[Technology Toolkit]
I Will Give You Data, Label It~ Auto Labeling!
Technology Toolkit 2021 is a technical white paper describing core technologies that
are being researched and developed by Samsung SDS R&D Center. We would like to introduce in this paper a total of
seven technologies concerning AI, Blockchain, Cloud, and Security with details on their technical definition, key
features, differentiating points, and use cases to give our readers some insights into our work.
Auto Labeling
1. Introduction to Technology
Technology Trends and Background
As AI technology advances, the demand for AI services is increasing. The process of building an AI service involves a
lot of work. For example, one of them includes creating a correct answer for training and finding a model with high
training efficiency. The performance of AI technology will be compromised if activities in the process, albeit small
one, are performed negligently. As a result, many researchers and developers still carry out the work manually. Of the
numerous tasks involved in the process, the most basic and the most labor- consuming task is labeling, which involves
making a correct answer for the data.
 [Figure 1]
Labeling
[Figure 1]
LabelingSince AI models tend to perform better with more data used for training, a lot of labeled data is required. Labeling
hundreds of thousands or millions of data manually, however, takes a lot of labor and time. Moreover, given that an
incorrect label adversely affects the AI model's performance, it is necessary to review the label for correctness.
Because of this labeling hassle, there is a growing market demand for technologies that can reduce manual work. Our
goal is to help minimize the cumbersome manual labeling work consuming many engineers with the help of automatic
labeling technology, a technology that is adopted by multiple global companies including Amazon, IBM, and Microsoft,
as well as a slew of start-ups.
Definition
Labeling is the task of producing a correct answer for given data, and here the correct answer is called a label. For
deep learning to undergo supervised learning, the data needs to be properly labeled. And accurate labeling is critical
as supervised learning based on incorrect labeling will degrade the model's performance.
There are many deep learning technologies that require labeling, such as image processing and natural language
processing. Among them, we introduce labeling for Image Classification, Object Detection, Image Segmentation, and Text
Analysis, and briefly touch upon the application of Active Learning technology. Let's take a look.
① Computer Vision (CV)
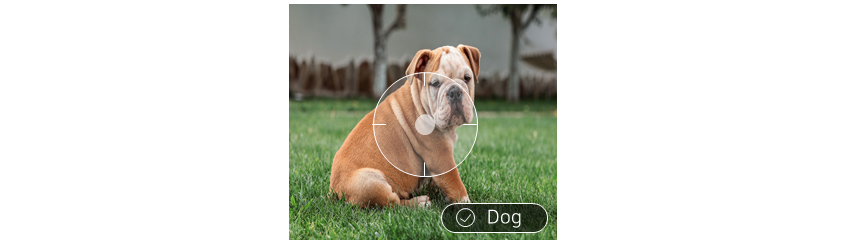
• Image Classification
The objective of image classification is to identify the class the image falls under when there are multiple classes
to choose from. For example, let’s say you are given hundreds of thousands of dog/cat images and need to sort
these images as either dog or cat. Here dog and cat are the given classes and this act of classifying a dog image as a
“dog” and a cat image as a “cat” is the image classification.
The labeling required for image classification is creating a label by identifying which class of the given classes
each image falls under. Usually, a single label is assigned to a single image, but sometimes multiple labels are
assigned to a single image depending on the task.
 [Figure 2] Image Classification (Source: Pixabay)
[Figure 2] Image Classification (Source: Pixabay)• Object Detection
The purpose of object detection is to find all objects in an image that are associated with the given class. Letgiven
classes each iman image of dogs and cats and you need to detect dogs and cats in the image. Here the given classes are
dogs and cats, and the task of identifying and marking all dogs and cats in the image is called object detection. The
labeling required for object detection is to assign the correct class and the location of all objects in the image
that are associated with the given class.
 [Figure 3]
Object Detection (Source: Pixabay)
[Figure 3]
Object Detection (Source: Pixabay)• Image Segmentation
Image segmentation can be largely divided into semantic segmentation and instance segmentation. The purpose of
semantic segmentation is to identify which of the given classes each pixel in an image falls under, and instance
segmentation is to identify an object in the image that associated with the given class and mark the pixels
corresponding to that object. For example, suppose there is a picture of three dogs overlapped side by side on a
field. Here semantic segmentation is marking each pixel as “dog” without distinguishing the three dogs
whereas instance segmentation is separating the these dogs and marking each pixel as “dog-1”,
“dog-2”, and “dog-3”.
