
핵심 인사이트
- AI 패권 경쟁 심화 속 한국의 전략적 투자: 미국, 중국에 이어 프랑스 등 주요국들이 AI 주권 확보에 나선 가운데, 한국 정부는 독자적인 FM 개발과 대규모 AI 데이터센터 구축을 통해 AI 강국으로의 도약을 추진하고 있습니다.
- 제조업 혁신과 전 국민 AI 접근성 확대: 한국 AI 정책은 단순히 기술 개발에 그치지 않고, AI 기반의 제조업 혁신과 공공 서비스 개선을 통해 국민 생활의 질을 높이는 데 초점을 맞추고 있습니다.
- 인프라·플랫폼형 소버린 AI 모델 제시: 한국은 반도체, 데이터센터, K-LLM, 제조 AI를 결합한 ‘인프라-플랫폼형 소버린 AI 중견국 모델’을 지향하며, 외교력과 비교우위를 활용한 차별화된 전략을 모색하고 있습니다.
신정부가 들어선 이후, 한국의 AI 정책은 세계가 놀랄 만큼 빠르고 강력한 가능성을 보여주고 있다. 사실 AI 시장은 단순 테크 기업들의 각축장이 아니라 각국의 정부가 나서서 AI 주권을 강조하면서 패권 경쟁의 전쟁터가 되었다. 이 전쟁에서 미국과 중국은 멀찌감치 앞서 나가고, 그 뒤를 프랑스와 중동 등이 뒤쫓아가는 형세였다. 한국은 사실 2000년대 IT 강국으로 주목받던 잠재력이 무색하게 AI 산업에 있어서는 이렇다할 명함조차 내밀지 못했다. 하지만, 새정부 들어서면서 한국산 FM(독파모 = 독립된 파운데이션 모델)에 대한 선언과 함께 AI 데이터센터 확보를 위한 노력 그리고 공공 부문에서의 AI 서비스 확대와 제조 AI 육성, AI 바우처 사업을 통한 전 국민의 AI 서비스 활성화 등에 대한 공격적인 정책들을 마련하면서 세계 3위 AI 강국을 향한 발걸음을 내딛고 있다. 한국의 AI는 어디를 향해서 가고, 앞으로 어떤 기회를 가지게 될까?
각국의 패권 경쟁이 된 소버린 AI
AI 산업은 크게 원천기술과 응용 서비스로 나뉠 수 있다. 원천기술에 속하는 것이 AI 인프라 즉 GPU와 HBM으로 구성된 서버와 데이터센터 그리고 FM(Foundation Model)이다. 데이터센터는 하드웨어이고 FM은 소프트웨어 알고리즘이다. 이 원천기술 위에 Cloud의 다양한 AI 솔루션들과 프로토콜들을 기반으로 AI 애플리케이션이 만들어져 응용 서비스로 구현되는 것이다. ChatGPT를 예로 들면, OpenAI가 임대 혹은 구축한 데이터센터(Microsoft의 DC 혹은 독자적으로 구축한 전용 AI DC)와 GPT라는 FM이 원천기술이고, ChatGPT를 포함해 달리와 소라, Atlas(오픈AI가 개발한 AI 브라우저) 등이 응용 서비스이다.
즉, ChatGPT와 같은 AI 서비스를 개발하고 운영하기 위해서는 FM이 필수적이다. FM이 있어야 다양한 용도에 맞는 LLM(Large Language Model)을 파생 개발이 가능하다. 그런 FM을 보유하고 있는 국가는 미국, 중국, 프랑스 그리고 일부 나라들이 있다. 그런데, FM의 성능은 기본적으로 파라미터 수로 평가한다. 미국의 AI 기업은 수조 개의 파라미터를 가진 FM을 가지고 있고 중국은 약 1조로 추정되고 있으며 그 외의 국가들은 수백만에서 수천만 수준이다. 그렇다 보니 미국과 중국이 압도적인 FM들을 보유하고 있다. FM이 훌륭해야 다양한 용도에서 사용 가능한 압도적 성능의 AI 서비스와 솔루션 개발이 가능하다.
하지만, 제대로 된 FM(LLM)을 만들려면 상당한 컴퓨팅 인프라를 필요로 한다. 그래서, 한국 정부의 AI 주권을 오롯이 지키기 위한 독자적인 한국형 LLM 개발 과정 역시 엄청난 GPU(+HBM)가 필요하다. 이를 위해 정부는 GPU를 K-LLM 기업에 임차해서 제공하고 국가 AI 컴퓨팅 센터를 구축하는 것이다. 그렇게 해서 5만 장 이상의 GPU를 확보할 로드맵을 발표했고, 2025년 경주 APEC 행사에서는 향후 26만 장의 GPU를 우선 공급받기로 엔비디아와 약속을 받아내기도 했다. 이처럼 한국 외에도 일본, 인도, 아랍에미리트, 대만, 캐나다 그리고 프랑스, 영국, 독일 등의 일부 유럽 국가들이 독자적인 LLM 개발을 위한 정부 차원의 투자에 본격적으로 나서고 있다.
왜일까? 그만큼 AI 모델을 독자적으로 만들 수 있어야 해외 AI 기술의 종속성에서 탈피해 자국의 언어와 문화 그리고 특정 산업 분야에 최적화된 AI 주권(소버린 AI)을 찾을 수 있기 때문이다. 특히 국가 안보와 보안, 국방 그리고 국가 기간망에 대해 온전한 통제를 하기 위해서는 자체적인 AI 모델에 기초해서 이들 영역의 AI화를 꾀해야 한다. 그래서 자체 LLM 개발과 이를 위한 컴퓨팅 인프라 확보를 경쟁적으로 하고 있는 것이다.
