

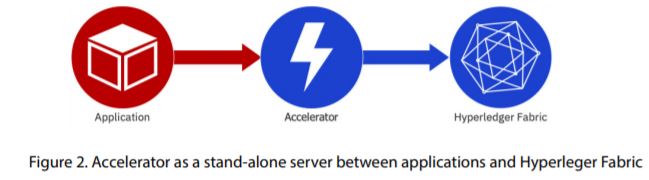
In its current incarnation, Accelerator exists as a stand-alone server for server-side acceleration. It is inserted between a blockchain application and Hyperledger Fabric networks as shown in Figure 2. Accelerator consists of three major components, which are Classifier, Aggregator, and Router, written in the Go programming language and utilizing Hyperledger Fabric Go SDK.
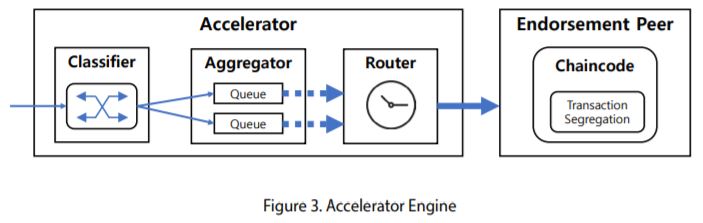
Components of accelerator
The fundamental tasks of Accelerator are to:
• classify received transactions with their destination which can be determined by a combination of channel, chaincode, and function name,
• aggregate the classified transactions into a new batched transaction, and
• route the batched one to a blockchain network for consensus.
1. Classifier
All transactions requested by the applications are passed to Classifier and categorized according to the transaction type. The transaction type is currently defined by a combination of the following elements:
• Channel name
• Chaincode name• Function name in the chaincode
2. Aggregator
A dedicated queue is assigned for each transaction type to collect the classified transactions. The classified transactions in a same batch should be in the same queue in Aggregator so that they can be processed altogether. Aggregator decides if it waits or submits a batched transaction to Router in accordance with the following conditions:
• Number of transactions
• Total size of transactions in bytes
• Wait time of the first transaction
• Occurrence of key duplication
Aggregator makes a batched transaction composed of all transactions in the queue as soon as when a combination of the conditions, which is generally given as a policy, is satisfied. For example, we can define a policy with a 10 as the number of transactions for collection, 1 MB for total size, 1 second for wait time. If any of one of these conditions is satisfied, for example 10 transactions arrive first, a batched transaction is generated and flushed out to Router.
A noticeable condition is checking the occurrence of key duplication, and it is used to compose the batched transaction with uncorrelated transactions only. One of the implementation examples of this feature is 1) keeping the records of keys of the transactions in Aggregator and 2) confirming the key existence in the records whenever a new transition arrives in Aggregator. If any duplication is found, a new batched transaction will be created with the transactions in the queue. In this case, the newly arrived one is not contained in the batch to avoid the collisions and then occupies another queue. This condition check must be preceded by the three conditions mentioned above.
3. Router
Router sends a batched transaction generated by Aggregator to an endorsement peer node through Hyperledger Fabric SDK. Then, the peer operates a verification process for each transaction in the batched transaction. Thus, a chaincode which segregates a given batched transaction into the individual single transactions should be supplementary installed in the endorsement peer. Finally, Router delivers the results to each application who requests the individual transaction included in the batched transaction.
Evaluation
Software test configuration
The following diagram shows the software configuration used to run use case tests. It details the main components in the test running on an IBM Cloud infrastructure as shown in Figure 4.
