A case of building scalable web applications using container technologies in a cloud environment
- 2022-03-31
- 작성자 Lee Gitae



In the IT industry, building web application systems in a cloud environment has been a major topic of discussion. What stands out is the need to enhance scalability through the adoption of container technologies. That is because Kubernetes, the de facto standard for container orchestration, is used for easier scaling in and scaling out. Let’s take a closer look at some considerations when building scalable web applications using container technologies.
Things to consider when adopting a container technology
When building a scalable web application and adopting a container technology, there are several factors to consider, unlike generally used monolithic environments.
[Wait!] What is the scalable web application?
A scalable web application refers to a web application designed to handle an increase in users or traffic while maintaining stability through horizontal scaling. In other words, it is designed to achieve high scalability, so you can scale up services by adding or building more servers. This makes it possible to ensure a high degree of availability and stability while minimizing the degradation of websites or services, even with a growing user base.
First, a container image build environment/ a container image-building environment
A container-based web application system deploys containers through image building whenever source code is modified. This is mainly due to setting up a pipeline that includes an image registry and container image building/deployment in a CI/CD environment primarily designed for DevOps.
Second, using SW that supports Linux environments and containers
Most container environments are based on Linux. Windows containers may be exceptionally configurable, but typically, converting a Windows-based system into a container requires a prior transition to a Linux environment. The process also involves switching to SW that supports containers. However, in cases where using SW without container support is inevitable, a VM environment may be more suitable.
Third, scalable applications
Applications can be flexibly scaled in or out only if the services are not impacted by scaling in, scaling out, creating/deleting additional containers, or the automatic allocation and release of workloads. Therefore, it is recommended to build stateless Web/WAS servers and stateful data configurations with persistent volumes.
[Wait!] What is the difference between stateful and stateless?
A stateful system maintains and manages status information. In other words, it is a system that operates based on the saved information of certain status information. On the contrary, a stateless system does not maintain status information and perform tasks without the saved status information.
![[Figure] Scalable web application configuration - stateless Web/WAS servers with container-based scaling in/out and stateful persistent volume for data storage](https://image.samsungsds.com/en/techreport/img_techreport_repo1_2.png?queryString=20260616090116)
A case of removing web servers
Generally, configuring a container-based web application in a Kubernetes environment requires inbound Http/Https traffic called an "Ingress Controller."
[Wait!] What is an Ingress Controller?
An ingress controller in Kubernetes manages ingress resources and sets paths for external access to applications. This enables the management of application routing, load balancing, and SSL certificates.
An ingress controller itself is a Pod served in Kubernetes worker nodes as a container. To ensure stable large-scale processing, it is recommended to have redundant proxy nodes that handle ingress controllers in order to allow load balancing through a load balancer (LB). The ingress controller will take over the role of a proxy, which was previously performed on a web server. This means it can directly call a WAS server without a web server. Such configuration is a common setup for web applications. It is expected to save resources and web server costs when there are redundant web servers configured for high availability (HA).
It shows the same level of TPS in performance tests where it is actually applied, so it is often applied to the web application configuration. Moving the static content under processing to a WAS server can be considered as well. Furthermore, when estimating the WAS server capacity, moving the static content to that server should also be considered.
[Wait!] What are transactions per second (TPS)?
Transactions per second (TPS) represent the number of transactions a system can complete in one second. The TPS signifies the system’s maximum throughput and is commonly used to measure the capacity of databases or web servers. A high TPS indicates excellent performance and the ability to effectively handle heavy traffic.
A case of maintaining web servers
A web application is a communication system that provides features, such as posts, comments, and discussions. If the web application contains large and frequently changing static content like videos, streaming, large files, or downloads, maintaining web servers becomes important. Company A configures its system to create two different ingress objects to call both the static content of the web server and the dynamic content of the WAS server. Such architecture systems can handle as much as 4,000 to 5,000 TPS. That is the result of routing web services and WAS services by configuring two different ingress objects with separated paths and session cookie names. As such, when static content is used in high volumes, most of the services are processed on web servers. Relatively, WAS server with low traffic may lead to savings on software licenses.
When configuring a web server in a Kubernetes environment, opening the NodePort and directly accessing the web server is one of the options to consider apart from configuration through an ingress controller. However, in the case of NodePort configuration, you need to consider port forwarding, mapping the ports in the 30000 range to ports 80, 8080, etc.
