

지난 1편에서는 어떻게 Spark에서 클러스터 컴퓨팅 작업들이 처리되는지를 이해하고, 이를 기반으로 Spark Context를 잘 관리함으로써 얻을 수 있는 장점들에 대해 소개를 해드렸습니다. 이번 시간에는 이를 바탕으로 Spark에서 제공하는 Fair Scheduler와 Dynamic Resource Allocation 기능을 사용해 어떻게 효율적으로 리소스를 관리할 수 있는지에 대해 소개하겠습니다.
Job간의 경합을 해결하는 Spark의 Fair Scheduler
지난 시간에서도 언급했듯이 하나의 Application은 여러 Job을 실행시켜서 원하는 바를 달성합니다. 예를 들어 1부터 10까지의 평균을 구하는 Application을 작성한다고 해보겠습니다. 그렇다면 우리는 두 개의 값이 필요합니다. 전체 숫자를 더한 값 55, 전체 숫자의 개수 10, 이렇게 두 값을 구해서 최종 결과 값 55 / 10 = 5.5 를 얻을 수 있습니다. 평균을 구하기 위해서 우리는 2가지 일(Job)을 Spark에게 요청해서 작업을 수행하게 된 것입니다.
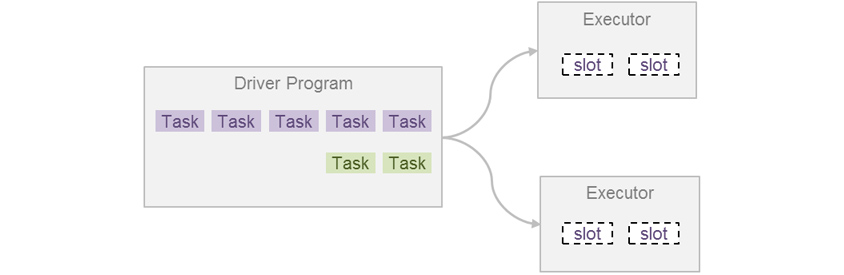 Spark Job Submit
Spark Job Submit
Spark에서 Job은 Task라고 하는 더 작은 실행 단위로 나뉩니다. 그리고 이 Task는 여러 Executor에게 작업 실행을 요청함으로써 병렬 처리가 가능하게 됩니다. 이후 Task가 종료되면 결과를 받고 다른 Task를 또 실행 요청하면서, Job의 모든 Task가 완료될 때까지 작업 요청을 진행하게 됩니다. 그리고 한 Job의 모든 Task가 종료되면 다음 Job을 실행할 수 있게 됩니다. 즉 먼저 실행된 Job의 모든 Task가 종료되면 그 다음 Job의 Task가 실행되는 FIFO (First In First Out) 구조입니다.
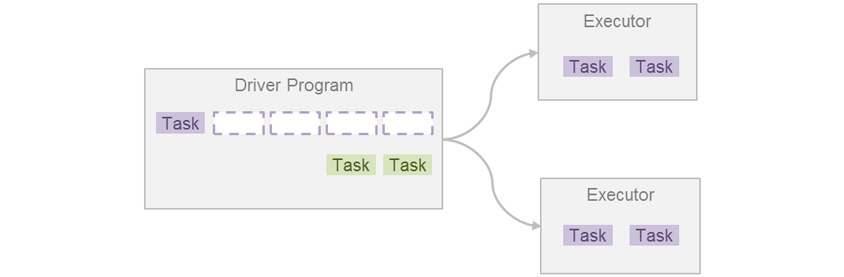 FIFO Scheduler
FIFO Scheduler
문제가 되는 상황은, 하나의 Job에서 실행해야 할 Task가 굉장히 많을 때, 뒤에 들어오는 Job의 Task 수가 아무리 적어도 멈춰서 기다려야 한다는 것입니다. 각 Job의 순수 실행 시간의 총합은 동일하겠지만, 대기시간(Response Time)을 포함한 전체 Job의 실행시간(Turnaround Time)은 어떤 Job이 먼저 실행되었느냐에 의해 크게 다를 수 있습니다.
