
금요일 저녁, 친구와 약속이 있습니다. 친구가 말합니다. "일몰 보면서 산책할 수 있는 데 가자, 대중교통으로 가기 편한 곳으로." 스마트폰을 꺼내 검색해봅니다. 남산타워, 한강공원, 경복궁. 틀린 답은 아닙니다. 하지만 왠지 아쉽습니다. 친구가 원했던 건 단순히 유명한 장소가 아니라, 지금 이 시간, 오늘 저녁 이 상황에 맞는 곳이었으니까요. 질문 하나에는 사실 여러 조건과 맥락이 함께 담겨 있었습니다.
RAG 시스템도 비슷한 문제를 안고 있습니다. LLM이 외부 지식을 검색해 답변을 생성하는 RAG* 구조에서, 질문과 직접 관련 없는 정보가 함께 검색되면 핵심 정보가 희석되고 답변 품질이 떨어집니다. 이를 해결하기 위해 문서와 개체 사이의 관계를 그래프로 표현하는 Graph 기반 RAG가 등장했지만, 여기서도 한계는 남아 있습니다. 많은 그래프 탐색 방식이 질문의 의미와 무관하게, 연결이 많거나 구조적으로 가까운 노드를 우선 탐색합니다. 질문이 바뀌어도 탐색 경로는 거의 그대로입니다.
* RAG (Retrieval-Augmented Generation): 외부 지식 베이스에서 관련 정보를 검색해 LLM의 생성 품질을 높이는 기법
삼성SDS 연구팀은 이 문제를 ‘흐름(Flow)’이라는 개념에서 실마리를 찾았습니다. 그래프 이론에서 오래전부터 쓰여온 흐름 확산(flow diffusion) 기법을 RAG의 맥락으로 재해석해, 질문의 의미에 따라 그래프 연결 강도를 동적으로 조정하고 정보가 의미 있는 경로를 따라 ‘흘러가도록’ 유도합니다. 이것이 Query-Aware Flow Diffusion RAG(QAFD-RAG)의 핵심 아이디어입니다.
QAFD-RAG란?
QAFD-RAG(Query-Aware Flow Diffusion RAG)는 별도의 학습이나 파인 튜닝 없이(training-free), 쿼리의 의미에 따라 지식 그래프의 간선 가중치를 동적으로 조정하고, 흐름 확산(flow diffusion)을 통해 관련 서브그래프만을 선택적으로 추출하는 Graph 기반 RAG 프레임워크입니다. Samsung SDS Research America가 개발해 ICLR 2026에 발표했습니다.
Query-Aware Flow Diffusion for Graph-Based RAG with Retrieval Guarantees 👉 논문 바로가기
1. Graph 기반 RAG는 왜 등장 했나
RAG는 LLM이 모르는 정보, 혹은 최신 정보를 외부에서 가져와 답변에 활용하는 구조입니다. 고객 지원 챗봇, 사내 문서 검색, 기술 지원 도우미 등 다양한 서비스에서 이미 폭넓게 쓰이고 있습니다. 그런데 실제 운영 환경에서는 질문과 직접 관련 없는 문서까지 함께 검색되는 일이 자주 발생합니다. 불필요한 정보가 함께 딸려오면 LLM에 전달되는 컨텍스트가 길어지고, 핵심 정보가 희석돼 답변 품질이 떨어집니다.
그래서 등장한 접근이 Graph 기반 RAG입니다. 문서와 개체 사이의 관계를 그래프 구조로 표현하는 방식입니다. 예를 들어 장애 분석 상황이라면, 장애 티켓 → 관련 서비스 → 인증 모듈 → 대응 문서처럼 여러 단계의 관계를 따라가며 정확한 정보를 찾을 수 있습니다. 이처럼 여러 지식 노드를 단계적으로 연결해 답을 찾는 방식을 멀티홉 추론(multi-hop reasoning)*이라고 합니다. 단순히 문서를 찾는 것이 아니라, 지식 관계 자체를 탐색하는 것입니다.
