[Technology Toolkit]
The Connecting Link for Everything in the World, It’s in the Knowledge Graph

Technology Toolkit 2021 is a technical white paper describing core technologies that
are being researched and developed by Samsung SDS R&D Center. We would like to introduce in this paper a total of
seven technologies concerning AI, Blockchain, Cloud, and Security with details on their technical definition, key
features, differentiating points, and use cases to give our readers some insights into our work.
Insight Engine
1. Introduction to Technology
Technology Trends and Background
Knowledge graph is a representation of knowledge structure showing related information in edges and nodes. When
information is stored in knowledge graph format, information of high relevance can easily be identified and thus
provide users with richer information.
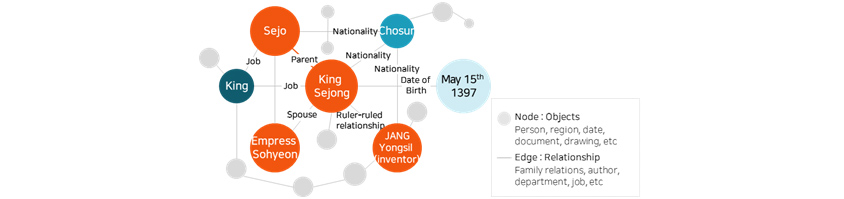 [Figure 1] Knowledge Graph
[Figure 1] Knowledge GraphInformation retrieval is one area where knowledge graph can be put to its best use. In the past, data were stored
using inverted index method (linking the texts and location of keywords within a set of documents) for information
retrieval. This method can show documents containing query without a problem, but it is limited in that it
doesn’t show related information.
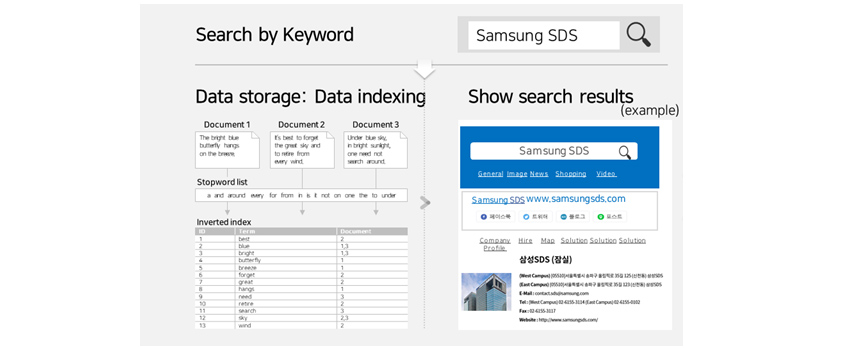 [Figure
2] Inverted Index Method (Users search for information by entering keywords into a search engine and when the
results appear with related links, they click on the link that seems most relevant. They repeat the search process
until the desired information is retrieved)
[Figure
2] Inverted Index Method (Users search for information by entering keywords into a search engine and when the
results appear with related links, they click on the link that seems most relevant. They repeat the search process
until the desired information is retrieved)
Building knowledge graph is the key to advancing information retrieval and delivering desired answers with related
information in clear format. Knowledge graph technology has high utility value as proven by its inclusion in Gartner's
Top Ten Data and Analysis Technology Trends[3] in 2019, and we expect to see it applied to broader area
moving forward. In this paper, we will give you an overview of knowledge graph – which is also being actively
adopted by leading global IT companies like Google and Amazon for storing knowledge for advanced search– and
some of the solutions that incorporate knowledge graph.
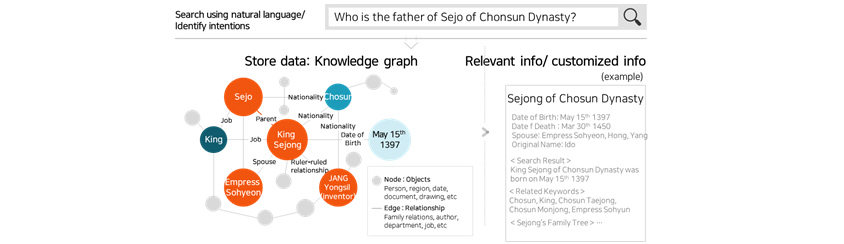 There is a
result on "who is the father of Sejo of Chosun Dynasty?" On the left side, there is a knowledger graph described on
Figure 1, and the right side there are relevant info about King Sejong like date of birth/death, spouse, and
original name.[Figure 3] Advanced information retrieval using knowledge
graph
There is a
result on "who is the father of Sejo of Chosun Dynasty?" On the left side, there is a knowledger graph described on
Figure 1, and the right side there are relevant info about King Sejong like date of birth/death, spouse, and
original name.[Figure 3] Advanced information retrieval using knowledge
graphDefinition
① Knowledge Graph
Knowledge graph refers to knowledge stored in graph format comprising of nodes and edges – node for data on
individual entity and edge for an association between each
entity. The main purpose of presenting data in knowledge graph format is that graph is the most useful data structure
for accumulating and delivering knowledge with their
association.
