loading...

생성형 AI 기술의 발전에 따라 많은 기업에서 자사 서비스에 생성형 AI 기술을 적용하려는 움직임이 활발하게 일어나고 있습니다. 삼성SDS 역시 AI 기술이 적용된 신규 서비스 발굴과 기존 서비스와의 통합을 위해 다양한 시도를 하고 있습니다. 그 중 삼성SDS Gen AI 해커톤에서 소개된 고객 기술지원 업무에서 활용할 수 있는 AI 기반 서비스와 기술 요소에 대해 소개합니다.
클러스터 진단 도구, SKE-GPT 소개
지난 1년간 SCP(Samsung Cloud Platform)의 컨테이너 상품 관련 기술지원 내역을 분석한 결과, 가이드를 통해 사용자 스스로 문제를 해결할 수 있는 케이스가 약 68%를 차지하였습니다. 자가 조치가 가능한 문의가 이렇게 많이 발생한 이유는 무엇일까요? 그 해답은 컨테이너 상품이 동작하는 쿠버네티스 환경의 특수성에서 찾을 수 있었습니다.
쿠버네티스는 리눅스 재단에서 관리하는 오픈소스 기반의 컨테이너 오케스트레이션 플랫폼(Container Orchestration Platform)입니다. AWS, Google 등 CSP(Cloud Service Provider)들은 자사 클라우드 환경에 맞게 재구성한 쿠버네티스 상품을 제공하고 있으며, SCP에서는 Kubernetes Engine(이하 SKE, SCP Kubernetes Engine)이라는 이름으로 서비스가 제공되고 있습니다.
CSP에서 제공하는 쿠버네티스의 경우 해당 클라우드 플랫폼과 통합된 형태의 기능과 서비스가 제공되어 사용자 편의성을 높일 수 있지만, 통합된 상품의 문제로 쿠버네티스의 애플리케이션이 동작하지 않을 경우 문제의 원인을 찾기가 매우 힘들다는 단점이 있습니다. 이러한 사용자의 pain-point에 착안하여 탄생한 것이 SKE-GPT(Samsung Cloud Platform Kubernetes Engine - GPT)입니다.
SKE-GPT는 SCP의 Kubernetes Engine에서 발생하는 문제를 빠르게 분석하고, 정확한 솔루션을 제공하는 AI 기반의 클러스터 진단 도구입니다. 클러스터의 상태를 점검하는 진단 영역과 발견된 문제점에 대한 솔루션을 제공하는 분석 영역의 두 가지 메인 컴포넌트로 구성되어 있습니다. 진단 영역에서는 사전 정의된 룰세트 기반으로 클러스터 내부의 워크로드 상태에 대해 점검하며, 필요시 클러스터와 연계된 SCP 외부 상품에 대한 상태 진단을 수행합니다. 진단 영역에서 문제가 발견되었다면, 분석 영역에서는 AI를 통해 솔루션을 생성합니다.
