

“내 이름은 노르베르 프티롤랭, 직업은 형사다. 어느 날 아침, 나의 왼손이 마치 다른 존재처럼 스스로 움직이기 시작했다. 처음에는 단순히 콧등을 긁는 것이나 숟가락 잡는 것을 거부했지만, 이제는 자동차 핸들을 잡는 것도 거부했다. 왼손은 나의 권총을 가지고 놀거나, 성냥불을 켜서 휴지통에 던지는 위험한 장난을 하며 나를 위협했다. 나는 왼손을 구슬리기 위해 손톱 화장을 시켜 주러 갔다.”
윗글은 베르나르 베르베르의 단편집 [나무] 중 "조종"이라는 단편에서 발췌한 내용입니다. 어느 날 갑자기 주인공은 자신의 의지에 따르지 않는 왼손의 반란에 직면하게 됩니다. 즉, 왼손이 주인공의 의지와는 별개로 움직이기 시작합니다. 이 왼손의 반란은 주인공 우뇌의 욕구불만 때문에 발생한 것으로, 이러한 이야기를 통해 베르나르 베르베르는 인간의 의지와 욕구, 그리고 그것들이 어떻게 충돌하고 조화를 이루는지에 대한 주제를 탐구하고 있습니다. 주인공의 왼손이 스스로 움직이기 시작하는 미스터리한 사건은 실제로 '분리된 뇌' 연구에서 관찰된 현상과 유사한 점이 있습니다.

인간의 좌뇌와 우뇌를 연결하는 뇌량(Corpus Callosum)은 신경섬유 다발로서 두 대뇌반구 사이의 정보 전달을 담당하며, 이를 통해 좌뇌와 우뇌가 서로 협력하여 다양한 기능을 수행할 수 있습니다. “Callosum”이란 교각, 즉 다리를 의미합니다. 뇌량이 끊어지면 두 뇌반구는 독립적으로 작동하게 됩니다. 이러한 상태의 환자들은 "분리된 뇌" 환자라고 불리며, 이들은 다음과 같은 특이한 행동을 보일 수 있습니다[1][2][3].
1) 독립적인 반응 : 뇌의 양쪽 반구는 독립적으로 정보를 처리하게 됩니다. 예를 들어, 환자에게 오른쪽 시야에 있는 물체를 보게 하면, 이것은 좌뇌에 의해 처리되며, 환자는 그 물체에 대해 언어로 설명할 수 있습니다. 반면, 왼쪽 시야에 있는 물체는 우뇌에 의해 처리되기 때문에 환자는 이 물체에 대해 말로는 설명하지 못하게 됩니다.
2) 모호한 정보 처리 : 한쪽 뇌 반구로만 정보가 전달되면, 그 정보의 전체적인 의미나 맥락을 파악하는 데 문제가 생길 수 있습니다.
3) 수동적인 손 : 우뇌는 오른쪽 손을, 좌뇌는 왼쪽 손을 제어합니다. 때문에 뇌량이 절단된 환자는 한 손이 다른 손의 행동을 방해하거나 둘 사이에 협동이 이루어지지 않는 상황을 경험할 수 있습니다.
뇌량이 끊어진(Split-brain) 환자에 대한 연구 중 많이 알려진 연구는 마이클 가자니가(Michael Gazzaniga)의 연구입니다. 그의 연구에서 split-brain 환자에게서 관찰된 현상 중 일부는 뇌의 “창작적 해석”과 관련이 있습니다. 예를 들어, 그는 실험에서 환자의 왼쪽 눈을 통해 우뇌에 "걷다"라는 명령을 전달했고, 환자는 일어나서 걸었습니다. 그다음 환자에게 그 행동의 이유를 물었을 때, "물을 마시러 가려고 했다"고 답했습니다. 언어 처리는 주로 좌뇌에서 이루어지므로, “걷다"라는 명령을 받은 사실을 모르는 환자의 좌뇌가 자신의 행동을 “창작적으로 해석”하여 말했다는 것을 의미합니다[4].
