

General AI vs Narrow AI
인공지능(Artificial Intelligence, AI)은 컴퓨터 시스템을 사용하여 인간의 지능적인 작업을 모방하거나 수행하는 것을 말합니다. 초기의 인공지능은 인간의 전문 지식을 기반으로 미리 정의된 규칙과 논리에 따라 단순 반복적인 작업을 주로 수행했습니다. 인공지능의 하위 분야로서 등장한 머신러닝(Machine Learning)은 인간이 쉽게 이해하거나 분별하기 어려운 패턴과 확률적 분포를 학습하여 인사이트를 제공함과 동시에 미래를 예측하여 의사 결정에 도움을 주었습니다. 머신러닝에서 한 단계 더 나아가 발달한 딥 러닝(Deep Learning)은 인간의 신경계 구조에 착안하여 만들어진 인공신경망을 기반으로 더 복잡하고 심층적인 정보를 처리할 수 있습니다. 이렇게 인공지능의 성능은 지속적으로 향상되어 왔습니다.
2016년 3월(7년 전 이맘때), 전 세계가 주목한, 인공지능 분야의 혁신적인 사건이 있었습니다. Google DeepMind에서 개발한 인공지능 AlphaGo가 바둑 세계 챔피언 이세돌 선수를 이긴 사건은 인공지능 기술의 혁신과 발전을 대중들에게 크게 알린, 역사적인 순간이었습니다. 이 대국은, 제한된 범위 내에서 특정 작업을 수행하고 특화된 문제를 해결할 수 있도록 설계된 Narrow AI(좁은 인공지능; Weak AI, 약 인공지능)의 능력을 명확하게 보여 주는 예시입니다. 바둑을 학습한 Narrow AI는 특정 영역에서 매우 전문화되어 있기 때문에, AlphaGo와 같이 바둑 게임을 놀라운 수준으로 수행할 수 있지만, 이와 관련 없는 다른 작업, 즉, 언어 이해, 이미지 분류, 음성 인식, 자율 주행, 수요 예측 등은 수행할 수 없습니다. 이와 달리, General AI(일반 인공지능; Strong AI, 강 인공지능)는 다양한 영역에서 인간이 할 수 있는 모든 지적 작업에 대해 인지/학습/수행할 수 있도록 설계된 것을 가리키며, 아직은 이론적 개념에 머물러 있습니다.
딥 러닝의 발전과 맞물려 등장한 생성형 AI(Generative AI)는 기존 패턴을 기반으로 오디오, 비디오, 이미지, 텍스트, 코드, 시뮬레이션 등의 새로운 콘텐츠를 생성하는데 사용할 수 있는 알고리즘입니다. OpenAI에서 개발한 ChatGPT는 생성형 AI 분야에서 인공지능 기술이 오랜 시간 지속적으로 진화해 오면서 만들어 낸 걸작으로서, Narrow AI에서 General AI로 향해 가는 변곡점이 되고 있습니다. 궁극적으로 인공지능은 인간의 지능을 능가하는 Super AI를 달성하는 것이 목표입니다.
ChatGPT는 주로 자연어 처리 작업(Natural Language Processing, NLP)을 위해 설계되었지만, Narrow AI에 비해 다양한 작업에 적용될 수 있습니다. 그러나 여전히 진정한 의미의 General AI는 아닙니다. ChatGPT의 지식과 능력이 사전에 정의된 학습 데이터의 범위에 의해 제한되며 언어 영역 대비 그 외의 작업은 비교적 약한 수행 능력을 가지고 있기 때문입니다.
General AI를 향해 가는 여정에 있어서 ChatGPT 출시는 인공지능 기술의 발전으로 인해 인간의 작업을 지원할 수 있는 영역 확장이 가속화되고 있으며, 현재까지 출시된 타 AI 모델들보다 큰 잠재력을 보여 준다는 점에서 의미 있습니다.
