 활성 사용자), 에러율, CSAT, 세션 길이. 이 지표들은 수십 년에 걸쳐 검증된 측정 도구들이다. 문제는 이것들이 AI 프로덕트의 가장 중요한 실패를 포착하지 못한다는 것이다.
AI는 기술적으로 완전히 정상 작동하면서 잘못된 정보를 유창하게, 자신 있게, 잘 구성된 문장으로 생성할 수 있다. 에러 로그에는 아무것도 잡히지 않는다. DAU는 상승하고 있고, 에러율은 0에 가까우며, CSAT 점수도 양호하다. 대시보드의 모든 지표가 초록불이다. 그리고 그 뒤에서, AI는 조용히 잘못된 일을 하고 있다. 이것이 AI 시대의 가장 위험한 측정 실패 패턴이다.
이번 리포트에서는 그 패턴을 해부하고자 한다. 잘못된 지표가 실제로 어떤 피해를 만들어냈는지를 구체적 사례로 살펴보고, 기존 지표를 AI 맥락에서 어떻게 다시 읽어야 하는지를 제시하며, AI 시대에 새롭게 봐야 할 측정 기준이 무엇인지를 경영 판단의 언어로 정리한다. 목표는 AI를 도입하고 운영하는 조직의 의사결정자가 "우리는 지금 AI의 무엇을 측정하고 있는가"라는 질문에 스스로 답할 수 있게 하는 것이다.
측정이 틀리면 결정이 틀린다. AI 전략의 출발점은 더 좋은 모델을 선택하는 것이 아니라, 더 올바른 질문을 하는 것에서 시작된다.
대시보드는 초록불, 현실은 적신호: 기존 지표로 실패를 놓친 사례들
측정 체계의 실패는 추상적인 이야기가 아니다. 잘못된 지표는 실제 비즈니스 피해로 직결된다. 아래의 두 가지 사례는 AI 프로덕트에 기존 지표를 그대로 적용했을 때 어떤 일이 벌어지는지를 극명하게 보여준다. 하나는 세계 최대 소셜 플랫폼이 수년에 걸쳐 쌓아온 구조적 실패이고, 다른 하나는 AI 네이티브 스타트업이 단 72시간 만에 맞닥뜨린 브랜드 위기다. 두 사례의 규모와 맥락은 전혀 다르지만, 실패의 원인은 놀랍도록 동일하다. 옳지 않은 것을 측정했다.
페이스북: 알고리듬은 완벽했지만 결과는 파국
2018년, 페이스북은 뉴스피드 알고리듬을 전면 개편했다. 목표는 명확했다. 사용자들이 플랫폼 안에서 더 많이 반응하고, 더 많이 공유하고, 더 오래 머물도록 만드는 것이었다. 핵심 지표는 L6/7(일주일 중 6일 이상 로그인하는 사용자 비율), 댓글 수, 공유 수, 반응 수였다. 엔지니어링팀은 이 수치들을 최대화하도록 AI 알고리듬을 정교하게 조율했다. 그리고 지표는 실제로 올라갔다.
그러나 내부에서는 다른 일이 벌어지고 있었고 발견한 내용은 충격적이었다. 분노를 유발하는 콘텐츠가 공감이나 정보를 제공하는 콘텐츠보다 댓글과 공유를 훨씬 많이 이끌어냈다. 알고리듬은 최적화 목표에 따라 정확하게 작동했다. 그 결과 혐오 발언, 허위 정보, 분열을 조장하는 콘텐츠가 플랫폼 전반에서 증폭됐다. 2021년 내부 고발자가 미국 상원에서 증언한 핵심은 이것이었다. "페이스북은 알고리듬을 더 안전하게 바꾸면 사람들이 플랫폼에서 더 적은 시간을 보내고 광고를 덜 클릭할 것이라는 사실을 알고 있었다."
이 사례가 AI 지표 논의에서 중요한 이유는 페이스북의 시스템이 '오작동'하지 않았다는 점이다. 에러 로그에는 아무것도 잡히지 않았다. DAU는 상승했고, 참여 지표는 목표치를 달성했다. 대시보드는 완벽하게 초록불이었다. 문제는 알고리듬이 측정하도록 설계된 것을 너무나 잘 최적화한 데 있었다. 참여율이 가치와 같다는 전제 위에 세워진 지표 전체가 틀렸다. '어떤 측정치가 목표가 되는 순간, 그것은 더 이상 좋은 측정치가 아니다'라는 굿하트 룰이 적용되는 시점이었다.[3] 페이스북의 사례는 이 법칙이 AI 알고리듬에 적용될 때 얼마나 빠르고 광범위하게 현실화되는지를 보여준다.