그렇다면 소버린 AI를 위한 LLM 개발은 컴퓨팅 인프라만으로는 가능한 것일까? 추가적으로 2가지가 필요하다. 첫째는 기술력 즉 역량 있는 인재가 필요하고 두 번째로는 데이터이다. 컴퓨팅 인프라야 자금만 확보해서 AI 반도체를 공급하는 기업과 협력 그리고 이를 운용할 데이터센터와 전력 등에 대한 준비(물론 이것만 해도 쉬운 일이 아님)하면 된다. 하지만, LLM을 개발할 수 있는 기술력은 하루아침에 확보할 수 있는 것이 아니다. 반면, 데이터는 자국의 오랜 역사 속에서 민관이 수집해 온 데이터를 이용할 수 있다. 그렇게 각국이 AI 패권을 놓치지 않기 위한 경쟁을 본격화하고 있다.
 [그림 1] 소버린 AI의 구축 방식(출처: NotebookLM으로 생성)
[그림 1] 소버린 AI의 구축 방식(출처: NotebookLM으로 생성)
소버린 AI는 '완전 자립(自强)'과 '개방 협력(協力)' 사이의 전략적 선택입니다.
| 자체적 대비(Internal Preparation) 자립 自强 - Close | 해외 기술 활용(Leveraging Foreign Technology) 협력 協力 - Open | |
|---|---|---|
| Infra & 반도체 | (自强) 자국 내 자체구축 DC, 자국 반도체 | (協力) 글로벌 클라우드 활용 |
| Foundation Model | (自强) From Scratch로 학습시킨 독자 FM | (協力) 오픈소스 또는 해외 FM 도입 후 CPT 기반 개발 |
| AI Ops | (自强) 자국 기업 개발 Ops | (協力) 해외 라이선스 또는 오픈소스 활용 |
| 서비스 | (自强) 자국 FM, 데이터, 인프라 기반 특화 서비스 | (協力) 해외 AI 기업의 국내 서비스 |
각 기술 스택 단계별로 최적의 조합을 찾는 것이 핵심 과제ss입니다.
그렇게 각국이 자체적인 소버린 AI를 강조하는 이유는 AI가 군사·경제·사회·산업을 모두 결합하는 총체적 주권의 문제이기 때문이다. 다만, 각국의 기술력과 산업 구조와 경쟁력 등이 다르기 때문에 각자의 소버린 AI에 대한 정의와 추진 방식은 조금씩 다르다. 즉, AI 모델에 대한 기술력 경쟁을 넘어 국가가 어떤 방식으로 AI를 ‘보유하고 활용하여 성장으로 전환할 것인가’에 있어 서로 차이가 있다.
미국과 중국의 경우는 A부터 Z까지 온전히 다(Full stack) 독자적으로 구축, 운영하는 것을 목표로 개발하고 있다. 그런 AI의 모든 것을 국가 통제 하에 우방국에게 제공, 판매하는 것이 이들의 목표다. 하지만, 모든 국가가 미·중처럼 할 수는 없다. 일례로 싱가포르는 ‘National AI Strategy 2.0’를 통해 자국이 직접 거대 모델을 모두 만들기보다는 공공·금융·물류·도시 운영 등 200여 개 이상의 서비스에 AI를 깊게 녹여 넣는 “AI 운영 허브 국가”를 지향하며, 동남아 역내 LLM 생태계 조성, 평가 샌드박스, 2024년 예산 기준 10억 달러 규모의 인프라·인재 투자로 미·중이 만든 모델과 클라우드를 전략적으로 병행 활용하면서도 자국 데이터와 공공 서비스만큼은 자국 내 인프라와 규제로 통제하는 제한적 디지털 주권 모델을 추구하고 있다.
영국은 ‘Pro-innovation approach to AI regulation’ 백서와 AI Safety Summit, AI Safety Institute를 축으로 빅테크를 과도하게 규제하지 않으면서도 AI 안전·윤리·표준을 선도하는 규범 국가로 포지셔닝해, 미국·중국처럼 자국 빅테크가 압도적이지 않은 현실을 인정하고 “규제·표준·거버넌스 주도권”을 통해 소버린 AI 영향력을 확보하는 전략을 택했다. 프랑스는 2018년 1.5억 유로 1단계 AI 전략 이후 France 2030 계획(총 540억 유로 혁신 투자 중 AI·데이터·HPC 비중 확대)을 통해 9개 AI 클러스터, 건강·제조·교통 등 도메인 특화 AI 전략 그리고 미스트랄 AI 기반으로 유럽형 AI 플랫폼을 유럽 전체에 제공하는 것을 지향하고 있다. 이렇게 “유럽형 AI 인프라와 산업 생태계를 직접 깔아 미·중 의존도를 줄이는 하드웨어·클라우드 중심의 소버린 AI”를 밀어붙이고 있다.
이에 비해 한국은 AI 국가 전략과 2024년 제정된 ‘AI 기본법’을 통해 세계 최초로 산업 진흥·규제·거버넌스를 하나의 프레임워크로 묶고, 2027년까지 약 10조 원을 투자해 2025년 당해만 1만 장의 GPU 확보를 목표로 하고 있다. 향후 2030년까지 수십만 장의 GPU와 여러 NPU 기반의 AI 데이터센터 구축을 민관이 나서서 추진할 것으로 기대된다. 즉, 반도체·DC 인프라·K-LLM·제조 AI를 결합한 “인프라·플랫폼형 소버린 AI 중견국 모델”을 지향해 미국, 중국에 이어 세계 3번째 AI 강국이 한국이 지향하고 있는 소버린 AI다. “공급망과 인프라에서의 비교우위와 외교력”을 활용하는 한국식 소버린 AI 전략을 모색하고 있다.
