Digital Business Requirements in the Era of Hyper-Personalization


The emergence of the hyper-personalization era
Among the marketing trends that emerged around 2020, hyper-personalization is still robust and catches attention. The term referred to in the book “Trend Korea 2020” by Nando Kim attracted marketers' interest in the retail and manufacturing industries. Unlike the tremendous attention given to this concept, it, in large part, remains vague. Moreover, when we look through the “digital-based hyper-personalization” promoted by many companies recently, we are often perplexed to find so many differences between the concept and the initiative items.
So what is the basic requirement of hyper-personalized business and marketing?
1) Customization? Personalization!
This is so common, but many companies misunderstand that showing information previously entered or set up by customers is personalization. Businesses provide information, thinking this activity as personalization, but customers regard it as customization. The well-known case is the product once searched for pops up on every website or mobile app customers visit. This is a kind of Ad Tech which displays targeted ads based on the browsing history and interests, including search keywords stored in the customer's devices. The online ads industry provides such data to advertisers. The problem is that almost all advertisers cannot process or create a personalized retargeting model and recommend the same products customers have already searched for. Customers may feel their privacy is breached when something they already searched for pops up again in the ads in other services.
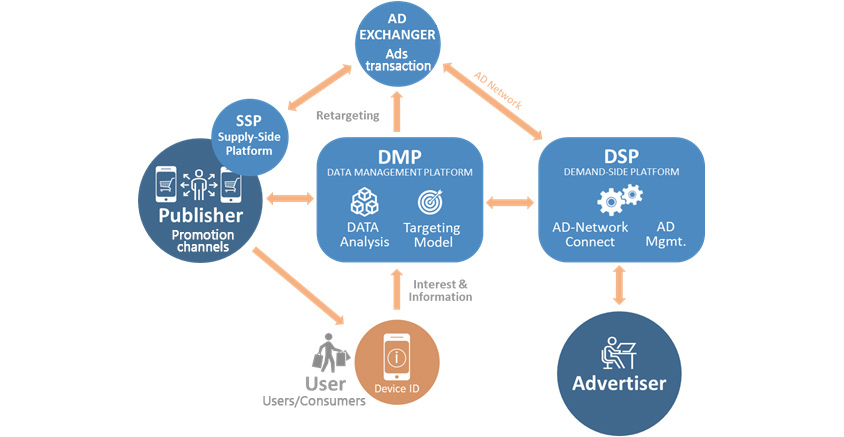
- retargeting
- ad network
- User Users/Consumers
- Interest & information
MyData was launched early this year and is facing similar issues. Its original purpose is to provide useful financial information by analyzing the individual's credit data collected by MyData operators with the customer’s consent. However, most operators only provide collected financial information in a more organized and refined form. (Considering that it is still in an early stage, the issue seems natural.)
Hyper-personalization for customers should, at least, recommend the right products or services based on a thorough understanding of each individual or suggest unexpected discoveries that suit customers' tastes.
2) The changes in understanding customers through data
What technology should companies then use, and what should they do with it to understand their customers? Before the emergence of the hyper-personalization trend, personalization practices existed, and the marketing methods and tools, such as customer relationship management (CRM), customer experience management (CEM), and digital log analysis, were utilized. Comparing those practices and hyper-personalization will allow us to easily understand traditional personalization methods and hyper-personalization.
Traditional methods, including CRM, have a relatively simple data structure on demographic characteristics included in customer data, behavioral information according to purchase and interests, and customer response data through datafication from responses against messages and promotions. In this case, customer targeting is likely to be chosen from the marketer's perspective.
The goal of hyper-personalization is to read the preference context depending on the situations and feelings of the customer beyond such limits. For example, a person sometimes likes drinking wine when they are in a romantic mood at their home in the late evening and other times likes drinking beer with their friends at a baseball game. The example helps us understand why multi-persona has emerged and gained interest. To do so, we must ensure and analyze many customer data points.
CRM data is based on past data and has dozens of items in the three contexts with longer data update cycles and smaller amounts of actual updates. However, to read preference context, we need to collect way more data types (for example, customer behavior logs, customer service history, online browsing history, external online behavior data, etc.) and bind hundreds to thousands of analyzed data points for customers.
Such a structure is called customer DNA (or customer digital DNA). We see more attempts for this in retailservice and brands/manufacturers.
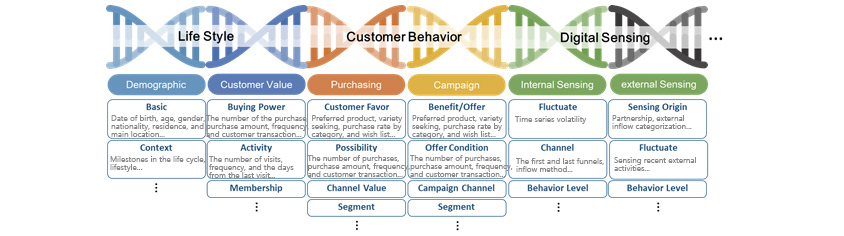
- Demographic - Basic: Date of birth, age, gender, nationality, residence, and main location.../Context: Milestones in the life cycle, lifestyle...