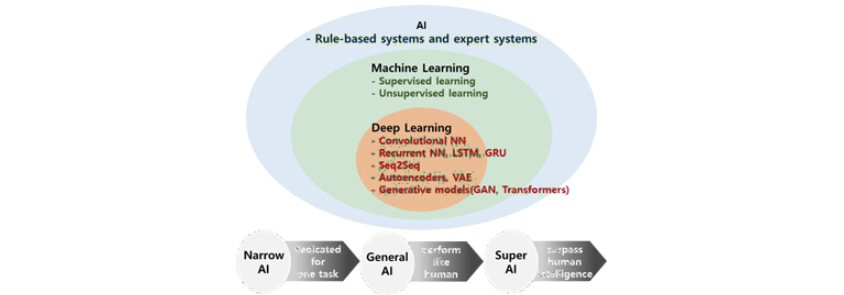 [그림 1] 인공지능이 포함하는 개념
[그림 1] 인공지능이 포함하는 개념
- rule-based system and expert systems
- supervised learning
- unsupervised learning
- rule-based system and expert systems
- convolutional NN
- recurrent NN, LSTM,GRU
- seq25eq
- autoencoders, VAE
- generative models(GAN, Transformers)
- Narrow AI -> General AI -> Super AI
인공지능(AI)는 지능형 시스템을 위한 방법론을 연구/개발하는 분야입니다. 초기 AI는 규칙 기반 또는 전문가 시스템으로서, 사전에 정의된 규칙 또는 인간의 전문 지식을 기반으로 작동했습니다. 머신러닝은 AI의 하위 분야로 등장하여 그간 발전해 왔으며, 딥러닝은 기계 학습의 하위 개념입니다. 딥러닝의 발전으로 인해 AI 성능이 크게 향상되었습니다. AI 발전 단계 중 현재는 Narrow AI와 General AI 사이에 위치하고 있습니다. AI 연구의 미래는 General AI 뿐만 아니라 Super AI를 달성하여, 인간-기계 상호 작용에서 전례 없는 가능성을 창출하는 것을 목표로 합니다.
OpenAI에서 ChatGPT를 출시(2022.11.30)한 데 이어 Google에서는 Bard 론칭 발표(2023.2.6)에서 데모를 시연하였습니다. 그리고 뒤이어 Google이 Workspace 제품군에 대한 AI 전면 적용 계획을 발표(2023.3.15)하였으며, 이틀 뒤 OpenAI와 파트너십을 맺고 있는 Microsoft에서 역시 자사 업무 생산성 도구 전반에 AI를 적용한 소프트웨어 Microsoft 365 Copilot 출시 계획을 발표(2023.3.16)하였습니다. 불과 4개월도 채 되지 않는 기간에 GPT 기술을 둘러싼 글로벌 빅테크 기업들의 경쟁이 격화되었고, 전 세계적으로 IT 업계에서는 GPT(Generative Pre-trained Transformer) 기술을 접목한 비즈니스 모델 개발에 열을 올리고 있습니다. ChatGPT 출시는 인공지능의 발전 단계에 큰 획을 긋는 역사적인 사건으로 기록될 것입니다.
| 일자 | 상세 내용 |
|---|---|
| ’22.11.30 | OpenAI, ChatGPT(GPT-3.5) 론칭 |
| ’22.12.05 | ChatGPT 일간 활성화 사용자 수(DAU) 100만 명 돌파 |
| ’22.12.15 | OpenAI, ChatGPT에 워터마크 도입 |
| ’22.12.25 | ChatGPT 일간 활성화 사용자 수(DAU) 1000만 명 돌파 |
| ’22.12.26 | Google, ChatGPT에 ‘코드 레드’ 발령 |
| ’22.12.27 | 베스핀글로벌, ‘헬프나우 AI’에 GPT 기술 도입 |
| ’22.12.31 | 12월 월간 활성화 사용자 수(MAU) 5,700만 명 돌파 |
| ’23.01.23 | Microsoft, OpenAI에 100억 달러 추가 투자 |
| ’23.01.31 | 12월 월간 활성화 사용자 수(MAU) 1억 명 돌파 |
| ’23.02.01 | 투블럭AI, 생성형 AI 활용 방법 관련 특허 등록 |
| ’23.02.03 | 네이버, 상반기 ‘서치GPT’ 출시 계획 발표 |
| ’23.02.06 | Google, Bard 론칭 발표 및 데모 시연 |
| ’23.02.07 | Microsoft, ChatGPT 탑재 검색 엔진 ‘빙(Bing)’ 발표 |
| ’23.03.09 | 업스테이지, OCR 기술에 ChatGPT를 결합한 ‘아숙업(AskUp)’ 론칭 |
| ’23.03.14 | OpenAI, ChatGPT(GPT-4) 론칭 |
| ’23.03.15 | Google, Workspace 제품군에 대한 AI 전면 적용 계획 발표 |
| ’23.03.16 | Microsoft, 업무 생산성 도구 전반에 AI를 적용한 Microsoft 365 Copilot 출시 계획 발표 |
| ’23.03.23 | OpenAI, ChatGPT plugin 지원 발표 |
ChatGPT란
ChatGPT는 OpenAI(Sam Altman이 2015년 12월 설립하였으며, 인공지능에 의한 전 인류적 이익을 추구하는 연구 개발 회사)가 개발한 대화형 AI(챗봇) 서비스로서, GPT 아키텍처를 기반으로 합니다. ChatGPT는 출시와 동시에 폭발적인 관심을 받으며 5일 만에 100만 명, 1개월 만에 약 1,000만 명의 사용자를 모은 데 이어 2개월 만에 월간 활성 사용자 수(Monthly Active Users, MAU) 1억 명을 돌파하였습니다. 타 IT 업체들의 경우, 100만 명 사용자 달성까지 걸린 시간이 Netflix(3.5년), Airbnb(2.5년), Facebook(10개월), Spotify(5개월), Instagram(2.5개월), iPhone(74일)인 것을 감안하면 엄청난 인기입니다.
