[Technology Toolkit]
The First Step to Smart Textual Analysis, KoreALBERT
![<small>[Technology Toolkit]</small><br>The First Step to Smart Textual Analysis, KoreALBERT thumbanil image](https://image.samsungsds.com/us/blog/__icsFiles/afieldfile/2021/03/24/koreaalbert_thumbnail.jpg?queryString=20260602010004)

Technology Toolkit 2021 is a technical white paper describing core technologies that
are being researched and developed by Samsung SDS R&D Center. We would like to introduce in this paper a total of
seven technologies concerning AI, Blockchain, Cloud, and Security with details on their technical definition, key
features, differentiating points, and use cases to give our readers some insights into our work.
Text Analysis using Korean Pre-trained BERT Model
1. Introduction to Technology
Technology Trends and Background
① Limitations of Statistical Language Models in Linguistic Representation
Language is the process of communicating intentions or meanings. Sentences have certain meanings, and humans
communicate through understanding and deciphering words in the sentence. Then how are we supposed to reflect this
process in deep learning models? Deep learning models are expressed in real number value computation, so it involves
the process of converting words into real number values. Previous deep learning models simply substitute words into
pre-defined real number values. But there is a downside to this approach since such model is unable to handle
linguistic ambiguities like homonyms properly. Take phrases like “Bank Account” and “River
Bank” for example. Although the two phrases contain the same word, they have very different meaning. Previously
available deep learning models could not convey this difference because they use the same real number value for the
word “bank” as shown in [Figure 1]. Therefore, it was necessary to develop a new model that can capture
contextual information.

- Bank
- Bank Account
- Different Meaning
- River Bank
- Bank: Converts words into real number values
- Deep Learning
- Bank Account
- 0.2 0.8 1.2 0.6
- Representing the same word
- 0.2 0.8 1.2 0.6
- River Bank
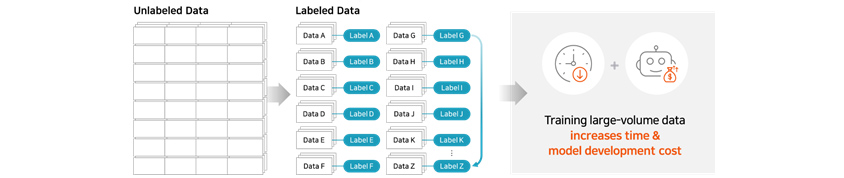
② Limitations in building datasets for DL language model training
Training a deep learning language model requires a massive amount of data although varied according to the size of the
model. Building a dataset for supervised learning in particular requires answers (label) which often entails
significant time and costs. So creating datasets for large-sized models with tens of millions of sentences and
associated labels becomes an extremely challenging task by itself.
- Data A: Label A
- Data B: Label B
- Data C: Label C
- Data D: Label D
- Data E: Label E
- Data F: Label F
- Data G: Label G
- Data H: Label H
- Data I: Label I
- Data J: Label J
- Data K: Label K
- Data Z: Label Z
③ Introduction to pre-trained models
First introduced by Google in 2018, BERT (Bidirectional Encoder Representation from Transformers) is a deep learning
language model pre-trained with large amount of English datasets, and it is developed to tackle the limitations of
statistical language models mentioned above. BERT presented state-of-the-art (SOTA) results in a wide variety of NLP
benchmarks such as General Language Understanding Evaluation (GLUE) and machine learning comprehension (SQuAD v1.1,
SQuAD v2.0), outperforming previous statistical language models that were available at that time. Various other
similar language models were presented afterwards. Since most of them work in a similar way to BERT, let’s take
a look at BERT more closely and find out how the above-mentioned drawbacks were addressed.
④ Contextual representations
BERT uses two training strategies to learn the context of a word. Learning contextual relations between words or
sentences allows the model to provide more accurate representations of a language.
• Masked Language Model (MLM)
Masked Language Modeling (MLM) is one way to train a language model. Here, certain words of a sentence are masked out
at random, and the model learns the language by guessing the masked words. The model is trained to predict and find
correct answers through contexts surrounding the masked words. This allows the model to naturally catch different
meanings of a word based on its relationship with surrounding words.