* multi-hop reasoning: 여러 지식 노드를 단계적으로 연결하며 답을 찾는 추론 방식
2. 기존 방법의 한계: query-agnostic 탐색
Graph 기반 RAG는 관계 구조를 활용한다는 점에서 분명한 강점이 있습니다. 하지만 기존 방법들은 공통된 한계를 가지고 있습니다. 바로 그래프를 탐색하는 방식이 질문의 의미와 무관하게 정해져 있다는 점입니다. GraphRAG는 미리 구성해둔 커뮤니티 단위로 문서를 묶어 반환합니다. LightRAG는 시드 노드 주변의 이웃 노드들을 가져옵니다. 어떤 질문이 들어오든, 탐색 방식 자체는 바뀌지 않습니다. 이를 query-agnostic*한 탐색이라고 합니다. 그 결과, 구조적으로 가깝거나 연결이 많은 노드는 질문과 관계없이 자주 선택됩니다. 마치 친구에게 "오늘 저녁 일몰 보기 좋은 곳"을 물었는데, 검색 엔진이 질문의 맥락은 따지지 않고 단순히 ‘서울’과 연결된 유명 장소를 전부 쏟아내는 것과 같습니다. 아래 [그림 1]에서 이 차이를 직접 확인할 수 있습니다. * query-agnostic: 질문 의미와 무관하게 그래프 구조나 연결 관계만으로 탐색이 이루어지는 특성
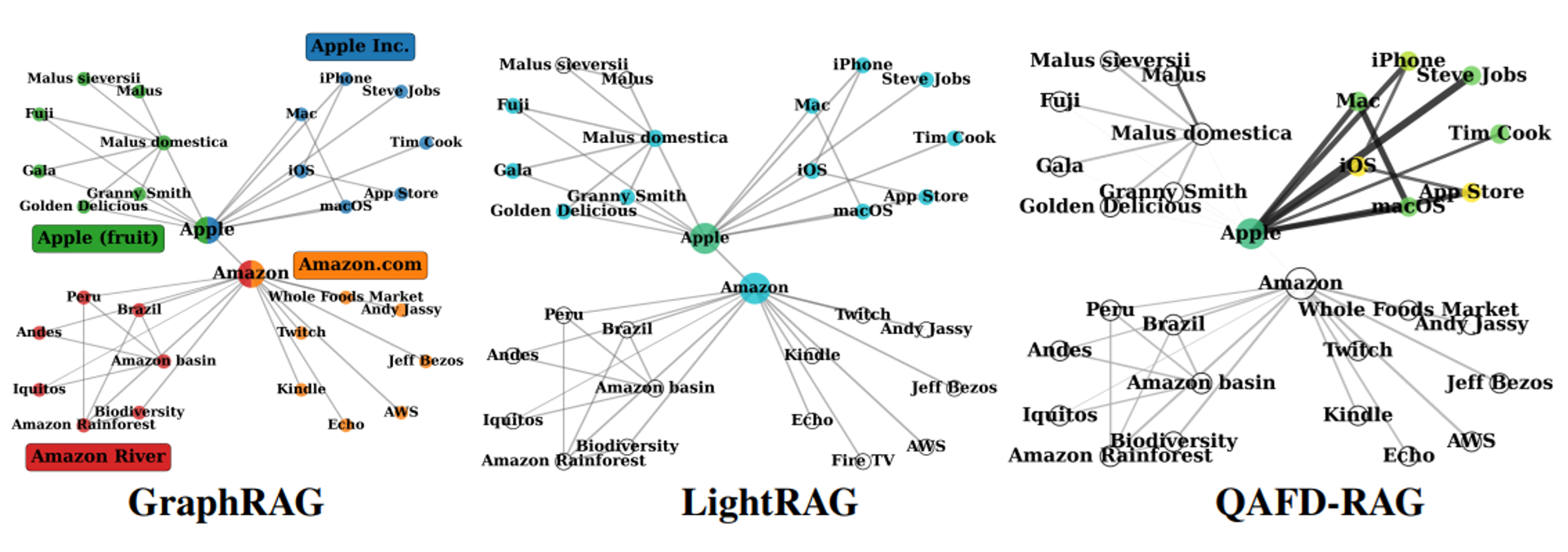 [그림 1] 쿼리 "Introduce Steve Jobs's products in Apple"에 대한 GraphRAG · LightRAG · QAFD-RAG의 탐색 결과 비교. GraphRAG는 Amazon River · Apple 과일 등 무관한 커뮤니티까지 포함하고, LightRAG는 구조적 이웃을 가져오지만, QAFD-RAG만이 쿼리 의미를 따라 iPhone · Mac · macOS에 집중합니다.