거대언어 모델의 할루시네이션(Hallucination)
거대언어 모델(Large Language Model), 특히 GPT-4, LLaMA, PaLM과 같은 모델들은 자연어 추론(Natural Language Inference)과 같은 다양한 작업에 뛰어난 성능을 보이며 많은 주목을 받고 있습니다. 그러나 이러한 모델들은 때때로 '할루시네이션'이라는 문제에 직면하게 됩니다. 할루시네이션은 모델이 훈련 데이터에 없는, 혹은 잘못된 정보를 생성하는 현상을 의미합니다[5]. 최근 Forbes에서 발표된 리포트에 따르면[6], 여러 기업의 데이터 과학자들과 엔지니어들은 LLM의 할루시네이션을 LLM의 도입을 주저하게 만드는 큰 장벽으로 지적하였습니다. 거대언어 모델은 대량의 데이터를 학습한 후 확률상 가장 높은 대답을 내놓는 것으로 그 진위는 확인할 수 없기에, 얼핏 그럴듯해 보이지만 말도 안 되는 답을 내는 오류를 범한다는 것입니다.
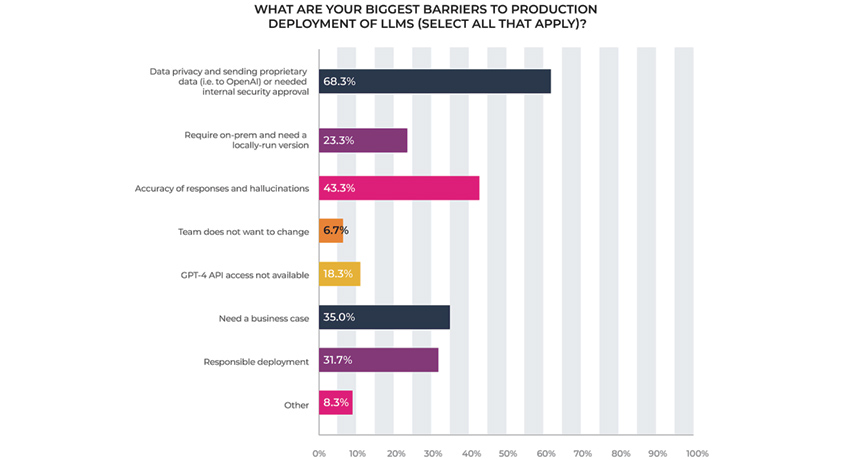 [그림 1] LLM의 도입을 막는 장벽, Data Privacy 1st, Hallucinations 2nd
[그림 1] LLM의 도입을 막는 장벽, Data Privacy 1st, Hallucinations 2nd
WHAT ARE YOUR BIGGEST BARRIERS TO PRODUCTION DEPLOYMENT OF LLMS (SELECT ALL THAT APPLY)?
- Data privacy and sending proprietary data (ie. to OpenAl) or needed internal security approval - 68.3%
- Require on-prem and need a locally-run version - 23.3%
- Accuracy of responses and hallucinations - 43.3%
- Team does not want to change - 6.7%
- GPT-4 API access not available - 18.3%
- Need a business case - 35.0%
- Responsible deployment - 31.7%
- Other - 8.3%
그런데 최근 OpenAI 개발자 커뮤니티에서 할루시네이션(Hallucination, 환각) 이 아닌 컨패뷸레이션(confabulation)이라고 해야 한다는 주장이 제기되었습니다[7]. 컨패뷸레이션(confabulation)은 의학 용어로 작화증인데, 사람이 허구의 사건이나 기억을 만들어 내는 것을 의미합니다. 영어사전을 찾아보면 Confabulation이 “허물없는 잡담”으로 번역되어 있기도 합니다.
2000년대 초반 죽어가던 인공지능 연구를 살리고, 지금의 딥러닝을 탄생시킨 제프리 힌튼 교수도 할루시네이션이 아닌 컨패뷸레이션이라는 주장에 힘을 실어주고 있습니다. 힌튼 교수는 최근 한 인터뷰에서, Confabulation 이 맞는 용어이고, 그것은 버그가 아닌 기능(Feature)이라고 말하며 다음과 같이 덧붙였습니다[8].
“사람들은 항상 이야기를 합니다. 절반의 진실과 잘못 기억된 세부사항은 인간 대화의 특징입니다. 언어 모델들은 마치 사람처럼 뭔가를 하고 있어요.”
LLM이 알지 못하는 사실에 대해 답변을 해야 할 때, 그들은 타당한 것처럼 보이는 것을 만들어 냅니다. 즉, 그것들은 사람처럼 confabulate(작화)합니다. LLM이 실제로 하는 것이 confabulating이라는 것을 인식하면, 우리는 그들의 응답을 인간의 행동과 비교하고 대조할 수도 있고, 인간의 인지적 체계를 모방해서 LLM을 더욱 발전시킬 수도 있을 것입니다.