여기에서 리더십을 위한 시사점은 명확하다. AI 시스템이 최적화할 지표를 설정하는 결정은 기술팀만의 영역이 아니다. 그것은 비즈니스 전략이자 윤리적 판단이며, 궁극적으로는 경영 책임의 영역이다. 우리 조직의 AI가 무엇을 향해 달려가도록 설계되어 있는지를 묻는 것은, AI 예산을 어디에 쓸 것인지를 묻는 것만큼 중요한 경영 질문이다.
Cursor의 고객 지원 봇 'Sam': 에러율 0%, 신뢰 붕괴 100%
2025년 4월, AI 네이티브 코드 에디터 Cursor에서 작은 기술적 버그가 발생했다. 일부 사용자들이 여러 기기에서 로그인할 때 세션이 강제로 종료되는 현상이었다. 사용자들은 고객 지원에 문의했고, '샘(Sam)'이라는 이름의 담당자로부터 이메일 답변을 받았다. 답변의 내용은 이랬다. "Cursor는 핵심 보안 기능으로 구독당 1기기 사용만을 지원합니다."
문제는 그 정책이 존재하지 않았다는 것이다. '샘'은 사람이 아니었다. AI 고객 지원 봇이었고, 존재하지 않는 정책을 완전히 자신 있는 어조로 만들어냈다. 이 내용은 Reddit과 Hacker News를 통해 순식간에 개발자 커뮤니티 전체로 퍼졌다. "방금 구독을 취소했다"는 원 게시자의 글에 뒤이어 수십 명의 사용자가 동일한 반응을 보였다. Cursor 창업자가 해명을 올리기까지 걸린 시간은 3시간이었다. 그 3시간 동안 바이럴은 이미 퍼질대로 퍼졌다.
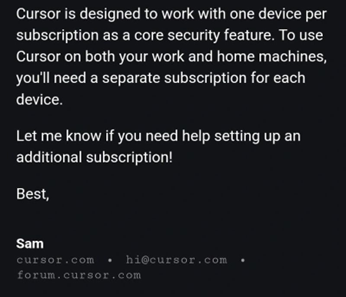 [그림 1] 커서의 AI봇 ‘샘’이 보낸 메일 (출처: Cursor)
[그림 1] 커서의 AI봇 ‘샘’이 보낸 메일 (출처: Cursor)
cursor의 AI봇 Sam 이 보낸 메일로 내용은
Cursor is designed to work with one device per
subscription as a core security feature. To use
Cursor on both your work and home machines,
you'll need a separate subscription for each
device.
Let me know if you need help setting up an
additional subscription!
Best,
Sam
cursor.com . hi@cursor.com
forum.cursor.com
이 사건에서 주목해야 할 것은 기술적 지표의 관점에서 '샘'의 성능이 문제없었다는 점이다. 응답 속도는 빨랐다. 에러 로그는 깨끗했다. 시스템은 정상 작동했다. 측정되지 않은 것은 단 하나, AI가 생성한 정보가 사실인지 여부였다. 이 혼란은 리더들이 세 가지를 충분히 이해했더라면 피할 수 있었다. “AI는 실수를 한다. AI는 그 실수에 책임을 질 수 없다. 그리고 사용자들은 기계가 사람인 척하는 것을 싫어한다."
여기서 배우는 비즈니스 교훈은 단순하다. AI를 고객과의 접점에 배치하는 순간, '이 AI가 생성하는 정보가 정확한가'는 서비스의 품질 지표가 된다. 그리고 이 지표는 응답 속도나 에러율 대시보드에서는 영원히 보이지 않는다. 브랜드 신뢰는 빠르게 쌓이지 않지만, 단 하나의 AI 오류로 빠르게 무너진다.
