

CNCF(Cloud Native Computing Foundation)의 2019년 연간 리포트[1]에 의하면, 조사에 참여한 기업 중 84%가 프로덕션 환경에서 컨테이너를 활용 중이며, 89%가 다양한 형태의 쿠버네티스(퍼블릭 클라우드에서 제공하는 관리형 쿠버네티스나 온프레미스 환경의 설치형 쿠버네티스와 같이 형태가 다양함을 의미)를 컨테이너 관리 도구로 사용한다고 답했습니다. 그만큼 컨테이너 기술이 보편화되었고, 컨테이너 오케스트레이션 도구인 쿠버네티스에 대한 활용도 높아졌음을 알 수 있습니다.
앞선 인사이트리포트에서 ‘초보자를 위한 쿠버네티스 소개[2]’라는 주제로 쿠버네티스를 소개하였으며, 이 외에도 다양한 학습 자료를 통해 쿠버네티스 개요와 기본 컴포넌트에 관한 정보를 접근하실 수 있을 것으로 생각됩니다. 이 글에서는 한 걸음 더 나아가 쿠버네티스 클러스터 운영자를 위한 모니터링이라는 주제를 다뤄보고자 합니다. 본 주제는 쿠버네티스를 직접 설치, 관리하는 환경에서 쿠버네티스 모니터링을 다룹니다. (쿠버네티스에 실행 중인 애플리케이션 모니터링을 직접 다루지 않으니 참고 바랍니다.)
1. 쿠버네티스 개념 살펴보기
본 주제로 바로 들어가기 전에 쿠버네티스 모니터링과 관련 있는 쿠버네티스의 개념을 짧게 다루겠습니다.
쿠버네티스 개념
쿠버네티스는 리눅스 컨테이너의 장점을 최대한 활용하기 위해 다수의 머신(노드)에서 애플리케이션(컨테이너)을 실행하고 오케스트레이션하는 도구입니다. 쿠버네티스의 내부 동작을 간략하게 설명하면 다음과 같습니다. 쿠버네티스는 선언적으로 정의된 애플리케이션 디스크립터의 의도된 상태(desired state)와 쿠버네티스의 현재 상태(current state)가 일치하는지 감시하고, 의도된 상태와 현재의 상태가 일치하지 않는 경우, 이를 조정(reconcile)하는 연속적인 과정을 통해 애플리케이션이 의도된 상태가 되도록 합니다.
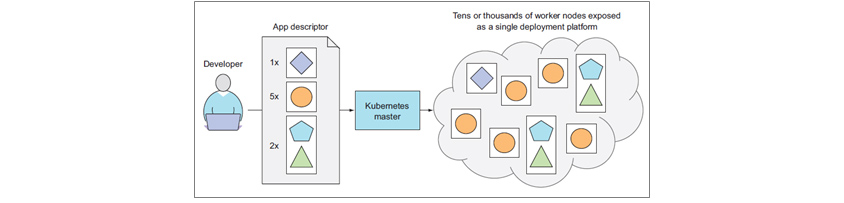 [그림 1] 개발자의 선언적 요청을 처리해 주는 쿠버네티스 개념도[3]
[그림 1] 개발자의 선언적 요청을 처리해 주는 쿠버네티스 개념도[3]
이를 간략히 표현하면 아래와 같습니다.[4]
desired := getDesiredState()
current := getCurrentState()
makeChange(desired, current)
}
쿠버네티스를 통해 애플리케이션은 항상 의도된 상태를 유지하게 됩니다.
쿠버네티스 개념 확대해보기
이를 한 단계 확대해보면 아래 [그림 2]와 같습니다. 개발자는 개발된 컨테이너 이미지를 이미지 레지스트리(Image registry)에 푸시하고, 쿠버네티스 컨트롤 플레인(Control Plane)에 매니페스트(App descriptor)를 게시합니다. 컨트롤 플레인과 통신하는 각 노드의 Kubelet이 이 신호를 받고, 컨테이너 런타임(Docker)은 정의된 이미지를 이미지 레지스트리에서 가져와 컨테이너를 실행합니다.