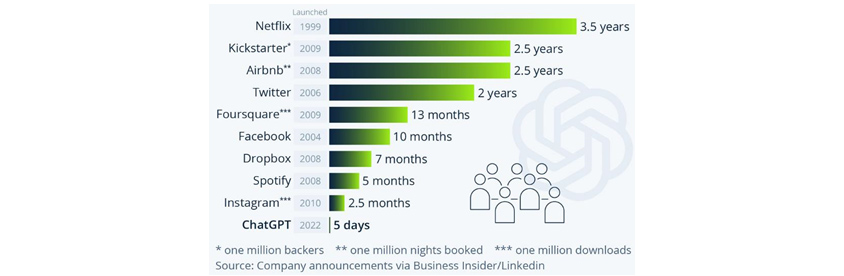 [그림 2] 플랫폼별 사용자 100만 명 도달에 걸린 시간, 출처: Katharina Buchholz, statista, 2023.1.24, 「ChatGPT Sprints to One Million Users」 (https://www.statista.com/chart/29174/time-to-one-million-users/)
[그림 2] 플랫폼별 사용자 100만 명 도달에 걸린 시간, 출처: Katharina Buchholz, statista, 2023.1.24, 「ChatGPT Sprints to One Million Users」 (https://www.statista.com/chart/29174/time-to-one-million-users/)
- Netflix - 1999 -3.5 years
- Kichstarter* - 2009 -2.5 years
- Airbnb** - 2008 -2.5 years
- twitter - 2006 -2 years
- Foursquare***- 2009 -13 months
- facebook - 2004 -10 months
- Dropbox - 2008 -7 months
- Spotify - 2008 -5 months
- Instagram*** - 2010 -2.5 months
- ChatGPT- 2022 -5 days
- *one million backers **one million nights booked ***one million downloads source company announcements via business insider/Linkedin
기존의 챗봇은 질문에서 추출한 키워드를 DB에 저장된 정보와 단순히 패턴 매칭을 하는 방식 등의 규칙 기반 시스템으로 작동하여, 한정된 범위 내에서만 대화가 가능합니다. 반면에, ChatGPT는 표면적인 정보 뒤에 숨어 있는 맥락을 이해하고, 과거 대화 기록을 기억함으로써, 직접 사람과 대화하는 것과 유사한 수준의 정보 전달이 가능합니다. 조금 더 구체적인 목적을 가진 예시들을 살펴본다면, 텍스트 생성(예: 가사, 소설, 이메일, 기획안), 감성 분석(예: 고객 후기 긍∙부정 구분), 문서 분류(예: 뉴스 기사 주제 분류, VoC 분류), 문서 요약, 키워드 추출, 번역, Q&A, 문법 교정, 프로그래밍 코드 작성, 표 작성 등의 기능을 수행할 수 있습니다. 출시 후 여러 성능 테스트를 거친 결과, 미국 와튼스쿨 MBA, 미국 의사면허 시험, 로스쿨 시험 등을 모두 무난하게 통과함으로써, 인간의 지적 능력과 관련된 업무 수행 역량을 입증하였습니다.
| 성능 | 상세 내용 |
|---|---|
| 미국 와튼스쿨 MBA 통과 | 필수 교과목인 ‘운영관리’ 기말시험에서 B-에서 B 사이 점수 획득 |
| 미국 미네소타 로스쿨 시험 통과 | 객관식 문항 95개, 에세이 문항 12개로 이루어진 시험에서 C+ 점수 획득 |
| 미국 의사면허시험(USMLE) 통과 | 모든 시험에서 50% 이상의 정확도 |
| 학술 논문의 공동 저자로 등재 | 영국 맨체스터 교수 Siobhan O'Connor, 논문에 ChatGPT를 공동 저자로 등재 |
| 광고 대본 작성 | 영화배우 Ryan Reynolds의 스타일로 휴대폰 통신사 Mint Mobile 광고 대본 작성 |
언어 모델의 발전
ChatGPT는 생성형 AI(Generative AI) 분야에서 인공 지능 및 기계 학습(Machine Learning) 기술이 오랜 시간 지속적으로 진화해 오면서 만들어 낸 걸작입니다. 생성형 AI는 기존 패턴을 기반으로 오디오, 비디오, 이미지, 텍스트, 코드, 시뮬레이션 등의 새로운 콘텐츠를 생성하는 데 사용할 수 있는 알고리즘으로서, 최근 언어 및 이미지 분석에서 크게 주목을 받고 있습니다. 생성형 AI 분야가 현재 수준으로 발전하기까지 크고 작은 공헌들이 있었지만, 언어 모델에 있어 큰 이정표 역할을 한 모델들 위주로 설명해 보겠습니다.