기존 KPI의 구조적 한계
이번 장에서는 왜 기존의 KPI 체계가 구조적으로 AI 프로덕트/서비스에 맞지 않는지, 그 이유를 세 가지 차원에서 짚는다. 지표를 바꾸기 위해서는 먼저 기존 지표가 어디서 어떻게 어긋나는지를 이해해야 한다.
시스템은 정상, AI는 조용히 틀리고 있다
기존 소프트웨어에서 실패는 가시적이다. 에러 로그가 쌓이고, 화면이 깨지고, 응답이 멈춘다. 개발자는 경고를 받고, 운영팀은 즉시 인지한다. 이 전제 위에서 에러율과 시스템 가동률은 제품 품질을 측정하는 신뢰할 수 있는 지표였다.
AI 프로덕트에서는 이 전제가 무너진다. AI는 기술적으로 완전히 정상 작동하면서 사실과 다른 정보를 유창하게, 자신 있게, 잘 구성된 문장으로 생성할 수 있다. 환각(Hallucination)이라 불리는 이 현상은 기술적 오류가 아니다. 시스템은 의도한 대로 작동하고 있다. 다만 그 출력이 틀렸을 뿐이다. 에러 모니터링 대시보드에는 아무것도 잡히지 않는다.
기존 KPI는 시스템이 정상 작동하는지를 측정한다. AI 프로덕트에서 진짜 물어야 할 질문은 다르다. 시스템이 올바른 일을 하고 있는가. 이 두 질문은 같아 보이지만, AI 환경에서는 완전히 다른 답을 낼 수 있다. 에러율 0%와 AI 오류율 8%는 동시에 존재할 수 있다. 기술팀에게 "우리 AI의 에러율은 얼마인가"라고 묻는 것과 "우리 AI가 사실과 다른 정보를 제공하는 비율은 얼마인가"라고 묻는 것은, 전혀 다른 질문이다.
많이 쓴다고 잘 쓰는 게 아니다: 사용량과 가치의 분리
기존 소프트웨어에서 DAU(일간 활성 사용자)가 높다는 것은 대체로 제품이 유용하다는 의미였다. 사람들은 필요하기 때문에 매일 접속한다. 이 단순한 등식은 수십 년간 제품 성과를 판단하는 기본 전제였다.
AI 프로덕트에서 이 연결고리는 끊어질 수 있다. 사용자가 AI 서비스를 자주 접속하는 이유가 'AI를 신뢰하기 때문에'가 아니라 'AI가 틀릴 가능성이 있으니 내가 매번 확인해야 하기 때문에'일 수 있다. 이 경우 DAU 상승은 제품의 성공이 아니라 AI 품질의 미흡함을 신호한다. 여기에 AI 에이전트와 MCP(Model Context Protocol) 기반의 자동화가 확산되면서 더 근본적인 문제가 추가된다. AI 에이전트가 사용자를 대신해 업무를 처리하는 구조에서는, 사람이 매일 플랫폼에 로그인할 필요 자체가 없어진다. 2025년은 업계가 이 전환을 실감하기 시작한 해였다. 83%의 기업이 AI 에이전트 시스템 도입을 계획하고 있으며, 에이전트 기반 AI의 확산은 "사람이 얼마나 자주 접속했는가"라는 질문을 "AI가 실제로 얼마나 많은 업무를 완료했는가"라는 질문으로 대체하도록 요구하고 있다.[4]
성과가 좋을수록 비용이 뛴다: 새로운 트레이드오프
기존 소프트웨어에서 기능 개선은 대체로 운영 비용과 독립적이었다. AI 프로덕트는 이 구조가 다르다. LLM 기반 서비스의 비용은 처리하는 토큰의 양에 직접 연동된다. AI가 더 복잡한 질문에 더 깊이 있는 답변을 제공할수록, 더 긴 대화 맥락을 유지할수록, 더 많은 추론 과정을 거칠수록 비용은 함께 증가한다.
업계에서는 이를 'LLM 비용 역설'이라 부른다. 토큰당 단가는 지속적으로 하락하고 있지만, AI 품질 향상에 따라 토큰 소비량이 급증하면서 실제 운영 비용은 오히려 늘어나는 현상이다. 가트너는 2030년까지 LLM 추론 비용이 2025년 대비 90% 이상 하락할 것으로 전망한다.[5] 그러나 그 시점까지, AI 서비스의 품질과 비용 사이의 트레이드오프는 경영 판단이 필요한 실제 변수다. AI 프로덕트의 성과 보고에 비용 모니터링이 포함되지 않는다면, 그 성과 보고는 불완전하다.