- AI will mankind
- 1) Save 2) Dominate 3) Love N)…
• Next Sentence Prediction (NSP)
In the Next Sentence Prediction (NSP) model, the model is given a pair of sentences as input and learns to predict
whether one sentence is the subsequent of the other. This way, the model can figure out the context of sentences.

- 1. This article is boring. It puts me to sleep.
- 2. This article is boring. I am suddenly awaken.
⑤ Overcoming drawbacks of self-supervised learning
There are a wide variety of text analysis tasks (or features) that are based on deep learning language models. These
tasks can be used to predict sentiment of a sentence, provide answers to a question, or find similar sentences.
Acquiring data and training models for each one of these tasks separately would require a tremendous amount of data.
But although each task may be different from one another, they all still use the same language and therefore need the
same language understanding. BERT models are pre-trained through various tasks like MLM or NSP and learn the basic
language skills. For the MLM task, texts for datasets are taken from Wikipedia, with some percentage of the sentences
masked out. In the NSP tasks, training datasets are generated by combining a pair of connected sentences with another
pair of sentences from other documents. That way, the model can learn a language representation by itself without
having humans provide labeled data. An unsupervised learning method where a model learns autonomously with unlabeled
data input is called “self-supervised learning,” and a language model built this way is referred as
“pre-trained language model.”
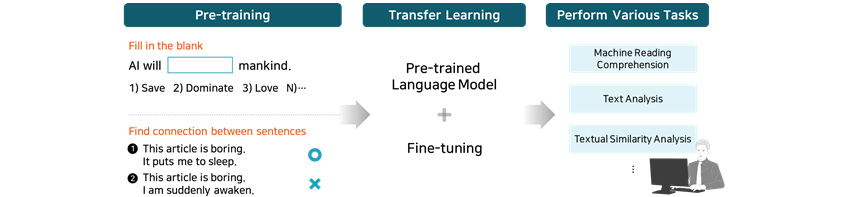
⑥ Fine-tuning based on transfer learning
Transfer learning is a machine learning technique where a pre-trained model on one task is re-trained for a new
purpose-specific task. Fine-tuning refers to this specific stage of the learning process in which a pre-trained model
is refined for specific task. The fine-tuning process is necessary because a pre-trained BERT model itself is not
trained yet to perform a specific task. Let’s find out what kind of tasks can be performed with a fine-tuned
model in the use cases below.
- Fill in the blank
- AI will mankind.
- 1) Save 2) Dominate 3) Love N)…
- Find connection between sentences
- 1. This article is boring. It puts me to sleep.
- 2. This article is boring. I am suddenly awaken.
- Pre-trained Language Model + Fine-tuning
- Machine Reading Comprehension
- Text Analysis
- Textual Similarity Analysis
2. Key Features
Korean Pre-trained Models
There are many publicly available pre-trained BERT models for English but it is difficult to utilize them for Korean
due to linguistic differences. Samsung SDS R&D Center gathered a massive volume of Korean text data and created
pre-trained models specifically built for Korean language.
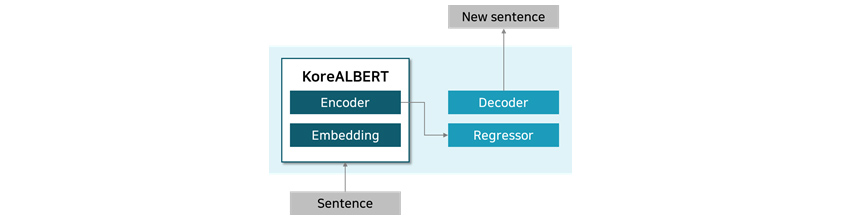
① KoreALBERT
The first model is KoreALBERT (Korea + ALBERT) [Figure 6], which learns Korean using ALBERT (A Lite BERT)
architecture, a lite version of BERT. To increase the usability of the model in various business settings, datasets
were made of formal Korean texts taken from a wide variety of sources including Wikipedia, news and book outlines. In
addition, we applied a new light-weight architecture and patented training methodology to obtain a competitive edge
over other previously available Korean language models (3. Differentiating Points).