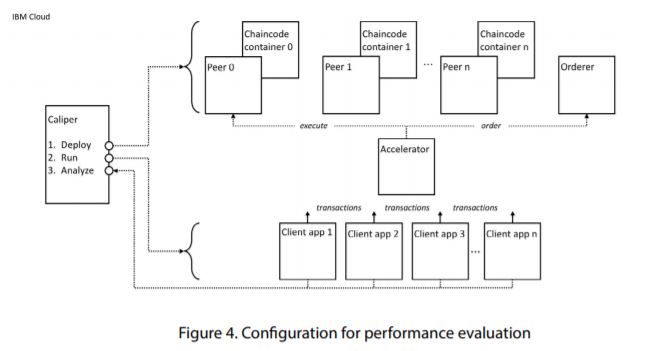
The software test configuration has the following components:
1. Caliper: This is the test harness technology used to deploy the test different components of the test, run the tests, and analyze the gathered results. Please refer to an official website for further information.
2. Peer nodes: These are the Hyperledger Fabric nodes that host copies of the blockchain ledger. A variable number can be configured; the results in this paper are for a configuration of 3 peers. The peer and orderer nodes jointly form a blockchain network.
3. Ordering node: This is the Hyperledger Fabric component that creates blocks of ordered transactions and distributes them to the different peer nodes in the ledger. The peer and orderer nodes jointly form a blockchain network.
4. Client applications: These are the applications that submit transactions to the network via Accelerator. Client applications do not talk directly to peer and orderer nodes as they would do in a normal Hyperledger Fabric network; they connect to Accelerator.
5. Accelerator: This component mediates interactions between client applications and the peer and orderer nodes that form the blockchain network.
This software configuration is running on IBM Cloud with the following resources allocated:
• 32GB of RAM
• 3.8 GHz quad core CPU
• 10 Gigabit network
• 960GB SSD
These resources are available to all the components in the test configuration according to real-time demand; the chaincode containers, peer and orderer nodes, client applications, and Accelerator share the available network, storage and CPU resources.
Test cases
The following use cases are run on this configuration.
1. Simple Query: A technical use case to measure simple ledger query on a single peer.
2. Simple Open: A technical use case to measure a simple update to a ledger.
3. Smallbank Query: A more “real world” query of a bank account in a ledger.
4. Smallbank Operations: A more “real world” update to a bank account held in a ledger
5. Smallbank Clash: A more realistic update to a bank account, with a variable degree of account collisions requiring transaction resubmission.
In Simple Query, an application invokes a chaincode via Accelerator, which collects a set of concurrent requests into a single batch (called a job). When the batch is full (according to an Aggregator), Accelerator invokes a modified chaincode with the job. The chaincode modification deblocks the job into individual invocations, which are then executed as normal. In Simple Query,each invocation queries the ledger by key for a single state using the getState() API. The aggregated response is returned to Accelerator, which dissembles it and notifies the applications with the result of their query.
In Simple Open, processing proceeds as Simple Query, but the chaincode invocations involve state changes rather than queries. Specifically, chaincode invocation updates the ledger by creating a new state using the putState() API. The aggregated response is returned to Accelerator which creates a transaction, orders it and waits to be notified that it has been committed. In then notifies the individual applications that their transaction has been committed (or failed). The Smallbank use cases are more realistic than the Simple use cases; they attempt to model a ledger of bank accounts which are being queried or having funds transferred between them. Most importantly, transaction collisions can occur where overlapping transactions are processed at the nearly same time. Processing proceeds as Simple Open, but chaincode invocations are subject to world state collisions. Specifically, each chaincode invocation updates the ledger with the getState() and putState() APIs, but there is an opportunity for different transactions to update the same state. Such a collision will result in an invalid job transaction being detected after the transaction has been ordered, resulting in the failure of all transactions in a job.