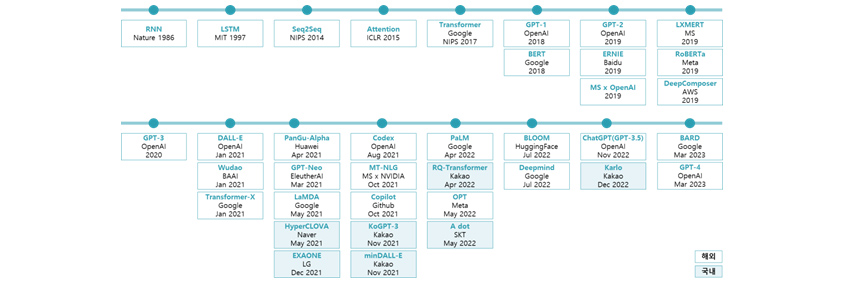 [그림 3] 언어 모델의 주요 발전 타임라인
[그림 3] 언어 모델의 주요 발전 타임라인
- RNN:Nabze,1986/LSTM:MIT,1997/SEQ@SEQ:NIPS,2014/Attention:ICLR,2015/Transformer:Google NIPS,2017/GPT-1:OpenAI,2018/GPT-2:OpenAI,2019/LXMERT:MS,2019//GPT-3:OpenAI,2020/DALL-E:OpenAI, Jan 2021/PanGu-Alpha:Hawai, Apr 2021/Codex:OpenAI,Aug 2021/PaLM:Google,Apr 2022/BLOOM:HuggingFace,Jul 2022/CHatGPT(GPT-3.5):OpenAI,Nov 2022/BARD:Google,Mar 2023
- BERT:Google,2018/ERNIE:Baidu,2019/RoBERTa:Meta,2019/Wudao:BAAI,Jan 2021/GPT-Neo:EleutheAI,Mar 2021/MT-NLG:MS x NVIDIA,Oct 2021/RQ-Transformer:kakao,Apr 2022s(국내)/Deepmind:Google,Jul 2022/Karlo:Kakao,Dec 2022(국내)
- MS x OpenAI,2019/DeepComposer:AWS,2019/Transformer-X:Google,Jan 2021/LaMDA:Google,May 2021/Copilot:Github,Oct 2021/OPT:Meta,May 2022/
- HyperCLOVA:Naver,May 2021(국내)/KoGPT-3:Kakao,Nov 2021(국내)/A dot:SKT,May 2022(국내)
- EXAONE:LG,Dec 2021(국내)/minDALL-e:Kakao,Nov 2021(국내)
인간의 두뇌로는 한눈에 쉽게 파악하기 어렵고 복잡한 규칙을 가진 현상을 기계에 학습시킴으로써, 현상 속에 내재된 패턴을 파악하고 미래를 예측하고자 합니다. 이를 위해서 현상에 대한 정보를 압축시킨 데이터를 인간의 신경계와 유사한 구조를 가지고 있는 인공 신경망에 넣어 줍니다. 데이터가 신경망 사이를 거쳐서 나아가는 동안 기계는 데이터의 대세적인 흐름, 유형화할 수 있는 요소들, 패턴 파악에 필수적인 정보들을 학습하고 노이즈는 제거해 가면서 데이터에 대해 이해하는 과정을 거칩니다. 그리고 데이터가 신경망의 최종 지점에 도달했을 때 기계가 학습한 정보를 바탕으로 예측값을 내어놓는데, 만약 정답과 다를 경우 데이터(오차)를 뒤로 돌려보내서 다시 학습하는 방식을 조정합니다. 정답을 제대로 맞히고 목표한 바를 이룰 때까지 이 과정을 반복합니다. 이렇게 기계가 데이터를 학습할 수 있도록 앞으로 흘려보내 주고 뒤로 돌려보내는 것을 순방향 신경망과 역전파(Feedforward Neural Networks and Backpropagation, FNNs, 1980s)라고 합니다.