롱텀 메모리와 숏텀 메모리
인간의 인지 체계는 크게 롱텀 메모리(Long-Term Memory)와 숏텀 메모리(Short-Term Memory)로 나뉩니다. 이 두 메모리 체계는 우리의 일상에서 수많은 정보를 처리하고 저장하는 데 중요한 역할을 합니다[9].
롱텀 메모리(Long-Term Memory)
롱텀 메모리는 우리의 지식과 경험을 장기간 동안 저장하는 메모리입니다.
이 메모리는 우리의 생애 동안 쌓인 수많은 정보와 경험을 포함하며 장기간 동안 잊혀지지 않습니다. 사람은 장기 기억이 필요할 때 회상하는 과정을 통해 사용할 수 있습니다.
숏텀 메모리(Short-Term Memory)
숏텀 메모리는 일시적으로 정보를 저장하고 처리하는 메모리입니다. 이 메모리는 제한된 용량을 가지며, 일정 시간이 지나면 정보가 사라집니다. 숏텀 메모리는 일상의 다양한 작업, 예를 들어 전화번호를 일시적으로 기억하거나, 쇼핑 목록을 머릿속에 떠올리는 등의 작업에 사용됩니다.
이제, 이 두 메모리 체계를 거대언어 모델(LLM)과 연관 지어 생각해 보겠습니다. LLM은 수많은 정보를 처리하고 저장할 수 있지만, 그 자체로는 모든 정보를 효과적으로 관리하고 검색하는 데 한계가 있습니다. 이때 벡터 데이터베이스를 도입하면, 롱텀 메모리와 같은 역할을 할 수 있습니다.
벡터 데이터베이스는 LLM이 사용하는 대량의 정보를 효과적으로 저장하고 검색할 수 있는 시스템입니다. LLM에 질문과 함께 일시적인 정보를 제공하여 원하는 결과를 얻게 하는 Prompt Engineering이 숏텀 메모리와 같은 역할을 하는 것이라면, 벡터 데이터베이스는 LLM의 롱텀 메모리와 같은 역할을 하며, 대량의 정보를 검색하고 사용할 수 있게 해줍니다. LLM에 벡터 데이터베이스를 활용하는 이 기법은 RAG(Retrieval Augmented Generation)로 알려져 있고, 특히 여러 기업에서 요구하는 산업 특화형(Domain-specific) LLM의 활용을 위해서 더욱 부각되고 있습니다.
Retrieve, Reflect, Plan(검색, 반추, 계획)
최근 미국의 스탠포드 대학과 구글 딥마인드 연구자들이 발표한 Generative Agents(생성적 에이전트) 논문[10]이 큰 주목을 받았습니다. 연구자들은 시뮬레이션 게임 환경에서 25명의 NPC(Non Player Character, 컴퓨터에 의해 조종되는 캐릭터)를 만들었고 ChatGPT가 그들의 행동을 결정하도록 설정했습니다.
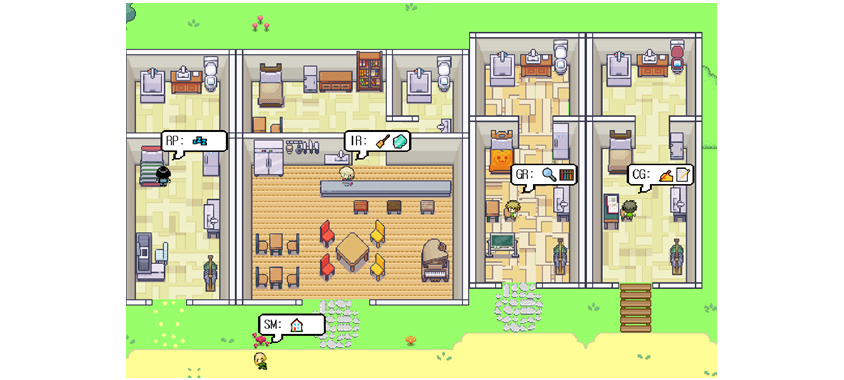 [그림 2] Generative Agents Game
[그림 2] Generative Agents Game
각 NPC들은 “메모리 스트림”이라는 롱텀 메모리를 받아 거기에 자신의 페르소나(Persona, 사회적 특성)와 함께 모든 행동을 매 분마다 기록했습니다. 그렇게 기록된 롱텀 메모리에서 Retrieve(검색) 과정을 통해 중요한 기억을 선별하였습니다. 선별된 기억과 함께 다음에 무슨 행동을 할지를 Prompt 형태로 ChatGPT에게 물어봤고, NPC들은 그 대답을 받아 다음 행동을 실행하도록 했습니다. 또한 ChatGPT가 롱텀 메모리로부터 Reflect, Plan(반추, 계획)을 일정한 주기로 생성한 뒤, 이를 다시 롱텀 메모리에 넣는 일종의 피드백 루프를 만들었고, 이를 통해 NPC의 행동이 계획성 있게 결정되도록 조정하였습니다.