Detailed result
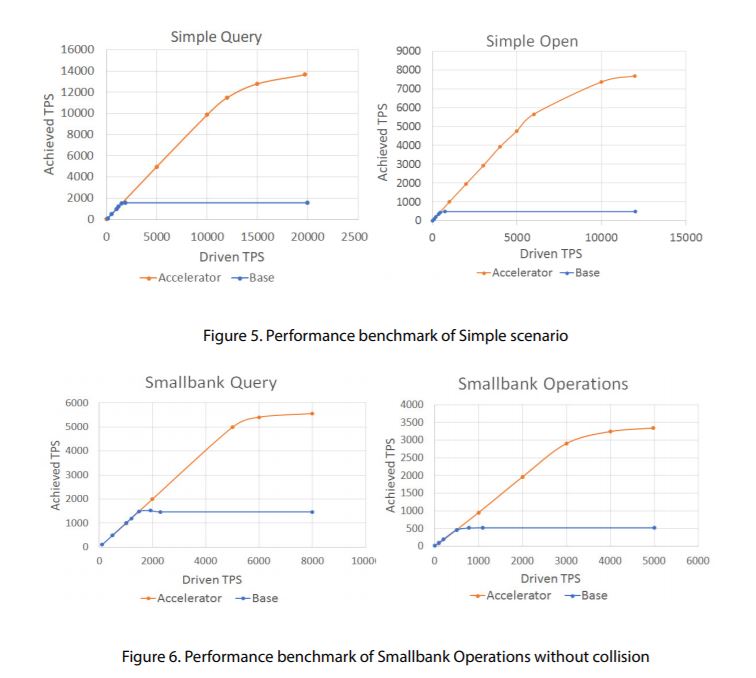
The graphs in Figure 5 correspond to the two basic forms of Accelerator use case – Simple Query and Simple Open. For both use cases, we can see how the driven transaction rate on the x-axis affects the achieved transaction rate on the y-axis; we vary the driven transaction rate, and the achieved transaction rate is the dependent variable. In the base case, without Accelerator, we can see linear growth up to 1,500 transactions per second (TPS). Above this rate, there is no gain in the achieved rate no matter how much the driven rate is increased. The system is effectively saturated at this point.
In the meantime, the result with Accelerator is significantly improved. We can see that for driven transaction rates up to 1500 TPS, the achieved transaction rate grows in the same manner as the base rate. However, with Accelerator, we are able to linearly drive query transactions up to an achieved rate of 11,000. Above this rate, transactions start to queue, as with the base case. For Simple Query, using Accelerator represents an improvement of approximately 600%. For Simple Open, we can see that the achieved rates are less than Simple Query because this use case has more work to do – transactions need to be executed, ordered then validated before they appear on the ledger. In the base case, we can see a linear growth up to 450 TPS, but after this point, the achieved rate again starts to plateau as the system becomes saturated.
Again, the result with Accelerator is significantly improved. We can see that there is near linear growth up to an achieved transaction rate of 5,000 TPS, which represents an improvement of 1,000%. This is even better than query; the use of Accelerator is more advantageous for update style transactions than query style transactions.
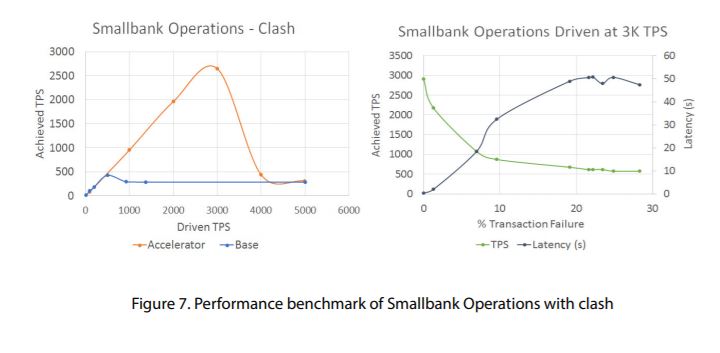
The graphs in Figure 7 correspond to the more real-world versions of the use cases – Smallbank query and Smallbank operations. For the Smallbank use cases, we can see very similar behavior to the Simple use cases. Accelerator makes a significant difference in throughput for these more real-world use cases. The improvement ratios are of the order of 300% and 600% respectively. We continue to see that the use of Accelerator is more advantageous for update style transactions than query style transactions, although both are significantly improved.