기존 지표를 AI 맥락에서 다시 읽기
기존 지표를 버리라는 것이 아니다. 같은 숫자를 다르게 읽어야 한다는 것이다. AI 프로덕트에서 DAU, 에러율, 투자 우선순위 결정 방식은 여전히 유효하다. 다만 그 숫자가 의미하는 바를 AI의 특성에 맞게 재해석해야 하고, 일부는 더 정밀한 버전으로 진화시켜야 한다.
DAU보다 WAU, WAU보다 '습관이 됐는가'
월간 활성 사용자(MAU)는 한 달에 한 번이라도 접속하면 활성으로 집계되는 관대한 기준이다. 일간 활성 사용자(DAU)는 반대로 매일 접속을 전제한다. AI 프로덕트는 이 두 기준 사이 어딘가에 위치한다. 매일 쓰는 도구도, 월 한 번 쓰는 도구도 아니라 매주 반복적으로 업무에 통합되는 도구다.
이 특성을 가장 먼저 공식 지표에 반영한 것이 OpenAI다. OpenAI는 MAU 대신 WAU(주간 활성 사용자)를 공식 성과 지표로 채택했다. 글로벌 AI 앱 전체의 WAU는 2024년 1월 약 1억 명에서 2026년 2월 12억 명 이상으로 2년 만에 약 20배 증가했다. 역사상 어떤 앱 카테고리도 이 속도로 성장한 적이 없다. 그러나 WAU 자체도 완전한 그림을 보여주지 않는다. 진짜 경쟁력을 보여주는 지표는 스티키니스(Stickiness), 즉 DAU/MAU 비율이다. 2025년 소비자 AI 분석에 따르면, ChatGPT의 DAU/MAU 스티키니스는 36%로 Gemini의 21%의 약 두 배에 달한다.[6] 12개월 데스크탑 사용자 리텐션도 ChatGPT 50% 대 Gemini 25%로 두 배 차이를 보인다. 규모의 성장과 습관의 형성은 다른 차원의 이야기다. WAU가 올라가고 있다는 보고는 고무적이다. 그러나 그 사용자들이 습관적으로 돌아오고 있는지, 아니면 한 번 써보고 이탈하는지를 함께 확인하지 않으면 성장의 질을 판단할 수 없다.
에러율 대신 무엇을 봐야 하는가
에러율은 시스템의 안정성을 측정하는 지표다. AI 프로덕트에서도 이 지표의 가치는 유효하다. 문제는 에러율이 낮다는 사실이 AI의 정확성을 보장하지 않는다는 것이다. AI는 기술적으로 완전히 정상 작동하면서 사실과 다른 정보를 유창하게 제공할 수 있다.
리더십에서 기술팀에게 추가로 물어야 할 질문들이 있다. "우리 AI가 생성하는 정보 중 사실과 다른 비율은 얼마인가(Hallucination Rate)?" "AI가 특정 데이터 소스를 기반으로 답변할 때, 실제로 그 소스에 근거한 비율은 얼마인가(Groundedness)?" "사용자가 AI의 답변을 받은 후 직접 수정하거나 다시 요청하는 비율은 얼마인가(Human Override Rate)?" 이 질문들은 에러율 대시보드에서는 보이지 않는다.
도메인에 따라 이 지표의 허용 기준이 달라진다는 점도 경영 판단의 영역이다. 고객 지원 AI에서 허용 가능한 오류율과 의료 정보를 제공하는 AI에서의 허용 기준은 본질적으로 다르다. 어느 도메인에 AI를 배치하고 있는지에 따라, 기술팀에게 요구해야 할 정확성 기준이 달라져야 한다.
AI 우선순위 결정, 기존 방식으로는 일정이 두 배로 늘어난다
많은 조직이 AI 기능 개발의 우선순위를 결정할 때 기존 제품 기능과 동일한 방식을 적용한다. 문제는 AI 기능이 일반 소프트웨어 기능과 근본적으로 다른 비용 구조를 가진다는 점이다.