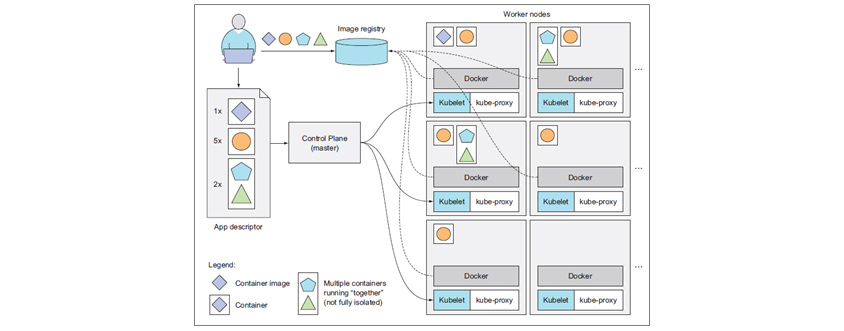 [그림 2] 쿠버네티스 아키텍처 기본 개요[5]
[그림 2] 쿠버네티스 아키텍처 기본 개요[5]
애플리케이션의 인스턴스가 쿠버네티스라는 추상화된 플랫폼 위에 배치됩니다. 또한 노드 장애나 스케일링이 발생하면 다른 노드에 스케줄링됩니다. 워커 노드(Worker nodes) 자체는 추상화되고, 애플리케이션이 어디에 배치될지 명확하지는 않습니다. 사실 내부 흐름은 실제로 더 복잡한데, 여기까지가 모니터링의 주제에서 이야기할 쿠버네티스의 특성입니다.
2. 쿠버네티스 환경의 모니터링 관점 변화
앞서 살펴본 대로, 사용자가 정의한 상태대로 임의의 노드에 수 개의 컨테이너가 배포되어 애플리케이션이 실행 중이라는 것은 이상적이지만, 직관적이지는 않습니다. 또한 OS 위에 쿠버네티스라는 새로운 레이어가 생겼습니다. 이로 인해 모니터링에 관한 관점도 변화가 필요합니다.
쿠버네티스가 아닌 환경의 모니터링은 다음 [그림 3]과 같습니다. 보통 각 서버는 특정 역할(WEB, DB 등)을 가지고 있고, 모니터링 에이전트를 설치해 정보를 수집하고, 이를 모니터링 백엔드로 전달합니다. 이를 Push-based 모니터링이라고 합니다. 각 서버는 특정 역할을 가지므로 역할에 맞는 메트릭을 수집하도록 별도의 설정이 필요할 수도 있습니다.
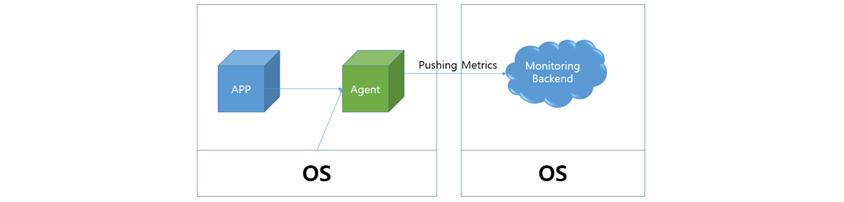 [그림 3] 쿠버네티스 환경이 아닌 경우 모니터링 예시
[그림 3] 쿠버네티스 환경이 아닌 경우 모니터링 예시
반면 쿠버네티스 환경의 모니터링은 애플리케이션의 단위가 작아지고, (하나의 노드에 다양한 애플리케이션의 인스턴스가 실행됩니다.) 모니터링 대상도 동적으로 변경될 수 있습니다. (스케일링(Scaling)이나 자연 회복(Auto Healing)에 의하여 노드별 역할을 구분하기 어렵습니다.) 애플리케이션을 관리하는 주체가 클러스터를 운영하지 않는 경우 에이전트를 설치하는 것도 쉽지 않습니다. 이러한 환경에서는 모니터링 백엔드가 모니터링 대상을 찾고 모니터링 메트릭을 수집해오는 것이 적절할 수도 있습니다. 이를 Pull-based 모니터링이라고 합니다.