음성이나 텍스트처럼 데이터가 앞뒤 순서를 가지고서 순차적으로 들어올 때, 순방향 신경망에서는 데이터가 계속 한 방향으로만 흘러가도록 넣어주며, 이 입력되는 데이터에 의존해서 기계도 예측값을 산출합니다. 하지만 이번에 새로 들어온 데이터에 대한 정보를 기반으로 예측값을 산출할 때 바로 직전에 이미 흘러가 버린 정보도 함께 참고하는 것이 더 정확할 수 있습니다. 이전에 들어와서 한 번 흘러가 버린 정보를 다시 망 내부로 유입시킬 수 있는 순환 구조를 가질 수 있도록 고안된 것이 순환 신경망(Recurrent Neural Networks, RNNs, 1980s- 1990s)입니다. 과거 정보에 대한 기억과 새로 들어온 정보를 함께 고려하여 앞뒤 맥락에 대한 이해를 바탕으로 신경망을 학습함으로써, 과거와 현재를 모두 아우른 예측이 가능합니다. 시계열 데이터, 음성 인식, 자연어 처리와 같이 시간이 흐름에 따라 변화하는 순차적 데이터 처리에 적합합니다.
이제 RNN 구조를 기반으로 과거에 들어온 정보도 같이 참고해서 현재값을 예측할 수 있습니다. 하지만 직전에 들어온 정보뿐만 아니라 한참 전에 들어온 정보도 함께 참고해야 하는데, 시간이 점점 흐르고 유입되는 데이터가 누적되는 상황에서는 기억이 소실되고 학습 능력이 떨어지게 됩니다. 이를 해결하기 위해서 장기적으로 기억해야 할 중요한 정보와 잊어버려도 되는 정보를 구분하여 제어함으로써, 길이가 긴 순차적 데이터도 효과적으로 학습할 수 있도록 고안된 것이 장단기 메모리(Long Short-Term Memory, LSTM, 1997)이며, RNN의 한 유형입니다.
두 개의 RNN 구조, 즉, (1) 입력 데이터를 학습하고 필요한 정보와 맥락만 응축해서 처리하는 RNN 구조 ‘인코더(encoder)’, 그리고 (2) 인코더로부터 과거 및 현재에 대한 응축된 정보를 전달받아 예측값을 산출하는 RNN 구조 ‘디코더(decoder)’를 결합하여 구성한 신경망 유형이 Seq2Seq(Sequence to Sequence, 2014)입니다. 이처럼 인코더와 디코더를 각각 구성하면 입력-출력 데이터 간 복잡한 관계를 더 효과적으로 파악할 수 있으므로 기계 번역과 같은 작업에 강점을 가집니다. 물론 이때 인코더 및 디코더를 구성하는 RNN을 LSTM 구조로 적용할 수 있으며, 여러 겹의 블록 형태로도 쌓을 수 있습니다.
Seq2Seq 모델에서 정보가 압축될 때 손실이 발생하기 때문에, 입력 정보가 길어지면 모델 성능이 떨어집니다. 이를 해결하기 위해서, 순차적으로 입력되는 정보 중 필요한 부분만 선택적으로 주의를 집중할 수 있도록 하여 Seq2Seq 모델의 성능을 높인 것이 Attention(주의) 메커니즘(2014) 입니다. 즉, 하나의 단어를 출력할 때마다 입력된 전체 문장을 참고하는데, 이때 입력 문장 내 모든 단어들을 동일한 비중으로 살피는 것이 아니라, 이번에 출력할 단어와 관련성이 높은 단어들에 조금 더 비중을 두는 것으로, 출력이 이루어질 때마다 입력 문장 내에서 큰 비중으로 다뤄지는 단어들의 집합은 계속 달라지게 됩니다.
Transformer 기반 언어 모델
2017년, Google에서 제목 ‘Attention is all you need’로 논문을 발표하면서 Attention 메커니즘을 적용한 Transformer 모델을 소개했습니다. Transformer는 이전 모델을 훨씬 능가하는 성능을 보여 주었으며, 이때부터 생성형 AI 분야에서 언어 모델이 빠른 속도로 발전하게 됩니다. 현재 활용되고 있는 언어 모델들의 대부분이 Transformer를 기반으로 확장해 가고 있는 것을 보면 더 혁신적인 방법론 제안이 있기까지는 계속해서 중심 역할을 할 것으로 보입니다.