The labeling required in semantic segmentation is identifying which class each pixel of the image falls under whereas
the labeling required in instance segmentation is to assign class that is appropriate to the pixels of all objects
belonging to a given class.
 [Figure 4] semantic segmentation (left), instance segmentation (right) / Source:
Pixabay
[Figure 4] semantic segmentation (left), instance segmentation (right) / Source:
Pixabay② Natural Language Processing (NLP)
• Named Entity Recognition
The objective of named entity recognition is to extract predefined entities from a sentence. In other words, it is the
task of identifying whether or not a particular word in the sentence belongs to the predetermined entity. Let’s
take a look at the following example: “Charles goes to school”. Here, the named entity recognition is the
task of classifying “Charles” as “a name of a person” and “school” as a
“place”. The labeling required in named entity recognition is assigning an entity name that is right for
the word within the sentence.
• Intent Classification
The objective of intent classification is to classify the intent of a sentence. For example, with the sentence "Please
give me a cup of Americano," intent classification is classifying the sentence as having the intention of "buying."
The labeling required in intent classification is assigning the right intent to each sentence.
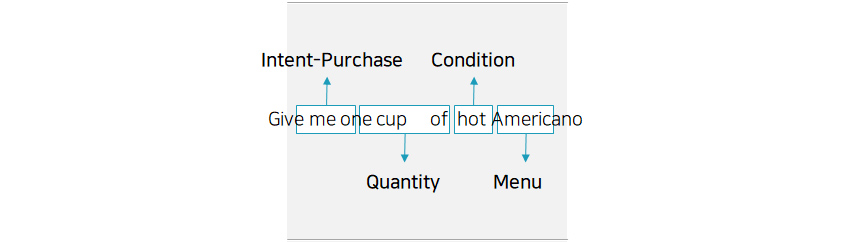 [Figure 5]
Intent classification
[Figure 5]
Intent classification• Active Learning
Active learning was developed to create high-performance deep learning model when there are unlabeled datasets. Active
learning methodology doesn't wait for researchers and developers to label all unlabeled datasets. The current deep
learning model is used to make a judgment on the given dataset, and present some of the most difficult-to-assess data
to researchers and developers. Then, researchers and developers manually label the subject data with priority, and the
model proceeds with the learning containing the newly labeled data. The re-trained deep learning model repeats the
earlier step of making a judgment on the given dataset and again present researchers and engineers with so some of the
most difficult-to-assess data. This way you can get a high-performance deep learning model faster as the deep learning
model gets refined with priority given to most complex data.
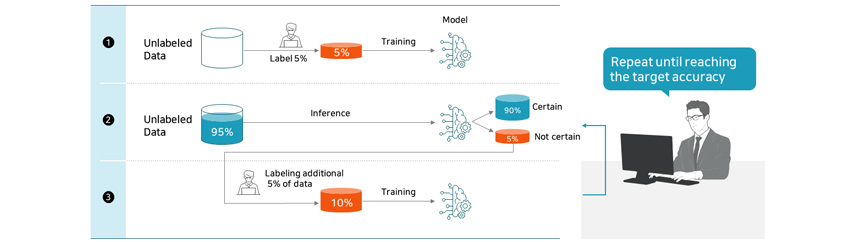
- Unlabeled Data 0%/Label 5%/Training/Model
- Unlabeled Data 95%/inference/Model is Certain 90% or Not certain 5%
- Labelling additional 5% of data/10%/training
2. Key Features
Auto-labeling is a business solution that allows you to quickly generate labels for your training data through an
intelligent process of training your model by selectively labeling key data. It manually label a small amount of
unlabeled data, and learns label information and other labeled data together to quickly label the rest of the data. It
provides an automated labeling process by manually labeling data that is difficult to determine the label and
automatically labeling the confirmed data.
Manual labeling
Manual labeling involves researchers and developers intervening in labeling the data. Labels created through this
process are usually established labels. Automatic labeling technology provides a dedicated labeling tool that makes
manual labeling easier and faster.