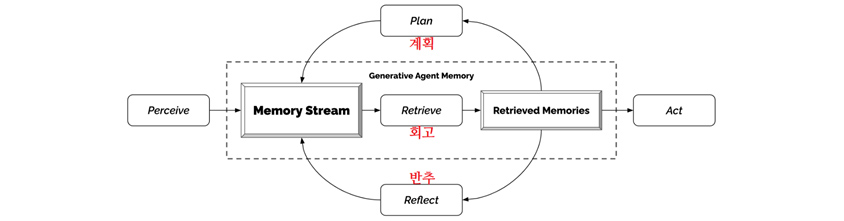 [그림 3] Generative Agents의 기억 아키텍처
[그림 3] Generative Agents의 기억 아키텍처
Generative Agents의 기억 아키텍처를 시각화 한 이미지로 Perceive → [Memory Stream → Retrieve(회고) → Retrieved Memories] → Act 순으로 흐르며 Memory Stream → Reflect(반추) → Retrieved Memories → Plan(계획) → Memory Stream... 으로 순환하는 고리가 있다. 대괄호로 감사진 [Memory Stream → Retrieve(회고) → Retrieved Memories] 은 Generative Agent Memory다.
이 가상의 세계에서 실험은 이틀 동안 진행되었습니다. 연구자들은 NPC들의 롱텀 메모리를 관찰해 가며 놀라운 사실을 발견할 수 있었습니다. NPC들은 부여된 페르소나에 따라, 예술가는 그림을 그렸고, 작가는 글을 썼습니다. 일상생활에서 아침 식사를 준비하고 일하러 가는 등의 행동을 하며, 그들은 의견을 형성하고, 서로를 인식하며 대화를 시작하는 등 마치 사람처럼 행동했습니다. 연구자는 한 NPC의 롱텀 메모리에 개입해 ‘파티를 열고 싶다’는 생각을 주입했습니다. 그러자 그 NPC는 파티를 계획했고 다른 NPC들을 초대했습니다. 초대받은 NPC들 중 몇몇은 파티가 열린다는 사실을 다른 NPC들에 알려주기도 했고, 파티가 열린 시간에 실제로 몇몇 NPC들은 파티 장소에 나타났습니다.
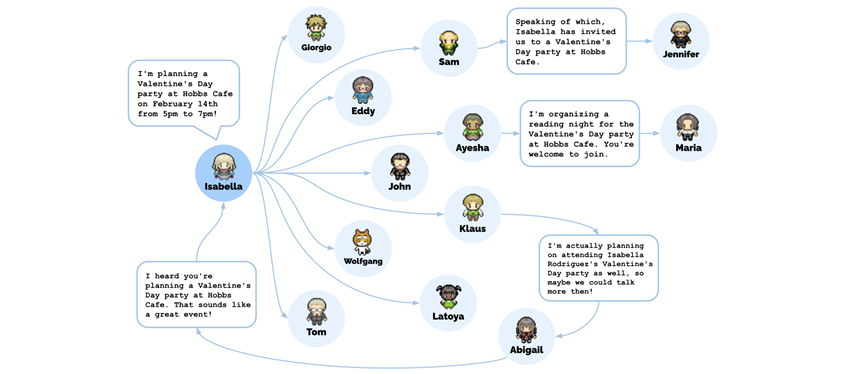 [그림 4] NPC들의 파티 초대
[그림 4] NPC들의 파티 초대
연구자들은 위 실험이 모두 완벽하게 돌아갔다고 주장하지는 않았습니다. 예를 들어 화장실에 여러 NPC가 동시에 들어가려고 한다거나, 저녁 늦게 이미 문을 닫은 상점에 들어가려 하는 행동을 관찰할 수 있었습니다. 그러한 행동들은 자연어로 전달하기 힘든 물리적 제한 또는 상황적 규범들을 설정해 놓지 않았기에 생기는 문제들로, 수없이 많은 제한 또는 규범을 미리 설정하기에는 그 작은 가상의 세계조차 충분히 복잡합니다. 물론 현실 세계는 이 작은 가상의 세계보다 훨씬 더 복잡합니다.