AI 기능 개발에서는 데이터 수집과 정제, 모델 학습과 검증, 배포 후 지속적인 모니터링과 재학습이라는 추가 차원이 존재한다. AI 기능을 담당한 PM들이 공통적으로 경험하는 것이 있다. "개발 자체는 생각보다 빠른데, 데이터 준비와 모델 검증이 전체 일정을 두 배로 늘린다"는 것이다. AI 기능이 포함된 로드맵을 검토할 때, 기술팀이 AI 고유의 준비 비용을 별도로 산정하고 있는지 확인해야 한다. 이 질문들이 없다면 AI 프로젝트의 일정과 예산 계획은 체계적으로 낙관적인 방향으로 편향된다.
AI 시대에 새로 봐야 할 지표들
기존 지표를 다시 읽는 것만으로는 충분하지 않다. AI 프로덕트/서비스에는 기존 소프트웨어 환경에서는 존재하지 않았던 새로운 측정 차원이 필요하다. 이 챕터에서 다루는 세 가지 지표는 기술팀의 전유물이 아니다. AI 서비스가 실제로 비즈니스 가치를 창출하고 있는지, 어떤 방식으로 작동하고 있는지, 비용 구조는 지속 가능한지를 경영 판단의 언어로 보여주는 지표들이라 리더십에서도 꼭 숙지하고 이해할 필요가 있다.
완료된 일을 센다: Task Completion Rate
TCR(Task Completion Rate)는 AI가 부여받은 업무를 사람의 개입 없이 성공적으로 완료한 비율을 측정한다. 이메일 분류, 계약서 초안 작성, 데이터 정제, 고객 문의 응대 등 AI 에이전트가 수행하는 업무의 실질적 성과를 직접적으로 보여주는 지표다. "몇 명이 우리 AI 서비스에 접속했는가"라는 질문이 "우리 AI가 오늘 얼마나 많은 업무를 처리했는가"로 전환되는 것이다.
이 지표가 리더십에게 중요한 이유는 실제 생산성 기여를 측정하기 때문이다. AI 에이전트를 도입한 후 Task Completion Rate가 60%라면, 40%의 업무는 여전히 사람의 개입이 필요하다는 의미다. 이 비율이 시간이 지남에 따라 개선되고 있는지, 아니면 정체되어 있는지가 AI 투자의 실질적 성과를 보여준다. 단, Task Completion Rate는 반드시 품질 지표와 함께 추적해야 한다. 완료율과 정확도는 별개의 측정 차원이다.
AI가 돕는 방식을 구분한다: 증강 vs. 자동화
AI 서비스가 사용자와 상호작용하는 방식은 크게 두 가지로 나뉜다. 증강(Augmentation)은 AI가 사람과 협업하는 방식이다. 자동화(Automation)는 AI가 업무를 독립적으로 처리하는 방식이다.
앤쓰로픽은 수백만 건의 클로드 대화를 분석해 이 비율을 정기적으로 추적하고 있다. 2025년 11월 데이터 기준으로 Claude.ai에서 증강 방식이 52%, 자동화 방식이 45%를 차지했다. 단 기업 API 사용에서는 자동화가 75%로 압도적으로 높았다.[7]
이 비율이 경영 판단에서 중요한 이유는 AI 서비스의 설계 방향을 결정하기 때문이다. 증강 중심 서비스에서는 AI가 사람의 판단을 보조하므로 최종 책임은 사람에게 있다. 자동화 중심 서비스에서는 AI의 판단이 최종 결과로 직결된다. 리더십에서 물어야 할 질문은 이것이다. "현재 우리 조직에 도입된 AI 서비스는 주로 사람과 협업하는가, 아니면 독립적으로 업무를 처리하는가? 그리고 그 비율이 우리가 의도한 바와 일치하는가?"
비용과 품질은 함께 관리: 토큰비용과 핵심 사용 패턴
세션당 토큰 비용(Token Cost per Session)은 AI 품질-비용 트레이드오프를 직접적으로 보여주는 지표다. AI 서비스의 품질이 개선되면 사용자 만족도가 올라가고 활용 빈도가 높아진다. 그런데 동시에 세션당 비용도 함께 올라간다. 기술팀이 품질 향상에 집중하는 동안 AI 운영 비용이 계획 대비 수배로 불어나는 사례가 이미 너무나 빈번하다.