② Knowledge Design
Because knowledge holds different concept and purpose depending on the area where it was accumulated, nodes and edges
of knowledge graph should contain information that differs by area. Knowledge design is the process of specifically
deciding which types of nodes and edges to use in accordance with the final information that will be provided to users
using knowledge graph.
③ Knowledge Engineering
Knowledge graph is constructed by analyzing data collected from multiple data sources. It takes text data such as
documents and uses natural language analysis technology to analyze, convert and accumulate them in nodes and edges. In
order to overcome the limitations of natural language processing technology and to reflect newly emerging data,
knowledge experts must check knowledge graph periodically and modify data not correctly accumulated. This process is
called knowledge engineering.
Technical Features
Knowledge graph offers many advantages over traditional table-based databases. First, it allows you to infer
relationship (reasoning) that is not explicitly defined. With existing table-based database, if the relationship
between entities is not clearly defined in the table, it would be impossible to infer their relationship, but with
knowledge graph, it is possible to explore and infer new relationship based on previously defined relationship of
knowledge graph. Second, knowledge graph yields better performance for query that can only be answered using multiple
references. Let’s say you enter the following query "show me the document cited by the document that was cited
by the proposal" into database. With existing table-based database, both the document table and the tables
representing the citation relationship must be referenced, which increases the number of data accesses. On the other
hand, the knowledge graph requires only few approaches to find an answer to your query because the documents are
linked to citation relationships. Finally, when there is a change in data such as adding of a new data or deleting or
changing of existing data, the knowledge graph can easily incorporate these changes. With existing database, every
time a new type of data is added, a table must be extended, and its relevance to existing data has to be considered
thoroughly. This will not only put a financial burden on calculation, but may compromise data integrity as well. It is
very easy to manage knowledge graph because all you have to do is just add or delete nodes from the existing knowledge
graph, and connect or delete edges based on the relationship between existing nodes.
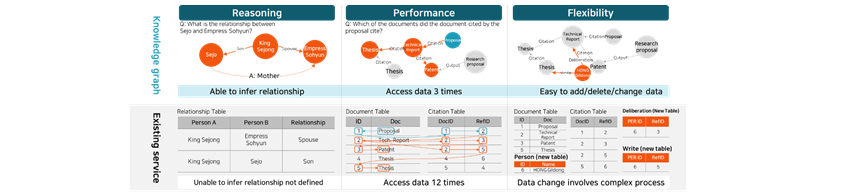 Advantages
of knowledge graph over existing database: reasoning(able to infer relationship), performance(access data 3 times),
flexibility(easy to add/delete/change data). [Figure 4] Advantages of knowledge graph
technology over existing database
Advantages
of knowledge graph over existing database: reasoning(able to infer relationship), performance(access data 3 times),
flexibility(easy to add/delete/change data). [Figure 4] Advantages of knowledge graph
technology over existing database2. Key Features
We provide functions needed to organize, manage and use unstructured text data as a knowledge graph in a set of
technologies called SDS Insight Engine. Our SDS Insight Engine builds knowledge graph from knowledge information
database owned by a company using AI- based unstructured text analysis technology. In addition, our solution offers
API that can advance information retrieval and recommendation service using knowledge graph.
