loading...

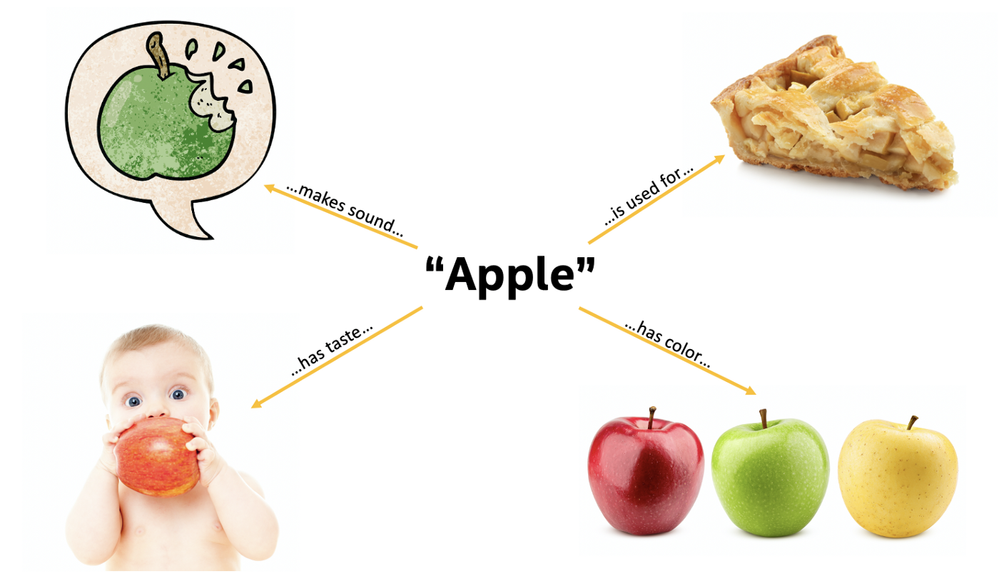 Humans understand an apple in various ways. (Source: Intel Labs)
Humans understand an apple in various ways. (Source: Intel Labs)
Related Articles
Humans understand an apple in various ways. (Source: Intel Labs)