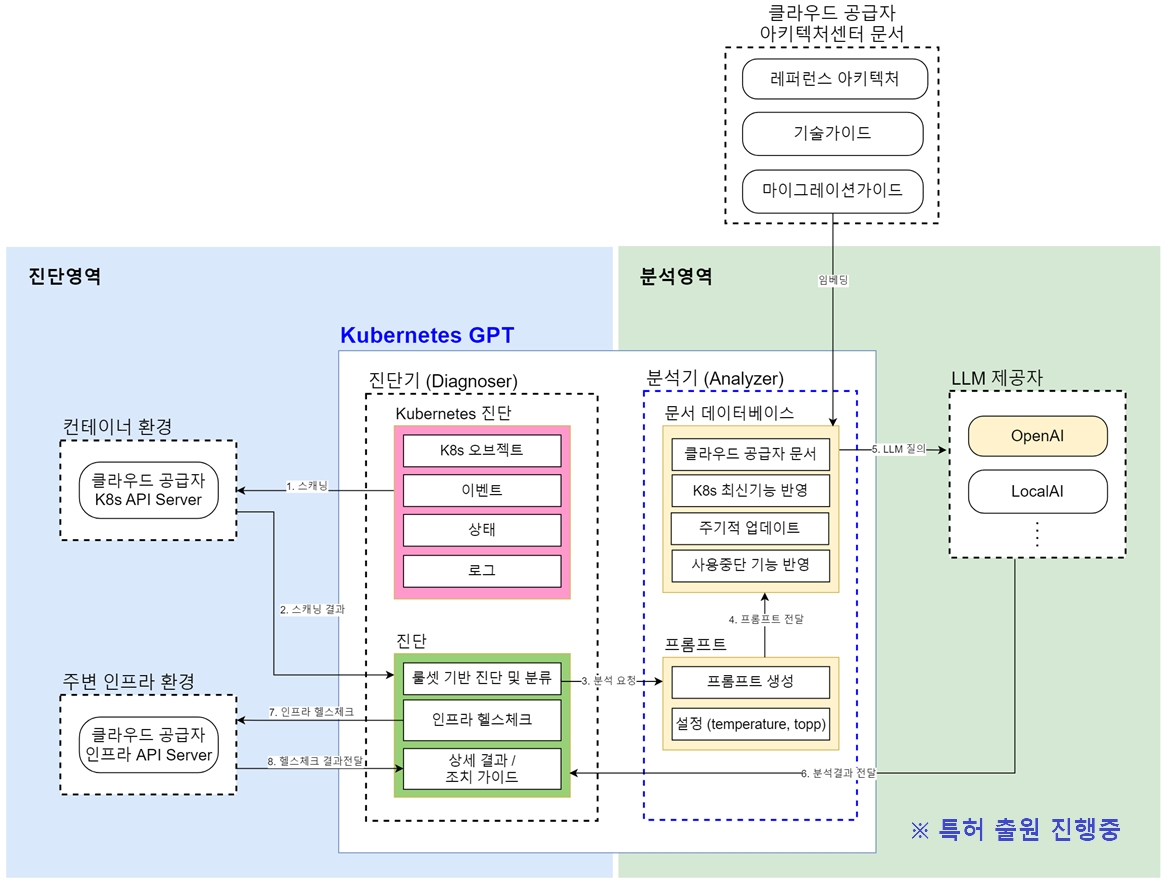 ▲ SKE-GPT 개념 아키텍처(특허 출원 진행 중)
▲ SKE-GPT 개념 아키텍처(특허 출원 진행 중)
Kubernetes GPT
분석영역
분석기 (Analyzer))특허 출원 진행중
SKE-GPT의 주요 특징은 다음과 같습니다.
- 간편한 조작: CLI(Command Line Interface)를 통해 간단한 명령어로 클러스터의 상태를 진단하고, 해결 방법을 제시합니다.
- 강력한 워크로드 스캐닝: 워크로드의 이벤트 로그와 YAML 파일을 분석하여 비정상 상태를 식별하고, 해결 방법을 제안합니다.
- SCP 상품 진단: SKE 서비스와 연계된 SCP 상품(Load Balancer, File Storage, DNS 등)의 상태 분석을 통해 SCP Console 설정에 대한 가이드를 제시합니다.
- 빠르고 정확한 솔루션: 다년간 SKE 운영 및 기술지원을 통해 쌓아온 지식을 기반으로 고객 상황에 딱 맞는 빠르고 정확한 솔루션을 제공합니다.
LLM 모델의 경우 학습되지 않은 데이터나 실시간 정보에 대해서는 제공할 수 없다는 단점이 있습니다. 그렇다면 SKE-GPT는 어떻게 기술지원 활동에 대한 노하우 기반의 솔루션을 제공할 수 있을까요? 이 궁금증을 해소하기 위하여 RAG라는 기술을 이해하여야 합니다.
RAG(Retrieval Augmented Generation) 이해하기
RAG란 LLM(Large Language Model)이 학습한 데이터 외에 외부 데이터를 추가로 제공하여 답변의 정확도를 높이는 기술을 뜻합니다. 이해를 돕기 위해 RAG가 적용된 LLM의 답변과 적용되지 않은 답변을 비교해 보겠습니다. 다음은 “SCP(Samsung Cloud Platform)에 대해 알려줘.”라는 동일 질문에 대한 두 챗봇의 답변입니다. 챗봇은 모두 GPT-3.5-Turbo 모델을 사용하였습니다.