② KoELECTRA
Introduced after BERT, ELECTRA is a language model created to address the inefficiency of BERT model which uses only
15% of masked tokens for training. In contrast with BERT, ELECTRA utilizes the rest 85% of the input tokens as well,
improving the training speed and performance compared to BERT. KoreELECTRA is a model trained on Korean texts with
ELECTRA model architecture. Although heavier, KoreELECTRA achieves better performance compared to KoreALBERT.

- Pre-trained model w/ Korean data
- Korea + ALBERT
- Applied a light-weight architecture ALBERT(A Lite BERT)
- Reduced model size(1/10 of BERT)
- Training methodology specialized for Korean language (Patented)
- Korean data model
- Korea + ELECTRA
- Applied ELECTRA architecture to address the inefficiency of BERT model
- Heavier in size but enhanced performance compared to KoreALBERT
Using Pre-trained Model for a Wide Variety of Tasks
A pre-training model cannot perform a specific task in itself, but it can be used a wide range of tasks after
fine-tuning. NLP (Natural Language Processing) can be largely divided into two groups: NLU (Natural Language
Understanding) and NLG (Natural Language Generation). NLU helps the comprehension of the text inputs and contexts, and
NLG is responsible for generating sentences based on the understanding of the context. So if you want to build a
chatbot, you need both NLU for understanding user’s intent and NLG for generating responses.
① NLU
Pre-training model is used for almost all of NLU tasks. Various NLU tasks including machine reading comprehension,
text classification and textual similarity analysis can be performed after fine tuning of a pre-trained model.
② NLG
NLG model is mounted with a decoder module for generating sentences, which doubles the cost of pre-training compared
to NLU models. But some of the recent studies have suggested ways to reduce NLG model pre-training costs using NLU
models.

- Ability to comprehend language
- Listening, reading
- Used in tasks that require language comprehension such as text classification, textual similarity analysis, machine reading comprehension, etc.
- Sentence generating tasks
- Speaking, writing
- Used for text summarization, paraphrasing, chatbot, etc.
- Sentence
- KoreALBERT: Encoder, Embedding
- Decoder, Regressor
- New sentence
3. Differentiating Points
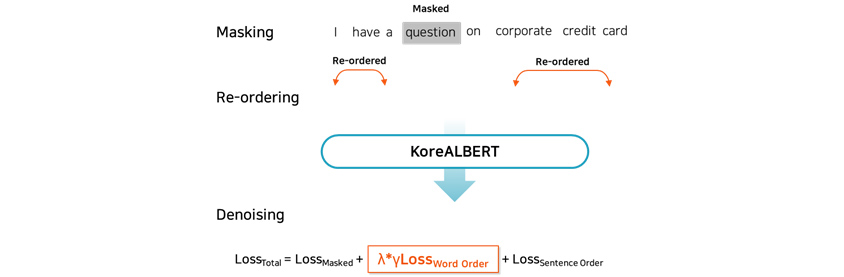
Improved Pre-training Methods
Samsung SDS adopted new training techniques to reduce model size while improving the accuracy of pre-trained models
that serve as the core engine for textual analysis. A new step was added [Figure 9] to the training process for
enhanced efficiency. In this stage, the model learns to predict the sequence of randomly shuffled words, which not
only significantly reduces parameter size (1/10 size of BERT parameter) but also increases the model accuracy. Samsung
SDS team patented this training technique and presented the result of the study at one of the top-tier global
conferences, ICPR 2020. The upgraded KoreALBERT model has a use case for ERP-related VoC analysis system which is
being operated in CPU-based server (4. Use Cases).
- I have a question(masked) on corporate credit card
- Re-ordered / Re-ordered
- KoreALBERT
- Loss(Total) = Loss(Masked) + Loss(Word Order) + Loss(Sentence Order)
In addition, Samsung SDS developed multi-lingual BERT model that can be used for various languages by employing
transfer learning and CNN (convolutional neural network) architecture. The model proved its superior performance
ranking top in the official leaderboard of a Korean MRC dataset, KorQuAD v1.0 (Korean Question Answering Dataset) in
August 2020.