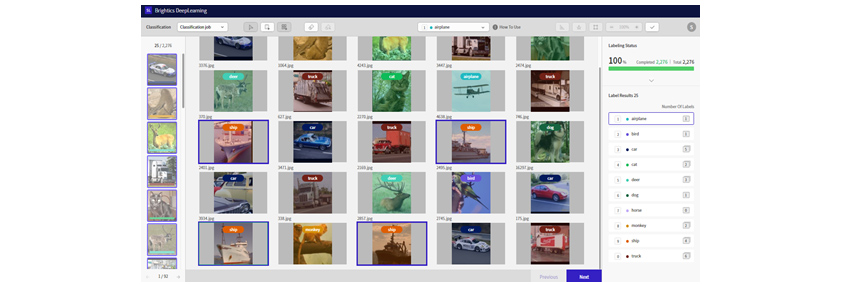 [Figure 7]
Manual Labeling Tool Screen
[Figure 7]
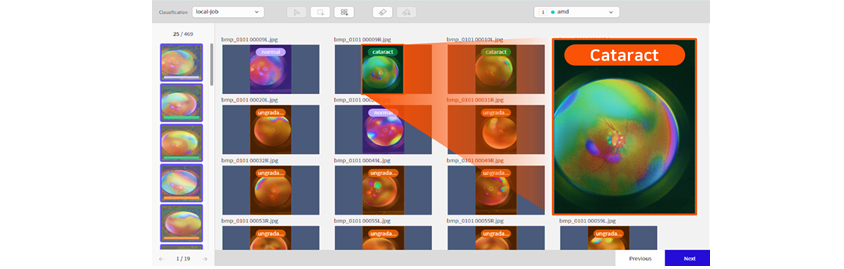
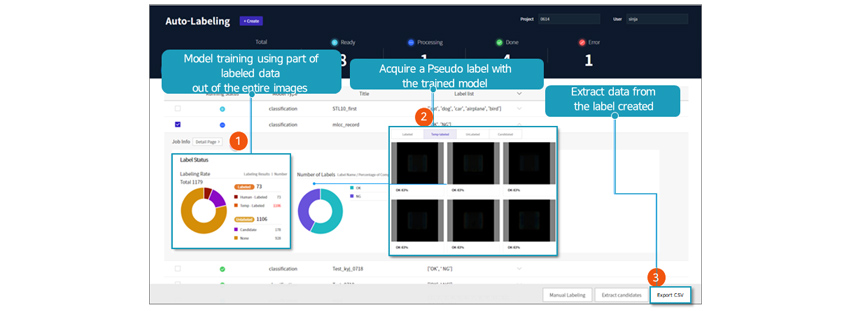
Manual Labeling Tool ScreenAutomatic labeling
Automatic labeling refers to a label predicted through a deep learning model. Labels created through this process are
not confirmed labels. This predicted label is used for learning using predicted labels, such as semi-supervised
learning, or for making manual labeling easier. Auto-labeling automatically labels unlabeled data using a small amount
of labeled data.
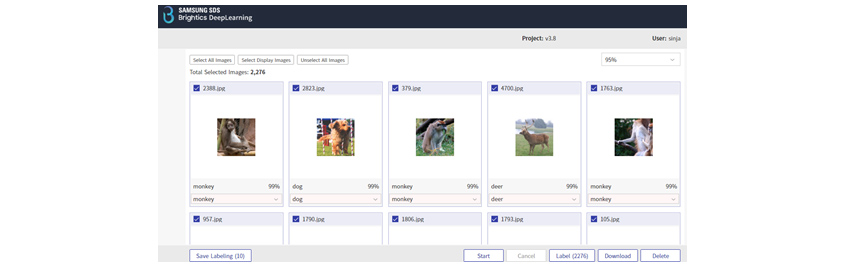 [Figure 8]
Auto Labeling Screen
[Figure 8]
Auto Labeling ScreenAutomatic Review
Automatic review analyzes data that has already been labeled and is used to improve data quality and improve learning
performance by separating or integrating existing labels.