Transformer(2017)도 Seq2Seq 모델처럼 입력 정보와 출력 정보 간 관계를 매핑하는 인코더-디코더 구조를 가지긴 하지만, 두 모델의 가장 큰 차이점은 정보를 받아들이는 방식입니다. RNN은 정보를 순차적으로 하나씩 입력받으면서 순환 구조를 통해 과거에 대한 기억을 되살려 활용하는 반면에, Transformer는 정보를 한꺼번에 입력받으며 Attention 메커니즘을 통해 집중이 필요한 정보들을 위주로 스캔하여 살펴봅니다. 먼저 인코더 Self-attention 메커니즘을 통해 입력된 전체 문장에서 단어마다 다른 단어들과의 관계 및 중요도를 파악하고 함축된 정보로 인코딩합니다. 이 정보를 받은 디코더는 인코더-디코더 Attention 메커니즘을 통해 현재 출력할 단어가 입력 문장 내 각 단어들과 얼마나 관련성이 있는지 측정할 뿐 아니라, 디코더 Self-attention 메커니즘을 통해 지금까지 출력된 단어들 간 관련성을 측정합니다. 즉, 입력 문장 내 단어들 간 관련성, 입력 문장과 출력 단어 간 관련성, 출력 문장 내 단어들 간 관련성을 두루 살피게 됩니다. 이 세 종류의 Attention 메커니즘으로 인해 입력 정보와 관련성이 높은 결과를 출력할 수 있으며, 이 Attention 메커니즘들은 병렬 처리되기 때문에 대량의 데이터를 효율적으로 다룰 수 있습니다. 참고로, RNN에서는 정보를 순차적으로 하나씩 입력 받기 때문에 문장 내 단어 순서 정보를 따로 처리하여 저장할 필요가 없으며 순환 구조를 통해 지나간 정보에 대한 기억을 되살리기만 하면 됩니다. 이와 달리, Transformer는 정보를 한꺼번에 입력 받으며, 문장 내 단어 위치 정보를 별도로 처리하여 결합시킴으로써 순서 정보를 보존(Positional Encoding)합니다.
BERT(Bidirectional Encoder Representations from Transformers, 2018)는 Google이 Transformer 모델을 기반으로 언어 표현을 사전 학습시키기 위해 고안한 방법론이자, 대량의 텍스트 데이터로 사전 학습된 모델입니다. 이름에서도 알 수 있듯이 양방향 문맥 파악이 가능하다는 점이 주요 특징이고, 이로부터 마스크 언어 모델링, 다음 문장 예측 등에 활용하기 용이하며, 특정 작업을 위한 Fine-tuning(미세조정)이 가능합니다.
1) 양방향 문맥(Bidirectional Context): 기존 언어 모델과 달리 앞뒤로 놓인 단어들을 모두 고려하여 문맥을 파악함으로써 언어 독해력을 높일 수 있습니다.
2) 마스크 언어 모델링(Masked Language Modeling, MLM): 입력된 문장 내에서 일정량의 단어들을 가린 뒤, 문맥을 고려하여 원래 단어가 무엇이었는지 예측하는 과정을 통해, 정확한 표현을 생성해 내는 방법을 학습합니다.
3) 다음 문장 예측(Next Sentence Prediction, NSP): 짝지어진 문장 입력을 통해 연달아 나타날 수 있는 문장들을 학습시킴으로써, 모델이 단어 수준을 넘어서 문장 수준에서 문맥을 이해할 수 있습니다.
4) 작업 특화 미세조정(Task-specific Fine-tuning): 사전 학습된 이후에는 특정 작업 관련 데이터로 미세조정해 줌으로써, 감성분석, Q&A, 개체명 인식(Named-Entity Recognition, NER) 등 다양한 자연어 처리를 수행할 수 있습니다.
BERT 방법론을 기반으로 학습 방식을 수정하여 모델 크기, 계산량, 성능 측면에서 개선된 BERT 계열의 모델에는 RoBERTa(Robustly Optimized BERT Pretraining Approach; Meta 개발), DistilBERT (Distilled version of BERT; HuggingFace 개발), ALBERT(A Lite BERT; Google 개발), ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately; Google 개발) 등이 있습니다.
GPT(Generative Pre-trained Transformer)
GPT(Generative Pre-trained Transformer) : OpenAI가 대량의 데이터로 다양한 작업을 수행할 수 있도록 사전 학습한 Transformer 모델입니다. BERT와 마찬가지로, 특정 작업을 잘 수행할 수 있도록 사전 학습된 모델을 Fine-tuning 할 수 있습니다. GPT는 일방향으로 나아 가면서 학습 및 예측을 하기 때문에 문장을 생성해 나가는 데 강점을 지닙니다. 이전까지의 단어들을 토대로 파악한 문맥에 맞게 단어를 생성하고 나면, 이 생성된 단어 역시 문맥 이해에 반영되고, 업데이트된 문맥 정보를 기반으로 또 다음 단어를 생성하는 과정이 반복적으로 일어납니다. 이 과정은 생성되는 문장이 일관된 문맥을 유지할 수 있도록 합니다.