Comparative Analysis of Pre-trained Models
[Figure 10] below displays the size and performance of different pre-trained models applicable in Korean language
comprehension tasks. With an improved pre-training method, KoreALBERT showed enhanced average scores at various Korean
language understanding tasks* with a much smaller parameter size, 7-20% level compared to other models. (*Evaluated
tasks: machine reading comprehension, semantic textual analysis, named entity recognition, intent classification,
question classification, sentiment analysis)
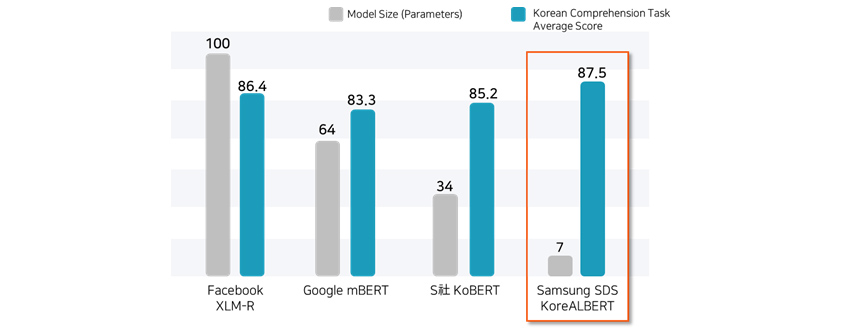
- Model Size (Parameters): 100
- Korean Comprehension Task Average Score: 86.4
- Model Size (Parameters): 64
- Korean Comprehension Task Average Score: 83.3
- Model Size (Parameters): 34
- Korean Comprehension Task Average Score: 85.2
- Model Size (Parameters): 7
- Korean Comprehension Task Average Score: 87.5
4. Use Cases
Case 1: Machine Reading Comprehension (MRC)
Machine Reading Comprehension task can be used for understanding text passages and answering relevant questions. As
displayed in [Figure 11], a pre-trained model was used as a baseline model, and enhanced CNN was added to augment the
MRC model’s performance. Our MRC model showed a strong performance in KorQaAD 1.0.
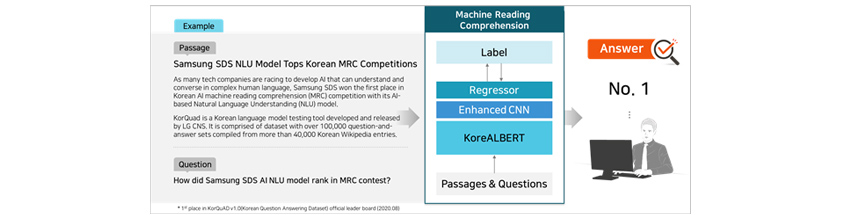
- Label, Regressor, Enhanced CNN, KoreALBERT, Passages & Questions
- Samsung SDS NLU Model Tops Korean MRC Competitions
- As many tech companies are racing to develop AI that can understand and converse in complex human language, Samsung SDS won the first place in Korean AI machine reading comprehension (MRC) competition with its AI-based Natural Language Understanding (NLU) model.
- KorQuad is a Korean language model testing tool developed and released by LG CNS. It is comprised of dataset with over 100,000 question-and-answer sets compiled from more than 40,000 Korean Wikipedia entries.
- How did Samsung SDS AI NLU model rank in MRC contest?
- No. 1
Case 2: Text Classification
Text classification task is used for categorizing texts into organized groups. One area where it can be used is
sentiment classification for determining whether the sentiment of given text input is positive or negative. Often used
for analyzing user comments or feedback on products, text classification task can be also used for intent
classification, as shown in [Figure 12]. Using the text classification task, any kind of text can be efficiently
organized and categorized into groups so it is one of the most frequently used tasks in business settings. Performance
of a text classification model may vary depending on the pre-trained model (KoreALBERT).
