

서비스 메시 개요
지금 서비스 메시가 의미 있는 이유
컨테이너 및 오케스트레이터 도입은 서비스 운영 비용의 극적인 감소라는 결과를 가져왔습니다. 이는 서비스 메시를 운영 가능하게 만들었고, 마이크로서비스를 운영 가능하게 만들었다고도 볼 수 있습니다. 특히, 도커와 쿠버네티스가 사실상의 표준으로 활약하면서 이러한 생태계 구축에 일조했습니다.
 이미지 출처: https://nordicapis.com/how-service-mesh-prevents-a-microservices-mess
이미지 출처: https://nordicapis.com/how-service-mesh-prevents-a-microservices-mess
먼저, 도커는 패키징이라는 문제를 해결합니다. 애플리케이션과 런타임 종속성을 컨테이너로 패키징함으로써 어디에서나 실행될 수 있는 대체 가능한 단위로 만들었습니다. 쿠버네티스는 그다음 단계를 해결합니다. 많은 실행가능한 도커 이미지를 컨테이너 서비스로 올렸을 때, 이들을 매핑하고 오케스트레이션하는 도구가 필요합니다. 쿠버네티스를 통해 하나의 서비스를 배포하는 시간은 10개의 서비스를 배포하는 것과 크게 다르지 않습니다. 또한, 폴리글랏 런타임 기반의 컨테이너와 결합하면 다양한 언어로 작성된 마이크로서비스로 구현되는 수많은 새로운 애플리케이션이 탄생합니다. 이러한 환경은 서비스 메시를 필요로 하게 되었습니다. 바꾸어 말하면, 서비스 메시가 실현 가능한 이유이기도 한데, 쿠버네티스가 서비스에 제공하는 것과 동일한 방식을 서비스 메시의 운영에 직접 적용할 수 있습니다. 프록시를 컨테이너에 패키징하고 쿠버네티스에 프록시를 어디에나 붙이도록 배포하면 서비스 메시 환경이 구성되는 것입니다.
서비스 메시 구조
서비스 메시는 애플리케이션 트래픽을 관리, 추적 및 보안성을 강화하기 위해 플랫폼 레이어에 구성되는 네트워크 제어 방법입니다. 서비스 메시의 대표 기능은 크게 세 가지로 애플리케이션 트래픽 관리, 관찰 가능성(observability), 보안입니다. 애플리케이션 레이어가 아닌 플랫폼 레이어에 이러한 기능이 추가됩니다. 서비스 메시는 데이터 플레인, 컨트롤 플레인 두 개 컴포넌트로 구성되는데, 데이터 플레인은 애플리케이션 사이에 있는 프록시 네트워크로 구성되고, 컨트롤 플레인은 프록시에게 수행할 작업을 알려주고 메시를 작동하는 사람을 위한 인터페이스를 제공합니다.
아래 그림에서 데이터 플레인 위치한 프록시는 haproxy 및 NGINX와 마찬가지로 L7 TCP 프록시입니다. 보통 엔보이(Envoy) 서비스를 이용하여 프록시를 구성하나, 자체 개발한 프록시 또는 노드 에이전트 방식을 사용하기도 합니다. 이 프록시는 서비스와의 프록시 호출을 담당합니다. (엄밀히 말하면 "포워드 프록시" 및 "리버스 프록시" 역할을 모두 수행하여 인바운드, 아웃바운드 호출을 모두 처리합니다) 컨트롤 플레인은 서비스 검색(Discovery), TLS 인증서 발급, 메트릭 집계 등을 포함하여 데이터 플레인이 작동하는데 필요한 컴포넌트들을 제공합니다. 또한, 컨트롤 플레인은 사용자가 전체적으로 데이터 플레인의 동작을 수정하고 검사할 수 있도록 API를 제공합니다.
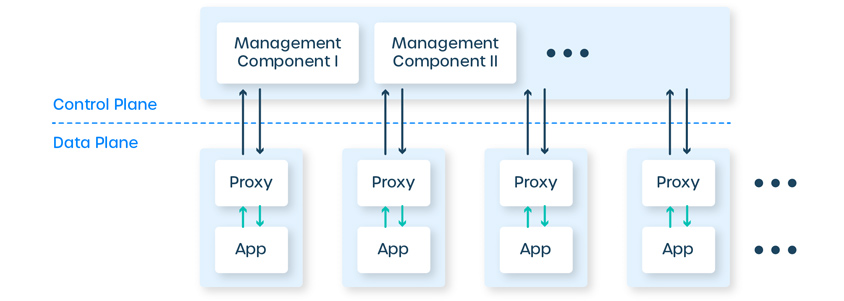
- management component 1 / management component 2
- control plane
- data plane
- proxy -> / proxy -> / proxy -> / proxy ->
- app - / app - / app - / app -
다음 그림은 서비스 메시 도구로 많이 알려진 이스티오 아키텍처입니다. 대부분의 서비스 메시 솔루션이 앞서 보여드린 아키텍처와 유사한 구성입니다.
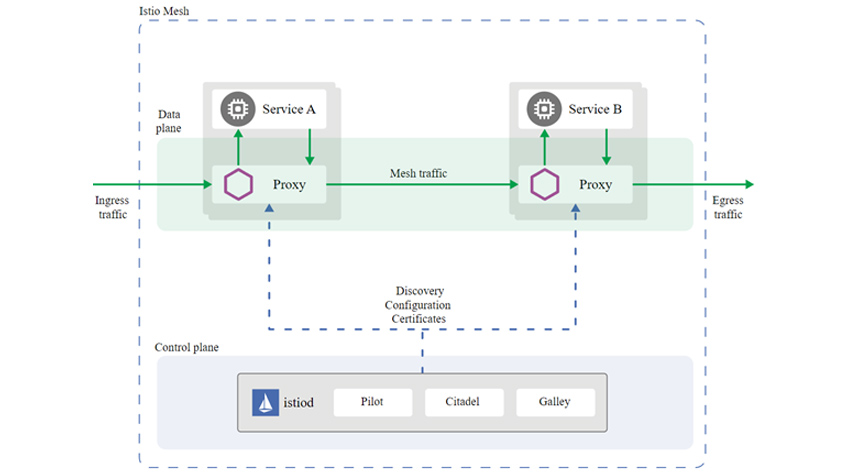
- data plane: service A -> / service B ->
- (Ingress traffic ->) /proxy - / (Mesh traffic ->) / proxy - / (Egress traffic ->)
- - Discovery Configuration Certificates -
- Control plane : istiod - Pilot / Citadel / Galley
데이터 플레인의 프록시는 Envoy를 사용하고, 서비스 메시의 모든 서비스에 대한 모든 인바운드 및 아웃바운드 트래픽을 관장합니다.