- Customer Value - Buying power: The number of the purchase, purchase amount, frequency, and customer transaction.../Activity: The number of visits, frequency, and the days from the last visit.../Membership
- Purchasing - Customer favor: Preferred product, variety seeking, purchase rate by category, and wish list.../Possibility: The number of purchases, purchase amount, frequency, and customer transaction.../Channel Value/Segment
- Campaign - Benefit, Offer: Preferred product, variety seeking, purchase rate by category, and wish list.../Offer Condition: The number of purchases, purchase amount, frequency, and customer transaction.../Campaign Channel/Segment
- Internal Sensing - Fluctuate: Time series volatility/Channel: The first and last funnels, inflow method.../Behavior Level
- External sensing - sensing origin: Partnership, external inflow categorization.../Fluctuate: Sensing recent external activities.../Behavior Level
3) Ensuring robust timely executions
Context-based personalization requires a time factor (on time). It is because the context for situations of customers changes frequently and rapidly. The recently built data-based hyper-personalization platforms mostly focus on the display exposureof B2C services or near-real-time offerings based on customer behavior.
The general big data environment has been arranged for analysts (data scientists). However, the problem is its execution. It is no use if insights are produced based on sophisticated analysis of customers, but cannot lead to business practice. For example, if there is a precise prediction algorithm to find what product will be most preferred today for certain customers, it will take days to produce outcomes, or only analysts can access it. Then, it may hardly show great effects in the business environment. Therefore, the key to big data-based hyper-personalization is the platformization of the structure that connects data processes from ensuring stocking,and analyzing to running and deploying data.
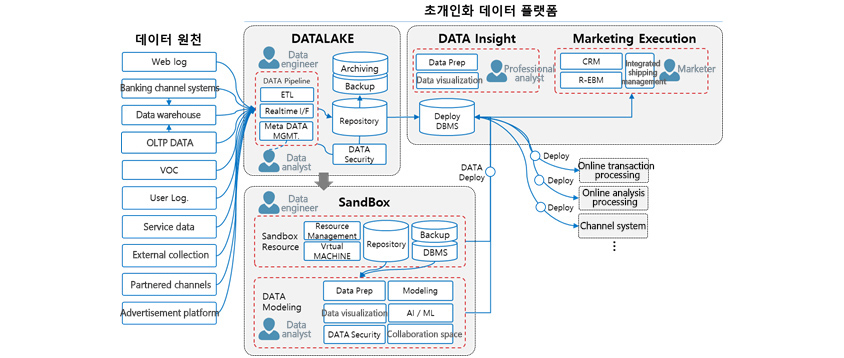
- Web logs, Banking channel systems, Data warehouse, OLTP DATA, VOC, User Log., Service data, External collection, Partnered channels, and Advertisement platform
- Data lake - Data engineer, DATA Pipeline: ETL, Real-time I/F, Meta DATA MGMT., and Data analyst
- Archiving, Backup <- Repository <- DATA Security
- DATA Insight - Data Prep, Data visualization, and Professional analyst
- Marketing Execution - CRM, R-EBM, Integrated shipping management, and Marketer
- Deploy DBMS
- Deploy → Online transaction processing
- Deploy → Online analysis processing
- Deploy → Channel system
- SandBox - Data engineer, Sandbox Resource (Resource Management, Virtual MACHINE, Repository, Backup, and DBMS)
- DATA Modeling (Data Prep, Modeling, Data visualization, DATA security, AI/ML, and A place for collaboration), Data analyst
Big data, hyper-personalization, and Trap
Until recently, many companies promoting digital innovations created big data structures and buy systems without clear goals and objectives, decreasing trends as if using big data has become common. Based on my past experience on projects, I suggest a few necessities that companies seeking digital innovation should bear in mind:
1) Specify your needs is important
Many companies need clear goals to follow suit for big data and hyper-personalization. So, they are more likely to only invest in labor costs and infrastructure building and, in return, receive little to meager and unfitting efforts towards them. Find the needs of the business regardless of the size and specify the expectations and objectives as much as possible.
2) Select the right system and platform for your capability
We often see changing system requirements whenever data analysts have changed because of the variety of capabilities and the technical spectrum of such personnel. Systems or analysis environments are unmatched by the analysts’ capability, causing both overinvestments and redundant investments. An alternative to such a system and platform would be cloud SaaS-based data analysis platforms that enable the expansion of only the necessary items or the flexibility for changing the analysis technology.
3) Involve experts in business data analysis
Many companies doubt investing in big data when they receive the first outcomes from creating a big data structure after a certain period. In most cases, the reasons behind it are due to disconnections from the existing business structures. Sometimes, after months of effort in data analysis in multiple aspects, data analysts only produce the most obvious outcomes for the person in charge without even trying to analyze them. If the people in charge participate, then at least they can remove obvious outcomes. Also, the reflection of the outcomes in the business will show better performance.
▶ The content is protected by the copyright law and the copyright belongs to the author.
▶ The content is prohibited to copy or quote without the author's permission.

Consulting Group, Innovative Data Business Team, S-Core Co., Ltd.
Professional consultant for digital innovation strategy, PI and ISP, big data platform strategy, digital channels, and marketing strategy in the finance, retail, and services industries. In charge of the MyData project.