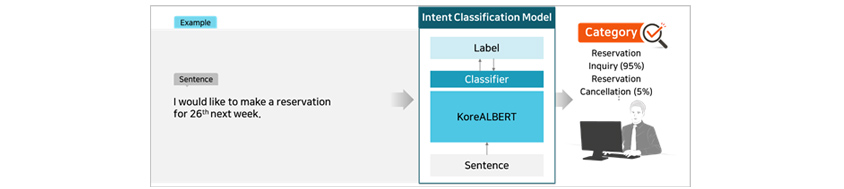
- Label, Claasfier, KoreALBERT, Sentence
- I would like to make a reservation for 26th next week.
- Reservation Inquiry (95%), Reservation Cancellation (5%)
Case 3: Semantic Textual Similarity (STS)
Semantic Textual Similarity deals with determining how similar two sentences are in terms of meaning or context. STS
can be useful in implementing a search feature for finding similar sentences to a query sentence and a saved sentence.
Samsung SDS’s STS task takes sentiment and context into consideration, therefore boasts a powerful performance
and quality compared to other previously available keyword search features [Figure 13 – Upper].
As the number of query sentences increases, so does the processing time. To address this issue, Samsung SDS suggested
a new architecture that utilizes Siamese Neural Network and Convolutional Neural Network (CNN) [Figure 13 –
Lower]. The result of this study was patented and presented at a renowned international symposium on artificial
intelligence, ICPR 2020.
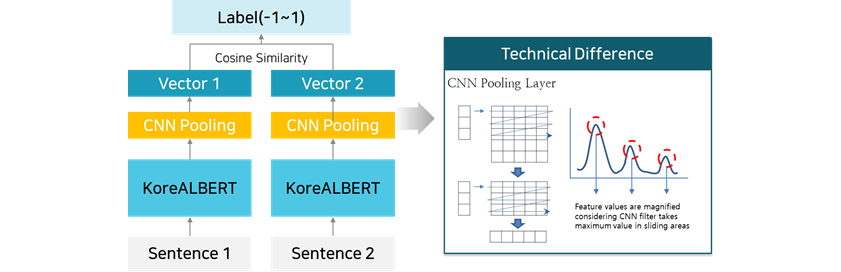
- CNN Pooling Layer
- Feature values are magnified considering CNN filter takes maximum value in sliding areas.
- Vector 1, CNN Pooling, KoreALBERT, Sentence 1
- Vector 2, CNN Pooling, KoreALBERT, Sentence 2
Case 4: Text Summarization
As shown in [Figure 14], text summarization model is divided into two types: extractive summarization model that
generates a summary by extracting key sentences from the document passage, and abstractive summarization model which
comprehends the details of a document and generates sentences with context. Extractive summarization model can be
built based on NLU, and abstractive summarization model on NLG engine. Textual summarization feature can save a lot of
time and costs for analytics experts who need to obtain insights from a massive volume of documents.
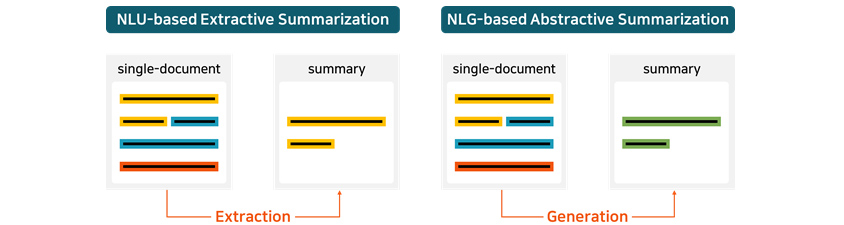
- single-document, Extraction, summary
- single-document, Generation, summary
5. Business Cases
Below is one of the use cases of language models for VoC (Voice of Customer) management.
Company A’s ERP system related VoC management process.
(1)System user submits ERP system inquiries.
(2)Service desk assigns the case to the person in charge.
(3)Relevant staff in charge verifies the inquiry type, and re-assigns the case if necessary.