컨트롤 플레인의 istiod는 트래픽 라우팅 규칙을 Envoy 구성으로 변환하고, 사이드카에 전파합니다. 그 외 서비스 디스커버리, 서비스 간 mTLS 통신을 위한 인증기관(CA) 역할을 합니다.
쿠버네티스의 샘플 애플리케이션을 살펴보겠습니다.
다음은 쿠버네티스에서 실행되는 일반적인 애플리케이션의 다이어그램입니다. 애플리케이션 A, B, C는 세 가지 마이크로서비스로 구성되고, A는 B, C와 http 프로토콜로 통신하고, B와 C는 gRPC를 통해 서로 통신합니다.
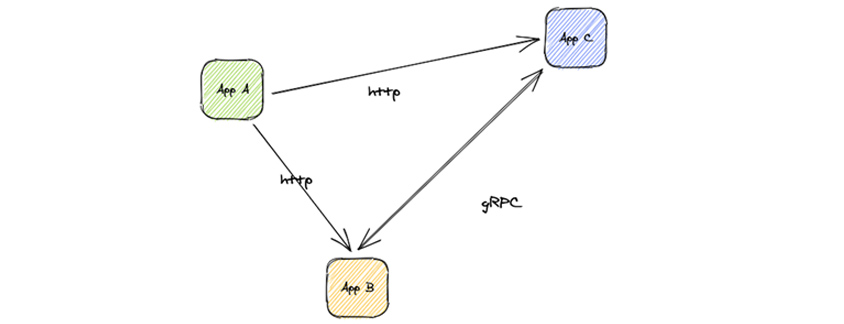
- App A ->(http) App C
- App A ->(http) App B
- App B ->(gRPC) App C
서비스 메시를 추가하면, 애플리케이션은 직접 통신에서 프록시를 통한 통신으로 변경됩니다. 이제 프록시가 모든 앱 간 통신을 가로채고 관리합니다. 왼쪽 이미지에서 볼 수 있듯이 프록시는 이제 각 구성 요소 사이에 위치하여 연결의 양쪽 끝에서 트래픽을 가로채고 있습니다. 프록시는 서비스 메시의 데이터 플레인을 구성하고 서비스 메시가 수행하는 모든 작업을 직접 수행합니다. 재시도를 구현하거나 mTLS를 추가하거나 요청 레벨의 부하 분산을 수행합니다.
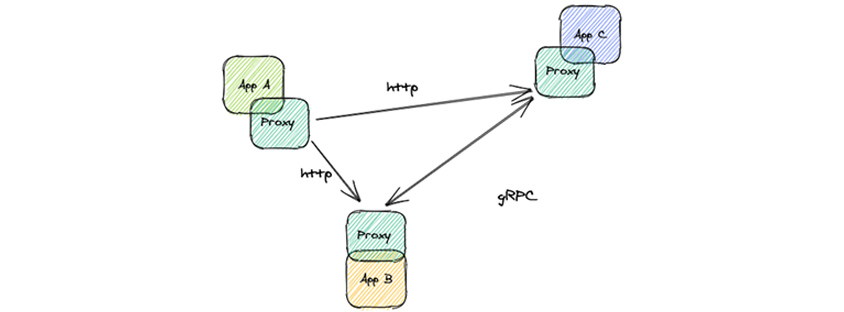
- App A /Proxy ->(http) Proxy / App C
- App A /Proxy ->(http) Proxy / App B
- Proxy / App B ->(gRPC) Proxy / App C
서비스 메시의 대표 기능
트래픽 관리 (Traffic Management)
단일 클러스터 내 및 클러스터 간 트래픽 라우팅은 더 나은 배포 전략을 가능하게 합니다. 트래픽 라우팅 규칙을 사용하면 서비스 간의 트래픽 흐름 및 API 호출을 쉽게 제어할 수 있습니다. 서킷 브레이커, 타임아웃 및 재시도와 같은 서비스 수준 속성의 구성을 단순화하고 A/B 테스트, 카나리 배포 및 퍼센트 기반 트래픽 분할을 통한 단계적 롤아웃과 같은 중요한 작업을 쉽게 설정할 수 있도록 합니다.
그런데, 이러한 트래픽 관리 기능들 중 쿠버네티스 자체에서도 트래픽 라우팅 기능을 일부 수행 가능하기 때문에, 서비스 메시에서는 어떻게 더 특별하게 제공하는지를 살펴보겠습니다.