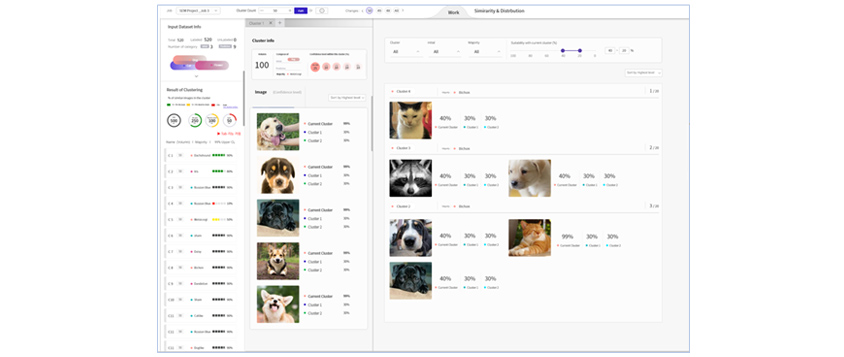 [Figure 9]
Automatic review
[Figure 9]
Automatic reviewLabel Manager
If multiple people collaborate to create large amounts of labels, Label Manager can help you create labels
efficiently. Administrators group the workers that produce labels to create label generation jobs. When jobs are
created, the Label Manager distributes the data to the group workers according to the settings of jobs. The
administrator can check the progress and the labels of each worker through Label Manager.
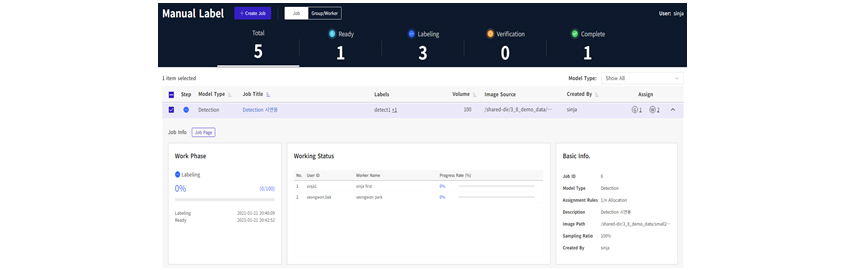 [Figure
10] Label Manager
[Figure
10] Label Manager3. Differentiating Points
Data Sampling
Automatic labeling samples images from a completely unlabeled state. Sampling extracts features from unlabeled images
in a dataset, and uses its own algorithm to select the desired number of images.
a. Has its own data sampling technology using Deep Features.
∙ Sampling technology that operates in an initial state without label.
∙ Improved performance by about 6% vs. random.
b. Has its own training model to improve performance.
∙ Recommend manual labeling image through Curriculum Learning method.
∙ 4~10% difference in average accuracy of Curriculum Learning vs. random.

- Auto Labelling DATA 0.1 89%,0.2 86%, 0.3 87%, 0.4 88%, 0.5 90%
- random 0.1 80%, 0.2 81%, 0.3 72%, 0.4 80%, 0.5 82%
- Auto Labelling DATA 0.1 89%,0.2 89%, 0.3 87%, 0.4 89%, 0.5 70%
- random 0.1 86%, 0.2 88%, 0.3 72%, 0.4 80%, 0.5 82%
98.1 % of automatic labeling accuracy, industry's highest level
The technology provides the industry's highest level of labeling performance with labeling accuracy of 98.1% compared
to 80% of public data and an automation rate of up to 1.8 times higher than that of Company A.
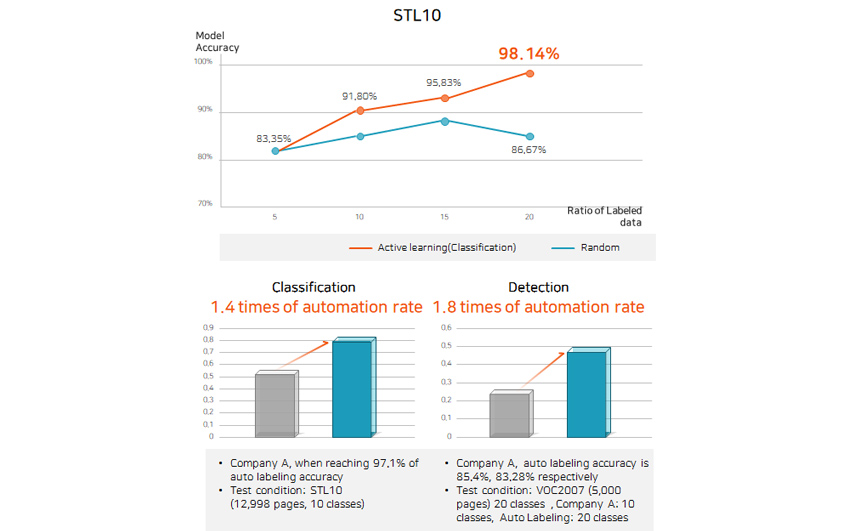
- Ratio of Random Labeled data - Model Accuracy 5-83.35%, 10 -85%, 15- 88%, 20-86.67%
- Ratio of Active learning(Classification) 5-83.35%, 10 -91.80%, 15- 95.83%, 20-98.14%
- Increased 0.5 to 0.8
- Company A Auto Labeling , when reaching 97.1% of auto lableling accuracy/Test condition :STL10(12,998pages, 10 classes)
- Increased 0.25 to 0.45
- Company A, Auto Labeling accuracy is 85.4%, 83.28% respectively /Test condition :VOC2007(5,000 pages) 20 classes ,Company A:10 classes, Auto Labeling: 20 classes
4. Use Case
Defects classification in manufacturing
Automatic labeling can be used for inspection of cell phone appearance and semiconductor wafer defects. You can save
time and cost by automatically labeling for classification of images with poor appearance. Automatic labeling can be
used to quickly generate labeling data sets for inspection of paint appearance defects that occur during the
automotive manufacturing process.