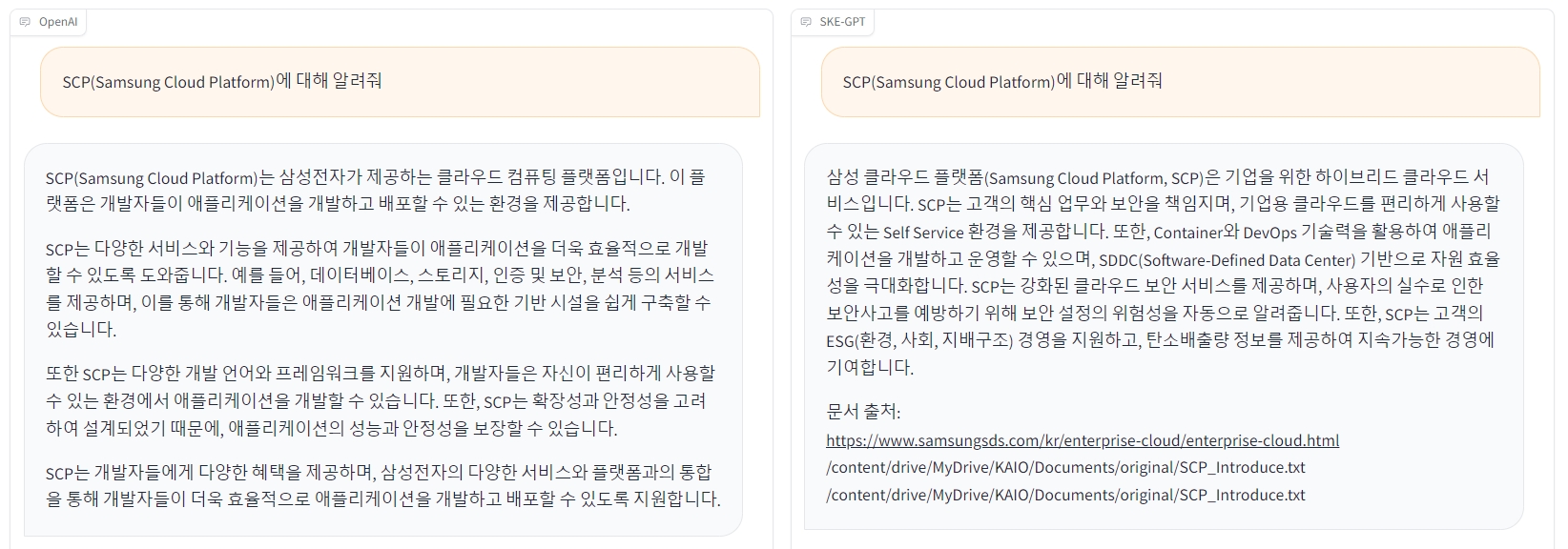 ▲ (좌) OpenAI GPT-3.5-Turbo 답변/(우) RAG 적용한 SKE-GPT 답변
▲ (좌) OpenAI GPT-3.5-Turbo 답변/(우) RAG 적용한 SKE-GPT 답변
답변의 차이가 느껴지시나요? GPT-3.5-Turbo 모델의 경우, 2021년까지의 데이터만 학습하였기 때문에 모델이 학습한 내용으로는 사용자의 의도에 적합한 답변을 하지 못하는 것을 확인할 수 있습니다. 조금 더 자세히 RAG 구현을 위한 기술 요소에 대해 알아보겠습니다.
일반적으로 RAG 기반의 LLM 애플리케이션은 다음과 같이 2개의 메인 컴포넌트로 구성됩니다.