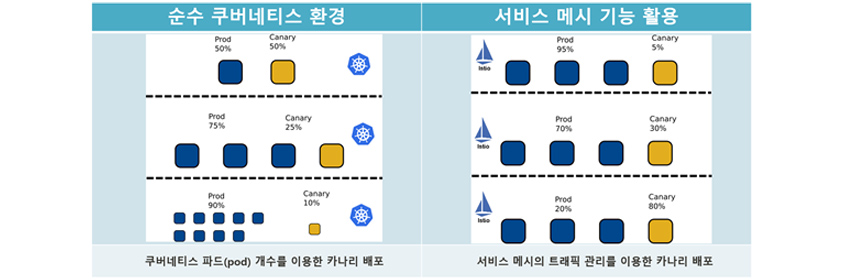
- Proxy :50% / canary : 50%
- Proxy :75% / canary : 25%
- Proxy :90% / canary : 10%
- 쿠버네티스 파트(pod) 개수를 이용한 카나리 배포
- Proxy :95% / canary : 5%
- Proxy :70% / canary : 30%
- Proxy :20% / canary : 80%
- 서비스 메시의 트래픽 관리를 이용한 카나리 배포
쿠버네티스 파드 개수를 이용해 카나리 테스트(왼쪽 이미지)를 하기 위해서는, 10%의 트래픽을 얻기 위해 최소 9개의 프로덕션 파드가 필요합니다. 파드 개수를 조정하여 50%, 25%, 10% 등 카나리 배포 비율을 조정합니다.
서비스 메시의 트래픽 관리 기능을 이용하면(오른쪽 이미지), 제공하는 파드 수에 관계없이 트래픽의 비율을 카나리 버전으로 지정할 수 있습니다. 카나리 버전을 제공하는 파드의 개수와 가져오는 트래픽은 관련이 없습니다. 왼쪽은 서비스 메시로 카나리 테스트를 달성할 수 있는 예입니다. 카나리 서비스용 파드 수는 1개로 운영 서비스 3개 보다는 적은 개수이지만, 트래픽 비율은 카나리로 5% → 30% → 80% 늘려나갈 수 있습니다.
보안 (Security)
마이크로서비스에는 메시지 가로채기(man-in-the-middle) 공격에 대한 보호, 인증 및 권한 부여 등 특정 보안 요구 사항이 있습니다. 서비스 메시 보안 기능에는 운영자가 이러한 문제를 해결할 수 있는 다양한 보안 솔루션이 포함되어 있습니다. TLS 암호화, 인증, 인가 및 감사(audit) 도구를 제공하여 서비스와 데이터를 보호합니다.
실제 유스케이스 확인해보기 위해, 전통적인 방식의 보안 아키텍처와 마이스로서비스 세상에서의 보안 아키텍처는 어떻게 다른지를 한번 살펴보겠습니다.
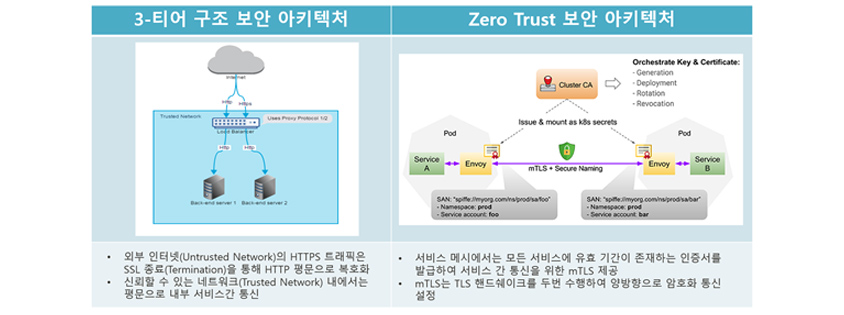
- 외부 인터넷(Untrusted Network)의 HTTPS 트래픽은 SSL 종료(termination)을 통해 HTTP 평문으로 복호화/ 신뢰할 수 있는 네트워크(Trusted Network) 내에서는 평문으로 내부 서비스간 통신
- 서비스 메시에서는 모든 서비스에 유효 기간이 존재하는 인증서를 발급하여 서비스 간 통신을 위한 mTLS 제공/ mTLS는 TLS 핸드쉐이크를 두번 수행하여 양방향으로 암호화 통신 설정
https://blog.aquasec.com/istio-kubernetes-security-zero-trust-networking
전통적인 3-티어 구조의 보안 아키텍처에서는 외부 인터넷(Untrusted Network)의 HTTPS 트래픽은 SSL 종료(Termination)을 통해 HTTP 평문으로 복호화되고, 신뢰할 수 있는 네트워크(Trusted Network) 내에서는 평문으로 내부 서비스 간 통신을 합니다.
반면에, 제로 트러스트 보안 모델은 '아무것도 신뢰하지 않고 모든 것을 검증한다'는 원칙에 따라 작동합니다. 서비스 메시에서는 모든 서비스에 유효 기간이 존재하는 인증서를 발급하여 서비스 간 통신을 위한 mTLS를 제공합니다. 이를 통해 암호화되지 않은 트래픽을 암호화합니다. mTLS는 TLS 핸드쉐이크를 두 번 수행하여 양방향으로 암호화 통신을 설정합니다. 마이크로서비스 환경에서는 모든 서비스 간의 통신의 환경은 안전하지 않다(Zero Trust)고 가정하고, 서비스 메시에서는 애플리케이션 간에 mTLS를 활성화하여 보안을 단순화시킬 수 있습니다.
관찰 가능성 (Observability)
서비스의 복잡도가 증가함에 따라, 서비스의 동작과 성능을 이해하고 파악하는 것이 더욱 어려워졌습니다. 서비스 메시는 모든 통신에 대한 상세한 텔레메트리(telemetry)를 생성합니다. 이 텔레메트리는 서비스 동작의 관찰 가능성의 기초 자료로 활용되고, 운영자가 이에 대한 분석을 통해 애플리케이션의 문제를 해결하고 유지 관리하고 최적화할 수 있도록 합니다. 관찰 가능성은 로그, 메트릭 및 추적과 같이 생성하는 데이터를 기반으로 시스템의 현재 상태를 측정하는 기능입니다.