- Challenge
- Solution
- Benefit
- Defect images are classification by the person in charge with the naked eye, resulting in poor classification accuracy due to low-skilled workers and differences in work efficiency among workers
- Prepare training data using skilled workers/Propose model structures for deep learning training/Create & apply deep learning models
- Save costs and manpower required for simple, repectitive classification tasks/Reduce the required to build models
- Detection accuracy is low because the person in charge defective coating of the product moving on the conveyor with the naked eye
- create correct answer to train paint defect data/Preprocess data, create & apply deep learning models
- Reduce the time/Accelerate defect detection speed/Save manpower reauired for simple
5. Business Cases
Manufacturing
Multilayer Ceramic Capacitor (MLCC) data that is thinner than human hair requires more time for labeling.
Auto-labeling can save labeling time by labeling only some data (20%) and automatically labeling the remaining 80% of
data. In addition, when doing manual labeling, it is easier to label large amounts of data using a dedicated labeling
tool.
 [Figure 14] Use Case Screen
[Figure 14] Use Case ScreenTrials and tests by many companies
Currently, automatic labeling is expanding in trials and testing in public institutions and in a number of
companies.
6. Closing
So far, we have looked at the technology and application examples of automatic labeling. We started research on
automatic labeling in the process of finding a way to not manually label the data required for deep learning model
training every time. Since 2019, the technology has been applied mainly to manufacturing sites, and it is now
expanding its application to various fields such as finance and medical care. We therefore realize the need to secure
and understand field data more while applying automatic labeling to various industries. Automatic labeling will
continue to be applied to industrial sites for better performance improvement, thereby securing world-class
technological competitiveness and market differentiation.
※ In regards to Auto Labeling, Samsung SDS research centers in both Korea and America are conducting research &
development.
# Reference
https://www.samsungsds.com/kr/ai-dl/brightics-deep-learning.html
▶ The content is proected by law and the copyright belongs to the author.
▶ The content is prohibited to copy or quote without the author's permission.
- The First Step to Smart Textual Analysis, KoreALBERT
- Smart QA Model That Understands Even Complex Tables
- I Will Give You Data, Label It~ Auto Labeling!
- The Connecting Link for Everything in the World, It’s in the Knowledge Graph
- Easy and Simple Blockchain Management, Nexledger!
- No More Short of GPU!
- In the Age of When Customer Data Must Be Treated as a King, PET Will Take on the Responsibility
- It is Important to Prevent Security Risks from Development Phase! Trust CAFA+ to Do the Job

ML Research Team at Samsung SDS R&D Center
Seongwon Park has participated in the research and development of automatic labeling and distributed learning of the Brightics DL solution, and he is currently participating in the development of various platforms and technology research for AI.
If you have any inquiries, comments, or ideas for improvement concerning technologies introduced in Technology Toolkit 2021, please contact us at techtoolkit@samsung.com.
Related Articles
-
What Are Cheapfakes (Shallowfakes)?
-
Which One Is Real? Generating and Detecting Deepfakes
-
Brightics Visual Search Acknowledged in Global Market Research Reports
-
Exploring the West Hall Expansion at the Las Vegas Convention Center
-
[Technology Toolkit]
The Connecting Link for Everything in the World, It’s in the Knowledge Graph
-
[Technology Toolkit]
I Will Give You Data, Label It~ Auto Labeling!
The Connecting Link for Everything in the World, It’s in the Knowledge Graph
I Will Give You Data, Label It~ Auto Labeling!