- Indexing
- Retrieval and Generation
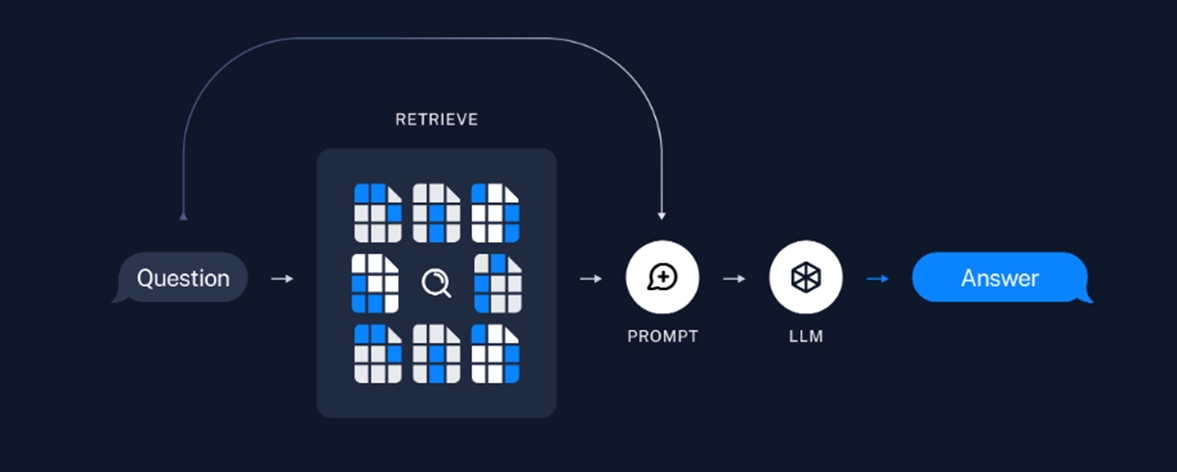
1. Indexing
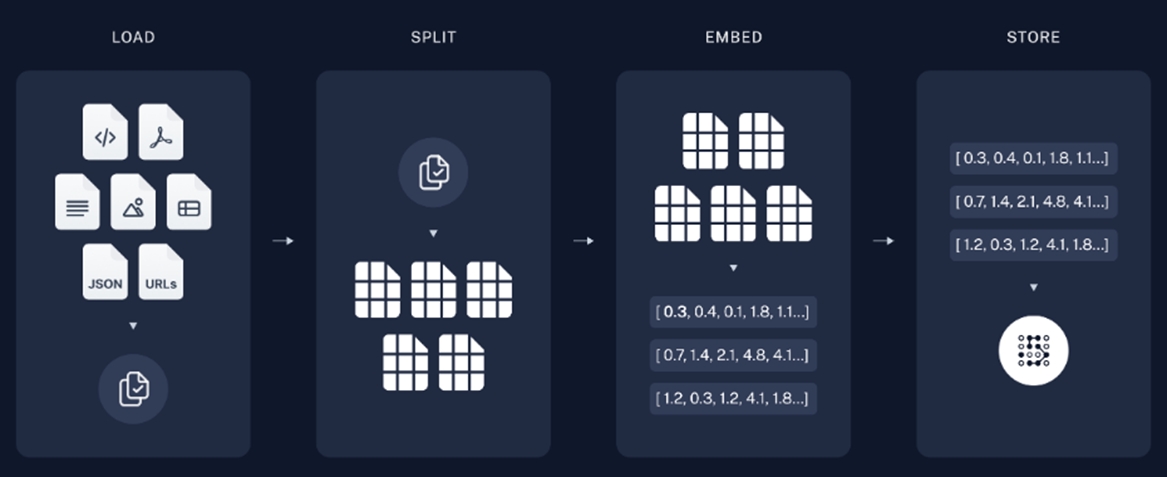 ▲ 출처: https://python.langchain.com/docs/use_cases/question_answering
▲ 출처: https://python.langchain.com/docs/use_cases/question_answering
Indexing은 LLM에게 전달할 데이터를 구성하는 컴포넌트입니다. 다양한 형태의 Document를 적당한 크기로 나눈 후 각 문서의 Embedding Vector 값을 도출하여 Vector DB에 저장합니다. Vector DB는 유사도 검색 기능을 통하여 입력된 문장, 단어와 유사한 값을 도출할 수 있습니다. RAG 기반의 LLM 애플리케이션은 유사도 검색 기능을 통해 챗봇에 입력된 사용자 질문과 유사한 Document를 찾아 LLM에 전달합니다. Indexing 컴포넌트 구현을 위한 세부 모듈에 대해 알아보겠습니다.
※ 이해를 돕기 위하여 LLM Application 개발을 위한 도구인 LangChain Framework의 모듈명을 사용하였습니다.