[그림 1] 쿼리 "Introduce Steve Jobs's products in Apple"에 대한 GraphRAG · LightRAG · QAFD-RAG의 탐색 결과 비교. GraphRAG는 Amazon River · Apple 과일 등 무관한 커뮤니티까지 포함하고, LightRAG는 구조적 이웃을 가져오지만, QAFD-RAG만이 쿼리 의미를 따라 iPhone · Mac · macOS에 집중합니다.
지식 그래프 기반 RAG 방법론 비교
- GraphRAG: 질의와 직접적인 관련이 없는 전체 커뮤니티를 검색합니다. 이 과정에서 'Mac', 'macOS'와 같은 관련 노드뿐만 아니라 'Amazon River', 'Apple (과일)'과 같이 질의 맥락과 무관한 노드들이 대량으로 포함됩니다.
- LightRAG: 시드 노드 주변의 1-홉(1-hop) 이웃 노드에 집중합니다. 'Steve Jobs', 'iPhone' 등 관련 노드를 찾지만, 구조적으로 가깝다는 이유로 'Fuji(사과 품종)'와 같은 불필요한 노드도 함께 추출합니다.
- QAFD-RAG (제안 모델): 질의의 전체적인 의미를 바탕으로 그래프 에지(연결선)의 가중치를 동적으로 재조정합니다. 이를 통해 'Amazon'이나 '과일 애플' 관련 클러스터로의 확산을 차단하고, 질의에 부합하는 일관된 서브그래프만을 추출합니다.
또 하나의 한계는 이론적 근거가 없다는 점입니다. 기존 방법들은 어떤 조건에서 관련 정보를 빠짐없이 가져올 수 있는지, 얼마나 불필요한 정보가 포함되는지에 대한 수학적 보장을 제공하지 않습니다. 잘 될 때는 잘 되지만, 왜 잘 되는지, 언제 안 될지를 예측하기 어렵습니다.
3. QAFD-RAG의 접근 방식: 2단계 파이프라인