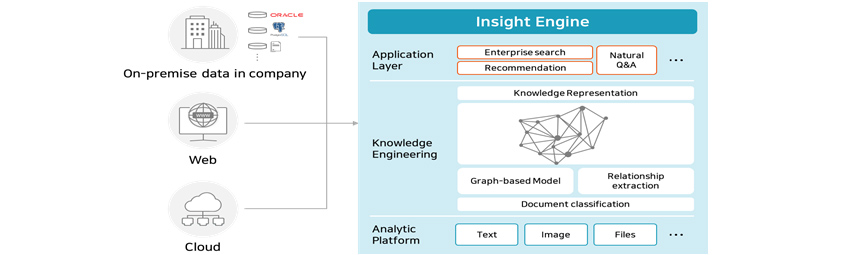
- Web
- Cloud
- Application Layer - Enterprise Search, Recommendation - Natural Q & A
- Knowledge Engineering - Knowledge Representation, Object, Graph-based Model, Relation ship extraction, Document classification
- Analytic Platform - text, Image, Files
Analytic Platform: analyzes various data stored in multiple sources
Knowledge information data held by a company are stored in various repositories ranging from DB, web, to cloud. The
information is stored as images as well as text and attachments of various formats. Our Insight Engine basically
extracts knowledge from unstructured text data but it can also extract and analyze texts that are in image format or
are included in office documents of various format (pdf, doc, ppt, pdf, html).
Insight Model Layers: builds knowledge graph using natural language processing technology
Our Insight Engine builds knowledge graph by analyzing unstructured text data obtained from data source, therefore
basic language analysis tools such as morpheme analysis, language identification, entity name recognition, tokenizer,
and relation extraction module are provided to support the analysis. We provide API that builds a personalized
recommendation model based on the knowledge stored in knowledge graph. To build and utilize knowledge graph, you need
graph database that’s equipped with a function for storing and finding knowledge information. Our Insight Engine
is designed to build knowledge graph using JanusGraph or neo4j, an open source graph database. We provide API with
varying functions that can add or delete edges and nodes and search nodes as well as sub-nodes in knowledge graph when
query is entered.
Application Layer: API that can apply knowledge graph to search enhancement, personalized recommendation, and QA system
The knowledge accumulated in knowledge graph can be used in conjunction with existing AI model designed for search,
recommendation, classification, and prediction. In addition, our Insight Engine can be applied to application service
that provides complex question-answering from natural language knowledge stored in knowledge graph using natural
language processing (NLP) and understanding technology (NLU). SDS Insight Engine offers the following features.
Integration of multiple data sources
∙ Integrates and leverages image and audio data as well as text (E-Mail, HTML) data
Recognizes intention and situation
∙ Recognizes intention and situation through AI-based natural language processing
∙ Provides meaningful information by extracting relationships from knowledge graph
Knowledge scalability
∙ Expands knowledge with configuration of relationships between data sources
∙ Efficiently updates and operates information collected/changed in real time
AI-based solution
∙ Provides complex question-answering using natural language processing and understanding (NLP, NLU) technology
∙
Connects to existing search/recommendation/classification/predictive AI model
3. Differentiating Points
Automated graph generation using AI-based natural language processing technology
Customers who are thinking of adopting knowledge graph to advance their information retrieval system are burdened by
the thought of having to build and run a new knowledge graph separately from their existing search system. But this is
not a problem with our SDS Insight Engine. Our Insight Engine comes with automation function that integrates knowledge
information databases and stores information in knowledge graph with ease. For example, our Insight Engine refers to
database schema and extracts node information like the name of a person/place/company and document category as well as
their relationships. Moreover, it extracts text data from the attachment file and uses it in natural language
processing analysis.
Nowadays, a lot of knowledge is stored in image format (jpg, png, etc.) like document scan, or in structure format
containing both text and tables (such as html), making it difficult to extract information and create knowledge graph
using existing technology. The advantage of SDS Insight Engine lies in that it can handle information stored in
various formats – it can extract and analyze unstructured data using the right text extract technology and build
knowledge graph.