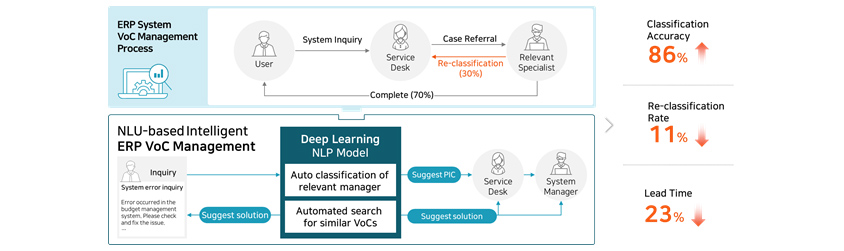
- User: System Inquiry
- Service Desk: Case Referral
- Relevant Specialist: Re-classification(30%), Complete(70%)
- Inquiry(System error inquiry): Error occurred in the budget management system. Please check and fix the issue.
- Suggest solution
- Deep Learning NLP Model: Auto classification of relevant manager, Automated search for similar VoCs
- Suggest PIC
- Suggest solution
- Service Desk
- System Manager
- Classification Accuracy 86%
- Re-classification Rate 11%
- Lead Time 23%
In the previous VoC management system, re-classification rate was as high as 30% due to misclassification, which also
delayed overall lead time. Samsung SDS R&D center was able to address this issue by applying two DL-based models
to the system: automatic relevant manager classification model and automatic similar VoC search model. Adoption of the
two new models increased the classification accuracy to 86%, reduced re-classification rate down to 11% and lead time
to 23%.
6. Closing
The number of business cases of pre-trained language model is growing with the extended application of the models in
wider area. Samsung SDS will continue to introduce more powerful and effective pre-trained models that could
potentially be applied in various tasks (4. Use Cases), while creating values for customer through insights gained
from various textual information and analysis.

# References
[1] KoreALBERT: Pretraining a Lite
BERT for Korean Language Understanding
[2] https://korquad.github.io/category/1.0_KOR.html
[3] Evaluation of BERT and ALBERT
Sentence Embedding Performance on Downstream NLP Tasks
[4] Analyzing Zero-shot
Cross-lingual Transfer in Supervised NLP Tasks
▶ The content is proected by law and the copyright belongs to the author.
▶ The content is prohibited to copy or quote without the author's permission.
- The First Step to Smart Textual Analysis, KoreALBERT
- Smart QA Model That Understands Even Complex Tables
- I Will Give You Data, Label It~ Auto Labeling!
- The Connecting Link for Everything in the World, It’s in the Knowledge Graph
- No More Short of GPU!
- In the Age of When Customer Data Must Be Treated as a King, PET Will Take on the Responsibility
- It is Important to Prevent Security Risks from Development Phase! Trust CAFA+ to Do the Job

Judong Kim, AI Core Lab at Samsung SDS R&D Center
Judong Kim is a researcher at Samsung SDS AI Core Lab, responsible for deep learning language models and model performance improvement.
Hyunjae Lee, AI Core Lab at Samsung SDS R&D Center
Hyunjae Lee is a researcher at Samsung SDS AI Core Lab. His main research area is NLP technology with a particular focus on Korean language models.
Hyunjin Choi, AI Core Lab at Samsung SDS R&D Center
Hyunjin Choi joined Samsung SDS as a software engineer although she studied business administration in college. After web/mobile and Windows programming, she is currently working on computational linguistics at AI Core Lab.
If you have any inquiries, comments, or ideas for improvement concerning technologies introduced in Technology Toolkit 2021, please contact us at techtoolkit@samsung.com.
- Brity Copilot, Now Evolved into Your Personal Agent! (Featuring the case of CMC Global in Vietnam)
-
Over the Coming Wave
- Part 2 Strategies for AI Risk Management -
Over the Coming Wave
- Part 1 AI Risk Perception and Assessment Framework - The Rise of Generative Enterprises: Reshaping the Future of Business With Generative Technologies
- ESG Framework for Sustainable AI Business
- B2B Companies Transforming Into 'Generative AI-Centered'