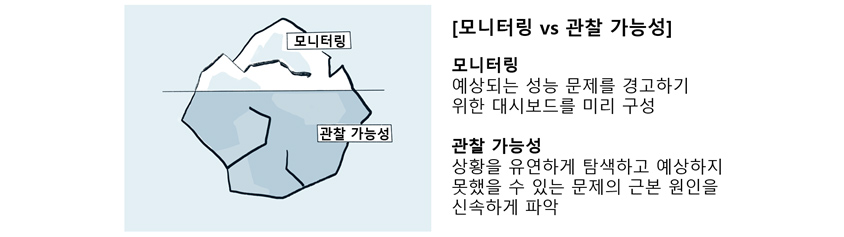
- 모니터링 : 예상되는 성능 문제를 경고하기 위한 대시보드를 미리 구성
- 관찰 가능성 : 상황을 유연하게 탐색하고 예상하지 못했을 수 있는 문제의 근본 원인을 신속하게 파악
관찰 가능성과 모니터링은 관련되어 있고 서로를 보완할 수 있지만 실제로는 다른 개념입니다. 모니터링 용어와는 어떤 차이가 있을까요? 모니터링 시나리오에서는 일반적으로 나중에 볼 것으로 예상되는 성능 문제를 경고하기 위한 대시보드를 미리 구성합니다. 그러나 이러한 대시보드는 발생하기 전에 어떤 종류의 문제가 발생할지 예측할 수 있다는 주요 가정에 의존합니다.
클라우드 네이티브 환경은 동적이고 복잡하기 때문에 이러한 유형의 모니터링에 적합하지 않습니다. 즉, 어떤 종류의 문제가 발생할 수 있는지 미리 알 수 있는 방법이 없습니다. 관찰 가능성 시나리오에서는 상황을 유연하게 탐색하고 예상하지 못했을 수 있는 문제의 근본 원인을 신속하게 파악할 수 있습니다.
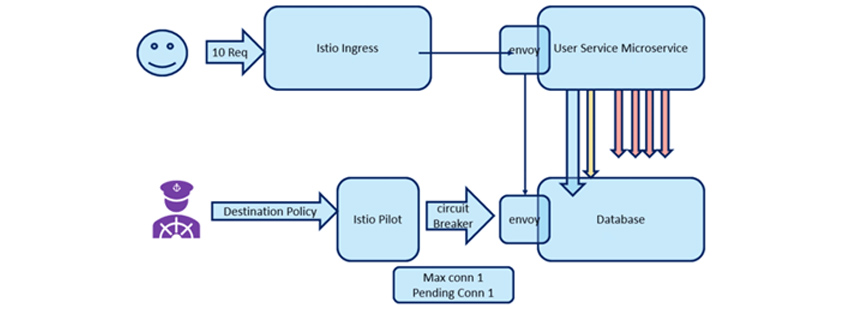
- 10Req -> Istio ingress ->envoy,User Service Microservice
- destination policy -> Istio Pilot ->(circuit breaker) envoy,database
- Max conn 1/ Pending Con 1
느리게 응답하고 전체 스택에 병목 현상을 일으키는 백엔드 서비스 인스턴스가 있다고 가정해보겠습니다. 프론트엔드 서비스의 요청이 시간 초과되어, 느린 서비스 인스턴스에 연결을 다시 시도합니다. 서비스 메시를 이용하여 프론트엔드 인스턴스가 정상적인 백엔드 인스턴스에만 연결되도록 하는 서킷 브레이커를 사용할 수 있습니다. 따라서 서비스 메시를 사용하면 스택의 가시성이 향상되고 문제를 해결하는 데 도움이 됩니다.

도입 전 확인 사항
서비스 메시는 누구에게 도움이 되나요?
Google, IBM 및 Lyft 간의 협업으로 탄생한 오픈 소스 서비스 메시인 이스티오라는 프로젝트에 대해 이야기하지 않고, 서비스 메시 환경에 대해 이야기하는 것은 어렵습니다.
 이미지 출처: https://istio.io
이미지 출처: https://istio.io
오늘날 서비스 메시에 대해 알고 있는 대다수의 사람들이 이스티오를 통해 서비스 메시를 소개 받았기 때문입니다. 이는 Google과 IBM의 엄청난 양의 마케팅 노력 때문인데, 이에 대한 영향으로 서비스 메시 및 이스티오가 Google에 의해 크게 홍보되었습니다. 때문에, 서비스 메시가 과대 포장된 부분으로 인해, 문제에 대한 해결보다는 기술 도입을 무조건적으로 검토하는 것은 아닌지 확인해볼 필요가 있습니다. 먼저, 어떤 문제를 해결하기 위해 서비스 메시를 내가 운영해야 하는 플랫폼에 도입하는지 당위성을 확인해보고, 여러 가지 서비스 메시 도구 중 이스티오 외 다른 더 좋은 대안은 없는가를 살펴보아야 합니다.
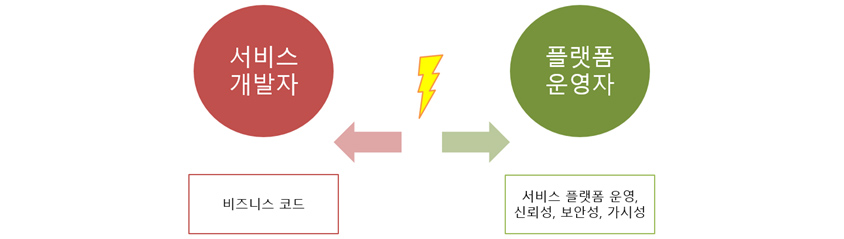
- 서비스 개발자 / 플랫폼 운영자
- / ->
- 비즈니스 코드/ 서비스 플랫폼 운영, 신뢰성, 보안성, 가시성
서비스 메시 도입을 검토하기 전에, 먼저 누가 혜택을 받을 것인지 나의 역할은 무엇인지부터 확인해 봐야 할 것입니다. 팀에서 오너십을 크게 구분한다면, 비즈니스를 담당하는 서비스 개발자와 이러한 서비스가 실행되는 플랫폼의 플랫폼 운영자로 나눌 수 있습니다. 두 역할 중에서 서비스 메시의 직접적인 수혜자는 플랫폼 운영자입니다. 결국 플랫폼 팀의 목표는 서비스 개발자가 비즈니스 로직을 실행할 수 있는 플랫폼을 구축하고 운영 환경을 서비스 개발팀에 영향 없도록 만드는 것입니다. 서비스 메시는 이러한 환경을 위한 기능들을 제공하고, 서비스 개발자에 대한 종속성을 유발하지 않도록 합니다.