이 문제를 해결하기 위해 Spark에서는 Fair Scheduling 기능을 제공하고 있습니다. 이는 Hadoop에도 동일하게 존재하는 Job Scheduling 방식 중 하나입니다. Spark Job은 Spark Scheduler의 Pool 안에서 동작하게 되는데, 이 Pool을 Fair로 설정하면 이용할 수 있습니다.
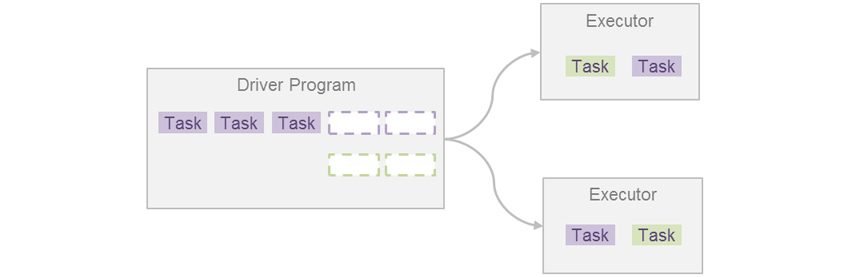 Fair Scheduler
Fair Scheduler
위와 같이 여러 Job이 제출될 경우 모든 Job에 대해 동일한 양의 리소스를 분배해줌으로써 동시에 여러 Job의 실행이 가능하게 됩니다. 또한 여러 개의 Pool을 구성하여 Job 간의 우선순위를 정해줄 수도 있습니다. 이렇게 Scheduler를 설정하여 여러 Job을 동시에 실행시킴으로써, Application의 총 실행 시간을 줄이고 처리량을 올릴 수도 있습니다.
효율적 리소스 할당을 위한 Dynamic Resource Allocation
앞에서는 하나의 Application 내에서 여러 Job이 동시에 존재했을 때의 이슈를 알아 보았습니다. 그렇다면 만약 Spark Cluster에 여러 Application이 존재할 때는 또 어떤 리소스 이슈가 있을 수 있을까요?
Spark Application은 Cluster Manager를 통해 Application에서 사용할 전체 리소스를 예약해두게 됩니다. 총 몇 CPU cores를 사용할지 Cluster Manager에 전달함으로써, 리소스를 할당받게 되는 것입니다. 앞에서 언급한 Filter, Correlation등을 독립된 Application으로 개발하면 각각 실행될 때마다 리소스를 새롭게 할당받게 되고, 이 리소스의 실체는 Executor와 그 Executor에서 사용 가능한 Cores 수가 되는 것입니다. 참고로 Spark Job Server는 그 자체로 하나의 Spark Application이고 함수들은 여러 Job 그룹들이 되는 형태입니다.
많은 Application이 실행되다 보면 아래와 같이 사전에 할당 받은 리소스를 사용하지 않는 상황이 발생할 수도 있습니다. 예상보다 데이터가 작았거나 Application의 작업이 상대적으로 너무 빨리 종료되었을 때 발생하는 상황입니다. 그렇게 되면 아래 그림의 왼쪽과 같은 모습이 연출됩니다. 결국 Cluster에 리소스는 충분히 있지만 사용하지 않게 되는 것이죠.