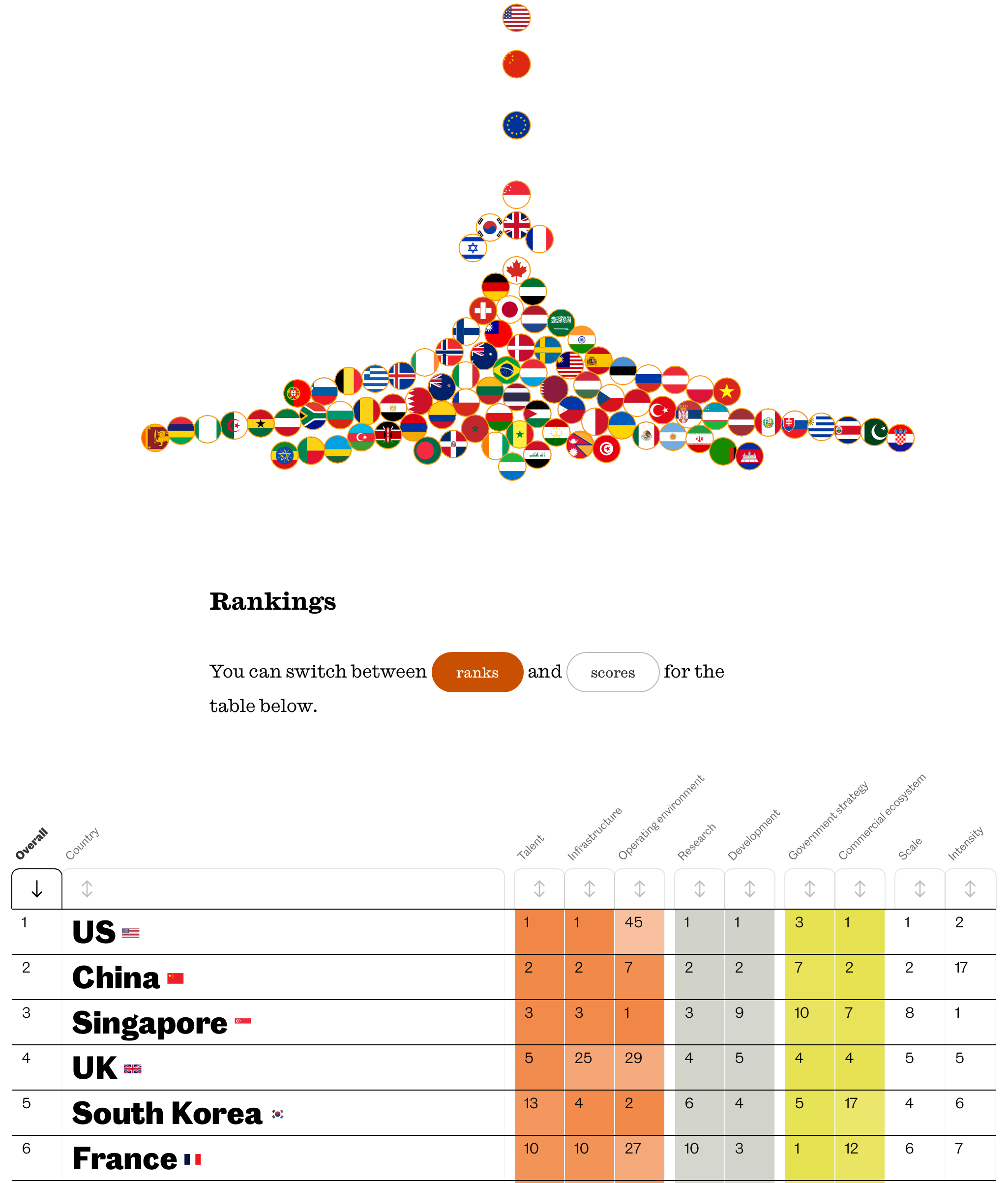 [그림 2] Tortoise Media의 Global AI Index(출처 : https://observer.co.uk/data/global-ai)
[그림 2] Tortoise Media의 Global AI Index(출처 : https://observer.co.uk/data/global-ai)
Rankings
You can switch between ranks and scroes for the table below.
| Overall | Country | Talent | Infrastructure | Operationg enviroment | Research | Development | Govement strategy | Commercial ecosystem | Scale | Intensity |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | US | 1 | 1 | 45 | 1 | 1 | 3 | 1 | 1 | 2 |
| 2 | China | 2 | 2 | 7 | 2 | 2 | 7 | 2 | 2 | 17 |
| 3 | Singapore | 3 | 3 | 1 | 3 | 9 | 10 | 7 | 8 | 1 |
| 4 | UK | 5 | 25 | 29 | 4 | 5 | 4 | 4 | 5 | 5 |
| 5 | South Korea | 13 | 4 | 2 | 6 | 4 | 5 | 17 | 4 | 6 |
| 6 | France | 10 | 10 | 27 | 10 | 3 | 1 | 12 | 6 | 7 |
한국의 AI를 향한 도전과 기회
사실 2025년 이전까지만 해도 미·중 중심으로 흘러가던 AI 시장에 프랑스의 미스트랄 AI 외에는 대부분의 국가가 독자적인 AI 모델 개발은 꿈꾸기가 어려웠다. 즉, AI 자강을 위한 방안보다는 미국이나 중국 등의 FM을 가져다 활용하는 것을 기본시 했었다. 하지만, AI가 가져올 파급력이 워낙 크고 자칫 해외의 AI 모델이나 서비스에 의존하게 될 경우 자국의 문화와 국가 인프라 그리고 산업의 자립에 존속성을 해칠 우려가 있어 한국은 신정부 들어서면서부터 K-LLM 개발을 향한 목소리를 높이고 있다.