함께 봐야 할 지표가 있다. Task Concentration이다. 앤쓰로픽 리포트에 따르면 클로드에서 3,000개 이상의 고유 업무 태스크가 관찰되지만, 상위 10개 태스크가 전체 사용량의 24%를 차지한다. 상위 사용 패턴이 명확해질수록 그 방향으로 서비스를 최적화하는 전략이 자연스럽게 도출된다. 이 패턴을 모른 채 AI 투자 방향을 결정한다면, 실제 사용자가 필요로 하는 것과 투자 우선순위가 어긋날 가능성이 높다.
측정을 조직의 의사결정에 연결하는 법
좋은 지표를 알고 있는 것과, 그 지표가 실제 조직의 의사결정으로 연결되는 것은 전혀 다른 문제다. AI 측정 프로그램이 실패하는 가장 흔한 원인은 잘못된 지표가 아니라, 지표와 결정 사이의 연결고리가 없는 것이다.
거버넌스 공백의 위험
위 Cursor의 사례를 보면 근본적인 질문이 남는다. 고객 접점에 배포된 AI 봇이 생성하는 정보의 정확성을 배포 전에 검증하는 프로세스가 있었는가? 그 프로세스의 기준을 누가 정의했는가?
사전에 정의된 성공 기준 없이 승인된 AI 프로젝트가 실패할 확률은 성공 기준이 명확한 프로젝트 대비 4.5배 높다. 배포 전 품질 검증 체계를 갖춘 조직은 그렇지 않은 조직 대비 프로덕션 인시던트를 60% 적게 경험한다.[8] AI 기능 배포 전 품질 검증은 기술팀만의 책임이 아니다. "어떤 기준을 통과해야 배포할 수 있는가"를 결정하는 것은 제품과 비즈니스를 이해하는 사람의 역할이다. 의료 정보를 제공하는 AI와 창작 보조 AI의 정확도 기준이 같을 수 없다. 지금 리더십에서 당장 점검해야 할 질문은 하나다. "우리 조직에서 AI 기능을 배포하기 전에 품질을 검증하는 프로세스가 있는가? 그리고 그 합격 기준을 누가 정의하는가?"
지표가 결정으로 이어지는 조직 만들기
지표를 수집하고 대시보드를 구성하는 것은 시작이다. 그 숫자가 실제 결정과 연결되지 않으면, 대시보드는 정보가 쌓이는 장식이 된다. 업계 전문가들은 이를 '대시보드 시어터(Dashboard Theater)'라고 부른다.
측정이 결정으로 이어지는 구조를 만들기 위해서는 세 가지 요소가 필요하다.
첫째, 측정-해석-액션의 루프를 정례화해야 한다. AI 품질 지표를 주간 단위로 검토하는 정기 리뷰 미팅을 만들고, 핵심 지표를 고정 안건으로 다루는 것이 출발점이다.
둘째, 임계값 기반의 사전 프로토콜을 문서화해야 한다. "Hallucination Rate가 특정 수준을 초과하면 해당 AI 기능 배포를 중단한다"는 식의 명확한 기준을 미리 합의하고 문서화해야 한다.
셋째, 지표의 오너십을 명확히 해야 한다. AI 성과 지표의 정의, 임계값 설정, 해석과 배포 결정이 기술팀에만 집중되어 있는 조직은 비즈니스 맥락이 측정 체계에 반영되지 않는 구조적 문제를 안고 있다.
AI 지표 체계의 성숙은 하루아침에 이루어지지 않는다. 서비스 출시 초기에는 사용자 피드백, 부정적 반응을 직접 읽으며 정성적으로 파악하는 것이 먼저다. 안정화 단계에서는 핵심 AI 지표를 대시보드에 세팅하고 임계값을 가설로 설정한 후 실제 데이터로 조정해간다. 성숙 단계에서는 품질 검증이 배포 파이프라인에 자동화되고, 지표가 배포와 예산 결정에 직접 연결되는 구조가 완성된다.
리더십을 위한 두 가지 질문
지금까지 AI 프로덕트의 측정이 왜 다른지, 무엇을 어떻게 봐야 하는지를 다뤘다. 마지막 장에서는 이 모든 논의를 하나의 실행 가능한 질문으로 압축한다. 의사 결정의 최상단에 있는 C레벨 임원과 전략기획 담당자가 AI 전략을 점검하는 자리에서, 기술팀에게, 그리고 스스로에게 던져야 할 두 가지 질문이다.
