Data Ingestion
- 실시간 데이터 수집
- 대량/로그 데이터 수집


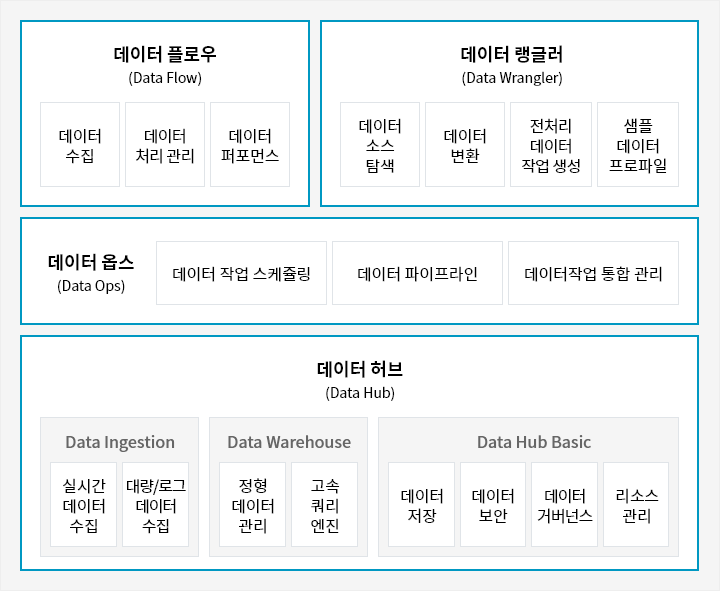
데이터 라이프사이클 전반을 관리·지원하는 데이터 플랫폼
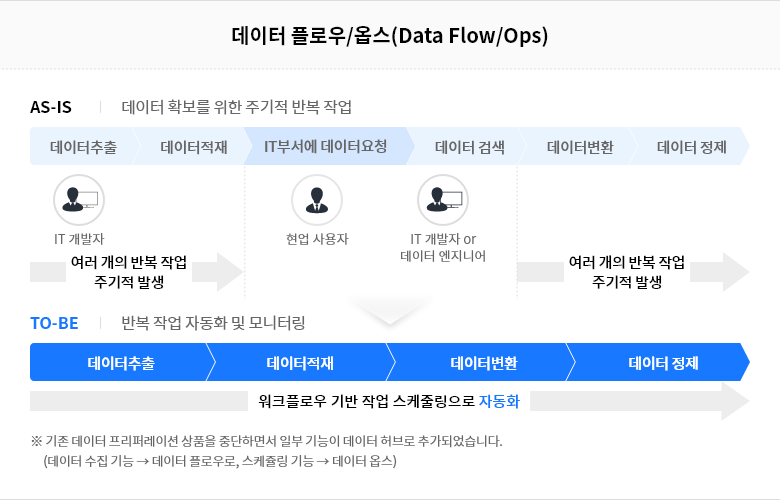
오픈소스 Nifi와 Airflow를 기반으로 다양한 유형의 데이터를 수집하고 작업을 정의하여, 워크플로우 기반의 데이터 스케줄링 기능을 제공합니다. 또한, 매니저 포털에서 서비스별 리소스 활용 현황도 모니터링할 수 있습니다.
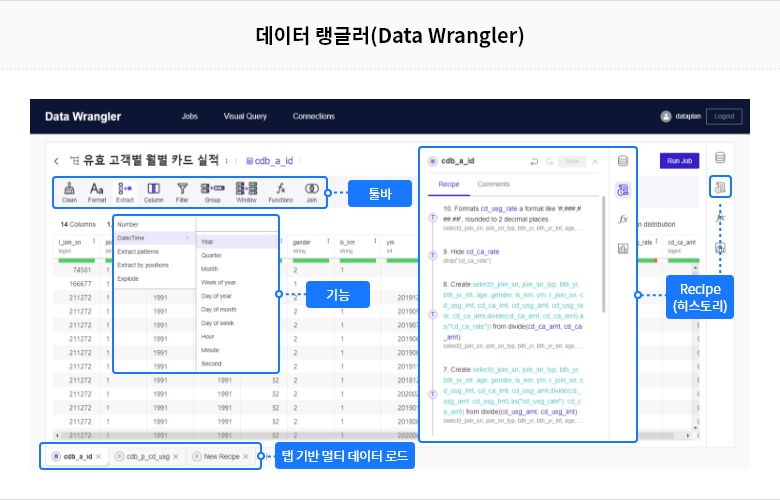
로우 코드 전처리 기능을 제공하여 누구나 쉽게 데이터 전처리를 수행할 수 있습니다.
또한, 데이터 프로파일링을 통해 데이터 탐색 및 데이터 분포 현황, 통계정보 등을 확인할 수 있고, 조인의 유형 및 조건을 몇 번의 클릭만으로 구성할 수 있으며 데이터 원천 확인이 가능합니다.
임계치 기반의 진단 기능으로 장애를 사전에 대응하고, 통합 로그 모니터링으로 모든 서비스 로그를 한 번에 확인하여 조치할 수 있는 가이드를 제공합니다.
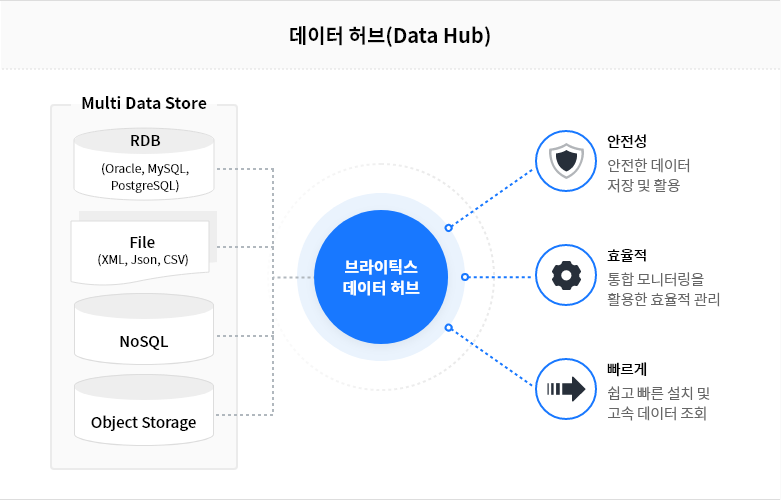
뿐만 아니라, 웹 기반으로 쉬게 설치할 수 있고, 하이브 쿼리 대비 약 11배 빠른 쿼리 성능을 제공받을 수 있습니다.
* 구성 오퍼링을 클릭해 보세요.