Document Loaders
LLM에게 전달할 외부 Document를 Application으로 읽어오는 역할을 담당합니다. Document의 종류는 TXT, PDF, Web Page, JSON, Programming Code(Python, Java 등), Image, CSV 등 다양합니다. LangChain에서 제공하는 Document Loaders 모듈을 사용하면, page_content와 metadata로 구성된 Document 구조체 형식으로 데이터를 읽어오는 것을 확인할 수 있습니다. SKE-GPT는 SCP에 대한 RAG 데이터 확보를 위해 삼성SDS 공식 홈페이지의 SCP 소개 페이지와 SCP 아키텍처센터 내 SKE 관련 기술 가이드 문서를 활용하였습니다.
다음은 https://www.samsungsds.com/kr/enterprise-cloud/enterprise-cloud.html 웹 페이지를 WebBaseLoader()를 통해 읽어왔을 때의 예시입니다.
 ▲ https://www.samsungsds.com/kr/enterprise-cloud/enterprise-cloud.html 웹 페이지 화면
▲ https://www.samsungsds.com/kr/enterprise-cloud/enterprise-cloud.html 웹 페이지 화면
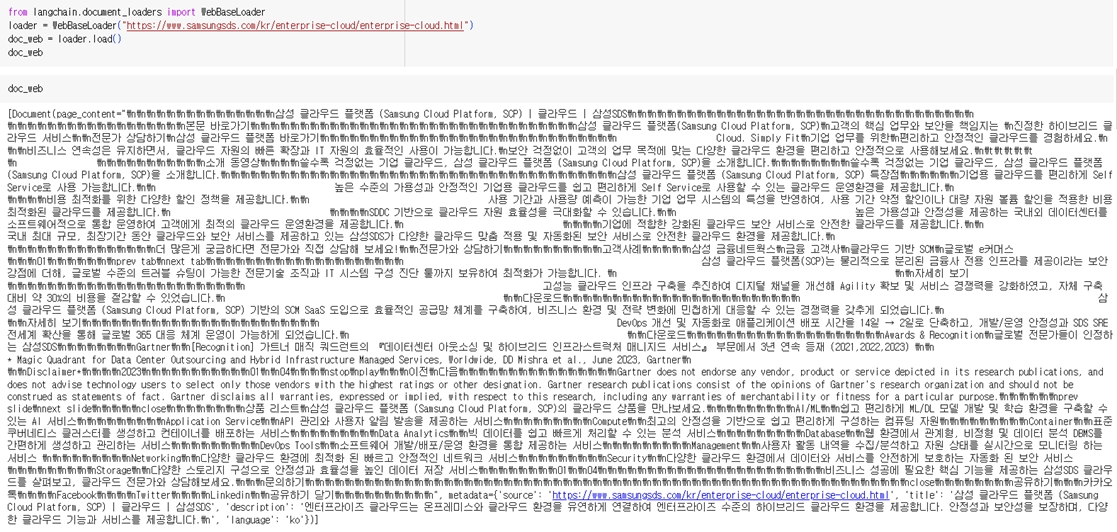 colab에서 WebBaseLoader()로 웹 페이지를 읽어온 화면
colab에서 WebBaseLoader()로 웹 페이지를 읽어온 화면
Text Splitters
LLM은 한 번의 질의에서 사용할 수 있는 Token 수가 제한되어 있습니다. Token은 LLM이 자연어 처리를 위해 문장 및 단어를 조각낸 최소 단위를 뜻하며, 통상적으로 1 Token = 4 Alphabet으로 계산되지만, 이는 LLM 모델마다 다를 수 있습니다. 사용자의 질문에 대한 답을 생성하는 챗봇의 경우 Token 수 제약이 매우 중요합니다. 사용자 질문과 LLM이 생성한 답변의 Token 합이 LLM이 사용할 수 있는 최대 토큰 길이를 넘길 수 없기 때문입니다. RAG를 사용할 경우 질문과 답변의 길이 외에 유사도 검색 결과인 Embedded Document가 전체 Token 수에 포함되므로 문서를 잘 쪼개는 과정이 필요합니다.