QAFD-RAG는 두 단계로 작동합니다. 별도 학습이 전혀 필요 없는(training-free) 프레임워크입니다.
인덱싱 단계(Indexing Stage)에서는 원본 문서로부터 지식 그래프를 구축합니다. 문서를 의미 단위로 분할한 뒤 LLM을 활용해 개체(entity)와 관계(relation)를 추출합니다. 예를 들어 기술 문서 한 챕터에서 ‘데이터베이스 → 서비스 API → 인증 모듈’ 같은 연결 관계를 얻어냅니다. 이 단계는 쿼리와 무관하게 한 번만 수행됩니다.
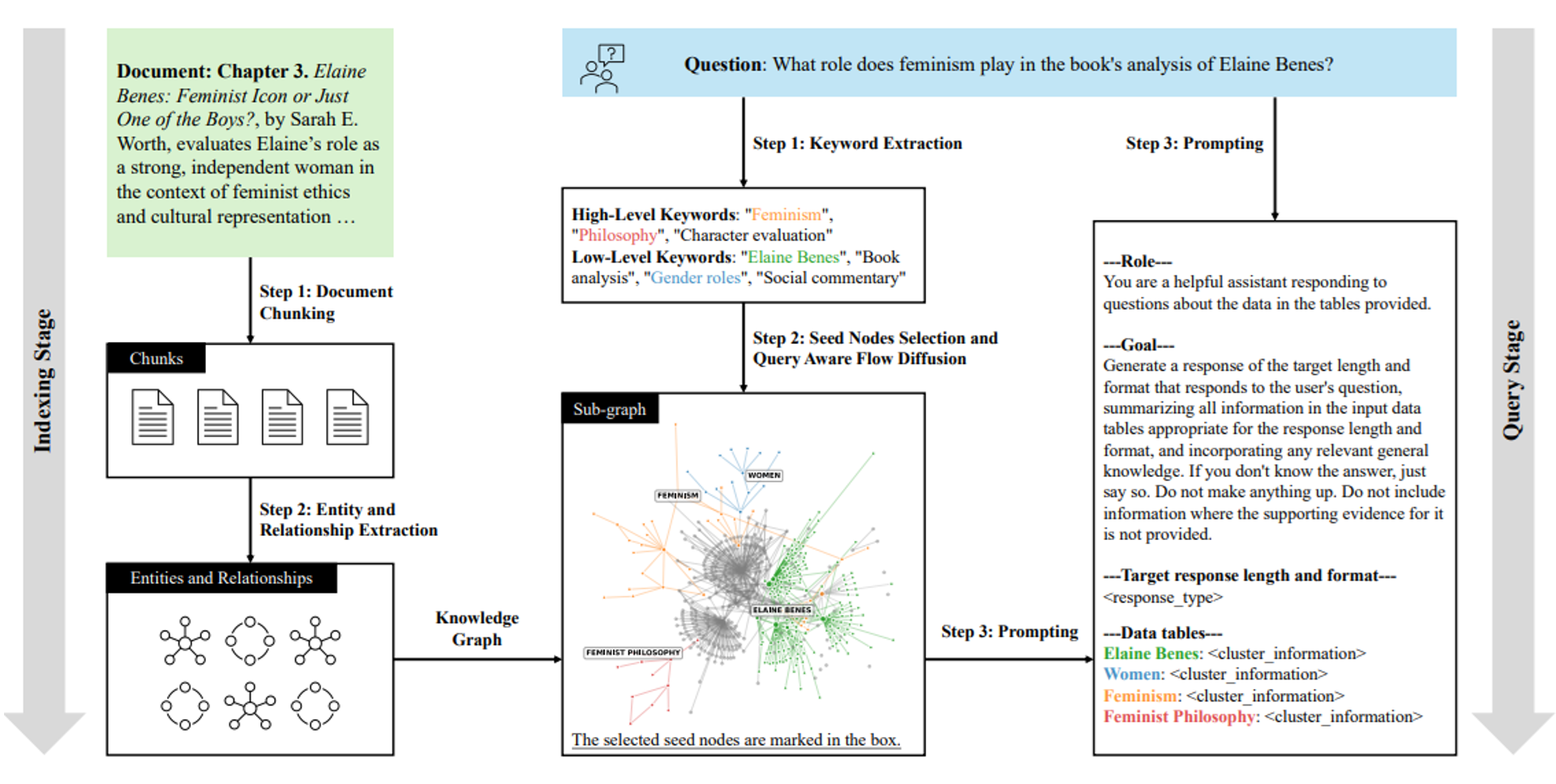 [그림 2] QAFD-RAG 전체 파이프라인. 인덱싱 단계(좌)에서 문서를 지식 그래프로 변환하고, 쿼리 단계(우)에서 키워드 추출 → 시드 노드 선택 → 흐름 확산 → 프롬프트 생성 순으로 관련 서브그래프를 추출합니다.
[그림 2] QAFD-RAG 전체 파이프라인. 인덱싱 단계(좌)에서 문서를 지식 그래프로 변환하고, 쿼리 단계(우)에서 키워드 추출 → 시드 노드 선택 → 흐름 확산 → 프롬프트 생성 순으로 관련 서브그래프를 추출합니다.
QAFD-RAG의 2단계 프레임워크 구조
- 인덱싱 단계 (Indexing Stage): 원본 문서(예: 일레인 베네스 관련 텍스트)를 청크(Chunk) 단위로 분할한 후, 엔티티(개체)와 관계를 추출하여 구조화된 지식 그래프를 생성합니다.
-
질의 단계 (Query Stage):
- 1. 키워드 추출: 사용자 질문에서 상위/하위 개념의 키워드를 뽑아냅니다.
- 2. 시드 노드 선택 및 흐름 확산: 추출된 키워드와 유사도가 높은 노드를 시작점으로 삼아, 질의 인식형 흐름 확산(QAFD) 기법으로 관련 서브그래프를 식별합니다.
- 3. 프롬프팅 및 생성: 선택된 서브그래프의 데이터를 바탕으로 LLM이 근거에 기반한 최종 답변을 생성합니다.