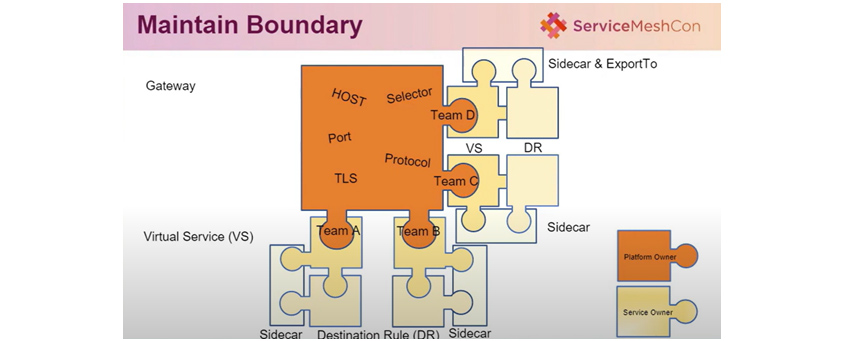
- gateway : host,selector.port,TLS,protocol, team A, team B, team C, team D / sidecar exportTo
- virtual service(VS) : sidecar destination rule (DR) sidecar / platform opener /service 0pener /sidecar /team A, team B
간접적이긴 하지만 서비스 개발자도 혜택을 받습니다. 서비스 개발자의 목표는 비즈니스 로직에 대한 구현에 집중하는 것이며, 운영 메커니즘이 적을수록 더 쉬워집니다. 예를 들어 재시도 정책이나 TLS를 구현하는 데 매달리기보다는 관련 기능에 대한 코드 반영을 할 필요 없이 비즈니스 로직에만 집중하고 플랫폼이 나머지를 처리할 것이라고 생각할 수 있습니다. 이는 서비스 개발팀에게도 큰 장점으로 부각될 수 있습니다. 플랫폼 운영과 서비스 개발 분리의 조직적 가치는 아무리 강조해도 지나치지 않습니다. 사실 이것이 서비스 메시가 가치 있는 핵심 이유라고 볼 수 있습니다. 서비스 메시를 운영하려는 조직이 결정되면, 다음 사항들을 먼저 확인해봐야 합니다.
서비스 메시가 정말 필요한가요?
사용자가 서비스 메시 도입을 하기 전에 도움이 될 수 있는지에 대한 지침이 필요합니다. 서비스 메시 자체가 목적이 되어서는 안 됩니다.

- 1. 개발/운영 조직의 규모는? 1. < 5, 2. 5~20, 3. 21~100, 4. 101+
- 2. 애플리케이션 내 서비스 개수는? 1. 1, 2. 2~10, 3. 11~100, 4. 101+
정답이 있는 것은 아니지만 아래와 같은 질문을 던져본다면, 서비스 메시 도입 여부를 결정하는데 도움이 될 수 있습니다.
엔지니어링 조직에 몇 명이 있습니까?
얼마나 많은 마이크로서비스가 있습니까?
이러한 마이크로서비스에는 어떤 언어가 사용됩니까?
오픈 소스를 사용한 경험이 있습니까?
어떤 플랫폼에서 서비스를 실행하고 있습니까?
서비스 메시에서 어떤 기능이 필요합니까?
사용하려는 서비스 메시 SW의 기능이 안정적으로 동작하나요?
서비스 메시 프록시는 가볍지 않다
프록시 자원은 인프라과 관련하여 리소스를 소비하고 및 네트워크 지연을 유발합니다. 메모리와 CPU를 소비하는 프록시를 사용하는 서비스 개수가 늘어남에 따라서 리소스 사용량이 증가하는 사례를 경험했습니다. 또한 서비스 간에 위치한 두 개의 프록시 자원은 네트워크 지연을 발생시킵니다.

- pod : consumer-gateway ->(to connection pool) Envoy ->(eTHO connection pool) ->Envoy ->(to connection pool) -> sauron-seo-app
일반 컨테이너 통신에서는 소스 컨테이너와 대상 컨테이너 사이에 커넥션 풀이 1개만 있지만 서비스 메시에서는 3개의 커넥션 풀이 있습니다.
소스 컨테이너 → 소스 사이드카 프록시
소스 사이드카 프록시 → 타켓 사이드카 프록시
타켓 사이드카 프록시 → 타켓 컨테이너
커넥션 풀이 늘어남으로 인해, 트러블 슈팅 구간(point of failure)도 확장됩니다. 서비스 메시를 운영하는 플랫폼 운영자는 이러한 비용을 직접적으로 감수해야 하고, 비즈니스 개발자 및 최종 사용자(End User)에게도 간접적으로 영향을 미칩니다.
인그레스 오브젝트 활용 어려운 케이스
이스티오의 경우, 외부 통신을 하기 위해서는 Istio Ingress Gateway 또는 Istio Ingress를 사용해야합니다. 그런데, 쿠버네티스 사용자는 보통 인그레스 오브젝트에 익숙하기 때문에 Istio Ingress를 사용하는 경우가 있을 것입니다.
 이미지 출처: https://istio.io
이미지 출처: https://istio.io
문제는 Ingress 관련 어노테이션 옵션을 활용하는 케이스가 있는 경우, 기존 nginx 인그레스 커뮤니티 버전 수준으로 세부 기능들이 제공되지 않는다는 것입니다.