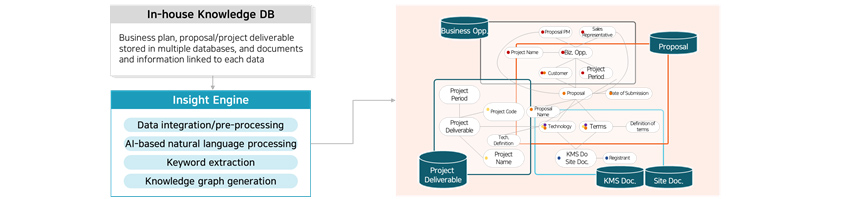
- Business plan,proposal/project deliverable stored in multiple databases, and documents and information linked to each data
- Data integration/pre-processing
- AI-based natural language processing
- Keyword extraction
- Knowledge graph generation
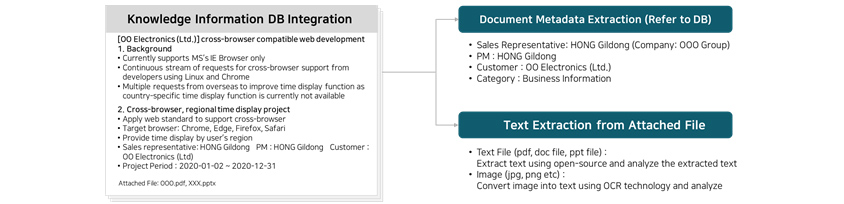
- [00 Electronics(Ltd.)]cross-browser compatible web development
- 1.background-Currently supports MS's IE Browser only/Continuous stream of requests for cross-browser support from developers using Linux and Chroms/Miltiple requests from overseas to improve time display function as country-specific time display function is currently not available
- 2.Cross-browser. regional time display project-Apply web standard to support cross-browser/Target browser:Chrome, Edge, Firefox, Safari/Provide time display by user's region/Safari representative : HONG Gildong PM:HONG Gildong/Customer : 00 Electronics (Ltd.)/Project Period:2020-01-02~2020-12-31
- Attacted File:000 pdf,XXX.pptx
- Sales Representative : HONG Gildong (Company : 000 Group)
- PM : HONG Gildong
- Customer : 00 Electronics (Ltd.)
- Category : Business Information
- Text File (pdf, doc file,ppt file): Extract text using open-source and analyze the extracted text
- Image 9jpg, png ect): Convert image into text using OCR technology and analyze
Our Insight Engine brings unstructured text data from knowledge information dataset and associated attachments, and
uses AI-based natural language processing technology to extract meaningful entity names and their relationship. Named
entity recognition is a technology that extracts words fitting pre-defined classification from unstructured text such
as the name of a person, organization, or place, and these extracted words become the nodes of knowledge graph. Named
entity recognition technology incorporated into our SDS Insight Engine is unique in that it complementarily uses deep
learning technology and dictionary-based method which means our deep-learning based model understands context and
recognizes unlearned name of a new company or person with flexibility and customizes dictionary to handle documents of
unfamiliar new domains such as humanities, business medical science or finance. Furthermore, when the relationship
between entities need to be defined in knowledge graph, our AI-based relationship extraction model refers to the
context of document and selects relationship that best describes them.

- [00 Electronics(Ltd.)]cross-browser compatible web development
- 1.background-Currently supports only IE Browser of MS/Continuous stream of requests for cross-browser support from developers using Linux and Chroms/Miltiple requests from overseas to improve time display function as country-specific time display function is currently not available
- 2.Cross-browser. regional time display project-Apply web standard to support cross-browser/Target browser:Chrome, Edge, Firefox, Safari/Provide time display by user's region/Safari representative : HONG Gildong PM:HONG Gildong/Customer : 00 Electronics (Ltd.)/Project Period:2020-01-02~2020-12-31
- Attacted File:000 pdf,XXX.pptx
- [00 Electronics:ORG(Ltd.)]cross-browser:TRM compatible web development
- 1.background-Currently supports only IE : TRM Browser of MS : ORG/Continuous stream of requests for support from developers using Linux and Chroms/Miltiple requests from overseas to improve time display function as country-specific time display function is currently not available
- 2.Cross-browser:TRM, regional time display project-Apply web standard to support cross-browse:TRM/Target browserTRM:Chrome:TRM, Edge:TRM, Firefox:TRM, Safari:TRM/Provide time display by user's region
- Attacted File:000 pdf,XXX.pptx
- Currently/ IE:TRM/ MS:ORG
- Product
- Related
- Synonym
- Founder
- The relationship that best describes entities is selected from thw list of relationship candidates by referring to the context
Application API including search enhancement, personalize recommendation and QA system
We provide application API that allows you to use knowledge graph to areas such as QA system or natural
language-based search enhancement. We provide differentiated knowledge graph-based technology using our top notch
multi-hop QA technology (QA system that answers questions by analyzing or making inferences upon review of multiple
documents) and Korean reading comprehension (MRC) technology.
For detailed descriptions and differentiating points of our QA technology, please refer to “smart QA model that
even understands complex tables”. Personalized recommendation is also one area where knowledge graph can become
of use. The limitations of traditional recommendation system can be alleviated by showing information related to the
data recommended by personalized recommendation algorithm using knowledge graph. Please refer to “4. Business
Cases” for real examples of using knowledge graph for advanced information retrieval and personalized
recommendation.