쿼리 단계(Query Stage)가 QAFD-RAG의 핵심입니다. 위의 [그림 2]에서 보듯이, 질문이 들어오면 먼저 LLM으로 키워드를 추출하고(Step 1), 그 키워드와 의미적으로 가까운 노드를 탐색의 시작점(seed node)으로 선택합니다(Step 2). 그런 다음 각 간선의 가중치를 질문 기반으로 실시간 조정한 뒤, 흐름 확산을 수행해 질문과 관련 높은 서브그래프를 탐색합니다(Step 3). 마지막으로 탐색된 서브그래프를 요약해 LLM의 컨텍스트로 전달합니다. 질문이 바뀌면 간선 가중치도 바뀌고, 탐색 되는 서브그래프도 달라집니다.
4. Flow Diffusion 원리: 질문이 탐색 방향을 바꾼다
흐름 확산(flow diffusion)은 물이 파이프를 통해 흐르는 모습과 비슷합니다. 강한 파이프(높은 가중치 간선)로는 물이 많이 흐르고, 약한 파이프(낮은 가중치 간선)로는 조금만 흐릅니다. QAFD-RAG에서 정보(질량, mass)는 시드 노드에서 출발해 간선 가중치에 따라 이웃 노드들로 퍼져 나갑니다.
핵심은 이 간선 가중치가 질문에 따라 매번 새로 계산된다는 점입니다. 간선 (u, v)의 가중치는 두 가지를 함께 봅니다. 노드 u와 v가 구조적으로 얼마나 가까운지, 그리고 각 노드가 질문의 의미와 얼마나 관련 있는지 입니다. 두 조건이 모두 충족되는 간선만 강화되고, 나머지는 자연스럽게 억제됩니다. 예를 들어 "인증 서버 장애 원인" 쿼리라면 인증 모듈, 세션 관리, 토큰 정책 방향으로 흐름이 집중되고, 관계없는 모니터링 노드나 백엔드 서비스 방향의 간선은 가중치가 낮아져 흐름이 차단됩니다.
확산이 반복될수록 흐름은 점점 특정 영역으로 집중됩니다. 최종적으로 남는 것은 질문과 의미적으로 밀접한 서브그래프뿐입니다. 이 서브그래프가 LLM의 RAG 컨텍스트로 사용됩니다.
이론적으로도 이 접근은 뒷받침됩니다. 논문은 신호 대 잡음비(SNR)*가 충분한 조건에서, 관련 노드는 빠짐없이 포함되고 비관련 노드로 흘러가는 정보량은 일정 수준 이하로 통제된다는 것을 수학적으로 증명합니다. 기존 방법들이 제공하지 못했던 이론적 보장입니다.
* SNR (Signal-to-Noise Ratio, 신호 대 잡음비): 관련 정보(신호)와 무관한 정보(잡음)의 비율. SNR이 높을수록 유용한 신호가 잡음보다 강하다는 의미
5. 실험 결과: 4개 벤치마크 성능 비교
QAFD-RAG의 핵심 주장은 두 가지입니다. 쿼리 의미를 반영한 탐색이 실제로 더 정확한 정보를 가져오는가, 그리고 그 효과가 특정 유형의 질문에만 국한되지 않고 다양한 환경에서도 일관되게 나타나는가입니다. 이를 검증하기 위해 논문은 Graph 기반 RAG 분야의 대표적인 방법들과 네 가지 벤치마크 영역에서 직접 성능을 비교했습니다.
비교 대상은 GraphRAG, LightRAG, HippoRAG, RAPTOR입니다. GraphRAG는 Microsoft가 개발한 방법으로, 문서 전체를 커뮤니티 단위로 묶어 요약한 뒤 질문에 답합니다. LightRAG는 시드 노드 주변의 이웃 노드를 탐색하는 경량 그래프 RAG로, 구조가 단순해 빠르지만 질문 맥락을 반영하지 못합니다. HippoRAG는 인간의 해마 기억 구조에서 영감을 받아 Personalized PageRank로 멀티홉 탐색을 수행하며 NeurIPS* 2024에 발표된 방법입니다. RAPTOR는 문서를 계층적으로 요약해 트리 구조로 쌓아두고 여러 수준에서 동시에 검색하는 방식입니다.