[참고] 쿠버네티스 환경에서 노드가 추가/삭제될 때마다 관리자가 에이전트를 설치/삭제해야 하나요?
→ 노드도 추가/삭제될 수 있지만 매번 관리자가 에이전트를 설치/삭제하지 않습니다. 보통 데몬셋(DaemonSet) 형태의 모니터링 컴포넌트가 사용되는데, 데몬셋은 모든 노드에 배포되는 애플리케이션을 나타내는 오브젝트로 보통 관리 목적의 구성요소를 배포하기 위해 사용됩니다.
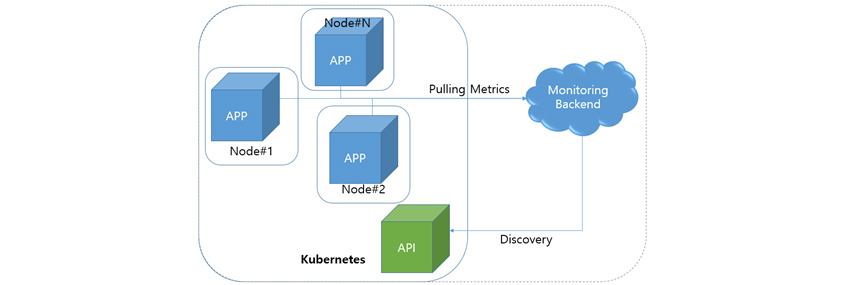 [그림 4] 쿠버네티스 환경의 모니터링 예시
[그림 4] 쿠버네티스 환경의 모니터링 예시(점선은 모니터링 백엔드도 쿠버네티스 내부에 속할 수 있음을 의미합니다.)
프로메테우스(Prometheus)는 대표적인 Pull-based 모니터링 툴입니다. [그림 5]와 같이 프로메테우스는 kube-apiserver로부터 서비스를 디스커버리하고, 각 대상에서 메트릭을 수집(Scrape)합니다. (Push-based 모니터링 툴이 메트릭을 모니터링 백엔드로 전송하는 반면, Pull-based 모니터링 툴은 모니터링 백엔드가 대상에서 메트릭을 가져옵니다.)
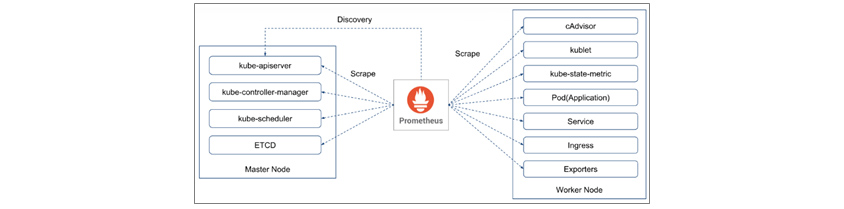 [그림 5] 프로메테우스를 통한 Service Discovery & Scrape[6]
[그림 5] 프로메테우스를 통한 Service Discovery & Scrape[6]
3. 쿠버네티스 모니터링 아키텍처
쿠버네티스 환경에서 모니터링이 어렵게 느껴지는 것은 당연합니다. 앞서 언급한 것과 같이 모니터링의 접근 방법이 달라져, 기존 모니터링 툴은 쿠버네티스 환경에서 사용하기에는 적합하지 않거나, 다른 설정이 필요하게 됩니다. 또한 쿠버네티스 자체를 모니터링해야 할 필요도 있습니다. 이로 인해 쿠버네티스 환경에서는 다양한 컴포넌트가 도입됩니다.