| 구분 | BERT | GPT |
|---|---|---|
| 특징 | 전체 문장 내에서 단어의 좌우, 즉, 양방향으로 문맥을 고려하면서 학습하기 때문에, 문장의 의미를 포괄적으로 이해함. 맥락 상 단어의 의미를 파악하는 것이 중요한 자연어 처리 작업에 강점을 지님. | 일방향으로 나아가면서 다음 단어를 예측하는 방식으로 학습하기 때문에, 순차적으로 일관되게 문장을 생성함. 인간처럼 일관되고 연관성이 높은 언어를 구사하여 대화형 작업에 강점을 지님. |
| 주요 응용 | 문서 분류 감성 분석 개체명 인식 Q&A 기계 번역 |
문장 완성 요약 대화형 챗봇 창작 글쓰기(소설, 시 등) 프로그래밍 코드 작성 |
GPT 시리즈 : OpenAI에서 개발한 GPT는 현재 총 5개(GPT-1, GPT-2, GPT-3, GPT-3.5, GPT-4) 버전이 존재합니다. 모두 기본적으로 같은 구조를 가지나, 버전이 올라갈수록 파라미터(Parameter, 매개변수)의 개수가 증가합니다. 이때 파라미터란 Transformer를 구성하는 여러 겹의 신경망 구조를 거치며 입력된 정보에 대한 학습이 이루어지는 동안 입력값들에 주어지는 가중치(Weight) 및 편향(Bias)를 가리키며, 인간의 뇌로 따지면 신경망에서 뉴런 간 연결을 시켜주는 시냅스가 신경 물질 전달을 위해 가지고 있는 정보로 이해할 수 있습니다. 이 파라미터들은 학습이 진행될수록 정답에 가까운 문장을 생성해내는 방향으로 조정됩니다. 파라미터 개수가 증가할수록 더 정교한 학습이 이루어지며, 길이가 긴 문장을 이해하거나 복잡한 작업을 처리할 수 있는 능력이 올라 갑니다.
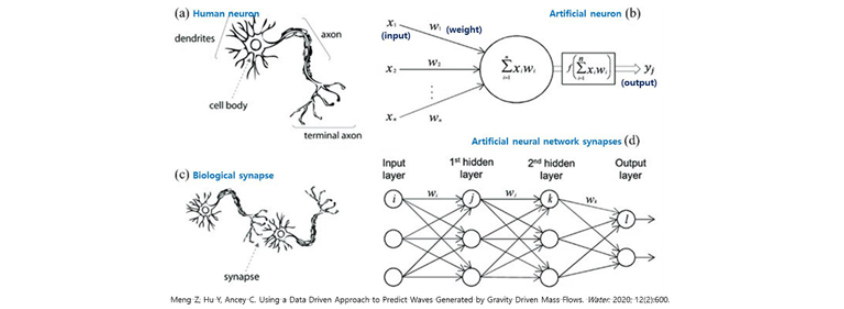 [그림 4] 인간-인공지능 뉴런
[그림 4] 인간-인공지능 뉴런
- dendrites/axon/cell body/terminal axon
- X1(input),X2,X3 -> W1,W2,W3(weight) -∑X1W1 - ∫(∑X1W1) ->Y∫(output)
- unsupervised learning
- synapse
- Input layer/1st hidde layer/2nd hidden layer/Output layer
- i ->(W1) - J ->(w2)- k -> i ->
GPT의 성능이 버전을 거듭할수록 향상되어 GPT-3부터는 인간에 가까운 언어 구사 능력을 보여준다는 평가를 받기 시작했습니다. GPT-3.5에서는 인간 피드백 기반 강화 학습(Reinforcement Learning with Human Feedback, 이하 RLHF)을 적용하였습니다. 이는, 인간이 작성한 질문과 답변으로 학습시킨 다음, 모델이 주어진 질문에 대해 답변을 여러 개 생성하면 인간이 순위를 매겨 추가 학습을 시킴으로써, 사용자의 의도와 니즈에 부합하는 답변을 생성할 수 있도록 유도한 것입니다. 즉, GPT를 학습시키는 도중에 인간이 개입하여 정답일 경우 보상을 주고 오답일 경우 벌을 주는 방식으로 가이드를 해줌으로써, 최종적으로 생성되는 답변의 성능을 높였습니다. 이 GPT-3.5를 기반으로 대화형으로 개발된 모델이 ChatGPT입니다.