*NeurIPS(Neural Information Processing Systems): 매년 12월 개최되는 세계 최대 규모의 기계학습(Machine Learning) 학회
벤치마크는 RAG 시스템이 실제 서비스에서 마주치는 서로 다른 네 가지 유형의 어려움을 다루도록 구성했습니다. 일반 지식 QA는 GPT-4o가 0~100점 척도로 포괄성·다양성·논리성 등을 채점하는 방식입니다. 멀티홉 추론은 정답과 예측의 토큰 겹침 비율인 F1(%)과 완전 일치율인 Exact Match(%)로 측정합니다. 장문서 요약은 인간이 작성한 참조 요약과의 일치도로 평가하고, 텍스트-SQL 변환은 생성된 SQL이 실제로 올바른 결과를 반환하는지 확인하는 실행 정확도(%)를 씁니다. 단위와 측정 방식이 각기 다른 만큼, 모든 영역에서 고르게 앞선다는 것은 특정 유형에만 강한 게 아니라는 의미이기도 합니다. QAFD-RAG는 네 영역 모두에서 일관된 우위를 보였습니다.
일반 지식 QA 평가에서는 농업, 생물학, 요리, 역사, 법률 등 10개 도메인에 걸쳐 포괄성, 다양성, 논리성, 관련성, 일관성의 5개 축 모두에서 기존 방법들을 안정적으로 앞섰습니다. 특히 논리성 지표의 개선이 두드러졌는데, 쿼리를 따라 형성된 탐색 경로가 실제로 더 논리적으로 연결된 컨텍스트를 제공하고 있음을 보여줍니다.
멀티홉 추론(HotpotQA, MuSiQue) 벤치마크는 Graph 기반 RAG의 진가를 보여주는 영역입니다. 아래 표에서 볼 수 있듯, QAFD-RAG는 HotpotQA에서 F1 73.42%, Exact Match 58.10%를 기록해 모든 방법 중 가장 높은 점수를 달성했습니다.
| 방법 | HotpotQA F1 (%) | HotpotQA EM (%) | MuSiQue F1 (%) | MuSiQue EM (%) |
|---|---|---|---|---|
| GraphRAG | 33.40 | 14.00 | 39.40 | 17.60 |
| LightRAG | 8.80 | 0.00 | 1.40 | 0.10 |
| RAPTOR | 52.30 | 25.00 | 28.10 | 10.50 |
| HippoRAG | 58.67 | 45.27 | 38.33 | 27.55 |
| QAFD-RAG | 73.42 | 58.10 | 47.99 | 33.50 |
텍스트-SQL 변환(Spider 2.0) 벤치마크에서도 QAFD-RAG + SQL-Agent 조합이 SQLite 26.70%, Snowflake 23.70%의 실행 정확도를 달성해 기존 방법들을 큰 폭으로 앞섰습니다. 데이터베이스 스키마를 지식 그래프로 변환해 관련 테이블과 컬럼을 정확히 찾아낼 수 있었기 때문입니다.
6. 의의와 확장 가능성
QAFD-RAG의 핵심 차별점은 성능 수치 자체보다 그것을 달성한 방식에 있습니다. 별도 학습 없이 기존 시스템에 모듈 방식으로 붙이면서, 동시에 이론적 보장까지 제공합니다. 왜 잘 되는지 설명할 수 있는 시스템은 실제 서비스 환경에서 더 신뢰받을 수 있고, 장애 대응이나 감사 상황에서도 근거를 제시할 수 있습니다. 기존 Graph 기반 RAG들이 오랫동안 함께 해결하지 못했던 두 가지 조건 — 쿼리 인식 탐색과 이론적 보장 — 을 동시에 충족했다는 점이 이 연구를 주목하게 만드는 이유입니다.
이 연구가 더 의미 있는 것은 지금 시점의 흐름과 맞닿아 있기 때문입니다. 2025년부터 RAG 분야의 경쟁 축이 모델 자체의 성능에서 retrieval 인프라의 품질로 이동하고 있습니다. 컨텍스트 윈도우 확장이나 파인 튜닝만으로는 복잡한 관계형 데이터를 다루는 데 한계가 있다는 것이 실험적으로 확인되면서, 어떤 정보를 어떻게 가져오는지가 다시 핵심 문제로 부상했습니다. 특히 기업 환경에서는 문서, 시스템 로그, 장애 티켓, 정책 문서처럼 서로 연결된 관계 데이터가 대부분입니다. 여기서 QAFD-RAG처럼 관계 구조를 질문 맥락에 맞게 탐색하는 방식은 실질적인 경쟁력이 됩니다.