인프라엔지니어는 기존 모니터링(HW, OS)과 쿠버네티스 모니터링을 병행하는 중복성을 가지면서도, 쿠버네티스 환경에서 바라보는 메트릭이 기존에 알던 메트릭과 일치하지 않거나, 완전히 새로운 메트릭때문에 어떤 것을 모니터링해야 하는지 판단하기 어렵습니다.
앞의 절에서 모니터링의 접근 방법이 다름을 이야기했고, 이번 절에서는 쿠버네티스 모니터링 아키텍처와 어떤 컴포넌트가 있는지 살펴보겠습니다. 그리고 다음 절에서 클러스터 운영 관점에서 무엇을 모니터링해야 할지 다뤄보겠습니다.
쿠버네티스 모니터링의 두 가지 파이프라인(Pipeline)
먼저 쿠버네티스 모니터링 아키텍처를 먼저 살펴보겠습니다. 쿠버네티스 모니터링을 쿠버네티스(혹은 컨트롤 플레인)의 컴포넌트가 직접 활용하는 정보와 이보다 많은 정보를 수집해 히스토리/통계 정보를 보여주는 모니터링 시스템 관점으로 나눠보겠습니다. 이 흐름을 쿠버네티스 공식 사이트[7]에서는 리소스 메트릭 파이프라인(Resource Metrics Pipeline)과 완전한 메트릭 파이프라인(Full Metrics Pipeline)으로 나눠서 설명하고 있습니다. (일부 문서에서는 이를 코어 메트릭 파이프라인(Core Metric Pipeline)과 모니터링 파이프라인(Monitoring Pipeline)으로 나누기도 합니다.)
리소스 메트릭 파이프라인은 쿠버네티스의 컴포넌트가 활용하는 메트릭의 흐름입니다. 쿠버네티스는 수집된 정보를 kubectl top 명령으로 노출해주고, 스케일링이 설정되어 있다면 자동 스케일링(Autoscaling)에 활용합니다. [그림 6]은 metrics-server를 통해 수집된 모니터링 정보를 메모리에 저장하고 API 서버를 통해 노출해 kubectl top, scheduler, HPA와 같은 오브젝트에서 사용된다는 것을 나타냅니다. 쿠버네티스의 일부 기능은 Metric Server의 정보를 사용합니다.
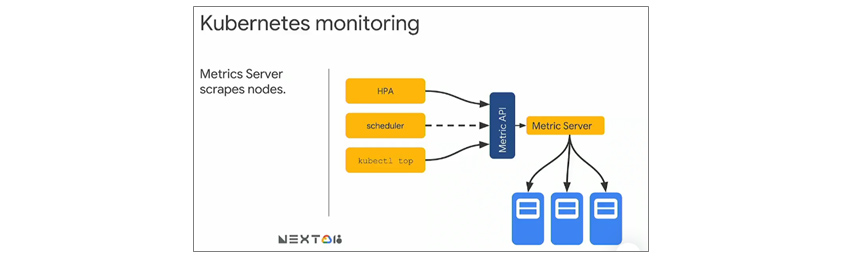 [그림 6] 쿠버네티스 모니터링[8]
[그림 6] 쿠버네티스 모니터링[8]
다만, 이러한 정보는 순간의 정보를 가지고 있고, 다양한 정보를 수집하지 않으며, 장시간 저장하지 않습니다. 이로 인해 두 번째 흐름인 완전한 메트릭 파이프라인이 필요합니다. 이는 기본 메트릭뿐만 아니라 다양한 메트릭을 수집하고, 이를 스토리지에 저장합니다.
완전한 메트릭 파이프라인 자체는 쿠버네티스에서 직접적으로 관여하지 않으며, CNCF 프로젝트 중 하나인 프로메테우스를 활용할 수 있습니다. 프로메테우스를 활용한 경우의 흐름은 아래 [그림 7]과 같으며, 프로메테우스를 통해 서비스 디스커버리(Service discovery), 메트릭 수집(Retrieval) 및 시계열 데이터베이스(TSDB, Time Series Database)를 통한 저장, 쿼리 엔진을 통한 PromQL 사용과 Alertmanager를 통한 통보가 가능합니다.