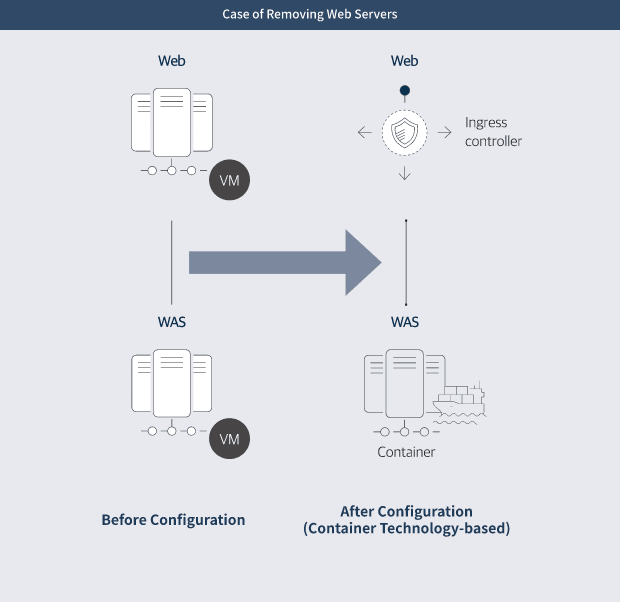
- Before configuration: WEB (vm) - WAS (vm)
- After configuration (based on container technologies): WEB (ingress controller) - WAS (container)
- Before configuration: Web(VM) - WAS(VM)
- After configuration (based on container technologies): WEB (ingress controller) - two WASes (container)
Go to Kubernetes Apps
https://www.samsungsds.com/en/container-k8sapps/k8sapps.html
A case of configuring persistent data
There are three main configurations for persistent data in the container-based web application system.
[Wait!] What is the persistent data?
Persistent data refers to any data that is stored permanently. In other words, the data remains intact after it has been created, even if the system is turned off or rebooted. Contrarily, volatile data, which is used temporarily, is deleted once the system is turned off or rebooted. One example of persistent data is data in a database, which ensures data persistence, security, and reliable management.

First, log files
Log files can be designed to be accessed by multiple container deployments that can be scaled in or out by configuring them at a consistent volume for RWX. Meanwhile, it is recommended to set separate paths by Pod name for log files of WAS container base images because logs for multiple containers are integrated into one file if their paths are the same. Furthermore, log files can be saved in object storage, but this requires another configuration to save the files there. Another option is to configure to integrate and save the logs in solutions, such as Splunk, and not to have WAS containers manage any log files.
Second, file data, such as texts, images, and videos
In cloud environments, it is recommended to store this file data in object storage.
Third, database data
In Kubernetes environments, stateful resources, such as databases, use StatefulSet. This is because a database performs different roles/functions for each Pod, unlike Web or WAS, which requires a maintained status when recreating Pods. Note that deployment guarantees the least numbers for defined replicas and may temporarily create more than defined numbers.
Kubernetes with the auto-healing feature offers great availability, even if for a single standalone database. Therefore, it is simple, yet effective to configure databases as standalone as long as availability is secured. Of course, an operator can be used to scale in/out container databases with an HA cluster configuration, but this is only useful for the convenience of database maintenance and management. That is because, in the case of auto scale-in/out failover, there are a few restrictions for container-based databases, including data integrity and consistency.
[Wait!] What is the high availability cluster (HA cluster)?
The high availability cluster (HA cluster) refers to a system configured with multiple computers as a cluster to work as a single system. It allows other servers to run when one of the servers fails, ensuring system availability. HA clusters adopt technologies, such as load balancing, data backup, and fault detection and recovery to offer reliable services. For example, a web server cluster might utilize HA clusters to disperse traffic and respond to faults.
Despite all the considerations, using the powerful tool, Kubernetes, is becoming a trend in MSA-based web application development using container technologies. Samsung Cloud Platform's Kubernetes Apps, which allow you to utilize Tomcat, Nginx, Web, and Was Server Software as containers, provide optimized development environments based on a multitude experiences of onsite operations. Check out the Kubernetes service, which enables effortless management of multiple containers in Samsung SDS.
Let’s meet Cloud Container at Samsung Cloud Platform
-
Container
Standard Kubernetes cluster creation and container deployment
- Professional, Lee Gitae / Samsung SDS
- Lee has experience and expertise in PaaS platforms based on container or Kubernetes, architecture design, build, and application of hybrid and multicloud platform technologies for Samsung affiliates and other companies in distribution, manufacturing, and public sectors.