K-LLM(독파모 = 독자적인 파운데이션 모델) 개발을 위해 정부는 2025년 5개 사업자를 선정(네이버클라우드, 업스테이지, SK텔레콤, NC AI, LG AI연구원)했고 2026년 즈음까지 1~2개 기업이 최종 선정될 것이다. 이같은 FM을 만드는 방법은 크게 From the scratch와 CPT(Continuous Pre-Training) 2가지 방식이 있다. 전자는 A부터 Z까지 맨땅에서 새로 개발하는 것이라 자원이 많이 들지만, 온전히 독자적인 모델 개발이 가능하고, 후자는 다른 FM(특히 공개된 오픈소스 기초 위에)을 기반으로 만드는 것이라 좀 더 빠르고 적은 자원으로도 개발이 가능하다는 이점이 있다. 반면 후자는 완벽히 통제 가능한 AI 모델의 주권을 가지는 것은 아니다. 그렇다 보니 한국의 K-LLM은 전자를 목표로 5개 기업이 개발 중에 있다. 이 FM의 목표 파라미터 수는 약 500B(5천만)로 미·중에 이어 세계 3번째이다.
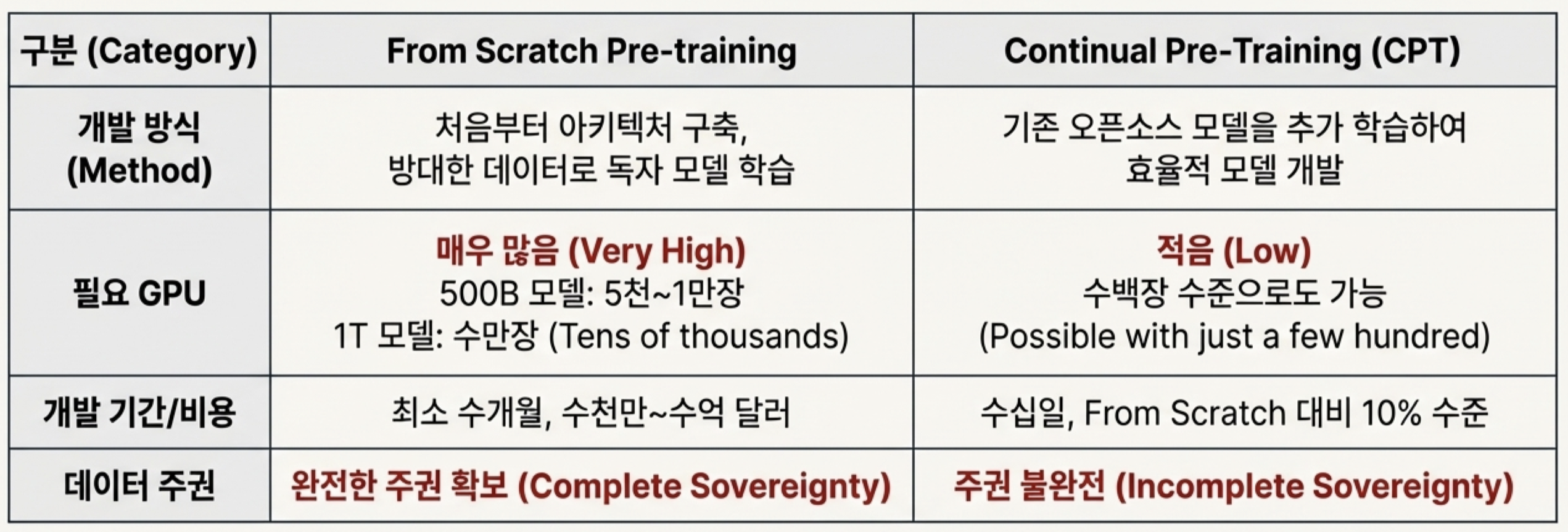 [그림 3] FM 개발의 2가지 방법론(출처: NotebookLM으로 생성)
[그림 3] FM 개발의 2가지 방법론(출처: NotebookLM으로 생성)
| 구분(Category) | From Scratch Pre-training | Continual Pre-Training(CPT) |
|---|---|---|
| 개발 방식(Method) | 처음부터 아키텍처 구축, 방대한 데이터로 독자 모델 학습 | 기존 오픈소스 모델을 추가 학습하여 효율적 모델 개발 |
| 필요 GPU | 매우 많음(Very High) / 500B 모델: 5천~ 1만장 / 1T 모델: 수만장 (Tens of thousnads) | 적음(Low) / 수백장 수준으로도 가능 (Possible with just a few hundred) |
| 개발 기간/비용 | 최소 수개월, 수천만 ~ 수억 달러 | 수십일, From Scratch 대비 10% 수준 |
| 데이터 주권 | 완전한 주권 확보 (Complete Sovereignty) | 주권 불완전 (Incomplete Sovereignty) |
이같은 자체 LLM을 굳이 만드는 이유는 이렇게 만든 기본 모델이 있어야 이를 기초로 각각의 산업과 공공에서 필요로 하는 AI 모델을 추가로 개발할 수 있기 때문이다. 즉, ChatGPT와 같은 대중적인 AI 서비스를 만들기 위함이 아니라 다양한 용도와 목적으로 여러 영역에서 사용할 AI를 위해 필요한 것이다. 이를 미국처럼 정부가 나서지 않고 민간의 테크 기업이 개발하면 좋겠지만, 그런 FM을 제대로 개발하려면 상당한 자본 투자와 기술력, 데이터를 필요로 한다. 그렇기에 정부가 나서서 멍석을 깔아주고 여러 IT 기술 기업들이 참여해 정부의 든든한 AI 인프라 지원과 데이터 등을 활용해 FM 개발에 나설 수 있도록 한 것이다.