The biggest difference with Smallbank use cases are clear however, when collisions are introduced, and the graphs below correspond to the more real-world versions of the ledger update use case with collisions included. The first graph is the same as Smallbank Operations, but with collisions occurring naturally. Up to about 3,000 TPS, collisions will not occur at any significant rate, and so the achieved transaction rate follows the same trajectory as Smallbank Operations. However, above this rate, collisions start to occur and increase, and thus affects the throughput rate. We see as the driven rate is increased, achieved rate becomes the same as that without Accelerator.
In the second graph, a fixed driven rate of 3,000 TPS is used and the collision rate varied. The graph shows the effect of increasing the collision rate on achieved TPS and latency on the y-axis. We can see that as the collision rate is increased, the transaction rate declines, and the latency increases.
In summary, the Smallbank clash use case and the two graphs above show that the benefits of Accelerator are lost once the rate of collision gets to about 10%. This reinforces the fact that for Accelerator to work best, transactions should be independent of each other.
Use case recommendation - Scenarios
Simple example for IoT
IoT devices and/or sensors applications represent a class of applications that exhibits characteristics particularly suitable for Accelerator. Namely, IoT applications (1) require high throughput due to potentially extremely high volumes of transactions and (2) are at the same time particularly suitable for acceleration due to transaction independence. IoT applications typically collect data and transactions from a high volume of independent devices with each device typically having its own unique identifier and each device possibly periodically generating either time series data or independent sensor readings which are not likely to correlate with other devices’ data because of the data characteristics. Due to that, it is typically possible to record each transaction in a separate, unique key which in turn leads to a very low possibility of the correlated data occurrence (e.g., transactions trying to update data with the same address or key at the nearly same time). In such cases, Accelerator can aggregate many transactions without expecting collisions between transactions. The client-side acceleration scheme may be used in an IoT Access Point.
Simple example for financial services
As the second class of applications, we have selected an example application scenario from the Financial Services space in which transactions correlations and possible update conflicts are more likely. This case has individual bank account holders sending transactions for money transfer that may have transactions with many correlations. Because it is possible and, in some cases, even likely that potentially many transactions can be associated with a particular account, it is more likely to encounter transaction update conflicts that are trying to update the same key concurrently at about the same time. Such conflict situation can make application of Accelerator less efficient as we are going to illustrate. However, unless the transactions with higher correlation are generated at the nearly same time, i.e., within the same block generation period (e.g. 1 sec), one can still expect the Accelerator benefits. Server-side Acceleration may be suitable. In most practical scenarios in this category while the conflicts and concurrent updates are possible, they will be typically spread over longer period of time and therefore make the use of Accelerator still very suitable.
Not applicable/contraindicated use cases, in summary
Accelerator may be less suitable for the cases where many simultaneous, concurrent transactions are trying to update a very small number of addresses with the same keys. In such cases, the many interdependent concurrent updates of the same key can lead to potentially many update conflicts which in turn create a situation where Accelerator performance decreases substantially and therefore makes its use less applicable. Such scenarios may include applications in which many users or blockchain clients want to update data on a very small number of addresses or with the same key values. For example, the scenario may include financial data exchanges (e.g., some stock exchange scenarios) on a few public accounts to deal with many concurrent requests from a large number of clients’ accounts (e.g., high volume of stock exchange transactions need to be recorded or netted or settled with respect to a small number of accounts). In this case, the number of aggregated transactions in a time (i.e., transactions that are “non-conflicting”) would be very small so as to keep avoiding the collisions, which means there would be small or no acceleration gains in such a case.

Ted Kim is Vice President of Enterprise Blockchain at Samsung SDS America.
- CES 2025 Through the Eyes of a Samsung SDS Digital Marketer!
- An Agile Approach, the Core of Corporate DT for Working Culture Innovation
- Digital ESG, a Critical Success Factor for ESG
- Conversational AI War Begins. Who Will Be the Winner?
- What Is Matter, the New Smart Home Standard?
- 2023 Forecast for Technology Trends