Text Splitter 단계에서는 입력받은 Document를 여러 개로 분리하는 역할을 수행하며, Token 수 기준, Document 형식별 특수문자 기준 등 다양한 기준으로 분리할 수 있습니다. 이렇게 분리된 결과를 Chunk라고 부르며, Chunk들은 다음 단계에서 Embedding Model에 의해 Embedding Vector 값으로 변환됩니다. SKE-GPT는 RecursiveCharacterTextSplitter()를 통해 chunk_size와 chunk_overlap을 지정하였습니다. Chunk_overlap을 지정하면 Document를 분리할 때 공통 영역을 지정하여 모델이 문장을 더욱 잘 이해할 수 있도록 도움을 줄 수 있습니다.
 ▲ chunk_overlap을 적용하여 문서를 분할한 예시 (https://cloud.samsungsds.com/serviceportal/assets/pdf/ko/SDS_Technical_Guide_Deployment_configuration_of_컨테이너_Registry_Image_v1.0_kor.pdf 일부 발췌)
▲ chunk_overlap을 적용하여 문서를 분할한 예시 (https://cloud.samsungsds.com/serviceportal/assets/pdf/ko/SDS_Technical_Guide_Deployment_configuration_of_컨테이너_Registry_Image_v1.0_kor.pdf 일부 발췌)
Text Embedding
Embedding이란 자연어 형태의 텍스트를 실수 벡터 형태로 표현하는 과정 또는 그 결과물을 이야기합니다. 명확한 구분이 필요할 때는 Embedding 결과물을 Embedding Vector라고 표현합니다. Document로부터 Embedding을 추출하는 데 사용되는 모델을 Embedding Model이라고 하며, OpenAI의 Embedding API를 활용하면 API 호출만으로도 간편하게 Embedding 값을 얻어낼 수 있습니다.
Vector Stores
전 단계에서 추출된 Embedding Vector들은 Vector Store라 불리는 Vector DB에 저장하고 관리할 수 있습니다. Vector DB를 활용하면 유사도 검색을 통해 사용자 질의와 근접한 Embedding을 손쉽게 검색할 수 있습니다.
 ▲ Vector Stores 종류
▲ Vector Stores 종류
| - | Dedicated Vector databases | Databases that support vector search |
|---|---|---|
| Open source (Apache 2.0 or MIT license) | chroma, marqo, vespa, drant, LanceDB, Milvus | OpenSearch, ClickHouse, PostgreSQL |
| Source available or commercial | Weaviate, Pinecone | elasticsearch, redis, ROCKSET, SingleStore |
2. Retrieval and Generation
 ▲ 출처: https://python.langchain.com/docs/use_cases/question_answering
▲ 출처: https://python.langchain.com/docs/use_cases/question_answering
Retrieval and Generation 컴포넌트는 Vector Store에서 사용자 질문과 유사한 문서를 검색하는 Retrieve 단계와 Prompt를 생성하여 LLM에 질의하는 Generation 단계로 구성되어 있습니다.
Retrievers
Retrieve란 ‘검색하다’라는 뜻으로, RAG에서는 Vector Store에 질의(query)와 유사한 문서를 검색하는 과정을 의미합니다. Retriever는 Vector Store의 검색 결과를 사용자 질의(question)와 함께 Prompt로 생성하여 LLM에 전달합니다. 이때 검색된 문서들은 Context 형태로 Prompt 구문에 포함됩니다. Retriever를 사용하면 애플리케이션의 특징에 맞는 검색을 수행할 수 있습니다. 유사도 기반 검색을 수행하는 Retriever의 결과를 조금 더 풍부하게 하고 싶다면 “Maximum Marginal Relevance Search” 옵션을 사용합니다. MMR 옵션은 검색 결과 문서 간 유사도를 최소화하여 LLM이 참조할 데이터를 다양하게 제공하도록 설정할 수 있습니다. 반대로 정보의 정확도가 중요한 애플리케이션이라면 “Similarity Score Threshold”를 사용하여 검색 결과가 특정값 이상인 문서만 반환하도록 할 수 있습니다. Score Threshold란 유사도 점수를 뜻하며 0에서 1 사이의 소수점 값을 가질 수 있습니다. 1에 가까울수록 유사도 점수가 높은 문서입니다.