그런데, AI 모델 개발은 GPU와 HBM 등의 AI 반도체를 필요로 하고, 이는 데이터센터를 통해 구동된다. 이같은 AI 반도체를 구하는 것도 어렵지만 그보다 더 어려운 것은 데이터센터의 구축과 운영이다. 데이터센터는 땅과 물 그리고 전기를 필요로 한다. 데이터센터에서 구동되는 GPU들은 엄청난 전기가 공급되어야 하고 공급되는 전력이 높은 만큼 열도 많이 난다. 그래서 이를 식히기 위한 냉각수도 필요하다. 물론 네트워크도 확보해야 한다. 이는 한 기업이 독자적으로 해결할 수 있는 것이 아니라 정부의 정책적 지원과 규제 완화 그리고 데이터센터가 위치할 지역 주민과 지자체의 양해를 필요로 한다.
일례로 엔비디아의 블랙윌 B200 GPU 1만 장을 운용하려면 약 10MW의 전력을 필요로 하는데 데이터센터는 GPU에만 전력이 공급되는 것이 아니라 메모리와 스위치, 스토리지 그리고 냉각과 네트워크 등 여러 전기를 필요로 하는 요소들이 있다. 결론적으로 1만 장의 GPU는 약 20MW 정도를 필요로 한다. 이 정도의 전력량은 한국의 약 4만 가구가 사용하는 전력과 비슷하다, 이를 인구로 따지면 약 10만 명 정도의 중소 도시(전북 남원시, 충남 보령시 등) 한 개가 쓰는 가정용 전략과 비슷하다. 그만큼 지방의 도시 수준의 전력량을 필요로 하는 것이다. 그런데, 이런 데이터센터가 수십 MW 수준을 넘어 GW를 훌쩍 넘는 수요를 필요로 하기 때문에 정부의 전폭적인 지원과 투자가 있어야 한다. 그런 이유로, 정부의 AI 정책은 K-LLM의 독자적 구축을 넘어 이를 위한 AI 반도체 확보와 이의 운용을 위한 데이터센터 지원으로 귀결된다.
균형있는 AI 생태계의 성장을 위한 과제
AI는 크게 데이터센터 그리고 그 위에서 구동되는 LLM과 Cloud가 있으며, 그 위에 이런 AI를 운영하기 위한 각종 솔루션들이 있다. 그리고 맨 마지막으로 실제 공공, 산업 그리고 사용자들이 사용하는 AI 애플리케이션이나 서비스들이 있다. 이렇게 4개의 영역으로 AI를 구분할 수 있다.
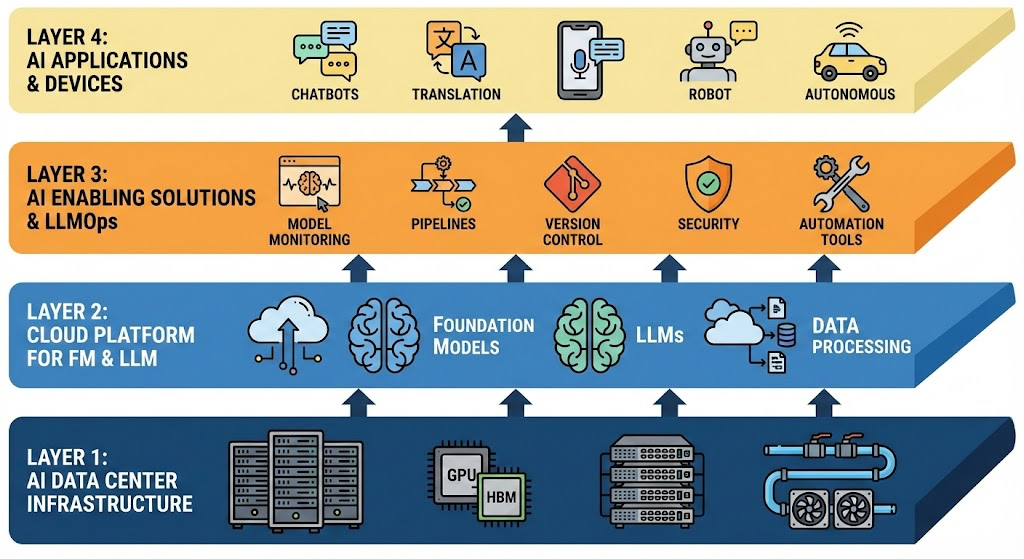 [그림 4] AI의 4가지 Layer(출처: Gemini로 생성)
[그림 4] AI의 4가지 Layer(출처: Gemini로 생성)
LAYER 1: AI DATA CENTER INFRASTRUCTURE (GPU,HBM,SERVER,NETWORK,COOLER) → LAYER 2: CLOUD PLATFORM FOR FM * LLM (FOUNDATION MODELS,LLMs,DATA PROCESSING) → LAYER 3: AI ENABLING SOLUTIONS & LLMOps (MODEL MONITORING,PIPELINES,VERSION CONTROL,SECURITY,AUTOMATION TOOLS) → LAYER 4: AI APPLICATIONS * DEVICES (CHATBOTS,TRANSLATION,ROBOT,AUTONOMOUS)
한국의 소버린 AI는 이들 영역 중 맨 아래의 데이터센터와 바로 그 위의 K-LLM 개발에 집중해 오고 있다. 하지만, 그 외에도 한국의 AI 정책은 AI를 활용한 산업 육성과 제도 개혁 그리고 국가 인재 양성과 AI 활용을 확대하는 4가지의 추가적 과제를 가지고 있다. 특히 AI 산업 육성은 AI 자체적 사업 외에 다른 산업을 AI 기반으로 혁신하는 것을 포함한다.