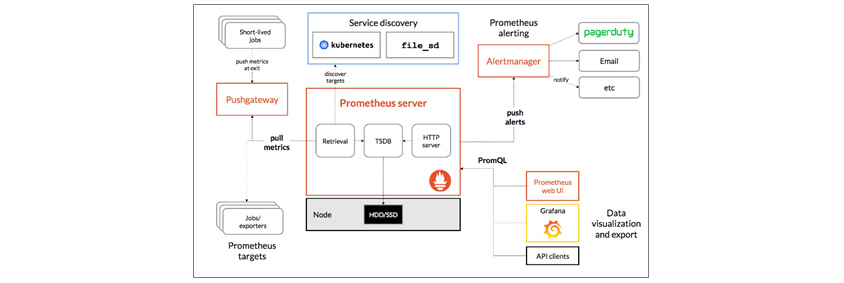 [그림 7] Prometheus architecture and its ecosystem component[9]
[그림 7] Prometheus architecture and its ecosystem component[9]
모니터링 컴포넌트 소개
지금까지 살펴본 파이프라인에 다양한 모니터링 컴포넌트가 등장해 헷갈릴 수 있는데, 이를 간단히 정리해보면 다음과 같습니다.
◎ cAdvisor: kubelet에 포함되어 노드, 파드, 컨테이너의 리소스 사용률을 수집하는 모듈
◎ metrics server: cAdvisor로부터 정보를 수집하는 도구로, 리소스 메트릭 파이프라인은 metrics server의 정보를 활용함 (이 역할을 수행하던 heapster는 쿠버네티스 버전 1.11부터 더 이상 사용되지 않음)
◎ Prometheus: 서비스 디스커버리, 메트릭 수집(Scrape) 및 저장(TSDB), 쿼리 기능(PromQL 사용), Alert 기능을 제공하는 도구
◎ Grafana: 데이터 시각화 도구(Prometheus를 데이터 소스로 지정)
◎ node exporter: Prometheus와 연동되는 수집기(Exporter) 중 하나로 노드의 HW, OS 메트릭을 수집하기 위한 도구
◎ kube-state-metric: API 서버를 통해 오브젝트 상태에 관한 메트릭을 생성하는 도구 (ex. 파드 현재 상태, 서비스 상태)
◎ metricbeat: kube-metric-server 및 로컬 머신, docker, kubelet에서 수집한 정보를 ElasticSearch 기반의 백엔드로 전송하는 도구
리소스 메트릭 파이프라인에 해당하는 cAdvisor와 metrics server, 각 클러스터 단위의 모니터링 시스템을 위한 Prometheus, Grafana, node exporter, kube-state-metirc이 있습니다. 추가로 ElasticSearch를 백엔드로 사용하는 경우 metricbeat를 활용할 수도 있습니다.
4. 무엇을 모니터링해야 할까?
그렇다면 쿠버네티스 환경에서는 과연 무엇을 모니터링해야 할까요? 그것을 이해하기 위해 쿠버네티스 환경에서 발생할 수 있는 이슈 상황을 몇 가지 예로 들어 보겠습니다.
① 특정 노드가 다운되거나 Ready 상태가 아닌 경우 (컨트롤 플레인이 다중화되거나, 애플리케이션이 디플로이먼트와 같은 단위로 구성된 경우 보통은 큰 문제가 되지 않지만, 특정 상황에서는 문제가 될 수 있습니다.)