우리는 지금 AI의 무엇을 측정하고 있는가
가장 먼저 해야 할 일은 현재 상태를 정직하게 진단하는 것이다. 조직에서 현재 AI 성과를 측정하는 지표가 무엇인지를 나열해 보면, 그 지표들이 기존 소프트웨어 서비스에 사용하던 것과 얼마나 다른지를 확인할 수 있다.
아래 질문들은 현재 AI 측정 체계의 공백을 점검하는 실용적 출발점이다.
우리 AI 서비스의 에러율이 낮다는 보고를 받는다. 그 에러율이 낮다는 것이 AI가 정확한 정보를 제공하고 있다는 의미인가, 아니면 단순히 시스템이 정상 작동하고 있다는 의미인가?
우리 AI 서비스의 DAU가 올라가고 있다. 그 상승이 사용자가 AI를 신뢰하기 때문인가, 아니면 AI가 한 번에 문제를 해결하지 못해서 반복 접속하기 때문인가? 우리가 고객 접점에 배포한 AI가 생성하는 정보의 정확성을 주기적으로 검증하는 프로세스가 있는가?
이 질문들에 명확하게 답할 수 없다면, 현재의 AI 측정 체계에 공백이 있다는 신호다. 공백을 메우는 것이 더 많은 지표를 추가하는 것을 의미하지 않는다. 지금 보고 있는 숫자가 실제로 무엇을 의미하는지를 다시 정의하는 것, 그리고 기존 지표가 포착하지 못하는 AI 고유의 차원을 추가하는 것이 먼저다.
AI 지표가 경영 결정과 연결되어 있는가
두 번째 질문은 지표의 존재가 아니라 지표의 기능에 관한 것이다. 측정하는 숫자가 있더라도, 그 숫자가 실제로 로드맵, 예산, 인력 배치 결정에 영향을 미치지 않는다면 그 측정은 보고를 위한 보고다. 최근 3개월간 AI 성과 지표로 인해 변경된 의사결정이 있는가? AI 기능의 배포가 품질 기준 미달로 연기된 사례가 있는가? 이 질문들에 "없다"는 답이 나온다면, 현재 AI에 투자하는 예산과 자원이 올바른 방향으로 가고 있는지를 확인할 수 없다는 문제는 동일하다.
기술팀과 경영진이 AI 성과를 같은 언어로 이야기하고 있는지도 점검해야 한다. 기술팀이 모델 정확도와 시스템 안정성을 보고하는 동안 경영진은 비즈니스 임팩트와 ROI를 묻는다면, 두 그룹은 서로 다른 것을 측정하며 같은 AI 서비스를 평가하고 있는 것이다. 이 간극을 좁히는 것이 AI 투자를 경영 결정과 연결하는 첫 번째 실질적 단계다.
마무리: 잘못된 지표는 잘못된 안도감을 준다
대시보드가 초록불일 때 가장 위험하다. 이것이 이번 글에서 전하는 핵심 메시지다.
페이스북의 알고리듬이 수년간 혐오 콘텐츠를 증폭시키는 동안 참여 지표는 계속 올라갔다. Cursor의 고객 지원 봇이 존재하지 않는 정책을 안내하는 동안 에러율은 0%였다. 시스템은 정상이었고, 숫자는 좋았고, 문제는 보이지 않았다. 누군가 올바른 질문을 던지기 전까지는 AI 프로덕트/서비스가 만드는 가장 위험한 실패는 이처럼 조용하고 경보가 울리지 않는다.
그 다른 질문이란 이것이다. 우리는 지금 AI의 무엇을 측정하고 있는가. 에러율이 아니라 정확성을. 접속 횟수가 아니라 완료된 업무를. 시스템 안정성이 아니라 사용자가 실제로 얻은 가치를. 이 질문의 방향이 바뀌는 순간, 같은 AI 서비스가 전혀 다르게 보이기 시작한다.
AI 전략의 출발점은 더 좋은 모델을 선택하는 것이 아니다. 지금 우리가 측정하고 있는 것이 실제로 올바른 것인지를 먼저 묻는 것이다. 그 질문에 정직하게 답하는 조직만이, 초록불 뒤에서 조용히 진행되는 실패를 먼저 발견할 수 있다.