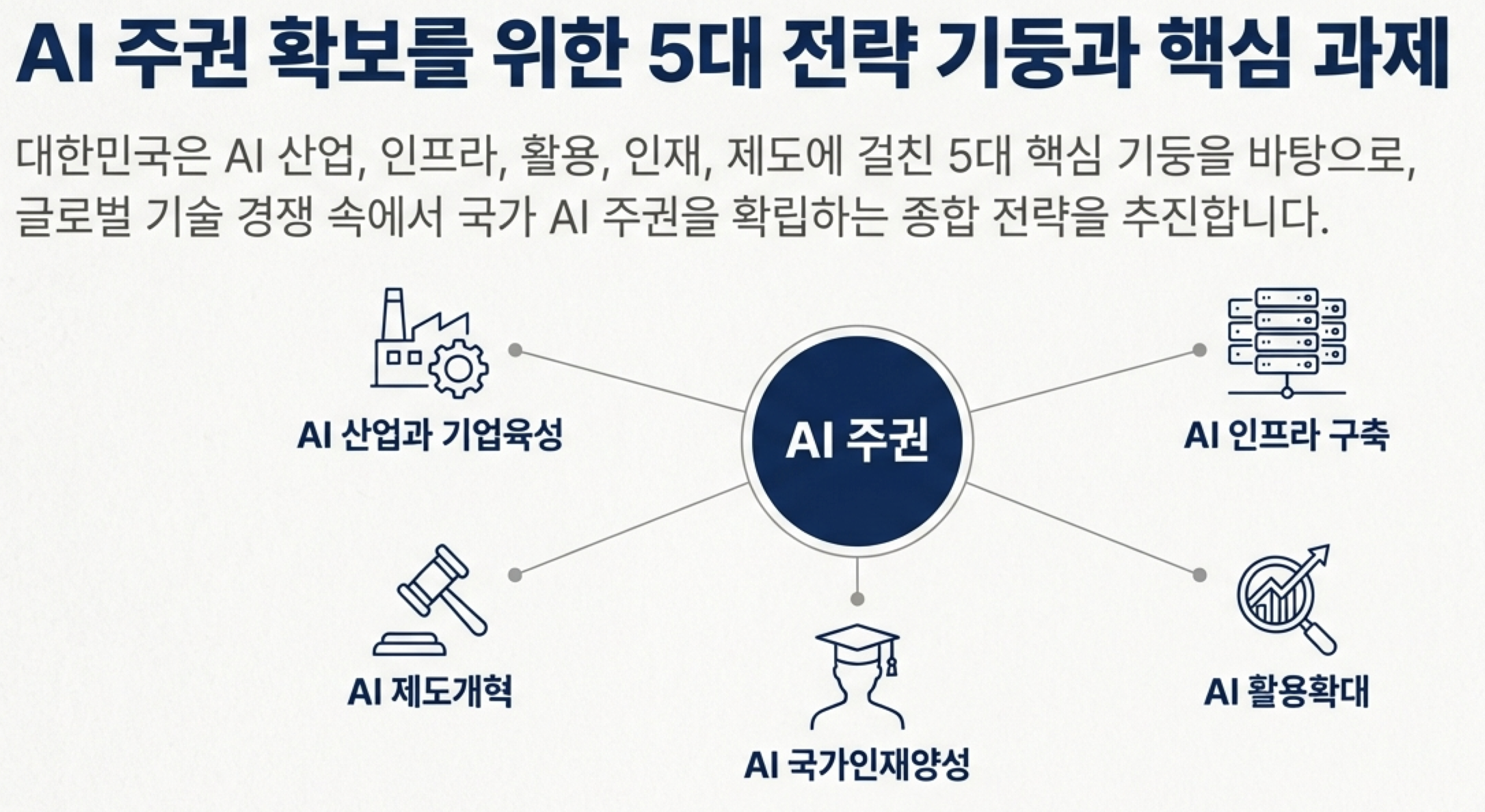 [그림 5] 소버린 AI의 5가지 정책(출처: NotebookLM으로 생성)
[그림 5] 소버린 AI의 5가지 정책(출처: NotebookLM으로 생성)
AI 주권 확보를 위한 5대 전략 기둥과 핵심 과제
대한민국은 AI 산업, 인프라, 활용, 인재, 제도에 걸친 5대 핵심 기둥을 바탕으로, 글로벌 기술 경쟁 속에서 국가 AI 주권을 확립하는 종합 전략을 추진합니다.