| GPT 시리즈 | 출시 년월 | 파라미터 수(개) | 특징 |
|---|---|---|---|
| GPT-1 | ’18.6월 | 1억 1천 7백만 | - 주요 학습 데이터: BookCrawl - 학습 방식: Unsupervised pre-training with unlabeled data and Supervised fine-tuning with labeled data - 특정 task를 위해 매번 Fine-tuning 필요하며, 학습 데이터에 민감 |
| GPT-2 | ’19.2월 | 15억 4천 2백만 | - 주요 학습 데이터: WebText(800만개의 문서, 40GB 용량) - 학습 방식: Unsupervised Pre-training and Zero shot Learning - 메타 러닝(meta learning)의 일종인 in-context-learning(사전학습 모델에 task에 대한 텍스트 인풋을 삽입) |
| GPT-3 | ’20.6월 | 1,750억 | - 주요 학습 데이터: CommonCrawl(Web, e-book, wiki 등 753.4GB) - 학습 방식: Unsupervised Pre-training and Zero shot, One shot, Few shot Learning - 사람처럼 글 작성, 코딩, 번역, 요약 가능 - 예시를 통해 간접적으로 모델에 지시 |
| GPT-3.5 | ’22.11월 | 1,750억 | - 인간 피드백 기반 강화학습(Reinforcement Learning with Human Feedback, RLHF) 적용으로 답변 정확도와 안정성 급증 - GPT-3와 달리 직접적으로 대화 형태로 지시 |
| GPT-4 | ’23.3월 | 비공개 | - 모델 구조/크기, 하드웨어 정보, 데이터 및 모델 학습 방법 비공개 - 이미지 입력도 받을 수 있는 멀티모달(multimodal) 기능 |
이처럼 언어 모델은 결국 정보가 저장된 창고이고, 그 정보가 원하는 형태로 출력될 수 있도록 정보를 보관할 때부터 창고를 잘 설계하고 학습시킨 결과입니다. 최대한 다양하고 많은 데이터를 창고에 저장할수록 창고에서 출력되어 나오는 지식의 폭도 넓어집니다. 기존 AI 모델의 학습량과는 비교도 안 될 만큼 대규모의 데이터를 기반으로 학습된 모델을 거대 언어 모델(Large Language Model, LLM)이라고 하며, GPT-3 모델의 경우 학습에 소요된 비용이 $46M(약 500억 원)로 추정되고 있습니다. OpenAI 외에도 국내외 여러 기업들에서 수십, 수백억 단위를 투자하여 거대 언어 모델들을 개발 및 출시하고 있으며, 개인/기업 사용자는 이 모델을 기반으로 추가 데이터(업종 지식, 실무 정보 등)로 Fine-tuning하는 작업을 거쳐 원하는 용도에 맞게 서비스를 개발하거나 활용할 수 있습니다.
ChatGPT
ChatGPT(GPT-3.5) : GPT-3.5 모델을 기반으로 2022년 11월 대화형으로 첫 출시되었습니다. ChatGPT가 사람에 가까운 대화를 할 수 있는 핵심적 기술 원리로는, GPT 중 ‘T’에 해당하는 ‘Transformer’를 꼽을 수 있으며, 이는 문장 속의 단어 간 관계를 추적해 맥락과 의미를 학습하도록 합니다. 앞서 말했던 것을 기억하고 오류를 수정하는 능력의 우수함이 다른 AI와 가장 차별화되는 특징이며, 기존 AI 챗봇에 비해 사람에 가까운 대화가 가능합니다. 간단한 질문, 어려운 개념 요약, 코딩, 글쓰기 등 다양한 기능을 제공합니다.
ChatGPT(GPT-4) : ChatGPT는 2023.3월 GPT-4 모델을 기반으로 업그레이드되었습니다. GPT-4도 다른 언어 모델과 마찬가지로 문서에서 다음 토큰을 예측하도록 사전 훈련(Pre-trained)된 Transformer 기반 모델입니다. OpenAI에서 파라미터 개수를 공개하지 않았으나 GPT 3.5보다 더욱 많은 파라미터로 구성된 것으로 추정됩니다. 더 복잡하고 미묘한 시나리오에서 자연어 텍스트를 이해하고 창의적으로 생성하는 능력이 뛰어날 뿐만 아니라, 기존 GPT-3.5 대비 다양한 언어 데이터를 학습해 영어 이외의 언어 생성 능력도 향상됐습니다. 무엇보다도, 입력된 이미지를 인식하는 멀티 모달(인간이 사물을 받아들이는 방식처럼 시각/청각 등 여러 채널을 통해 정보를 동시에 받아들여 학습하고 사고하는 기능) 기능 탑재를 GPT-4의 강점으로 꼽을 수 있습니다. 예를 들어 냉장고 내부의 음식을 촬영한 사진으로 요리가 가능한 음식들을 추천받을 수 있습니다.
GPT-3.5 vs. GPT-4 : GPT-4는 LSAT, SAT 등의 성적뿐 아니라 UBE(Uniform Bar Exam, 미국변호사시험)에서 상위 10%의 성적을 거두면서 하위 10%를 기록한 GPT-3.5를 앞섰습니다. 이외에도 GPT-4는 MMLU(Measuring Massive Multitask Language Understanding, 대규모 멀티태스킹 언어 이해) 테스트 점수(57개의 객관식 문제로 언어 능력을 측정한 점수)에서 영어 이외의 언어(데이터 양이 적은 라틴어, 스와힐리어 등에 대해서도)로도 GPT-3.5의 영어 테스트보다 더 높은 점수를 획득했습니다.
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()