좌뇌는 논리적 사고, 계획, 언어 처리 등의 기능을 담당하며, 이는 Generative Agents의 'Plan' 메커니즘과 유사합니다. 'Plan' 메커니즘에서는 NPC의 행동이 일관적일 수 있도록 미래의 행동 순서를 ChatGPT를 통해 계획합니다. 이 계획과 함께 롱텀 메모리에서 중요한 기억의 Retrieve(검색)이 일어나고, Reflect(반추)도 고려하여 Prompting으로 ChatGPT에게 NPC의 다음 행동을 물어봅니다. 이는 인간의 좌뇌가 논리적으로 정보를 처리하고, 미래의 행동을 계획하는 것과 유사합니다.
반면, 우뇌는 감정, 창의성, 공감 능력 등을 담당합니다. 이는 Generative Agents의 'Reflect' 메커니즘과 연결될 수 있습니다. Reflect(반추)라는 과정을 통해 에이전트는, 롱텀 메모리에 저장된 일련의 경험을 기반으로 ChatGPT에 일상적 경험의 추상화를 요청합니다. 이 과정에서 에이전트는, 롱텀 메모리에 자연어 형태로 저장된 자신의 경험과 ChatGPT에 의해 자연어로 응답받은 감정을 반영하게 됩니다. 이는 인간의 우뇌가 감정과 창의성을 통해 새로운 아이디어나 감정을 형성하는 것과 유사합니다.
이러한 비유를 통해 우리는 Generative Agents의 작동 원리를 더 깊게 이해할 수 있습니다. 이러한 원리는 LLM을 사용하는 더 발전적인 게임 NPC뿐만 아니라, 수많은 기업에서 Autonomous AI Worker를 만드는 데 사용될 수 있습니다. 특히 장기 경험을 기반으로 한 인간 행동 모델이 필요한 분야에서 그 잠재력이 큽니다.
Generative Agent 기억 아키텍처의 활용
최근 중국의 칭화대에서는 Generative Agent의 기억 아키텍처를 사용하여, LLM을 통해 만든 Agent 들이 협업하면서 소프트웨어를 개발하는 시스템을 연구하였습니다[11]. 이 시스템 안에서 CEO, CPO, CTO, 개발자, 리뷰어, 테스터, 디자이너라는 7명의 에이전트가 있는 ChatDev라는 가상의 소프트웨어 개발 회사를 만들어 게임을 개발하도록 했습니다. 설계, 코딩, 테스팅, 문서화라는 네 가지 단계로 개발 과정을 나누고 개발의 주요 과정을 작은 서브태스크로 분해한 뒤, "Chat Chain”이라는 메커니즘을 도입하여 Waterfall 방식의 소프트웨어 개발이 순차적으로 진행될 수 있도록 설정했습니다. Chat Chain을 통해 CTO는 프로그래머에게 markdown 형식을 사용하여 소프트웨어 시스템을 구현하도록 지시합니다. 프로그래머는 응답으로 코드를 생성하고 markdown 형식을 기반으로 해당 코드를 추출합니다.
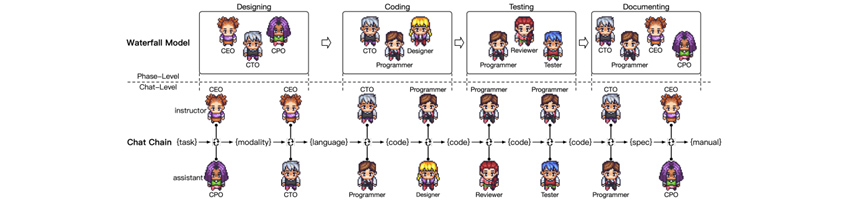 [그림 5] ChatDev의 Chat Chain
[그림 5] ChatDev의 Chat Chain
ChatDev의 소스코드[12]가 최근 깃헙에 공개되었습니다. Generative Agent에 관심이 있는 사람이라면 누구나 소스코드를 다운받아 설치하고 ChatGPT API를 설정한 후, “핑퐁 게임을 만들어 주세요” 같은 간단한 자연어 명령을 통해 게임을 만들 수 있습니다. Chat Chain 시각화 툴을 통해, agent들 사이에 어떤 대화가 오가는지 모니터링하며 개발 과정을 관찰할 수도 있습니다.