FAQ
-
AI 프로젝트가 실패하는 비율이 왜 높은가요?
2025년 한 해에만 42%의 기업이 주요 AI 이니셔티브를 중단했습니다. 이는 기술적인 문제보다는 잘못 설정된 성공 지표와 측정 체계 부재가 주된 원인입니다. AI가 무엇을 잘하고, 무엇을 잘못하고 있는지 측정하는 방법을 모르는 채 투자하고 있기 때문입니다.
-
기존 소프트웨어 지표로는 AI의 성과를 제대로 측정할 수 없나요?
네, 그렇습니다. AI는 기술적으로 완벽하게 작동하면서도 잘못된 정보를 생성할 수 있습니다. 에러 로그에는 아무런 문제가 잡히지 않고, DAU는 상승하며, 에러율은 0%에 가깝지만, AI는 조용히 잘못된 일을 하고 있을 수 있습니다. 기존 지표는 AI 프로덕트의 가장 중요한 실패를 포착하지 못합니다.
-
AI 프로젝트의 성공을 측정하기 위해 어떤 새로운 지표를 사용해야 하나요?
Task Completion Rate (AI가 부여받은 업무를 성공적으로 완료한 비율), AI 증강 vs 자동화 비율, 토큰 비용 등이 중요합니다. 또한 AI가 생성하는 정보의 정확성을 측정하는 Hallucination Rate, Groundedness, Human Override Rate도 고려해야 합니다.
-
AI 측정 체계를 개선하기 위한 첫걸음은 무엇인가요?
현재 AI 성과를 측정하는 지표를 점검하고, 그 지표들이 실제로 무엇을 의미하는지를 다시 정의해야 합니다. 또한, 기존 지표가 포착하지 못하는 AI 고유의 차원을 추가해야 합니다.
-
AI 측정 관련 최신 트렌드는 무엇인가요?
AI 에이전트 시스템의 확산으로 인해 “AI가 얼마나 많은 업무를 완료했는가”를 측정하는 것이 중요해지고 있습니다. 또한, AI 증강과 자동화 비율을 구분하여 AI 서비스의 설계 방향을 파악해야 합니다.
-
AI 기능 개발의 우선순위를 결정할 때 고려해야 할 사항은 무엇인가요?
AI 기능은 일반 소프트웨어 기능과 다른 비용 구조를 가지고 있습니다. 데이터 준비, 모델 검증, 지속적인 모니터링과 재학습에 필요한 추가 비용을 고려해야 합니다.
-
AI 서비스의 품질과 비용 사이의 트레이드오프를 어떻게 관리해야 하나요?
LLM 기반 서비스의 비용은 토큰 소비량에 직접 연동됩니다. AI 품질 향상에 따라 토큰 소비량이 급증하면서 실제 운영 비용이 늘어날 수 있습니다. 품질과 비용을 균형 있게 관리하는 것이 중요합니다.
-
AI 투자 의사결정 시 리더십이 가장 중요하게 고려해야 할 질문은 무엇인가요?
“우리는 지금 AI의 무엇을 측정하고 있는가?” 그리고 “AI 지표가 경영 결정과 연결되어 있는가?” 이 두 가지 질문에 명확하게 답할 수 있어야 합니다.
References
Folio3 AI, What Percentage of AI Projects Fail in 2026?
MIT Sloan, Pertama Partners, “AI Project Failure Statistics 2026: The Complete Picture”, Feb 8, 2026
Rachel Thomas & David Uminsky, “The Problem with Metrics is a Fundamental Problem for AI”, 2020
Cisco, “Cisco AI Readiness Index”
Gartner, “Gartner Predicts That by 2030, Performing Inference on an LLM With 1 Trillion Parameters Will Cost GenAI Providers Over 90% Less Than in 2025”, Mar 25 2026.
a16z, “State of Consumer AI 2025: Product Hits, Misses, and What's Next”, Dec 18, 2025
Anthropic, “Anthropic Economic Index Report: Economic Primitives”, Jan 15, 2026
Getmaxim, “A Comprehensive Guide to Testing and Evaluating AI Agents in Production”, Nov 22 2025
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.