앞으로의 방향도 자연스럽게 이어집니다. 현재 주목받고 있는 Agentic RAG는 AI 에이전트가 검색 전략을 스스로 결정하고 여러 단계에 걸쳐 정보를 수집하는 방식인데, QAFD-RAG의 flow diffusion은 이 흐름에서 핵심 부품으로 활용될 수 있습니다. 에이전트가 복잡한 질문을 서브쿼리로 분해하면, QAFD가 각각에 대해 의미적으로 정확한 서브그래프를 독립적으로 탐색하고 결과를 합산하는 방식으로 자연스럽게 연결됩니다. 흐름 기반 탐색은 어떤 경로를 통해 어느 노드가 선택되었는지 추적할 수 있어, 의료나 법률처럼 답변 근거가 명확해야 하는 도메인으로의 확장도 열려 있습니다. 질문의 의미가 그래프 탐색의 나침반이 되는 방향으로, QAFD-RAG가 그 가능성을 먼저 열었습니다.
핵심 내용 요약
기존 Graph 기반 RAG는 그래프 구조 중심의 탐색 방식으로 인해 질문 의미를 충분히 반영하지 못하고, 탐색 결과에 대한 이론적 보장이 부족하다는 한계를 가집니다. 삼성SDS Research America가 ICLR 2026에 발표한 QAFD-RAG는 쿼리마다 간선 가중치를 동적으로 재조정하는 흐름 확산(flow diffusion) 기법으로, 쿼리 비인식 탐색(query-agnostic)과 이론적 보장 부재라는 두 핵심 문제를 동시에 해결합니다. 추가 학습 없이 기존 RAG 시스템에 모듈로 통합 가능하며, 멀티홉 추론, 장문서 요약, Text-to-SQL 등 다양한 벤치마크에서 기존 방법들을 일관되게 능가합니다.
FAQ
-
QAFD-RAG(Query-Aware Flow Diffusion RAG)는 추가 학습이나 파인 튜닝 없이(training-free), 쿼리 의미에 따라 지식 그래프 간선 가중치를 동적으로 조정해 관련 서브그래프만 추출하는 Graph 기반 RAG 프레임워크입니다. Samsung SDS Research America가 개발했으며 ICLR 2026에 발표되었습니다. RAG 기본 개념과 Graph 기반 RAG가 필요한 이유는 아래 Q2를 참고하세요.
-
RAG(검색증강생성, Retrieval-Augmented Generation)는 LLM이 외부 지식을 검색해 답변 품질을 높이는 기법입니다. 그러나 일반 RAG는 문서 간 관계를 충분히 반영하기 어려워, 복잡한 질문에서 핵심 정보가 희석되는 문제가 있습니다. Graph 기반 RAG는 문서와 개체의 관계를 지식 그래프로 표현해 이러한 문제를 보완합니다.
-
GraphRAG와 LightRAG는 그래프 구조나 연결 관계를 중심으로 탐색이 이루어지기 때문에, 질문이 바뀌어도 탐색 방식이 크게 달라지지 않는(query-agnostic) 한계가 있습니다. QAFD-RAG는 쿼리가 바뀔 때마다 간선 가중치를 새로 계산해, 같은 그래프에서도 질문에 따라 전혀 다른 서브그래프를 탐색합니다.
-
별도의 모델 파인 튜닝이나 추가 학습 데이터가 필요하지 않습니다. 기존 LLM과 지식 그래프만으로 새로운 도메인에도 바로 적용할 수 있습니다.
-
관계형 데이터베이스(Text-to-SQL), 의학 지식 그래프, 법률 문서 네트워크, 사내 시스템 의존성 관리처럼 개체 간 관계가 복잡하고 멀티홉 추론이 필요한 도메인에서 특히 강점을 발휘합니다.
-
모듈 방식으로 설계되어 있어 기존 시스템에 쉽게 통합할 수 있습니다. 예를 들어 기존 GraphRAG 기반 RAG의 탐색 방식을 QAFD로 교체하거나, retrieval 단계만 선택적으로 개선하는 방식으로 적용할 수 있습니다.