AI 주권 - AI 산업과 기업 육성 / AI 제도개혁 / AI 국가인재양성 / AI 활용확대 / AI 인프라 구축
그중 가장 정부가 공들이는 것이 바로 제조업에서의 AI 활용이다. 한국은 오래전부터 제조 강국으로서 세계적인 입지를 다져오고 있다. 그런데, 최근 들어 중국 제조업의 경쟁력이 만만치 않다. 한국 제조의 부활을 위해 정부는 AI를 제조 혁신에 활용하는 데 적극적이다. 국가 AI 대전환을 위한 15개 선도 프로젝트 내역 중에 제조와 관련된 것이 무려 7개나 된다. 로봇, 조선, 공장, 차량 그리고 드론과 반도체, 가전에 AI를 접목해 혁신하는 것이 핵심이다. 이렇게 제조업의 부활을 위해 독자적인 K-LLM 개발을 하는 것이기도 하다. 그렇게 제조에 적용된 AI를 제조 AI라고 부르며, 공장이 완전한 무인화, 자동화, 지능화가 되는 것을 Physical AI라고 부른다. 즉, 산업용 로봇이나 휴머노이드 로봇 등에 AI가 탑재됨으로써 초자동화, 초지능화로 작동될 수 있는 미래 제조를 위한 것이 제조 AI의 궁극적 목표다.
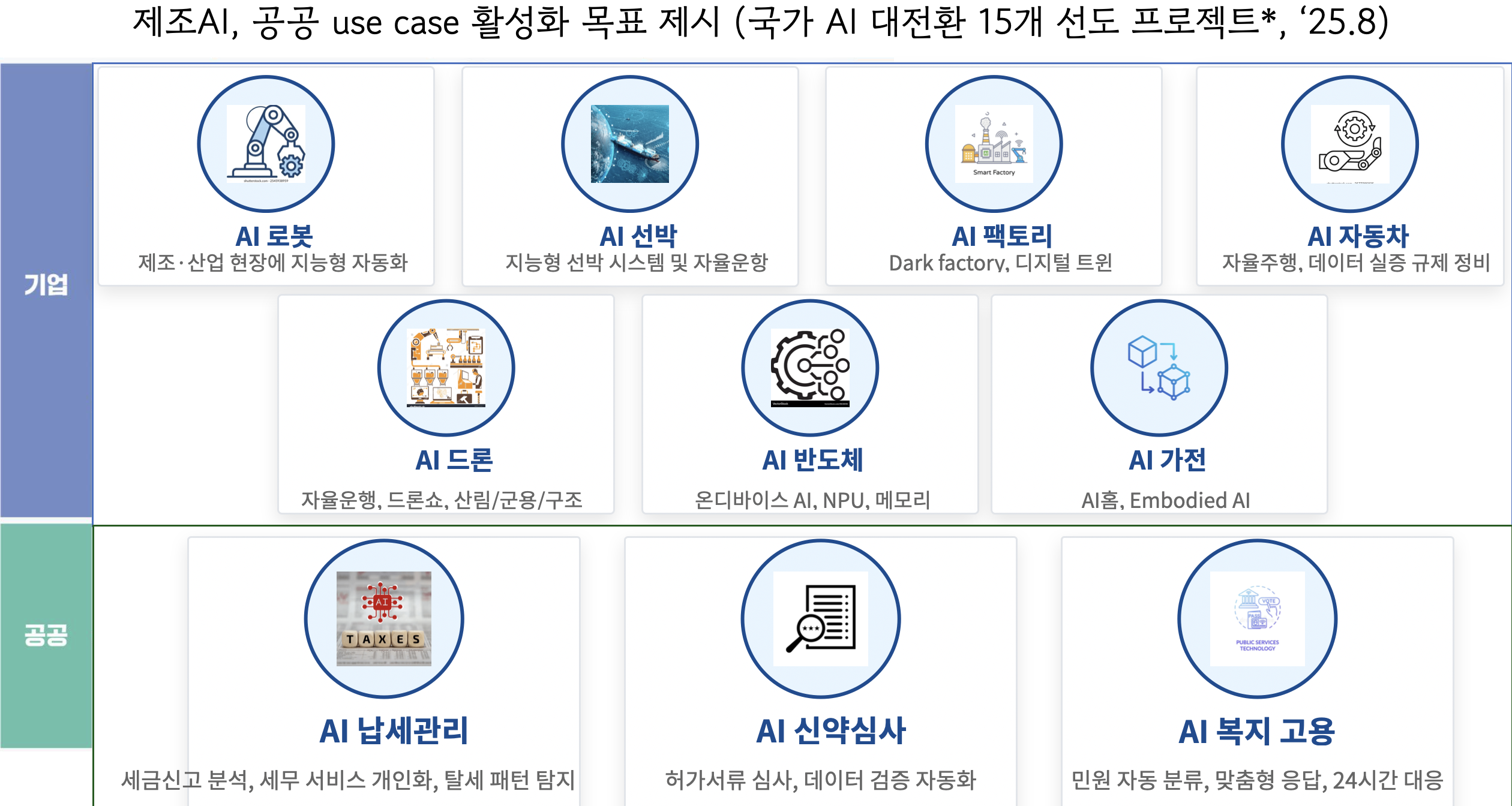 [그림 6] 한국 제조업의 부활을 위한 제조 AI(출처: NotebookLM으로 생성)
[그림 6] 한국 제조업의 부활을 위한 제조 AI(출처: NotebookLM으로 생성)
제조 AI, 공공 use case 활성화 목표 제시 (국가 AI 대전환 15개 선도 프로젝트*, '25.8)
기업
- AI 로봇 - 제조·산업 현장에 지능형 자동화
- AI 선박 - 지능형 선박 시스템 및 자율운항
- AI 팩토리 - Dark factory, 디지털 트윈
- AI 자동차 - 자율주행, 데이터 실증 규제 정비
- AI 드론 - 자율운행, 드론쇼, 산림/군용/구조
- AI 반도체 - 온디바이스 AI, NPU, 메모리
- AI 가전 - AI홈, Embodied AI
공공
- AI 납세관리 - 세금신고 분석, 세무 서비스 개인화, 탈세 패턴 감지
- AI 신약심사 - 허가서류 심사, 데이터 검증 자동화
- AI 복지 고용 - 민원 자동 분류, 맞춤형 응답, 24시간 대응
물론 그 외에도 공공 영역에 AI를 활용해 보다 나은 행정, 공공 서비스를 실현하는 것도 AI 활용 확대에 포함되어 있다. 정부의 AI 정책은 단지 인프라나 AI 모델 그 자체에만 있는 것이 아니라 이렇게 구축된 AI를 실제 산업 혁신에 활용하고 전 국민이 더 나은 공공 서비스를 AI 도움을 받아 편리한 경험을 가질 수 있는 것을 목적으로 하고 있다. 이를 위해 먼저 공공 영역에 AI를 접목해 더 나은 서비스를 개발하고 보다 많은 시민들이 공정하게 AI를 사용할 수 있도록 즉 AI에 대한 접근성을 전 국민이 보장받을 수 있도록 하는 것도 포함되어 있다. 사실 AI 강국으로 가는 길은 인프라 투자에 머무는 것을 넘어 누구나 AI를 업무와 일상에서 사용할 수 있도록 하는 것이고, 그 과정에 AI 사업을 하는 기업 그리고 AI를 이용하려는 모든 기업의 혁신이 가속화되는 것에서 찾을 수 있다. 그런 만큼 애써 만든 AI를 여기저기에서 활용하도록 확대하는 것은 중요한 과제이다.