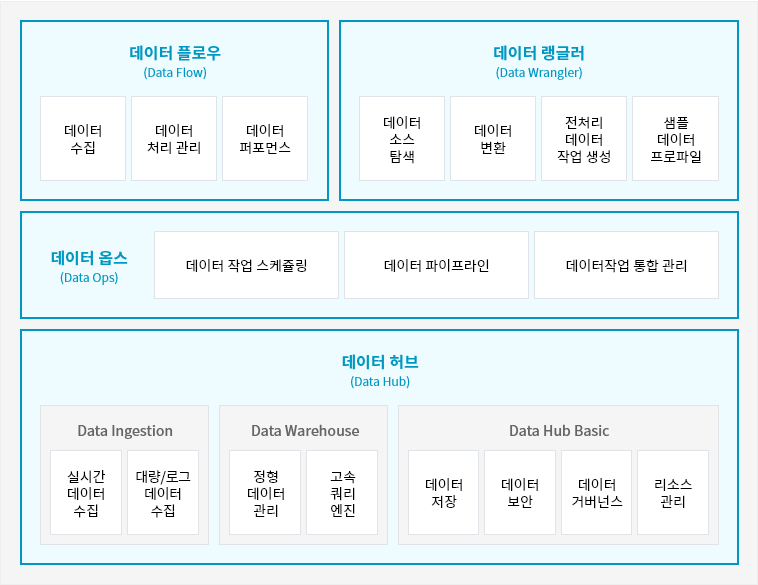
Data Ingestion
Data Warehouse
Data Hub Basic
수많은 채널로부터 다양한 소스와 유형의 데이터를 손쉽게 수집할 수 있습니다.
실무자에게 익숙한 엑셀과 유사한 기능을 제공하여, 데이터를 탐색하고 원하는 형태로 재구성할 수 있습니다.
데이터 수집 Job을 관리하고 스케줄링 및 모니터링할 수 있습니다.
하둡 생태계를 기반으로 데이터를 안전하게 저장 및 분석하고, 효율적으로 관리할 수 있는 모니터링 체계를 제공합니다.
[Recognition] 삼성 SDS, IDC MarketScape APEJ AI Life-Cycle 소프트웨어 분야 리포트 국내 유일 우수 벤더로 최초 등재
IDC MarketScape: Asia/Pacific (Excluding Japan) AI Life-Cycle Software Tools and Platforms 2022 Vendor Assessment (Doc # AP48940522)2022.10
[Recognition] 삼성SDS는 IDC에서 발간한 MarketScape: Asia/Pacific Vision AI Software Platform 2021 Vendor Assessment 리포트에서 Major Player 중 하나로 선정
MarketScape Asia/Pacific (Excluding Japan) Vision AI Software Platform 2021 Vendor Assessment, IDC2021.10



X86 서버 기준, 3 노드 이상으로 구성
- CPU : 16코어/노드
- 메모리 : 128GB/노드
- 디스크 : 1TB/노드
- 운영체제 : CentOS, RHEL 7.x
X86 서버 기준, 3 노드 이상으로 구성
- CPU : 16코어/노드
- 메모리 : 256GB/노드
- 디스크 : 4TB/노드
- 운영체제 : CentOS 7.x, RHEL 7.x
SDS Cloud, Amazon Web Service, MS Azure, Google Cloud 등
- 브라우저 : Chrome (50.0 버전 이상)
- 해상도 : 1280 * 900 권장
![]()
브라이틱스 데이터 허브에 대한 사용자 가이드입니다.


삼성SDS의 AI 전문가들이 무엇이든 친절하고 신속하게 답변해 드립니다.