예) Istio Ingress에서는 다음과 같은 annotation 사용 불가
nginx.org/ssl-backends: wildfly
nginx.ingress.kubernetes.io/ssl-passthrough
nginx.ingress.kubernetes.io/backend-protocol: "HTTPS"
nginx.ingress.kubernetes.io/secure-backends: "true"
nginx.ingress.kubernetes.io/ssl-redirect: "true"
mTLS 통신의 단점
보안 네트워크 정책을 생성하기 위해 mTLS를 사용하는 경우 모든 연결이 프록시를 통과하기 때문에 사용자는 클러스터에서 트래픽을 암호화하는 데 사용할 때 상당한 성능 저하를 경험하게 됩니다. 또한 설계상 서비스 메시는 사이드카 프록시를 사용하여 정책을 제어하므로 컨테이너에서 나오는 모든 연결은 자동으로 합법적인 트래픽으로 처리됩니다. 공격자가 컨테이너에 침입하면 자동으로 해당 컨테이너 네트워크 ID를 상속하므로 무엇이든 할 수 있습니다. 서비스 메시의 보안 조치만을 맹목적으로 신뢰하기보다는 전체적인 접근 방식을 고려하는 것이 중요합니다.
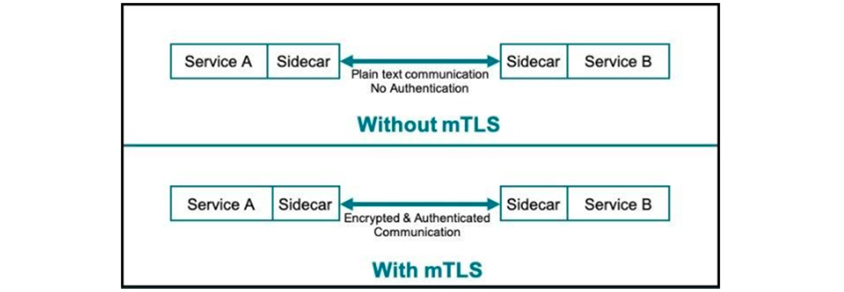
- service A / sidecar ->(plain text communication No Authentication) sidecar / service B
- service A / sidecar ->(Encrypted & Authentication communication) sidecar / service B
코드 수정이 필요한 경우가 발생한다.
앞서 비즈니스를 담당하는 서비스 개발자는 애플리케이션 코드의 변경 없이 서비스 메시를 사용할 수 있다고 하였습니다. 그런데, 몇 가지 특정 기능을 사용하기 위해서는 애플리케이션 코드를 수정하거나, 관련 라이브러리를 반영해야 하는 상황이 발생합니다.
사례 1: HTTP 헤더 기반 Request Routing
트래픽 라우팅 중에 HTTP 헤더값에 따라, 대상 서비스를 다르게 라우팅하는 기능이 있습니다. 이러한 경우, 애플리케이션 코드를 이스티오 오브젝트의 헤더 식별 규칙에 맞춰서 변경해야 합니다.
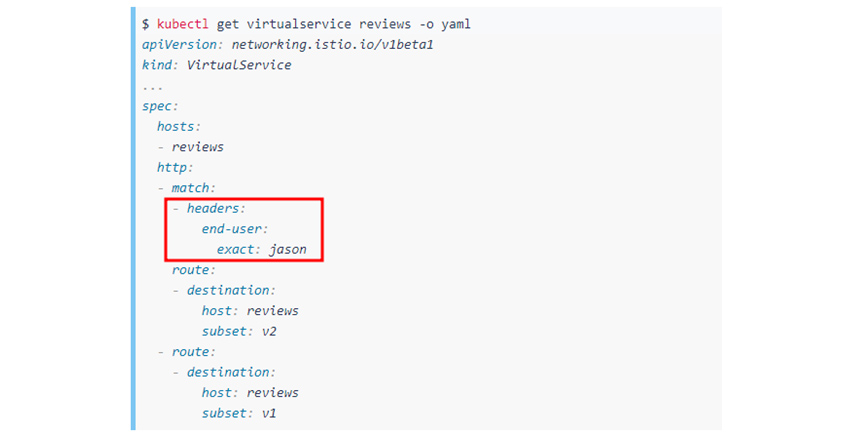
- $ kubect1 get virtualservice reviews -o yam1
- apiVersion : networking.istio.io/v1beta1
- kind: virtualservice
- ...
- spec:
- host:
- -reviews
- http:
- -match:
- -headers:
- end-user:
- exact:jason
- rooute:
- -destination:
- host:reviews
- subset:v2
- -rooute:
- -destination:
- host:reviews
- subset:v1
사례 2: 트레이싱 헤더를 반영하기 위한 텔레메트리 라이브러리 사용
관찰 가능성을 위해 Jaeger와 같은 트레이싱 도구를 사용하는 경우, 소스코드에 텔레메트리 라이브러리를 반영해 주어야 합니다. 서비스를 추적하기 위해, 텔레메트리 라이브러리를 통해 트레이스 ID(trace id)를 생성합니다. 이 트레이스 ID는 스팬이라고 불리는 서비스 헤더를 통해 전파됩니다. 스팬(Span)은 서비스명, 서비스 시작 시간 및 기간이 있는 논리적 작업 단위를 나타냅니다. 그리고, 트레이스(Trace)는 실행 경로이고, 1개 이상의 스팬으로 이루어져 있습니다. 트레이스는 클라이언트가 특정 기능 요청 후 응답을 리턴받을 때까지의 스팬들로 구성됩니다.