 [Figure 9] Expansion of personalized recommendation keywords using knowledge graph
[Figure 9] Expansion of personalized recommendation keywords using knowledge graph
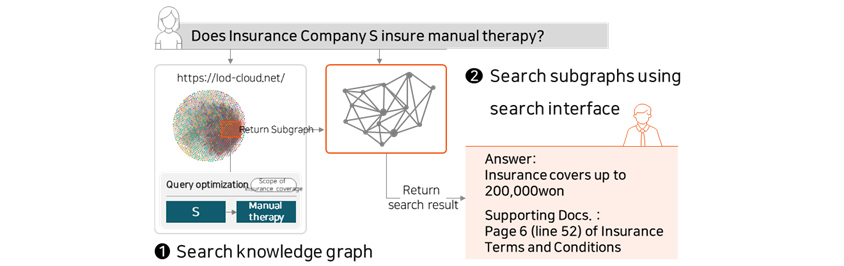
Search konwledge graph, Search subgraphs using search interface Question answering system
Question : Does insurance company s insure manual therapy?
- Search knowledge graph
- https://lod-cloude.net
- return subgraph
- query optimization : s-> manual therapy
-
Search subgraphs using search interface
- Answer: insurance covers up to 200,000won
- Supporting docs: page 6(line 52) of insurance terms and conditions
4. Business Cases
Search enhancement and knowledge recommendation service for Samsung SDS in-house knowledge management system
Knowledge Management, the process of leveraging knowledge database to handle various business issues and make sound
business decisions, is becoming a global business trend. As a result, there is a growing demand for technology that
enables companies to integrate, manage and search various knowledge data they own.
Knowledge graph shows its qualities the best when it comes to enterprise search. It shows related information along
with the data requested from scads of corporate documents and in-house technologies thereby promising users with rich
set of information.
In line with this global trend, we applied knowledge graph-based search enhancement and knowledge recommendation
solution to ARISAM, our internal knowledge portal system. We used our Insight Engine to integrate and analyze scads of
documents pertaining to business opportunities, proposals, and project deliverables that are scattered across 28
different internal web sites, as well as their metadata and attachments of various formats and we built all this
knowledge into a single knowledge graph structure. In addition, we designed the system so that when questions are
entered in a search box, the system retrieves related information - keywords, businesses, employees, and recommended
knowledge - from knowledge graph and show them on the result screen along with the information requested.
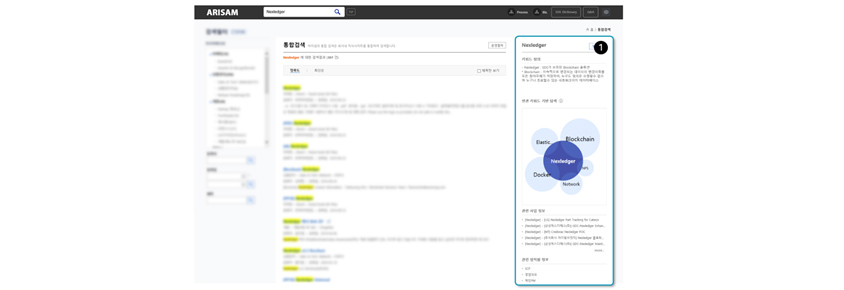 [Figure 11] Using knowledge graph to advance information retrieval for our internal knowledge portal
site (① Shows related information retrieved from knowledge graph including keywords, business, employees, and
recommendations)
[Figure 11] Using knowledge graph to advance information retrieval for our internal knowledge portal
site (① Shows related information retrieved from knowledge graph including keywords, business, employees, and
recommendations)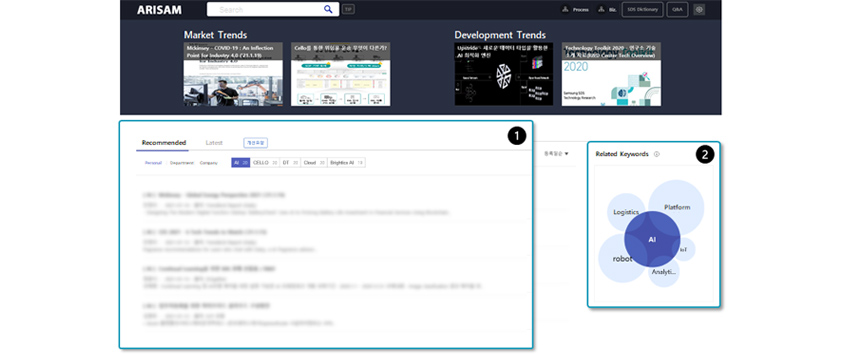 [Figure
12] Knowledge recommendation service based on keywords of personal interest (① Provides personalized
recommendations, team/corporate-level recommendations, ② Provides a map of related keywords)
[Figure
12] Knowledge recommendation service based on keywords of personal interest (① Provides personalized
recommendations, team/corporate-level recommendations, ② Provides a map of related keywords)5. Closing
Because knowledge graph technology is still a work in progress, a lot needs to be done before we can actually make it
available for business adoption. We need to make specific plans in advance as to what data to use to build which
service and design which information to accumulate in knowledge graph. We would also need knowledge engineers in
implementation and operation phase to provide continuous quality management of knowledge.