② 컨트롤 플레인의 주요 컴포넌트 상태가 비정상적인 경우
③ 노드의 가용한 리소스보다 리소스 요청량(Request)이 커서 파드가 배포되지 않는 경우
④ 노드 리소스가 부족하여 컨테이너의 크래시(혹은 eviction)가 발생한 경우
⑤ 특정 컨테이너가 OOMKilled나 그 밖의 문제로 인해 반복적으로 재시작하는 경우
⑥ PV로 할당하여 마운트된 파일시스템의 용량이 부족한 경우
이를 통해 쿠버네티스를 모니터링하는 것은 OS 레벨에서 쿠버네티스, 외부 자원(스토리지)까지 범위가 넓어진다는 것을 알 수 있습니다. 이를 바탕으로 클러스터 운영자가 모니터링해야 할 부분을 몇 가지로 분류해 보았습니다.
클러스터 구성요소(노드 및 주요 컴포넌트)의 상태
쿠버네티스 환경이라면 쿠버네티스 자체를 모니터링해야 합니다. 컨트롤 플레인의 구성요소에 문제가 발생되어 사용자 애플리케이션이 배포되지 않거나 컨트롤러가 수행해야 하는 동작이 실패하는 상황이 발생할 수 있습니다. 클러스터의 주요 컴포넌트와 더불어 노드의 상태도 확인이 필요하며 각각 Healthy, Ready 상태이어야 합니다.
노드의 리소스 가용량
특정 노드에 관한 파드의 스케줄링은 노드에 할당되지 않은 리소스가 남아 있는 경우에 한해 가능합니다. 노드의 리소스 사용량 자체는 스케줄러가 수행하는 파드 스케줄링과 상관이 없습니다. 즉, 노드 가용량을 모니터링해야 하는 이유는 전체 노드에 가용한 리소스(Allocatable)가 파드의 요청량(Request)보다 부족하면 파드가 더 이상 스케줄링되지 못하기 때문입니다. 필요한 경우 노드 리소스를 증설하거나, 노드를 추가해야 합니다. 가장 쉬운 방법은 노드 상태를 확인하여 Allocated resources 부분의 각 CPU와 메모리 요청(Request)에 대한 퍼센티지를 확인할 수 있습니다.
노드의 리소스 사용량
OS 레벨의 모니터링을 하고 있다면, sar 혹은 유사 메트릭으로 노드 리소스 사용량을 모니터링할 수 있습니다. (단, sar 등의 리소스 사용량이 kubectl top node의 결과와 완전히 일치하지 않습니다.)
[참고] 왜 kubectl top node와 free -m의 결과가 다를까요?
→노드 리소스 정보를 수집하는 cAdvisor에서는 memory.usage_in_bytes - total_inactive_file을 사용하며, 일반적으로 OS 모니터링에 사용되는 Available Byte(/proc/meminfo)와 값이 다릅니다.[10]
쿠버네티스에서는 노드의 MemoryPressure, DiskPressure가 발생하는 경우 노드의 컨디션이 변경되고 파드 eviction이 발생합니다. 이는 아래값[11]을 참조하므로 이 이상으로 노드의 리소스가 유지되도록 모니터링이 필요합니다.
nodefs.available<10%
nodefs.inodesFree<5%
imagefs.available<15%
워크로드(Workload) 이슈
애플리케이션 자체 모니터링을 언급하지는 않았지만, 애플리케이션 프로세스 다운을 모니터링하는 부분이 있을 수 있습니다. 파드에 적절한 라이브니스 프로브(liveness probe)가 설정되어 있는 경우, 혹은 OOMKilled되는 경우는 컨테이너의 재시작 횟수(Restart Count)가 지속적으로 증가하는지 모니터링해 볼 수 있습니다.
파드에서 한 가지 더 이야기 하고 싶은 것은 퍼시스턴트 볼륨(PV, Persistent Volume)입니다. 특정 애플리케이션은 PV의 용량 부족으로 문제가 될 수 있습니다. 퍼시스턴트 볼륨을 뒷받침하는 기반스토리지는 인프라 차원에서 관리되므로 스토리지에서 용량을 관리하고 모니터링 시스템으로 전송할 수 있습니다. 한편, 퍼시스턴트 볼륨은 파드가 실행 중인 노드에 마운트되므로, (파일시스템 모니터링이 동적으로 반영된다면) 노드의 파일시스템 모니터링으로 가능합니다. 물론 컨테이너 리소스에 관한 모니터링도 가능하지만, 이는 컨테이너의 요청(Request)이 적절한지의 여부를 아래 [그림 8]과 같이 점검할 수 있다는 차원에서만 언급하겠습니다.