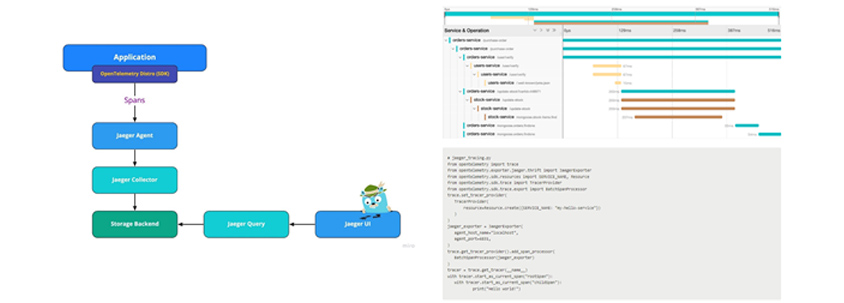 이미지 출처: https://www.jaegertracing.io
이미지 출처: https://www.jaegertracing.io
트러블 슈팅이 어렵다
사례 1: 사이드카 삽입 직후 서비스 중단
Zookeeper는 쿠버네티스 스테이트풀셋(StatefulSet)으로 실행됩니다. 각 Zookeeper 파드에 엔보이 프록시를 주입하려고 하면 Zookeeper 파드가 실행되지 않고 통신을 설정하지 못하여 계속 재시작을 반복하는 문제가 발생했습니다. 기본적으로 Zookeeper는 서버 간 통신을 위해 파드(Pod) IP 주소에서 수신을 대기합니다. 그러나 이스티오는 바인딩 주소가 파드 IP 주소가 아닌 localhost (127.0.0.1)여야 합니다.
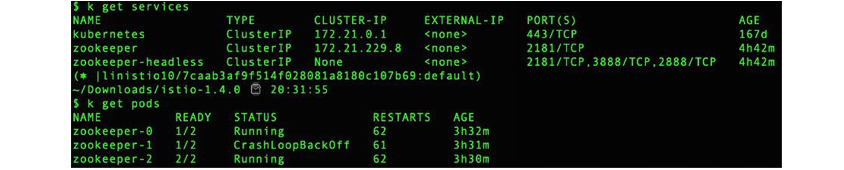 이미지 출처: https://www.cncf.io/blog/2020/10/26/service-mesh-is-still-hard
이미지 출처: https://www.cncf.io/blog/2020/10/26/service-mesh-is-still-hard
사례 2: 애플리케이션 시작 또는 중지 시 서비스의 이상 동작
애플리케이션 컨테이너가 사이드카보다 먼저 시작되는 경우 애플리케이션 오류가 발생할 수 있습니다. 사이드카가 앱 컨테이너보다 먼저 중지되는 경우에도 비슷한 문제가 발생할 수 있습니다. 쿠버네티스에는 컨테이너 종속성을 선언하는 표준 방법이 없습니다. 사이드카 KEP (Kubernetes Enhancement Proposal)가 이슈로 등록돼 있으나, 아직 쿠버네티스 릴리스로 반영되지 않았습니다.
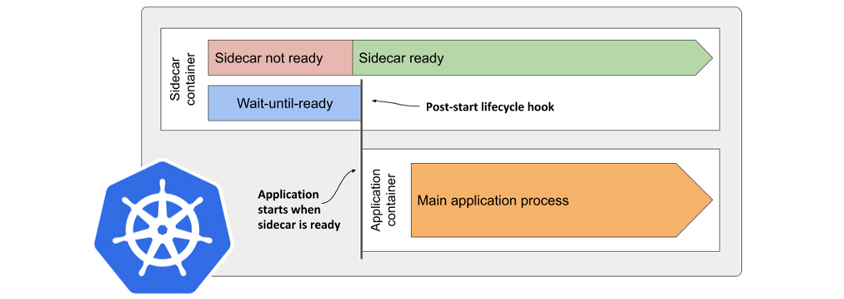
- sidecar container : sidecar not ready/sidecar ready
- wait-uuntil-ready/ post-start lifecycle hook
- application starts when sidecar is ready -> /application container:main application process
위 그림은 문제를 해결하기 위해 사이드카가 준비될 때까지 애플리케이션 시작을 지연할 수 있는 lifecycle.postStart 옵션을 적용한 해결 방법입니다. 그러나, 메인 프로세스가 실패하면 애플리케이션 컨테이너가 바로 시작하기 때문에 완벽하다고 볼 수 없습니다.
사례 3: 서버 시간 불일치(time skew)로 인한 장애
서버 시간을 동기화하기 위한 별도 NTP를 운영하지 않은 경우에는 노드 간에 서버 시간이 갈수록 불일치하는 현상이 발생할 수 있습니다. 컨트롤 플레인에 반영된 변경사항이 데이터 플레인에 제대로 반영되지 않는다던가, 텔레메트리 수집 도구(Zipkin)에서 트레이스를 찾을 수 없는 현상이 그 예입니다.

위 화면은 스팬(span) 순서의 역전 현상이 발생하여, 클라이언트의 스팬이 서버의 스팬보다 뒤에 발생하는 것으로 표기된 사례입니다.
대안은 없는가?
트래픽 라우팅의 대안은 없는가?
단편적인 예이지만, 카나리 배포의 경우 nginx 인그레스 컨트롤러는 canary annotation을 적용할 수 있습니다. 또한, ArgoCD에서도 롤아웃 플러그인을 설치하면 strategy.canary.steps.setWeight 속성 정의를 통해 카나리 배포를 할 수 있습니다. 이외 트래픽 라우팅의 다른 기능도 서비스 메시 외 대안이 있는지 확인해 볼 필요가 있습니다.