한국의 소버린 AI가 인프라에서 K-LLM을 기초로 한국 산업 육성과 다양한 AI 서비스의 탄생으로 이어지고 전 국민이 AI의 혜택을 받을 수 있는 것을 포괄해 갈 수 있다면 전 세계 3위 안에 드는 AI 강국으로 가는 길은 이루어질 것이다.
FAQ
소버린 AI는 특정 국가가 해외 기술에 의존하지 않고 자체적으로 AI 기술을 개발, 활용, 통제하는 것을 의미합니다. 이는 국가 안보, 경제 주권, 문화적 특성을 보호하고, 자국 산업에 최적화된 AI 서비스를 제공하기 위해 중요합니다.
Q. K-LLM(독파모)은 무엇이며, 왜 중요한가요?
K-LLM은 ‘한국형 파운데이션 모델(Korean Large Language Model)’의 약자로, 한국 정부가 주도하여 개발 중인 독자적인 AI 기본 모델입니다. 이는 한국어 및 한국 문화에 특화된 AI 서비스를 개발하고, 해외 기술 의존도를 낮추는 데 핵심적인 역할을 합니다.
Q. AI 데이터센터가 왜 중요한가요?
AI 데이터센터는 AI 모델을 학습시키고 운영하는 데 필요한 막대한 컴퓨팅 자원을 제공합니다. 특히, 대규모 언어 모델(LLM)처럼 복잡한 AI 모델을 개발하고 활용하기 위해서는 고성능 GPU와 안정적인 전력 공급이 필수적이며, 이를 위한 데이터센터 구축이 중요합니다.
Q. 한국 AI 정책의 핵심 목표는 무엇인가요?
한국 AI 정책의 핵심 목표는 세계 3위 AI 강국으로 도약하는 것입니다. 이를 위해 독자적인 AI 기술 확보, AI 기반 산업 혁신, 전 국민의 AI 접근성 확대, 그리고 AI 안전 및 윤리적 문제 해결에 집중하고 있습니다.
Q. 한국 AI 정책의 주요 과제는 무엇인가요?
한국 AI 정책의 주요 과제는 AI 인재 양성, 데이터 확보, AI 윤리 및 안전 기준 마련, 그리고 AI 기술의 산업 전반으로의 확산입니다. 또한, AI 기술의 발전에 따른 사회적 변화에 대한 대비도 중요한 과제입니다.
Q. 제조 AI란 무엇이며, 한국 제조업에 어떤 영향을 미칠까요?
제조 AI는 인공지능 기술을 제조업 프로세스에 적용하여 생산 효율성을 높이고, 품질을 개선하며, 새로운 가치를 창출하는 것을 의미합니다. 한국은 제조 강국으로서 AI를 활용하여 제조업 경쟁력을 강화하고, 스마트 팩토리 구축을 가속할 계획입니다.
Q. 일반 사람들은 한국 AI 정책의 변화를 어떻게 체감할 수 있을까요?
한국 AI 정책의 발전은 공공 서비스 개선, 맞춤형 AI 서비스 제공, 그리고 새로운 일자리 창출 등 다양한 방식으로 시민들의 삶에 긍정적인 영향을 미칠 것입니다. 예를 들어, AI 기반의 의료 서비스, 교육 서비스, 교통 서비스 등이 더욱 발전하고 편리해질 것으로 기대됩니다.
▶ 해당 콘텐츠는 저작권법에 의하여 보호받는 저작물로 기고자에게 저작권이 있습니다.
▶ 해당 콘텐츠는 사전 동의 없이 2차 가공 및 영리적인 이용을 금하고 있습니다.
![]()

김지현 | 테크라이터
기술이 우리 일상과 사회에 어떤 변화를 만들고, 기업의 BM 혁신에 어떻게 활용할 수 있을지에 대한 관심과 연구를 하고 있습니다.