We expect these remaining works will help us build more insightful search engine that will allow us to explore various
connecting relationships in data with flexibility.
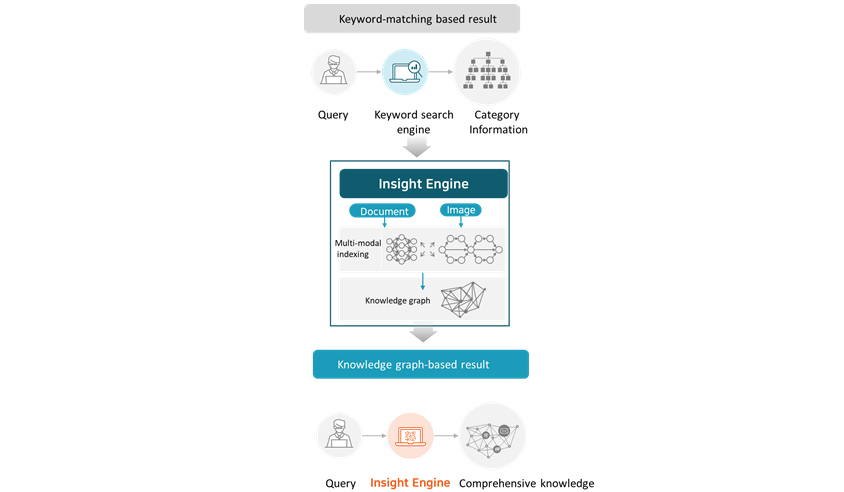
- Keyword-matching based result
- query -> keyword serch engine -> category information
- Insight Engine
- document, image, multi-modal indexing
- knowledge graph
- knowledge graph-based result
- query -> insight engine -> comprehensive knowle

# References
[1] https://developer.apple.com/library/archive/documentation/UserExperience/Conceptual/SearchKitConcepts/searchKit_basics/searchKit_basics.html
[2] http://snap.stanford.edu/decagon
[3] https://www.gartner.com/smarterwithgartner/gartner-top-10-data-analytics-trends/
▶ The content is proected by law and the copyright belongs to the author.
▶ The content is prohibited to copy or quote without the author's permission.
- The First Step to Smart Textual Analysis, KoreALBERT
- Smart QA Model That Understands Even Complex Tables
- I Will Give You Data, Label It~ Auto Labeling!
- The Connecting Link for Everything in the World, It’s in the Knowledge Graph
- Easy and Simple Blockchain Management, Nexledger!
- No More Short of GPU!
- In the Age of When Customer Data Must Be Treated as a King, PET Will Take on the Responsibility
- It is Important to Prevent Security Risks from Development Phase! Trust CAFA+ to Do the Job

ML Research Team at Samsung SDS R&D Center
As a machine learning-based model and solution researcher & engineer with a major in a brain engineering, Sunghoon JOO is involved in knowledge graph construction and advanced search using AI natural language processing technology.
If you have any inquiries, comments, or ideas for improvement concerning technologies introduced in Technology Toolkit 2021, please contact us at techtoolkit@samsung.com.
Related Articles
-
Brightics Visual Search Algorithm Claims 5th Place in NIST Face Recognition Vendor Test
-
What Are Cheapfakes (Shallowfakes)?
-
Which One Is Real? Generating and Detecting Deepfakes
-
Brightics Visual Search Acknowledged in Global Market Research Reports
-
[Technology Toolkit]
The Connecting Link for Everything in the World, It’s in the Knowledge Graph
-
[Technology Toolkit]
I Will Give You Data, Label It~ Auto Labeling!
The Connecting Link for Everything in the World, It’s in the Knowledge Graph
I Will Give You Data, Label It~ Auto Labeling!