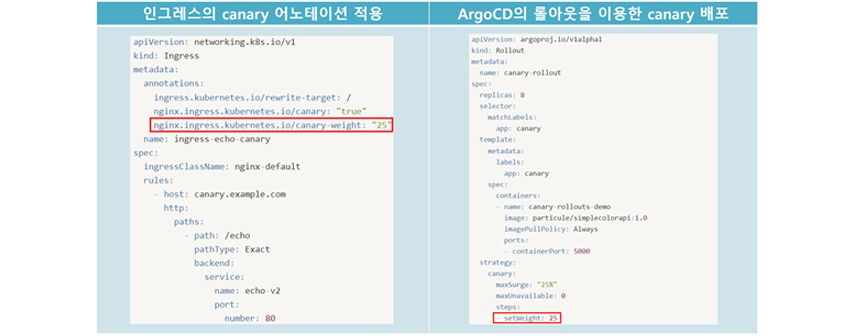
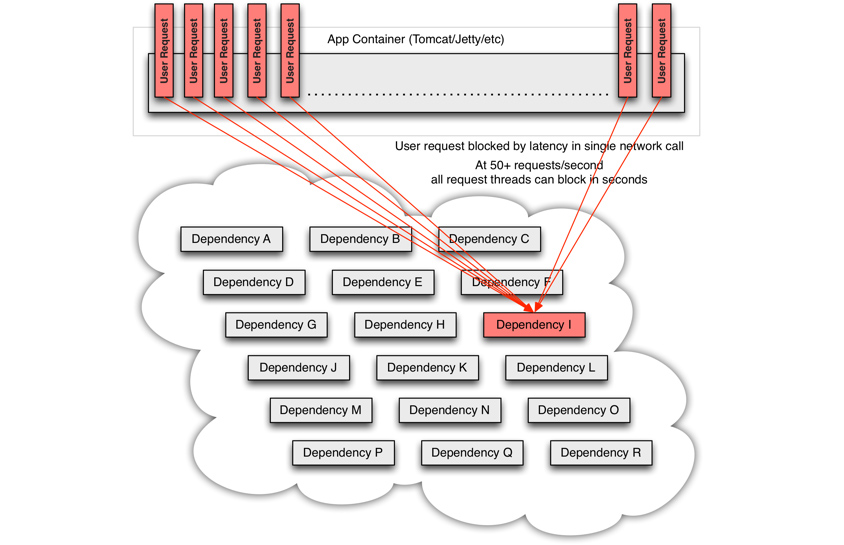
서킷 브레이커의 대안은 없는가?
기존에도 사용했던 방식으로, 해당 케이스에 대한 요건만 있다면, Spring Cloud for Kubernetes의 hystrix 라이브러리 사용하여 서킷 브레이커를 적용할 수 있습니다. 아래 사례는 하위 서비스 호출 응답 지연으로, 장애 전파 (Cascade Failure)가 발생하는 사례입니다. 이러한 경우, 애플리케이션 내 서킷 브레이커를 적용하여, 빠른 실패 응답을 발생시켜 장애 전파를 막을 수 있습니다.
- user request,user request,user request,user request,user request/app container(Tomcat/Jetty/ect)/user request,user request ->
- user request blocked by latency in single network call At 50+ request/second all request threads can block in seconds
- dependency A,dependency B,dependency C
- dependency D,dependency E,dependency F
- dependency G,dependency H, -> dependency I
- dependency J,dependency K,dependency L
- dependency M,dependency N,dependency O
- dependency P,dependency Q,dependency R
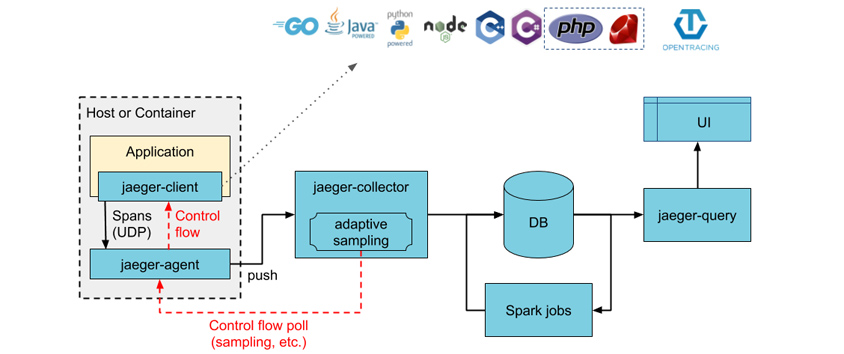
관찰 가능성의 대안은 없는가?
서비스 메시를 구성하지 않아도, Jaeger, Zipkin 분산 트레이싱 도구만으로도, 관찰 가능성 목표를 달성할 수 있습니다. Jaeger는 쿠버네티스 오버레이터 방식으로 구성하도록 가이드를 지원합니다.
- application
- jaeger-client
- Spans(UDP)-> / -Control flow
- -(control flow poll(sampling, etc.)) jaeger-agent ->
- jaeger-collector
- -> adaptive sampling ->
- -> DB ->
- - Spark jobs -
- jaeger-query ->
- UI
References
[1] https://www.cncf.io/blog/2020/10/26/service-mesh-is-still-hard/
[2] https://www.cncf.io/blog/2021/12/17/benchmarking-linkerd-and-istio-2021-redux/
[3] https://www.cncf.io/blog/2022/05/17/service-meshes-are-on-the-rise-but-greater-understanding-and-experience-are-required/
[4] https://linkerd.io/2021/04/01/introduction-to-the-service-mesh/
[5] https://istio.io/latest/blog/2022/get-started-ambient/
[6] https://istio.io/latest/blog/2022/introducing-ambient-mesh/
[7] https://linkerd.io/2020/12/03/why-linkerd-doesnt-use-envoy/
[8] https://buoyant.io/service-mesh-manifesto
[9] https://medium.com/containers-101/fully-automated-canary-deployments-in-kubernetes-70a671105273
[10] https://blog.aquasec.com/istio-kubernetes-security-zero-trust-networking
[11] https://medium.com/jaegertracing/jaeger-tracing-a-friendly-guide-for-beginners-7b53a4a568ca
[12] https://www.waytoeasylearn.com/learn/istio-circuit-breaker/
[13] https://thenewstack.io/istio-applies-to-join-cncf-why-now/
[14] https://karlstoney.com/2019/05/31/istio-503s-ucs-and-tcp-fun-times/
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

삼성SDS 클라우드서비스사업부 클라우드개발실 SCP Platform아키텍처그룹
저는 Samsung Cloud Platform에서 AI/ML 서비스 중 AIOS의 기획, 설계, 개발을 담당하고 있습니다. 또한, GPUaaS의 다양한 서비스 기술을 클라우드 환경에 적극적으로 접목하고자 다양한 방안을 모색하고 있습니다.