이렇게 훌륭한 결과에도 불구하고 Generative Agent 혹은 Autonomous AI Worker에 대한 장밋빛 미래만 보이는 것은 아닙니다. 위 칭화대의 연구에서, ChatDev는 오목 게임 외에 총 70개의 개발 태스크를 수행했고, 이 중 13.3%는 오류로 인해 실행에 실패했습니다. 실패의 원인은 ChatGPT의 토큰 제한으로 인해 긴 코드를 생성하지 못했거나, 소스코드의 외부 종속성 문제 때문이었습니다. 따라서, 아직은 숙련된 프로그래머의 개입 없이 복잡한 애플리케이션을 만드는 것은 어려워 보입니다.
글을 마치며…
Generative Agent와 Autonomous AI Worker는 최근 인공 지능 분야에서 빠르게 주목받는 기술로 부상하고 있습니다. 이러한 기술의 부상은 거대언어 모델(LLM)의 급속한 발전과 밀접하게 연관되어 있습니다. LLM은 텍스트 기반의 질의응답, 문장 생성, 문서 요약 등 다양한 언어 작업에서 뛰어난 성능을 보여주며, 그 가능성을 널리 인정받고 있습니다. 그러나 LLM의 한계도 명확합니다. 복잡하고 다양한 작업을 처리하기 위해서는 사용자의 지속적인 입력과 가이드가 필요하며, 이는 작업의 효율성을 저하시키는 주요 요인 중 하나입니다.
Generative Agent의 등장은 이러한 문제를 해결하는 데 큰 도움이 될 것으로 보입니다. Generative Agent는 다른 에이전트와의 협력을 통해 더욱 복잡한 작업을 해결할 수 있으며, 이러한 에이전트 간의 협력은 인간의 지속적인 개입 없이도 작업을 완료할 수 있는 가능성을 보여주었습니다. 이러한 기술의 발전은 단순한 작업 자동화를 넘어서, 인간과 기계의 협력을 통한 창의적인 문제 해결의 새로운 패러다임을 제시할 것입니다. 이는 기존의 작업 방식을 혁신하며, 새로운 가치를 창출하는 데 큰 도움이 될 것으로 기대됩니다.
References
[1] Gazzaniga, M. S. (1967). The split brain in man. Scientific American, 217(2), 24-29.
[2] Gazzaniga, M. S., Bogen, J. E., & Sperry, R. W. (1962). Some functional effects of sectioning the cerebral commissures in man. Proceedings of the National Academy of Sciences, 48(10), 1765-1769.
[3] Sperry, R. W. (1984). Consciousness, personal identity and the divided brain. Neuropsychologia, 22(6), 661-673.
[4] Gazzaniga, M. S., & LeDoux, J. E. (1978). The integrated mind. Plenum Press.
[5] McKenna, N., Li, T., Cheng, L., Hosseini, M. J., Johnson, M., & Steedman, M. (2023). Sources of Hallucination by Large Language Models on Inference Tasks. arXiv preprint arXiv:2305.14552.
[6] https://www.forbes.com/sites/aparnadhinakaran/2023/04/26/survey-massive-retooling-around-large-language-models-underway
[7] https://community.openai.com/t/hallucination-vs-confabulation/172639
[8] https://www.technologyreview.com/2023/05/02/1072528/geoffrey-hinton-google-why-scared-ai/
[9] Cowan, N. (2008). What are the differences between long-term, short-term, and working memory?. Progress in brain research, 169, 323-338.
[10] Park, J. S., O'Brien, J. C., Cai, C. J., Morris, M. R., Liang, P., & Bernstein, M. S. (2023). Generative agents: Interactive simulacra of human behavior. arXiv preprint arXiv:2304.03442.
[11] Qian, C., Cong, X., Yang, C., Chen, W., Su, Y., Xu, J., ... & Sun, M. (2023). Communicative agents for software development. arXiv preprint arXiv:2307.07924.
[12] https://github.com/OpenBMB/ChatDev
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

삼성SDS 컨설팅팀
생성형 AI가 촉발시킨 초거대 AI 비즈니스 열풍은 이 세상을 더 나은 방향으로 변화시킬 것이라 믿습니다. 다양한 잠재력을 보여주고 있는 AI 기술을 활용하는 동시에 법적, 윤리적 쟁점을 완화시킬 신뢰 가능한 AI에 관심을 두며, 많은 기업들과 협업하고 소통하기를 기대하고 있습니다.