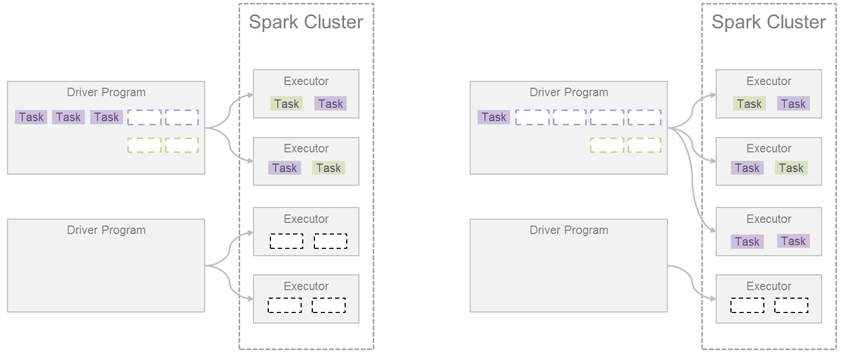 리소스를 많이 사용하는 어플리케이션에서 추가로 자원을 요청하는 것 ‐ Static Resource Allocation vs Dynamic Resource Allocation
리소스를 많이 사용하는 어플리케이션에서 추가로 자원을 요청하는 것 ‐ Static Resource Allocation vs Dynamic Resource Allocation
다행히 우리는 Spark의 Dynamic Resource Allocation 기능을 활용하여 그림의 오른쪽과 같이 문제를 해결할 수 있습니다. 즉 리소스를 많이 사용하는 Application에서 추가로 자원을 요청하는 것입니다. 이렇게 함으로써 훨씬 효율적으로 리소스를 사용하게 될 수 있습니다.
참고로 이 기능은 Spark 1.2 에서 도입이 되었습니다. 당시에는 Hadoop Yarn에서만 사용 가능했고, 이를 위해 Yarn의 Scheduler 설정을 추가로 해주어야 했습니다. 이후 Spark 1.6부터는 Standalone과 Mesos에서도 지원이 되면서 널리 사용 가능하게 되었습니다.
여기서 주의할 점은 Spark Job Scheduler의 리소스 공유 단위가 CPU cores 였다면, Dynamic Resource Allocation의 리소스 공유 단위는 Executor라는 것입니다. 그리고 한 Application에서 사용할 수 있는 최대/최소 Executor 수를 지정할 수 있는데, 한 Application에서 전체를 독점하게 되면 다른 Application이 실행할 때 즉시 대응할 수 없는 문제도 발생할 수 있으니, 실제 사용자들이 어떤 방식으로 분석 작업을 하는지에 따라 적절한 수치를 찾는 것이 굉장히 중요합니다.
끝으로
지금까지 2편에 걸쳐 Spark Cluster에서 CPU 리소스를 잘 활용하기 위한 여러 기법을 알아봤습니다. 다시 살펴보자면 Spark Job Server를 이용해서 사전에 Spark Context의 리소스를 미리 확보할 수 있었고, Fair Scheduler를 이용해서 Spark Context 내에서 이루어지는 Job들의 경합과 우선순위를 제어할 수 있었습니다. 그리고 Dynamic Resource Allocation을 통해 Spark Context 간의 효율적 리소스 재분배도 가능하게 됐습니다.
사실 이렇게 전달해드린 내용만으로는 최적의 클러스터 환경을 한 번에 구축하기는 쉽지 않을 것입니다. 이 지식을 기반으로 시스템을 운영해나가면서 최적의 리소스 설정 값과 Spark Context 개수 등을 계속 찾아야 합니다. 결국 상황에 따른 튜닝이 반드시 계속 필요합니다. 그리고 이를 잘 하기 위해서는 Spark Context와 Spark Execution Model을 잘 이해하는 것이, Spark Cluster를 구축하고 운영하는데 매우 중요합니다. 아무쪼록 이 글이 Spark Cluster를 운영하는 초급, 중급 사용자들에게 작은 도움이 되었으면 하는 바람입니다.
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

삼성SDS AI Analytics팀
삼성SDS 빅데이터 플랫폼 Brightics AI 개발 조직에서 개발 및 기술 지원 업무를 맡고 있습니다. 사내외 여러 Site에서 Spark, Hadoop 기반의 빅데이터 플랫폼 구축을 위한 기술 지원 업무를 수행했습니다. 현재는 Kubernetes를 활용한 Containerization 업무를 수행하고 있습니다.