Generate
Generate 단계에서는 앞에서 생성한 Prompt를 LLM에 전달하여 받은 답변을 사용자에게 전달합니다. LLM이라 표현하였지만 애플리케이션에 따라 Chat Model을 사용할 수도 있습니다. 지금까지 설명한 RAG를 적용한 애플리케이션의 흐름을 요약하면 다음과 같습니다.
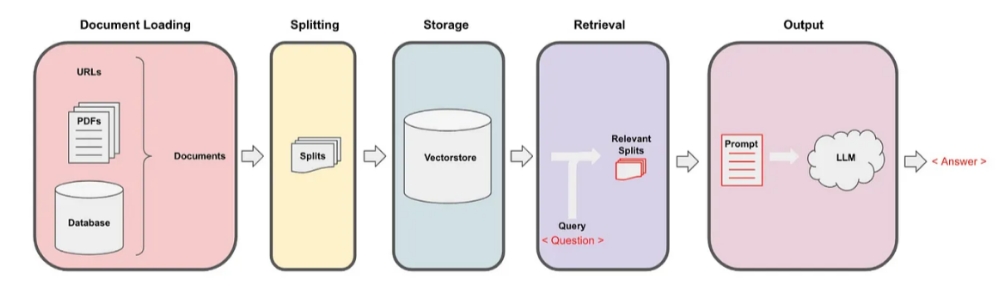 ▲ 출처: https://medium.com/@onkarmishra/using-langchain-for-question-answering-on-own-data-3af0a82789ed
▲ 출처: https://medium.com/@onkarmishra/using-langchain-for-question-answering-on-own-data-3af0a82789ed
Document Loading
URLs, PDFs, Database > Documents
Splititing
SplitsStorage
VectorstoreRetreval
Query Question
Relevant Splits
Output
Prompt > LLMAnswer
기업 맞춤형 RAG의 활용과 기대효과
빠르게 발전하는 AI 기술과 함께 RAG는 AI 기반 서비스의 핵심 기능으로 자리 잡을 것입니다. 미래의 RAG는 텍스트뿐만 아니라 이미지, 음성, 영상 등 다양한 형태의 데이터를 처리하는 Multi-Modal 기능과 결합하여 풍부하고 다양한 정보를 처리하는 데 기여할 것입니다. 반면 고려해야 할 사항도 있습니다. RAG가 다루는 데이터는 기업 내부의 민감한 사항들을 담고 있기 때문에 데이터 암호화뿐만 아니라 Vector Store, Embedding Model, LLM 같은 RAG 구성 요소들 역시 외부로의 노출이 없도록 안정성을 보장할 수 있는 방안이 필요합니다. 이런 점들을 고려하여 RAG 기반의 AI 기술을 활용한다면, 기업에서는 업무 생산성을 향상하고 지식 공유 및 협업을 강화할 수 있습니다. 예를 들어, RAG를 활용한 지식 검색을 통해 일원화된 지식 전파가 이루어질 수 있습니다. 또한 기업 내부 양식 기반의 문서 작성을 효율화하고, 정보 취합 및 데이터 분석을 자동화하여 업무 프로세스를 개선할 수 있습니다. RAG를 효과적으로 활용한다면 기업은 더 나은 의사 결정과 서비스 제공을 통해 경쟁우위를 확보할 것입니다.
# References
[1] https://python.langchain.com/docs/use_cases/question_answering
[2] https://cloud.samsungsds.com/serviceportal/assets/pdf/ko/SDS_Technical_Guide_Deployment_configuration_of_컨테이너_Registry_Image_v1.0_kor.pdf
[3] Why You Shouldn’t Invest In Vector Databases? | by Yingjun Wu | Data Engineer Things (det.life)
[4] https://medium.com/@onkarmishra/using-LangChain-for-question-answering-on-own-data-3af0a82789ed
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

강수희
삼성SDS SCP서비스지원그룹
SCP(Samsung Cloud Platform)의 Container(Kubernetes, SCR), DevOps 상품군의 기술지원 역할을 담당하고 있습니다. AI 및 신기술을 활용한 아키텍처 설계에 관심이 많습니다.