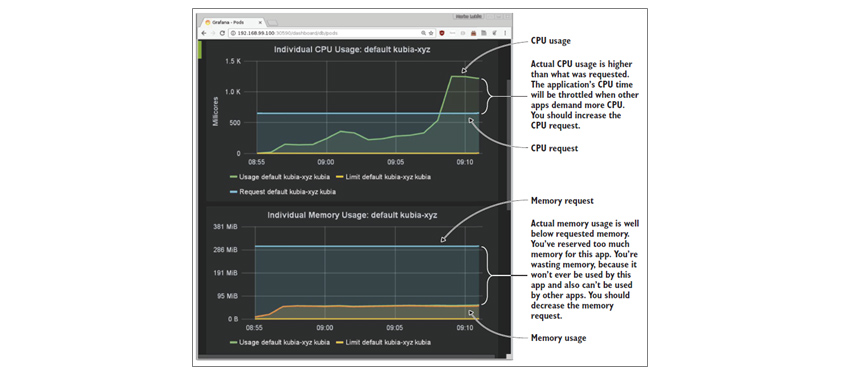 [그림 8] 파드의 CPU와 메모리 사용량 차트[12]
[그림 8] 파드의 CPU와 메모리 사용량 차트[12]
5. 마치며
이 글을 작성하며 각 모니터링 컴포넌트의 사용법과 메트릭에 관한 설명을 하지 않았지만, 이는 다양한 자료를 통하여 공개되어 있으니 확인해 보시기를 추천해 드립니다. 클라우드 네이티브 환경에서 서비스 측면의 모니터링도 중요하지만, 한편으로는 기반플랫폼인 쿠버네티스 클러스터 자체의 유효성 보장을 위한 모니터링도 확인이 필요합니다. 짧지만 쿠버네티스 클러스터를 운영하는 데 도움이 되시기 바라며 글을 마칩니다.
# References
[1] https://cncf.io/blog/2020/03/04/2019-cncf-survey-results-are-here-deployments-are-growing-in-size-and-speed-as-cloud-native-adoption-becomes-mainstream/
[2] https://samsungsds.com/global/kr/insights/Kubernetes_inform_kr.html
[3] 마르코 룩샤, Kubernetes in Action, 2018, 17p
[4] https://engineering.bitnami.com/articles/a-deep-dive-into-kubernetes-controllers.html
[5] 마르코 룩샤, Kubernetes in Action, 2018, 20p
[6] https://yunsangjun.github.io/blog/kubernetes/2018/07/20/kubernetes-monitoring.html
[7] https://kubernetes.io/ko/docs/tasks/debug-application-cluster/resource-usage-monitoring/
[8] https://www.youtube.com/watch?v=nz-B6JBgbZA&index=21&list=PLBgogxgQVM9v0xG0QTFQ5PTbNrj8uGSS-&app=desktop
[9] https://prometheus.io/docs/introduction/overview/
[10] https://kubernetes.io/docs/tasks/administer-cluster/out-of-resource/#eviction-signals
[11] https://kubernetes.io/docs/tasks/administer-cluster/out-of-resource/
[12] 마르코 룩샤, Kubernetes in Action, 2018, 435p
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

삼성SDS 클라우드사업부 클라우드아키텍처팀
삼성 관계사의 웹 기반 서비스를 구현하기 위한 인프라엔지니어로 시작해 HW, OS, 미들웨어 등 인프라 전반을 아우르는 경험을 쌓았습니다. 이후 SDS 클라우드 서비스의 쿠버네티스 기반 시스템을 운영하였습니다. 현재 CI-TEC에서 장애지원 및 기술전문가 역할을 하고 있습니다.